Spark3.x入门到精通-阶段四(SparkSql详解javascala实战)
Spark SQL简介
Spark SQL 是 Spark 中的一个子模块,主要用于操作结构化数据。它具有以下特点:
- 能够将 SQL 查询与 Spark 程序无缝混合,允许您使用 SQL 或 DataFrame API 对结构化数据进行查询;
- 支持多种开发语言;
- 支持多达上百种的外部数据源,包括 Hive,Avro,Parquet,ORC,JSON 和 JDBC 等;
- 支持 HiveQL 语法以及 Hive SerDes 和 UDF,允许你访问现有的 Hive 仓库;
- 支持标准的 JDBC 和 ODBC 连接;
- 支持优化器,列式存储和代码生成等特性;
- 支持扩展并能保证容错。

DataFrame
为了支持结构化数据的处理,Spark SQL 提供了新的数据结构 DataFrame。DataFrame 是一个由具名列组成的数据集。它在概念上等同于关系数据库中的表或 R/Python 语言中的 data frame。 由于 Spark SQL 支持多种语言的开发,所以每种语言都定义了 DataFrame 的抽象,主要如下:
| 语言 | 主要抽象 |
|---|---|
| Scala | Dataset[T] & DataFrame (Dataset[Row] 的别名) |
| Java | Dataset[T] |
| Python | DataFrame |
| R | DataFrame |
DataFrame 对比 RDDs
DataFrame 和 RDDs 最主要的区别在于一个面向的是结构化数据,一个面向的是非结构化数据,它们内部的数据结构如下:
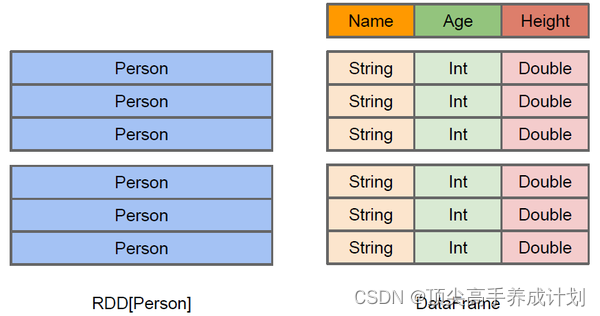
DataFrame 内部的有明确 Scheme 结构,即列名、列字段类型都是已知的,这带来的好处是可以减少数据读取以及更好地优化执行计划,从而保证查询效率。
DataFrame 和 RDDs 应该如何选择?
- 如果你想使用函数式编程而不是 DataFrame API,则使用 RDDs;
- 如果你的数据是非结构化的 (比如流媒体或者字符流),则使用 RDDs,
- 如果你的数据是结构化的 (如 RDBMS 中的数据) 或者半结构化的 (如日志),出于性能上的考虑,应优先使用 DataFrame。
DataFrame的使用
准备数据person.json
{"id": "1","name": "zhangsan","sorce": 90}
{"id": "2","name": "lishi","sorce": 100}
{"id": "3","name": "wanwu","sorce": 800}上传到hdfs
hadoop dfs -put person.json /下面是知道把数据变成什么类型的时候可以使用下面的方式
java版本
public class JavaDataFrameStart {public static void main(String[] args) {SparkConf sparkConf = new SparkConf();sparkConf.setAppName("JavaDataFrameStart").setMaster("local");SparkSession spark = SparkSession.builder().appName("Java Spark SQL basic example").config(sparkConf).getOrCreate();Dataset json = spark.read().json("hdfs://master:8020/person.json");json.show();spark.close();}
}
打包上传到服务器
bin/spark-submit --class com.zhang.one.JavaDataFrameStart --master yarn /home/bigdata/shell/original-sparkstart-1.0-SNAPSHOT.jar
scala版本
object ScalaDataFrame {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("ScalaDataFrame")conf.setMaster("local")val spark = SparkSession.builder().appName("Spark SQL basic example").config(conf).getOrCreate()val dataFrame: DataFrame = spark.read.json("data/person.json")dataFrame.show()//打印元数据信息dataFrame.printSchema()//查询指定的列dataFrame.select(dataFrame.col("name")).show()//对于分数加一操作dataFrame.select(dataFrame.col("sorce").plus(1)).show()dataFrame.groupBy(dataFrame.col("id")).count().show()spark.close()}
}RDD和DataFrame互相装换
准备数据person.txt
1 zhangsan 90
2 lishi 100
3 wanwu 20java版本
public class JavaStudent implements Serializable {private Integer id;private String name;private Integer score;public Integer getId() {return id;}public void setId(Integer id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public Integer getScore() {return score;}public void setScore(Integer score) {this.score = score;}@Overridepublic String toString() {return "JavaStudent{" +"id=" + id +", name='" + name + '\'' +", score=" + score +'}';}
}操作的代码
public class JavaRDDToDataframe {public static void main(String[] args) throws AnalysisException {SparkConf sparkConf = new SparkConf();sparkConf.setAppName("JavaRDDToDataframe").setMaster("local[2]");JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);//创建sparksql上下文SQLContext sqlContext = new SQLContext(javaSparkContext);JavaRDD personRDD = javaSparkContext.textFile("data/person.txt");JavaRDD studentJavaRDD = personRDD.map(new Function() {@Overridepublic JavaStudent call(String lineText) throws Exception {String[] initLine = lineText.split(" ");JavaStudent javaStudent = new JavaStudent();javaStudent.setId(Integer.valueOf(initLine[0]));javaStudent.setName(initLine[1]);javaStudent.setScore(Integer.valueOf(initLine[2]));return javaStudent;}});//将RDD转化成DataFrame,这里是通过反射的方式,返回的RDD数据要和对应类的属性名对应Dataset personDataFrame = sqlContext.createDataFrame(studentJavaRDD, JavaStudent.class);//对于DataFrame数据创建一张临时表personDataFrame.createTempView("student");//对于创建的表执行sql操作sqlContext.sql("select * from student").show();//将DataFrame装换成RDDJavaRDD resultRDD = personDataFrame.javaRDD().map(new Function() {@Overridepublic JavaStudent call(Row rowData) throws Exception {JavaStudent javaStudent = new JavaStudent();javaStudent.setId(rowData.getInt(0));javaStudent.setName(rowData.getString(1));javaStudent.setScore(rowData.getInt(2)+100);return javaStudent;}});resultRDD.foreach(new VoidFunction() {@Overridepublic void call(JavaStudent javaStudent) throws Exception {System.out.println(javaStudent);}});javaSparkContext.close();}
