模型蒸馏原理和bert模型蒸馏以及theseus压缩实战
目录
一、模型蒸馏简介和步骤
二、模型蒸馏实战
1、Bilstm和Roberta文本分类效果展示
2、roberta蒸馏到bilstm
三、Roberta压缩——theseus理解和实战
1、bert-of-theseus思想和方法
2、利用bert-of-theseus实现的roberta压缩
模型压缩有剪枝、蒸馏和量化等一些方法,模型蒸馏实现起来比较容易简单,这里对模型蒸馏进行分析和实战效果展示。
一、模型蒸馏简介和步骤
模型蒸馏的思想就是利用一个已经训练好的、大型的、效果比较好的Teacher模型,去指导一个轻量型、参数少的student模型去训练——在减小模型的大小和计算资源的同时,尽量把Student模型的准确率保证在Teacher模型附近。这种思想和方法在Hinton等论文Distilling the Knowledge in a Neural Network中做了详细的介绍和说明。
模型蒸馏训练的框架结构图

第一步:训练big模型(Teacher model),这里用到的就是正常的label(hard label)——尽量把模型的准确率训练提升上来。
第二步:联合小模型和大模型进行蒸馏训练(参考上图)。加载大模型的权重后冻结大模型的权重,得到输出soft target;小模型对soft target和hard target(数据的真实label)进行损失计算,对损失进行加权求和,然后在更新梯度,从而更新小模型的参数。值得注意的是大模型和小模型的输出计算loss的时候,需要对输出进行一个整除T的操作——论文提出的softmax-T:
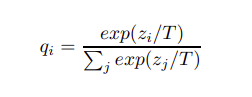
这里的T是为了使得logit输出的各个类别的概率比较平滑,使得分布比较均匀,小模型在训练的时候就能学习到概率比较小的类别的一些信息。
总体loss如下:
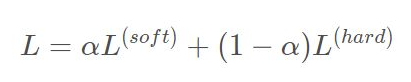
一般而言这里的loss加权选择1:1就可以了,具体设计到loss函数的选择L_hard就选择交叉熵损失函数,L_soft可以选择相对熵KLDivLoss函数、MseLoss函数、CosineEmbeddingLoss(有人用过,我没使用过)。
具体选择什么样的loss函数,就需要针对不同的业务场景和数据来进行实验,那个效果好选择那一个(这个没有很强的理论来分析那个loss更好,一切看效果)
二、模型蒸馏实战
之前做过一个文本分类的任务,这里想进行一个文本分类任务的模型蒸馏实验,看看具体的效果怎么样。
首先看看大模型和小模型单独的效果如何,这里就把单独训练的过程和结果展示一下,具体的代码不做演示(可参考我的博客文章——基于机器学习算法和pytorch实现的深度学习模型的中文长文本多分类任务实战——TextBert和TextRNN部分内容)。特此说明该次训练采用的预训练模型是roberta模型而不是Chinese-BERT-wwm模型。
1、Bilstm和Roberta文本分类效果展示
Bilstm——TextRNN训练过程和最终结果如下:


可以看到最终在验证集上的准确率是:74.65%
Roberta——TextBert训练过程和效果如下:


