scikit-learn中离散特征二值化
scikit-learn中离散特征二值化
最近在看西瓜书用scikit-learn中的CART去跑西瓜数据集,结果遇到麻烦了,西瓜数据集特征不光离散的,而且还是中文的。。(PS:其实我们的数据集中特征值常常是离散的类别,这个很正常),但在scikit-learn中不支持这种离散的类别特征作为输入,这点不得不说weka的人性化,直接输入原始数据集就可以了。。为了解决这个问题,就要用到独热编码(One-Hot Encoding),下面来说下这个One-Hot Encoding:
- One-Hot Encoding

就拿“色泽”这个属性来看看one-hot encoding,显然色泽有“青绿,乌黑,浅白”三个不同的离散值(类别),那么就需要三位二进制数来表示这个特征,则边玩码后应该是这样的:

来讲下上图中数据是怎样产生的,即one-hot encoding是怎样编码的。显然“色泽”这个属性的三个离散值按照[乌黑,浅白,青绿]排列的,来看第一个样本(图中index为0的)色泽=青绿,因此和[乌黑,浅白,青绿]一比对,对应的编码就是001,依次类推2,3,4,5个样本色泽这个属性的编码分为为100,100,001,010。其实说白了就是把一个属性变成了“三个”,因为模型才不关心你几个特征呢,它只管你给他他能计算的,能挖掘出信息的。这就是one-hot编码的大概内容。下面回到scikit-learn中的实现:自然而言想到sklearn的 的Preprocessing模块中的
- 造的数据集
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import LabelBinarizer
from sklearn.feature_extraction import DictVectorizerdata = pd.DataFrame({'name':['Tom','Andy','David'],'age':[20,21,22],'height':[175,165,180]})
print(data)
下面使用OneHotEncoder类来对特征进行onehot编码:
#新版本不允许传入一维数组,因此传入data[['age']],sparse=False为不使用稀疏矩阵表示
arr = OneHotEncoder(sparse = False).fit_transform(data[['age']])
print(arr)
讲到这个地方,要插一个插曲,也是遇到的坑,记录一下,就是当时OneHotEncoder(sparse = False).fit_transform( data['age'] )参数传的是 data['age'],然后有提示就是新版不再允许传入一维数组,一直没搞懂data['age']和data[['age']]的区别,请教石神后,方知data['age']返回的是series,data[['age']]因为传入的是列表['age']所以返回的是dataframe,知道这点区别,为了更加弄明白本质区别是什么,做了实验,相信看完下面的对比,还有和我一样不明白的同学能够有一个清晰的认识:

一目了然,转成列表后,一个是一维的一个是二维的。 回到正题,还可以传入多个特征一次性处理完:
arr = OneHotEncoder(sparse = False).fit_transform(data[['age','height']])
print(arr)
- LabelBinarizer()

发现完全可以解决问题,但 新问题是LabelBinarizer()只能传入一维数组处理,不接受二维的,也就是说如果你想一次对多个特征处理,不能全部传入。。。博主试图用pandas的apply()解决,但无奈水平不到家,没解决,有解决的可以在下方评论贴出,只求别太麻烦。
- 新大陆1(get_dummies())

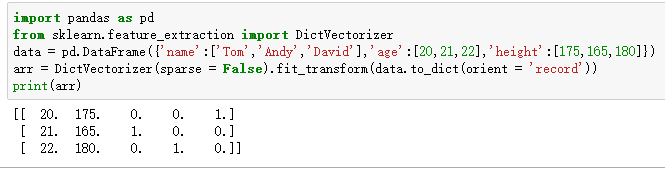
- 新大陆2(DictVectorizer)
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!