}
执行后的结果
+---+--------+-----+
| id| name|score|
+---+--------+-----+
| 1|zhangsan| 90|
| 2| lishi| 100|
| 3| wanwu| 20|
+---+--------+-----+JavaStudent{id=1, name='zhangsan', score=190}
JavaStudent{id=2, name='lishi', score=200}
JavaStudent{id=3, name='wanwu', score=120}scala版本
object ScalaRDDToDataFrame {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setMaster("local[2]").setAppName("ScalaRDDToDataFrame")val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()val lineRDD: RDD[String] = session.sparkContext.textFile("data/person.txt")//引入隐私装换(这里的session就是什么创建的session:SparkSession的变量)import session.implicits._//RDD装换成DataFrameval personDataFrame: DataFrame = lineRDD.map(_.split(" ")).map(item => {Student(item(0).toInt, item(1).trim, item(2).toInt)}).toDF()//创建一个临时视图personDataFrame.createTempView("person")val filterData: DataFrame = session.sql("select * from person where score >= 100")//把过滤出来的数据变成RDD处理val rdd: RDD[Row] = filterData.rdd//后面多次使用缓存下rdd.cache()//下面是根据ROW的位置得到数据rdd.map(row=>{Student(row.getInt(0),row.getString(1),row.getInt(2))}).foreach(println)//下面可以根据指定的列得到数据rdd.map(row=>{Student(row.getAs[Int]("id"),row.getAs[String]("name"),row.getAs[Int]("score"))}).foreach(println)session.stop()}
}case class Student(val id:Int,val name:String,val score:Int)这里的装换是动态数据装换(就是不知道要返回的是什么类的时候)
java版本
public class JavaRDDToDataFrameMethodTow {public static void main(String[] args) throws AnalysisException {SparkConf sparkConf = new SparkConf();sparkConf.setMaster("local").setAppName("JavaRDDToDataFrameMethodTow");JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);SQLContext sqlContext = new SQLContext(javaSparkContext);JavaRDD personInitRDD = javaSparkContext.textFile("data/person.txt");JavaRDD personRow = personInitRDD.map(new Function() {@Overridepublic Row call(String lineText) throws Exception {String[] strings = lineText.split(" ");//使用动态类型构建的时候,要保证返回的数据类型和后面的structFields类型一致return RowFactory.create(Integer.valueOf(strings[0]), strings[1], Integer.valueOf(strings[2]));}});//对于上面返回的RDD匹配字段元数据ArrayList structFields = new ArrayList<>();structFields.add(DataTypes.createStructField("id",DataTypes.IntegerType,true));structFields.add(DataTypes.createStructField("name",DataTypes.StringType,true));structFields.add(DataTypes.createStructField("score",DataTypes.IntegerType,true));StructType structType = DataTypes.createStructType(structFields);//构建RDD和structType的关系得到dataFrame,注意Dataset的别名就是DataFrameDataset dataFrame = sqlContext.createDataFrame(personRow, structType);dataFrame.createTempView("person");// sqlContext.sql("select * from person").show();Dataset targetDataFrame = sqlContext.sql("select * from person where score >=100");//dataFrame装换成RDDJavaRDD rowJavaRDD = targetDataFrame.javaRDD();rowJavaRDD.foreach(new VoidFunction() {@Overridepublic void call(Row row) throws Exception {System.out.println(row);}});javaSparkContext.close();}
}
scala版本
object ScalaRDDDataFrame {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("ScalaRDDDataFrame").setMaster("local")val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()//第一步得到数据val initDataRDD: RDD[String] = sparkSession.sparkContext.textFile("data/person.txt")//第二步装换成ROWval initDataRowRDD: RDD[Row] = initDataRDD.map(line => {val strings: Array[String] = line.split(" ")Row(Integer.valueOf(strings(0)), strings(1), Integer.valueOf(strings(2)))})//第三步建立对应的元数据信息val dataTypes=StructType(//这里的元数据类型和上面的数据要对应Array(StructField("id",DataTypes.IntegerType,true),StructField("name",DataTypes.StringType,true),StructField("score",DataTypes.IntegerType,true),))//第四步,得到DataFrameval dataFrame: DataFrame = sparkSession.createDataFrame(initDataRowRDD, dataTypes)dataFrame.createTempView("person")val filterDataFrame: DataFrame = sparkSession.sql("select * from person where score>=100")filterDataFrame.rdd.foreach(println)sparkSession.stop()}
}SparkSql外部数据源
读数据格式
所有读取 API 遵循以下调用格式:
// 格式
DataFrameReader.format(...).option("key", "value").schema(...).load()// 示例
spark.read.format("csv")
.option("mode", "FAILFAST") // 读取模式
.option("inferSchema", "true") // 是否自动推断 schema
.option("path", "path/to/file(s)") // 文件路径
.schema(someSchema) // 使用预定义的 schema
.load()读取模式有以下三种可选项:
| 读模式 | 描述 |
|---|---|