可以发现roberta在验证集上最好的准确率是84.72%
2、roberta蒸馏到bilstm
蒸馏示意图如下

蒸馏的思路比较简单,把上述微调训练好的roberta模型作为teacher模型,Bilstm作为student模型。然后使用不同的loss函数,进行文本分类任务的训练。核心代码如下:
train_data = ReadDataSet('train.tsv',args)train_loader = DataLoader(dataset=train_data, batch_size=args.batch_size, shuffle=True)dev_data = ReadDataSet('dev.tsv',args)dev_loader = DataLoader(dataset=dev_data, batch_size=args.batch_size, shuffle=True)teacher_model = torch.load('savedmodel/TextBert_model.bin')student_model = TextRNN()train(teacher_model,student_model,train_loader,dev_loader,args)以上训练集和验证集数据加载、教师模型和学生模型定义
完整的训练代码如下:
def train(teacher_model,student_model,train_loader,dev_loader,args):teacher_model.to('cuda')student_model.to('cuda')#teacher网络参数不更新for name,params in teacher_model.named_parameters():params.requires_grad = False# 初始学习率,student网络参数梯度更新optimizer_params = {'lr': 1e-3, 'eps': 1e-8}optimizer = AdamW(student_model.parameters(), **optimizer_params)scheduler = ReduceLROnPlateau(optimizer, mode='max', factor=0.5, min_lr=1e-6, patience=2, verbose=True,eps=1e-8) # mode max表示当监控量停止上升时,学习率将减小;min表示当监控量停止下降时,学习率将减小;这里监控的是dev_acc因此应该用max# #teacher网络输出和student网络输出进行损失计算# soft_criterion = nn.KLDivLoss()#teacher网络输出和student网络输出进行损失计算soft_criterion = nn.MSELoss()#student网络和label进行损失计算hard_criterion = nn.CrossEntropyLoss()#alpha(0,1)之间——两个loss的权重系数alpha = args.alpha#T_softmax()的超参[1,10,20]等等值可以多测试几个T = 10early_stop_step = 50000last_improve = 0 #记录上次提升的stepflag = False # 记录是否很久没有效果提升dev_best_acc = 0dev_loss = float(50)dev_acc = 0correct = 0total = 0global_step = 0epochs = args.epochsfor epoch in range(args.epochs):for step,batch in enumerate(tqdm(train_loader,desc='Train iteration:')):global_step += 1optimizer.zero_grad()batch = tuple(t.to('cuda') for t in batch)input_ids = batch[0]input_mask = batch[1]label = batch[2]student_model.train()stu_output = student_model(input_ids)tea_output = teacher_model(input_ids,input_mask).detach()#soft_loss————studetn和teach之间做loss,使用的是散度losssoft_loss = soft_criterion(F.log_softmax(stu_output/T,dim=1),F.softmax(tea_output/T,dim=1))*T*T# #soft_loss————studetn和teach之间做loss,使用的是logits的Mse损失# soft_loss = soft_criterion(stu_output,tea_output)#hard_loss————studetn和label之间的loss,交叉熵hard_loss = hard_criterion(stu_output,label)loss = soft_loss*alpha + hard_loss*(1-alpha)loss.backward()optimizer.step()total += label.size(0)_,predict = torch.max(stu_output,1)correct += (predict==label).sum().item()train_acc = correct / totalif (step+1)%1000 == 0:print('Train Epoch[{}/{}],step[{}/{}],tra_acc{:.6f} %,loss:{:.6f}'.format(epoch,epochs,step,len(train_loader),train_acc*100,loss.item()))if (step+1)%(len(train_loader)/2)==0:dev_acc,dev_loss = dev(student_model, dev_loader)dev_loss = dev_loss.item()if dev_best_acc < dev_acc:dev_best_acc = dev_accpath = 'savedmodel/TextRnn_distillation_model_mse.bin'torch.save(student_model,path)last_improve = global_stepprint("DEV Epoch[{}/{}],step[{}/{}],tra_acc{:.6f} %,dev_acc{:.6f} %,best_dev_acc{:.6f} %,train_loss:{:.6f},dev_loss:{:.6f}".format(epoch, epochs, step, len(train_loader), train_acc * 100, dev_acc * 100,dev_best_acc*100,loss.item(),dev_loss))if global_step-last_improve >= early_stop_step:print("No optimization for a long time, auto-stopping...")flag = Truebreakwriter.add_scalar('textBert_distillation_bilstm/train_loss', loss.item(), global_step=global_step)writer.add_scalar('textBert_distillation_bilstm/dev_loss', dev_loss, global_step=global_step)writer.add_scalar('textBert_distillation_bilstm/train_acc', train_acc, global_step=global_step)writer.add_scalar('textBert_distillation_bilstm/dev_acc', dev_acc, global_step=global_step)scheduler.step(dev_best_acc)if flag:breakwriter.close()注释写的比较详细,最重要的地方:
#teacher网络参数不更新for name,params in teacher_model.named_parameters():params.requires_grad = False
...... student_model.train()stu_output = student_model(input_ids)tea_output = teacher_model(input_ids,input_mask).detach()#soft_loss————studetn和teach之间做loss,使用的是散度losssoft_loss = soft_criterion(F.log_softmax(stu_output/T,dim=1),F.softmax(tea_output/T,dim=1))*T*Thard_loss = hard_criterion(stu_output,label)loss = soft_loss*alpha + hard_loss*(1-alpha)
注意到teacher模型参数不更新,在计算softloss的时候,对于teacher和student模型的输出需要做softmax_T的操作,然后使用KLDivLoss或者MseLoss来计算loss。
KLDivLoss结果如下


