s3vm与tritraining_S4VM解析
1、S3VM
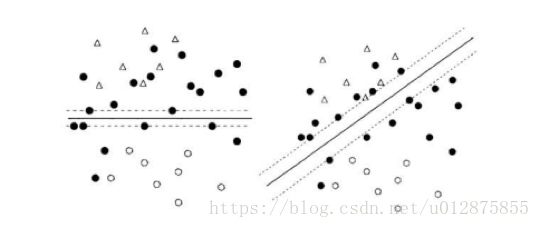
传统半监督支持向量机通过探索未标记数据来规范。调整决策边界,寻找最有的大间隔、低密度的超平面,比如S3VMs、TSVM等半监督SVM算法,如图所示,S3VM试图找到一个超平面,将有标记样本能够正确划分,且穿过特征空间中密度最低的区域;右图即是S3VM寻找的理想超平面。
S3VM的目标函数如下, 其中损失函数是hinge loss,限制条件是保证未标注样本的分布于标注样本分布一致。

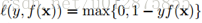
因为给定少量的有标注点和大量无标注的点,可能存在不止一个间隔较大的低密度分界线,如果只考虑一个,可能会造成较大的损失。
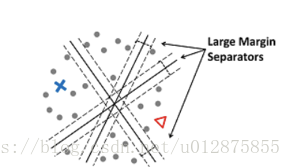
2、S4VM:
不同于S3VM,S4VM关注多个可能存在的低密度分界,使用多个超平面,是一种集成学习方法。

起目标函数如上:其中正则项用来保证不同超平面之间具有一定的差异性,如果两个超平面差异性越大,则预测相同的数目越小,则函数值越小,M为惩罚系数,M越大,则要求超平面的差异性越大。
3、实现方式
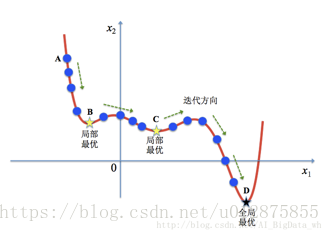
因为S4VM的目标函数是非凸的,因此可能存在多个局部最优解,如果使用梯度下降求解,则容易求解出局部最优解而非全局最优,基于词,论文提出两种求解全局最优的实现方式。
1、全局模拟退火算法
模拟退火算法的主要思想是,在求解过程中,每次随机出一个新的x_new ,计算f(x_new)是否优于f(x),如果f(x_new)优于f(x),则接受x_new, 否则将以一定概率接受当前解,此概率设置为与全局变量T(温度)有关,温度越高,则概率越大,在迭代过程中,温度逐渐下降,接受的概率也逐渐降低。在求解全局最小值的时候,接受的概率p=exp(-dE / T),其中dE = f(x_new) - f(x)。
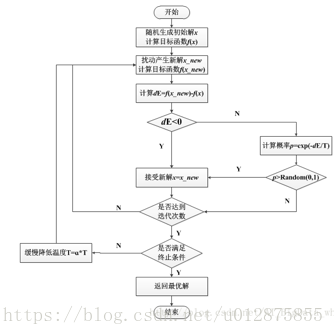
使用全局模拟退火算法求解S4VM的伪代码如下:


首先是随机出T个超平面,即给出T个超平面对未标注样本的预测值,在Localsearch中,根据预测值,即可以使用传统SVM学习到每个超平面的参数,对于每个超平面,在固定参数下,调整每个未标注样本的标签,使得目标函数最终收敛,则一次Localsearch完成,其他部分与模拟退火算法一致。
2、使用采样方式

随机选择出N个超平面,其中N > T
对于每个超平面,使用S3VM进行求解,得到N个S3VM超平面,每个超平面对未标记样本具有预测值,然后对所有样本进行聚类,聚类数目为T,在每个簇中,选择使得目标函数最小的一个超平面,这样会最终选出T个超平面。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!