permissive | 当遇到损坏的记录时,将其所有字段设置为 null,并将所有损坏的记录放在名为 _corruption t_record 的字符串列中 |
dropMalformed | 删除格式不正确的行 |
failFast | 遇到格式不正确的数据时立即失败 |
写数据格式
// 格式
DataFrameWriter.format(...).option(...).partitionBy(...).bucketBy(...).sortBy(...).save()//示例
dataframe.write.format("csv")
.option("mode", "OVERWRITE") //写模式
.option("dateFormat", "yyyy-MM-dd") //日期格式
.option("path", "path/to/file(s)")
.save()写数据模式有以下四种可选项:
| Scala/Java | 描述 |
|---|---|
SaveMode.ErrorIfExists | 如果给定的路径已经存在文件,则抛出异常,这是写数据默认的模式 |
SaveMode.Append | 数据以追加的方式写入 |
SaveMode.Overwrite | 数据以覆盖的方式写入 |
SaveMode.Ignore | 如果给定的路径已经存在文件,则不做任何操作 |
CSV
自动推断类型读取读取示例:
spark.read.format("csv")
.option("header", "false") // 文件中的第一行是否为列的名称
.option("mode", "FAILFAST") // 是否快速失败
.option("inferSchema", "true") // 是否自动推断 schema
.load("/usr/file/csv/dept.csv")
.show()使用预定义类型:
import org.apache.spark.sql.types.{StructField, StructType, StringType,LongType}
//预定义数据格式
val myManualSchema = new StructType(Array(StructField("deptno", LongType, nullable = false),StructField("dname", StringType,nullable = true),StructField("loc", StringType,nullable = true)
))
spark.read.format("csv")
.option("mode", "FAILFAST")
.schema(myManualSchema)
.load("/usr/file/csv/dept.csv")
.show()写入CSV文件
df.write.format("csv").mode("overwrite").save("/tmp/csv/dept2")也可以指定具体的分隔符:
df.write.format("csv").mode("overwrite").option("sep", "\t").save("/tmp/csv/dept2")DataFrame的load和save
可以实现不同数据之间的转换
java版本
public class JavaJsonParquet {public static void main(String[] args) {SparkConf sparkConf = new SparkConf();sparkConf.setMaster("local").setAppName("JavaJsonParquet");JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);SQLContext sqlContext = new SQLContext(javaSparkContext);//加载指定的Json文件直接得到RowDataset jsonDataFrame = sqlContext.read().format("json").load("data/person.json");jsonDataFrame.show();//得到的数据保存为parquetjsonDataFrame.write().format("parquet").save("data/person.parquet");javaSparkContext.close();}
}
scala版本
object ScalaJsonParquet {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setMaster("local").setAppName("ScalaJsonParquet")val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()session.read.format("json").load("data/person.json").write.format("parquet").save("data/parquet")session.stop()}
}加入写入模式的操作
java版本
public class JavaJsonParquet {public static void main(String[] args) {SparkConf sparkConf = new SparkConf();sparkConf.setMaster("local").setAppName("JavaJsonParquet");JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);SQLContext sqlContext = new SQLContext(javaSparkContext);//加载指定的Json文件直接得到RowDataset jsonDataFrame = sqlContext.read().format("json").load("data/person.json");jsonDataFrame.show();//得到的数据保存为parquet,下面是使用追加的方式jsonDataFrame.write().mode(SaveMode.Append).format("parquet").save("data/person.parquet");javaSparkContext.close();}
}
scala版本
object ScalaJsonParquet {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setMaster("local[1]").setAppName("ScalaJsonParquet")val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//使用追加的方式写入session.read.format("json").load("data/person.json").write.mode(SaveMode.Append).format("parquet").save("data/parquet")session.stop()}
}json和parquet基本操作
由于比较简单这里就使用scala了
object ScalaReadParquet {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("ScalaReadParquet").setMaster("local")val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()session.read.parquet("data/person.parquet").show()session.read.json("data/person.json").show()session.stop()}
}读取JSON文件
spark.read.format("json").option("mode", "FAILFAST").load("/usr/file/json/dept.json").show(5)需要注意的是:默认不支持一条数据记录跨越多行 (如下),可以通过配置 multiLine 为 true 来进行更改,其默认值为 false。
// 默认支持单行
{"DEPTNO": 10,"DNAME": "ACCOUNTING","LOC": "NEW YORK"}//默认不支持多行
{"DEPTNO": 10,"DNAME": "ACCOUNTING","LOC": "NEW YORK"
}写入JSON文件
df.write.format("json").mode("overwrite").save("/tmp/spark/json/dept")两种获取json数据执行join操作
准备数据person.json
{"id": "1","name": "zhangsan","courceid": 1}
{"id": "2","name": "lishi","courceid": 2}
{"id": "3","name": "wanwu","courceid": 1}java版本