roberta 蒸馏到Bilst——KLDivLoss准确率:78.78%
MseLoss结果如下


roberta蒸馏到Bilstm采用MseLoss的准确率是80.99%
注意以上蒸馏过程中采用不同的loss函数的时候,其他的参数没有变化。
可以得出结论,蒸馏确实能提高小模型的性能,不同的loss函数也是具有不同的效果;另外还有其他的超参就没有去验证做实验了,读者可以自行去做实验。
三、Roberta压缩——theseus理解和实战
针对Bert系列模型的蒸馏方法,有distillbert和tinybert,这些模型都是直接作用在bert预训练的阶段,然后把训练好的模型应用到下游任务,这样的压缩蒸馏方法对一般人来说不太友好。论文:ERT-of-Theseus: Compressing BERT by Progressive Module Replacing——提出了一种适合在funetune阶段对bert模型进行压缩蒸馏的方法,可以把Bert按照module replacing的方式来做压缩。
1、bert-of-theseus思想和方法
把训练分为两个过程,第一阶段使用模块替换(就是把原来的模型中的一些模块按照某些规则替换成更细更小的子层)。论文中把原始模型称为P_model,压缩后的模型称之为S_model,该训练阶段中考虑了P_model和S_model,它们都参与了训练;第二阶段单独S_model的微调阶段,就是为了让所有的S_model的模块参数训练任务中去。

第一阶段:压缩训练阶段——模块替换
它的思想——就是在训练的时候把S_model中的某一个模块按照一定的规则平行替换掉P_model对应的模块。当然这里不会在每个训练的step的时候把所有的P_model模块替换掉,不然就是直接用S_model来进行训练了。
论文提出替换的规则是:通过一个伯努利分布,采样一个随机变量,概率是p,那么P_model每个模块有p的概率替换掉,1-p的概率不被替换。
这里还有一个值得注意的地方,P_model和S_model在训练的时候,属于P_model的权重参数都要冻结起来,不参数梯度计算和更新,只有S_model的权重参数参与梯度计算和更新。
第二阶段:S_model finetune后的finetune——psot training
在第一阶段训练完成后,得到了S_model模型结构和权重,只需要把它组合成一个单独的模型,正常的进行同样的数据集和任务进行微调,起到一个精炼的作用,进一步提升S_model的效果。
2、利用bert-of-theseus实现的roberta压缩
参考bert-of-theseus的pytorch版本源码,实现了个人的MY_BERT_THESEUS项目。
模型代码:
from bert_theseus.modeling_bert_of_theseus import BertModel
import torch
import torch.nn as nn
import torch.nn.functional as Fclass TextBert(nn.Module):def __init__(self,args=None):super(TextBert,self).__init__()self.bert = BertModel.from_pretrained(args.model_path)self.dropout = nn.Dropout(0.5)self.cl1 = nn.Linear(768,768)self.cl2 = nn.Linear(768,384)self.cl3 = nn.Linear(384, 8)def forward(self,input_ids,attention_mask):embedding = self.bert(input_ids,attention_mask)[0]mean_embedding = torch.mean(embedding,dim=1)x = self.dropout(mean_embedding)x = F.relu(self.cl1(x))x = F.relu(self.cl2(x))logit = self.cl3(x)return logit同样的这里加载Bert系列模型和抱抱脸的transformer是差不多的
from bert_theseus.modeling_bert_of_theseus import BertModel
self.bert = BertModel.from_pretrained(args.model_path)
这里的BertModel实现如下:
class BertModel(BertPreTrainedModel):def __init__(self, config):super(BertModel, self).__init__(config)self.config = configself.embeddings = BertEmbeddings(config)self.encoder = BertEncoder(config)self.pooler = BertPooler(config)self.init_weights()def forward():......核心的在BertEncoder的实现,如下(其实就是bert-of-theseus库的实现)
class BertEncoder(nn.Module):def __init__(self, config):super(BertEncoder, self).__init__()self.prd_n_layer = config.num_hidden_layersself.scc_n_layer = config.scc_n_layerassert self.prd_n_layer % self.scc_n_layer == 0self.compress_ratio = self.prd_n_layer // self.scc_n_layerself.bernoulli = Noneself.output_attentions = config.output_attentionsself.output_hidden_states = config.output_hidden_statesself.layer = nn.ModuleList([BertLayer(config) for _ in range(self.prd_n_layer)])self.scc_layer = nn.ModuleList([BertLayer(config) for _ in range(self.scc_n_layer)])def set_replacing_rate(self, replacing_rate):if not 0 < replacing_rate <= 1:raise Exception('Replace rate must be in the range (0, 1]!')self.bernoulli = Bernoulli(torch.tensor([replacing_rate]))def forward(self, hidden_states, attention_mask=None, head_mask=None, encoder_hidden_states=None,encoder_attention_mask=None):all_hidden_states = ()all_attentions = ()if self.training:inference_layers = []for i in range(self.scc_n_layer):if self.bernoulli.sample() == 1: # REPLACEinference_layers.append(self.scc_layer[i])else: # KEEP the originalfor offset in range(self.compress_ratio):inference_layers.append(self.layer[i * self.compress_ratio + offset])else: # inference with compressed modelinference_layers = self.scc_layer......这里就仅仅是对self.scc_n_layer的定义修改为config文件来配置的。
第一步:进行roberta中模块替换训练,把模型由12层压缩为6层。
使用bert_theseus定义的模型结构代码来初始化一个bert_theseus系列的模型,然后把微调好的roberta权重加载到该模型中。该模型有12层P_model子层——self.layer,它和roberta权重一一对应;然后还有6层S_model的子层,加载的时候torch会随机初始化,我们这边直接把roberta前6层模型权重赋值给S_model子层——self.scc_layer。代码如下:
#加载并初始化大小模型model = TextBert(args)model_state_dic = model.state_dict()stand_model = torch.load('savedmodel/TextBert_model.bin')stand_model_state_dic = stand_model.state_dict()#把训练好的大模型权重赋值给P_modelfor k, v in model_state_dic.items():for name, param in stand_model_state_dic.items():if name==k:model_state_dic[k] = parammodel.load_state_dict(model_state_dic)#给S_model赋予大模型的权重值————初始化scc_n_layer = model.bert.encoder.scc_n_layermodel.bert.encoder.scc_layer = nn.ModuleList([deepcopy(model.bert.encoder.layer[index]) for index in range(scc_n_layer)])剩下的训练和就普通的模型训练一样了,代码不展示,上结果图和训练过程的一些曲线图


