利用pandas求神经网络中二分类的混淆矩阵
(test_data, test_labels) 分别为测试集的数据和标签
1、利用神经网络来进行预测(假设当前的神经网络是network)
prediction = network.predict(test_data)
2、得到的prediction是一个(samples_count, 1)的Numpy数组,我们将它转换为一个(samples,_count)的数组
prediction = [(int) ((prediction[i][0] + 0.5) / 1.0) for i in range(len(prediction))]
转换为整数是为了和二分类中的正负例相对应
3、利用numpy将数组中的整数转换为浮点数,便于后续处理
import numpy as np
prediction = np.asarray(prediction).astype('float32)
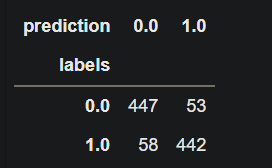
4、利用pandas来求出混淆矩阵`
import pandas as pd
pd.crosstab(test_labels, predction, rownames = 'labels', colnames = 'predicts')
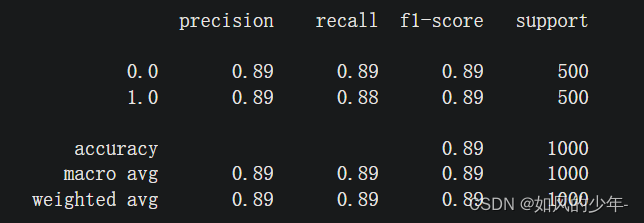
5、利用sklearn中的classification_report来查看对应的准确率、召回率、F1-score
from sklearn.metrics import classification_report
print(classification_report(test_labels, prediction))
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!