public class JavaJsonJoin {public static void main(String[] args) throws AnalysisException {SparkConf sparkConf = new SparkConf();sparkConf.setMaster("local").setAppName("JavaJsonJoin");JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);SQLContext sqlContext = new SQLContext(javaSparkContext);//得到PersonDataFrameDataset personDataFrame = sqlContext.read().json("data/person.json");personDataFrame.createTempView("person");//里面保存的是json字符串ArrayList courseJson = new ArrayList<>();courseJson.add("{\"id\":\"1\",\"score\":\"90\"}");courseJson.add("{\"id\":\"2\",\"score\":\"190\"}");courseJson.add("{\"id\":\"3\",\"score\":\"190\"}");JavaRDD courceRDD = javaSparkContext.parallelize(courseJson);//根据JavaRDD得到DataFrameDataset courceDataFrame = sqlContext.read().json(courceRDD);courceDataFrame.createTempView("cource");//join两张表sqlContext.sql("select * from person left join cource on person.courceid=cource.id").show();javaSparkContext.close();}
}
得到的结果是
+--------+---+--------+---+-----+
|courceid| id| name| id|score|
+--------+---+--------+---+-----+
| 1| 1|zhangsan| 1| 90|
| 1| 3| wanwu| 1| 90|
| 2| 2| lishi| 2| 190|
+--------+---+--------+---+-----+scala版本
object ScalaJsonJoin {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setMaster("local").setAppName("ScalaJsonJoin")val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()//得到person的临时表session.read.json("data/person.json").createTempView("person")val courceJsonString: Array[String] = Array("{\"id\":\"1\",\"score\":\"90\"}","{\"id\":\"2\",\"score\":\"190\"}","{\"id\":\"3\",\"score\":\"190\"}")//得到cource的临时表val courceRDD: RDD[String] = session.sparkContext.parallelize(courceJsonString)session.read.json(courceRDD).createTempView("cource")session.sql("select * from person left join cource on person.courceid=cource.id").show()session.close()}
}输出结果
+--------+---+--------+---+-----+
|courceid| id| name| id|score|
+--------+---+--------+---+-----+
| 1| 1|zhangsan| 1| 90|
| 1| 3| wanwu| 1| 90|
| 2| 2| lishi| 2| 190|
+--------+---+--------+---+-----+Hbase案例
pojo
@Data
public class VirtualPojo {private String ORDER_ID;private String STARTING_LNG;private String STARTING_LAT;}HbaseUtil
public class HbaseUtil {private static Connection connection = null;public HbaseUtil(){if(connection==null||connection.isClosed()){Configuration config = HBaseConfiguration.create();config.set("hbase.zookeeper.quorum", "hadoop102");try {connection=ConnectionFactory.createConnection(config);} catch (IOException e) {e.printStackTrace();}}}public Connection getConnection(){return connection;}/*** 创建表* @param tableName* @param columeFamily*/public void createTable(String tableName,String columeFamily){try {TableName tableName1 = TableName.valueOf(tableName);Admin admin = connection.getAdmin();if (admin.tableExists(tableName1)) {admin.disableTable(tableName1);admin.deleteTable(tableName1);}HTableDescriptor hTableDescriptor = new HTableDescriptor(tableName1);HColumnDescriptor hColumnDescriptor = new HColumnDescriptor(columeFamily);hTableDescriptor.addFamily(hColumnDescriptor);admin.createTable(hTableDescriptor);} catch (IOException e) {e.printStackTrace();}}/*** 生成put* @param rowKey* @param columeFamily* @param dataColumeAndValue* @return*/public Put createPut(String rowKey, String columeFamily, Map dataColumeAndValue){Put put = new Put(rowKey.getBytes());Set> entries = dataColumeAndValue.entrySet();for (Map.Entry entry : entries) {put.addColumn(columeFamily.getBytes(),entry.getKey().getBytes(),entry.getValue().getBytes());}return put;}public Table getTable(String tableName){Table table = null;try {table = connection.getTable(TableName.valueOf(tableName));} catch (IOException e) {e.printStackTrace();}return table;}public List getRest(String tableName,Class clazz) throws Exception {Table table = null;Scan scanner = null;List restList = null;try {restList = new ArrayList<>();table = getTable(tableName);scanner = new Scan();try (ResultScanner rs = table.getScanner(scanner)) {for (Result r : rs) {//反射形成对象//获取字节码对象类的所有字段属性Field[] fields = clazz.getDeclaredFields();T t = clazz.newInstance();NavigableMap familyMap = r.getFamilyMap("info".getBytes());for (Map.Entry entry : familyMap.entrySet()) {String colName = Bytes.toString(entry.getKey());String colValue = Bytes.toString(entry.getValue());for (Field field : fields) {String fieldName = field.getName();field.setAccessible(true);if (fieldName.equalsIgnoreCase(colName)) {String fieldType = field.getType().toString();if (fieldType.equalsIgnoreCase("class java.lang.String")) {field.set(t, colValue);} else if (fieldType.equalsIgnoreCase("class java.lang.Integer")){field.set(t, Integer.parseInt(colValue));} else if (fieldType.equalsIgnoreCase("class java.lang.Long")){field.set(t, Long.parseLong(colValue));} else if (fieldType.equalsIgnoreCase("class java.lang.Double")) {field.set(t, Double.parseDouble(colValue));} else if (fieldType.equalsIgnoreCase("class java.util.Date")) {SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");field.set(t, sdf.format(new Date(Long.parseLong(colValue + "000"))));} else if (fieldType.equalsIgnoreCase("java.lang.Boolean")) {field.set(t, Boolean.parseBoolean(colValue));} else {field.set(t, null);}}}}restList.add(t);}}} catch (Exception e) {e.printStackTrace();}return restList;}public static void main(String[] args) throws IOException {HbaseUtil hbaseUtil = new HbaseUtil();try {List rest = hbaseUtil.getRest("hai_kou_virtual_parkp", VirtualPojo.class);for (VirtualPojo virtualPojo : rest) {System.out.println(virtualPojo);}} catch (Exception e) {e.printStackTrace();}}/*** 根据表名开始时间和结束时间查询轨迹** @param tableName* @param orderId* @param startTimestampe* @param endTimestampe* @return*/public List getRest(String tableName, String orderId,String startTimestampe, String endTimestampe, Class clazz) throws Exception {Table table = null;Scan scanner = null;List restList = null;try {restList = new ArrayList<>();table = getTable(tableName);String startRowKey = orderId + "_" + startTimestampe;String endRowKey = orderId + "_" + endTimestampe;scanner = new Scan();scanner.setStartRow(startRowKey.getBytes());scanner.setStopRow(endRowKey.getBytes());try (ResultScanner rs = table.getScanner(scanner)) {for (Result r : rs) {//反射形成对象//获取字节码对象类的所有字段属性Field[] fields = clazz.getDeclaredFields();T t = clazz.newInstance();NavigableMap familyMap = r.getFamilyMap(Constants.DEFAULT_FAMILY.getBytes());for (Map.Entry entry : familyMap.entrySet()) {String colName = Bytes.toString(entry.getKey());String colValue = Bytes.toString(entry.getValue());for (Field field : fields) {String fieldName = field.getName();field.setAccessible(true);if (fieldName.equalsIgnoreCase(colName)) {String fieldType = field.getType().toString();if (fieldType.equalsIgnoreCase("class java.lang.String")) {field.set(t, colValue);} else if (fieldType.equalsIgnoreCase("class java.lang.Integer")){field.set(t, Integer.parseInt(colValue));} else if (fieldType.equalsIgnoreCase("class java.lang.Long")){field.set(t, Long.parseLong(colValue));} else if (fieldType.equalsIgnoreCase("class java.lang.Double")) {field.set(t, Double.parseDouble(colValue));} else if (fieldType.equalsIgnoreCase("class java.util.Date")) {SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");field.set(t, sdf.format(new Date(Long.parseLong(colValue + "000"))));} else if (fieldType.equalsIgnoreCase("java.lang.Boolean")) {field.set(t, Boolean.parseBoolean(colValue));} else {field.set(t, null);}}}}restList.add(t);}}} catch (Exception e) {e.printStackTrace();}return restList;}
} SparkAnalyHbase
object SparkAnalyHbase {private val core: H3Core = H3Core.newInstance()def uberh3(lat: Double, lng: Double, res: Int): String = {core.geoToH3Address(lat, lng, res)}def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName(this.getClass.getSimpleName).setMaster("local")//读取hbase的时候要有网络传输所以要序列化.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer").registerKryoClasses(Array(classOf[ImmutableBytesWritable], classOf[Result]))val sparlSql: SparkSession = SparkSession.builder().config(conf).getOrCreate()val sparkContext: SparkContext = sparlSql.sparkContext//开始处理hbase,是根据hfile来读取分析val scanner = new Scanval hbaseConfig: Configuration = HBaseConfiguration.create//ORDER_ID String,CITY_ID String,STARTING_LNG String,STARTING_LAT Stringscanner.addFamily("info".getBytes)scanner.addColumn("info".getBytes, "ORDER_ID".getBytes)scanner.addColumn("info".getBytes, "CITY_ID".getBytes)scanner.addColumn("info".getBytes, "STARTING_LNG".getBytes)scanner.addColumn("info".getBytes, "STARTING_LAT".getBytes)import org.apache.hadoop.hbase.protobuf.ProtobufUtilval proto = ProtobufUtil.toScan(scanner)val scanToString = Base64.encodeBytes(proto.toByteArray)import org.apache.hadoop.hbase.mapreduce.TableInputFormat//设置hbase表hbaseConfig.set(TableInputFormat.INPUT_TABLE, "hai_kou_order_topic")hbaseConfig.set(TableInputFormat.SCAN, scanToString)hbaseConfig.set("hbase.zookeeper.quorum", "hadoop102")val