训练过程收敛的比较快速,验证集在S_model的推理下准确率最高是84.16%
第二步:S_model组合成一个新的模型持续训练精调——post training
在第一步训练过程中,保存了bert_theseus的P_model的self.layer12层和S_model的self.scc_layer的6层权重以及做分类用的全连接权重。那么就需要对S_model的self.scc_layer的6层权重拿出来组合为一个新的小模型,继续在相同的数据集上训练。代码如下:
# 初始化Bert模型为6层小模型TextBert中的self.bert是直接由transformer来实现的而不是bert_theseusconfig = BertConfig.from_pretrained(args.model_path,num_hidden_layers=6)model = TextBert(args,config)model_state_dic = model.state_dict()#加载压缩后的6层模型权重theseus_model_state_dic = torch.load('savedmodel/TexrBert_distillation_theseus_state_dict_scc_n_layer_6.bin')#把训练好的模型权重赋值给重新融合的小模型参数字典中,进行post_trainingfor k,v in model_state_dic.items():for name,params in theseus_model_state_dic.items():if '.layer.' not in name:if k==name or k==name.replace('.scc_layer.','.layer.'):model_state_dic[k] = params#一定要重新装载,不然不生效model.load_state_dict(model_state_dic)效果如下:


可以看到进行post training后准确率得到了进一步的提升:84.70%
总结
本博客介绍了经典的模型蒸馏的思想和步骤,并对文本分类任务由Roberta蒸馏到BiLstm的效果做了比对实验;同时也介绍了一种比较方便在微调阶段对Bert模型进行压缩的方法——bert-of-theseus,实验得出该方法在模型的准确率保留上效果明显。
BiLstm:74.68%
roberta:84.72%
Roberta蒸馏到BiLstm+KLDivLoss:78.78%——相比Bilstm上升4个点,相对roberta下降了6个点
Roberta蒸馏到BiLstm+MseLoss:80.99%——相比Bilstm上升6个点,相对roberta下降了4个点
Bert_of_theseus+第一阶段:84.16%,下降了0.56%
bert_of_theseus+post_training:84.70% 下降了0.02%
post_training也是有作用的。
参考文章
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!