hbaseRDD: RDD[(ImmutableBytesWritable, Result)] = sparkContext.newAPIHadoopRDD(hbaseConfig, classOf[TableInputFormat],classOf[ImmutableBytesWritable], classOf[Result])//得到的结果装换成RDDval orderRDD: RDD[Row] = hbaseRDD.mapPartitions(iterator => {val newItems = new ListBuffer[Row]()var row: Row = null;while (iterator.hasNext) {val result = iterator.next()._2row = Row.fromSeq(Seq(new String(result.getValue("info".getBytes, "ORDER_ID".getBytes)),new String(result.getValue("info".getBytes, "CITY_ID".getBytes)),new String(result.getValue("info".getBytes, ("STARTING_LNG".getBytes))),new String(result.getValue("info".getBytes, "STARTING_LAT".getBytes))))newItems.append(row)}Iterator(newItems)}).flatMap(item => item)//field里面指定的类型要和Row里面的类型保持一致val fields = Array(new StructField("ORDER_ID", StringType),new StructField("CITY_ID", StringType),new StructField("STARTING_LNG", StringType),new StructField("STARTING_LAT", StringType))val structType = new StructType(fields)val orderDataFrame: DataFrame = sparlSql.createDataFrame(orderRDD, structType)//这里获取到了数据// orderDataFrame.show()//这里使用自定义函数sparlSql.udf.register("locationToH3", uberh3 _)orderDataFrame.createTempView("order")//这里根据地理坐标得到Uberh3val selectOrderSql ="""|select ORDER_ID,CITY_ID,STARTING_LNG,STARTING_LAT|,locationToH3(STARTING_LAT,STARTING_LNG,12) uberh3address| from order|""".stripMarginval orderInfoAndUberH3Address: DataFrame = sparlSql.sql(selectOrderSql)orderInfoAndUberH3Address.createTempView("orderInfoAndUberH3Address")//选出Uberh3索引里面大于10的作为虚拟车站import org.apache.spark.sql.functions._import sparlSql.implicits._val groupUberh3: Dataset[Row] = orderInfoAndUberH3Address.groupBy("uberh3address").count().filter("count>3")groupUberh3.createTempView("groupuberh3")//这里使用得到的uberh3得到订单的坐标val virtualPark: Dataset[Row] = sparlSql.sql(s"""|select|ORDER_ID,|CITY_ID,|STARTING_LNG,|STARTING_LAT,|row_number() over(partition by orderInfoAndUberH3Address.uberh3address order by STARTING_LNG,STARTING_LAT asc) rn|from orderInfoAndUberH3Address join groupuberh3 on orderInfoAndUberH3Address.uberh3address = groupuberh3.uberh3address|""".stripMargin).filter("rn<=1")//这里就是得到的虚拟车站的信息val resultShema = new StructType(Array(StructField("ORDER_ID", StringType, true),StructField("STARTING_LNG", StringType, true),StructField("STARTING_LAT", StringType, true)))val resultDataFrame: DataFrame = virtualPark.select("ORDER_ID", "STARTING_LNG", "STARTING_LAT")//保存数据val hbConf = HBaseConfiguration.createhbConf.set("hbase.zookeeper.quorum", "hadoop102")hbConf.set("hbase.zookeeper.property.clientPort", "2181")//这里是要输出到的表hbConf.set(TableOutputFormat.OUTPUT_TABLE, "hai_kou_virtual_parkp")val job = new Job(hbConf);//ImmutableBytesWritable理解为hbase表中的rowkey(ImmutableBytesWritable,Result)job.setOutputKeyClass(classOf[ImmutableBytesWritable])job.setOutputValueClass(classOf[Result])job.setOutputFormatClass(classOf[TableOutputFormat[ImmutableBytesWritable]])val target: RDD[(ImmutableBytesWritable, Put)] = resultDataFrame.rdd.mapPartitions(iterator => {val newItems = new ListBuffer[(ImmutableBytesWritable, Put)]()while (iterator.hasNext) {val next: Row = iterator.next()val put = new Put(next.getString(0).getBytes)//1.设置订单IDput.addColumn("info".getBytes,"ORDER_ID".getBytes,next.getAs[String]("ORDER_ID").getBytes)//2.设置经度put.addColumn("info".getBytes, "STARTING_LNG".getBytes,next.getAs[String]("STARTING_LNG").getBytes)//3.设置维度put.addColumn("info".getBytes, "STARTING_LAT".getBytes,next.getAs[String]("STARTING_LAT").getBytes)//6.添加到集合中newItems.append((new ImmutableBytesWritable, put))}Iterator(newItems)}).flatMap(item => item)// 这里得到自己写的hbase工具类创建表val hba = new HbaseUtilhba.createTable( "hai_kou_virtual_parkp","info")target.saveAsNewAPIHadoopDataset(job.getConfiguration)sparkContext.stop()sparlSql.stop()sparlSql.close()}
}SQL Databases
Spark 同样支持与传统的关系型数据库进行数据读写。但是 Spark 程序默认是没有提供数据库驱动的,所以在使用前需要将对应的数据库驱动上传到安装目录下的 jars 目录中。下面示例使用的是 Mysql 数据库,使用前需要将对应的 mysql-connector-java-x.x.x.jar 上传到 jars 目录下。
读取数据
读取全表数据示例如下,这里的 help_keyword 是 mysql 内置的字典表,只有 help_keyword_id 和 name 两个字段。
spark.read
.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver") //驱动
.option("url", "jdbc:mysql://127.0.0.1:3306/mysql") //数据库地址
.option("dbtable", "help_keyword") //表名
.option("user", "root").option("password","root").load().show(10)从查询结果读取数据:
val pushDownQuery = """(SELECT * FROM help_keyword WHERE help_keyword_id <20) AS help_keywords"""
spark.read.format("jdbc")
.option("url", "jdbc:mysql://127.0.0.1:3306/mysql")
.option("driver", "com.mysql.jdbc.Driver")
.option("user", "root").option("password", "root")
.option("dbtable", pushDownQuery)
.load().show()//输出
+---------------+-----------+
|help_keyword_id| name|
+---------------+-----------+
| 0| <>|
| 1| ACTION|
| 2| ADD|
| 3|AES_DECRYPT|
| 4|AES_ENCRYPT|
| 5| AFTER|
| 6| AGAINST|
| 7| AGGREGATE|
| 8| ALGORITHM|
| 9| ALL|
| 10| ALTER|
| 11| ANALYSE|
| 12| ANALYZE|
| 13| AND|
| 14| ARCHIVE|
| 15| AREA|
| 16| AS|
| 17| ASBINARY|
| 18| ASC|
| 19| ASTEXT|
+---------------+-----------+也可以使用如下的写法进行数据的过滤:
val props = new java.util.Properties
props.setProperty("driver", "com.mysql.jdbc.Driver")
props.setProperty("user", "root")
props.setProperty("password", "root")
val predicates = Array("help_keyword_id < 10 OR name = 'WHEN'") //指定数据过滤条件
spark.read.jdbc("jdbc:mysql://127.0.0.1:3306/mysql", "help_keyword", predicates, props).show() //输出:
+---------------+-----------+
|help_keyword_id| name|
+---------------+-----------+
| 0| <>|
| 1| ACTION|
| 2| ADD|
| 3|AES_DECRYPT|
| 4|AES_ENCRYPT|
| 5| AFTER|
| 6| AGAINST|
| 7| AGGREGATE|
| 8| ALGORITHM|
| 9| ALL|
| 604| WHEN|
+---------------+-----------+可以使用 numPartitions 指定读取数据的并行度:
option("numPartitions", 10)在这里,除了可以指定分区外,还可以设置上界和下界,任何小于下界的值都会被分配在第一个分区中,任何大于上界的值都会被分配在最后一个分区中。
val colName = "help_keyword_id" //用于判断上下界的列
val lowerBound = 300L //下界
val upperBound = 500L //上界
val numPartitions = 10 //分区综述
val jdbcDf = spark.read.jdbc("jdbc:mysql://127.0.0.1:3306/mysql","help_keyword",colName,lowerBound,upperBound,numPartitions,props)想要验证分区内容,可以使用 mapPartitionsWithIndex 这个算子,代码如下:
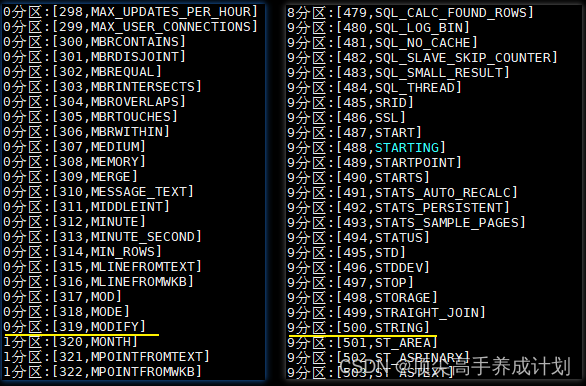
jdbcDf.rdd.mapPartitionsWithIndex((index, iterator) => {val buffer = new ListBuffer[String]while (iterator.hasNext) {buffer.append(index + "分区:" + iterator.next())}buffer.toIterator
}).foreach(println)执行结果如下:help_keyword 这张表只有 600 条左右的数据,本来数据应该均匀分布在 10 个分区,但是 0 分区里面却有 319 条数据,这是因为设置了下限,所有小于 300 的数据都会被限制在第一个分区,即 0 分区。同理所有大于 500 的数据被分配在 9 分区,即最后一个分区。
写入数据
val df = spark.read.format("json").load("/usr/file/json/emp.json")
df.write
.format("jdbc")
.option("url", "jdbc:mysql://127.0.0.1:3306/mysql")
.option("user", "root").option("password", "root")
.option("dbtable", "emp")
.save()数据读写高级特性
并行读
多个 Executors 不能同时读取同一个文件,但它们可以同时读取不同的文件。这意味着当您从一个包含多个文件的文件夹中读取数据时,这些文件中的每一个都将成为 DataFrame 中的一个分区,并由可用的 Executors 并行读取。
并行写
写入的文件或数据的数量取决于写入数据时 DataFrame 拥有的分区数量。默认情况下,每个数据分区写一个文件。
分区写入
分区和分桶这两个概念和 Hive 中分区表和分桶表是一致的。都是将数据按照一定规则进行拆分存储。需要注意的是 partitionBy 指定的分区和 RDD 中分区不是一个概念:这里的分区表现为输出目录的子目录,数据分别存储在对应的子目录中。
val df = spark.read.format("json").load("/usr/file/json/emp.json")
df.write.mode("overwrite").partitionBy("deptno").save("/tmp/spark/partitions")输出结果如下:可以看到输出被按照部门编号分为三个子目录,子目录中才是对应的输出文件。

分桶写入
分桶写入就是将数据按照指定的列和桶数进行散列,目前分桶写入只支持保存为表,实际上这就是 Hive 的分桶表。
val numberBuckets = 10
val columnToBucketBy = "empno"
df.write.format("parquet").mode("overwrite")
.bucketBy(numberBuckets, columnToBucketBy).saveAsTable("bucketedFiles")文件大小管理
如果写入产生小文件数量过多,这时会产生大量的元数据开销。Spark 和 HDFS 一样,都不能很好的处理这个问题,这被称为“small file problem”。同时数据文件也不能过大,否则在查询时会有不必要的性能开销,因此要把文件大小控制在一个合理的范围内。
在上文我们已经介绍过可以通过分区数量来控制生成文件的数量,从而间接控制文件大小。Spark 2.2 引入了一种新的方法,以更自动化的方式控制文件大小,这就是 maxRecordsPerFile 参数,它允许你通过控制写入文件的记录数来控制文件大小。
// Spark 将确保文件最多包含 5000 条记录
df.write.option(“maxRecordsPerFile”, 5000)可选配置附录
CSV读写可选配置
| 读\写操作 | 配置项 | 可选值 | 默认值 | 描述 |
|---|---|---|---|---|
| Both | seq | 任意字符 | ,(逗号) | 分隔符 |
| Both | header | true, false | false | 文件中的第一行是否为列的名称。 |
| Read | escape | 任意字符 | \ | 转义字符 |
| Read | inferSchema | true, false | false | 是否自动推断列类型 |
| Read | ignoreLeadingWhiteSpace | true, false | false | 是否跳过值前面的空格 |
| Both | ignoreTrailingWhiteSpace | true, false | false | 是否跳过值后面的空格 |
| Both | nullValue | 任意字符 | “” | 声明文件中哪个字符表示空值 |
| Both | nanValue | 任意字符 | NaN | 声明哪个值表示 NaN 或者缺省值 |
| Both | positiveInf | 任意字符 | Inf | 正无穷 |
| Both | negativeInf | 任意字符 | -Inf | 负无穷 |
| Both | compression or codec | None, uncompressed, bzip2, deflate, gzip, lz4, or snappy | none | 文件压缩格式 |
| Both | dateFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 | yyyy-MM-dd | 日期格式 |
| Both | timestampFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 | yyyy-MMdd’T’HH:mm:ss.SSSZZ | 时间戳格式 |
| Read | maxColumns | 任意整数 | 20480 | 声明文件中的最大列数 |
| Read | maxCharsPerColumn | 任意整数 | 1000000 | 声明一个列中的最大字符数。 |
| Read | escapeQuotes | true, false | true | 是否应该转义行中的引号。 |
| Read | maxMalformedLogPerPartition | 任意整数 | 10 | 声明每个分区中最多允许多少条格式错误的数据,超过这个值后格式错误的数据将不会被读取 |
| Write | quoteAll | true, false | false | 指定是否应该将所有值都括在引号中,而不只是转义具有引号字符的值。 |
| Read | multiLine | true, false | false | 是否允许每条完整记录跨域多行 |
JSON读写可选配置
| 读\写操作 | 配置项 | 可选值 | 默认值 |
|---|---|---|---|
| Both | compression or codec | None, uncompressed, bzip2, deflate, gzip, lz4, or snappy | none |
| Both | dateFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 | yyyy-MM-dd |
| Both | timestampFormat | 任何能转换为 Java 的 SimpleDataFormat 的字符串 | yyyy-MMdd’T’HH:mm:ss.SSSZZ |
| Read | primitiveAsString | true, false | false |
| Read | allowComments | true, false | false |
| Read | allowUnquotedFieldNames | true, false | false |
| Read | allowSingleQuotes | true, false | true |
| Read | allowNumericLeadingZeros | true, false | false |
| Read | allowBackslashEscapingAnyCharacter | true, false | false |
| Read | columnNameOfCorruptRecord | true, false | Value of spark.sql.column&NameOf |
| Read | multiLine | true, false | false |
数据库读写可选配置
| 属性名称 | 含义 |
|---|---|
| url | 数据库地址 |
| dbtable | 表名称 |
| driver | 数据库驱动 |
| partitionColumn, lowerBound, upperBoun | 分区总数,上界,下界 |
| numPartitions | 可用于表读写并行性的最大分区数。如果要写的分区数量超过这个限制,那么可以调用 coalesce(numpartition) 重置分区数。 |
| fetchsize | 每次往返要获取多少行数据。此选项仅适用于读取数据。 |
| batchsize | 每次往返插入多少行数据,这个选项只适用于写入数据。默认值是 1000。 |
| isolationLevel | 事务隔离级别:可以是 NONE,READ_COMMITTED, READ_UNCOMMITTED,REPEATABLE_READ 或 SERIALIZABLE,即标准事务隔离级别。 默认值是 READ_UNCOMMITTED。这个选项只适用于数据读取。 |
| createTableOptions | 写入数据时自定义创建表的相关配置 |
| createTableColumnTypes | 写入数据时自定义创建列的列类型 |
SparkSql内置函数
简单聚合
数据准备
{"id": "1","name": "zhangsan","courceid": 1}
{"id": "2","name": "lishi","courceid": 2}
{"id": "3","name": "wanwu","courceid": 1}读取文件
object ScalaHanshu {def main(args: Array[String]): Unit = {val c = new SparkConf()c.setAppName("ScalaHanshu").setMaster("local[2]")//使用函数之前要引入隐私装换import org.apache.spark.sql.functions._val session: SparkSession = SparkSession.builder().config(c).getOrCreate()session.read.json("data/person.json").show()session.close()}
}count
session.read.json("data/person.json").select(count("name")).show()countDistinct
session.read.json("data/person.json").select(countDistinct("courceid")).show()approx_count_distinct
通常在使用大型数据集时,你可能关注的只是近似值而不是准确值,这时可以使用 approx_count_distinct 函数,并可以使用第二个参数指定最大允许误差。
session.read.json("data/person.json").select(approx_count_distinct ("courceid",0.1)).show()first & last
获取 DataFrame 中指定列的第一个值或者最后一个值。
session.read.json("data/person.json").select(first("courceid"),last("courceid")).show()min & max
获取 DataFrame 中指定列的最小值或者最大值。
empDF.select(min("sal"),max("sal")).show()sum & sumDistinct
求和以及求指定列所有不相同的值的和。
empDF.select(sum("sal")).show()
empDF.select(sumDistinct("sal")).show()avg
内置的求平均数的函数。
empDF.select(avg("sal")).show()数学函数
Spark SQL 中还支持多种数学聚合函数,用于通常的数学计算,以下是一些常用的例子:
// 1.计算总体方差、均方差、总体标准差、样本标准差
empDF.select(var_pop("sal"), var_samp("sal"), stddev_pop("sal"), stddev_samp("sal")).show()// 2.计算偏度和峰度
empDF.select(skewness("sal"), kurtosis("sal")).show()// 3. 计算两列的皮尔逊相关系数、样本协方差、总体协方差。
empDF.select(corr("empno", "sal"), covar_samp("empno", "sal"),covar_pop("empno", "sal")).show()聚合数据到集合
empDF.agg(collect_set("job"), collect_list("ename")).show()分组聚合
简单分组
empDF.groupBy("deptno", "job").count().show()
//等价 SQL
spark.sql("SELECT deptno, job, count(*) FROM emp GROUP BY deptno, job").show()分组聚合
empDF.groupBy("deptno").agg(count("ename").alias("人数"), sum("sal").alias("总工资")).show()
// 等价语法
empDF.groupBy("deptno").agg("ename"->"count","sal"->"sum").show()
// 等价 SQL
spark.sql("SELECT deptno, count(ename) ,sum(sal) FROM emp GROUP BY deptno").show()自定义函数
UDF(单行输入一个输出)
object ScalaHanshu {//定义一个函数def myudf(name:String):Int={name.length}def main(args: Array[String]): Unit = {val c = new SparkConf()c.setAppName("ScalaHanshu").setMaster("local[2]")import org.apache.spark.sql.functions._val session: SparkSession = SparkSession.builder().config(c).getOrCreate()session.read.json("data/person.json").createTempView("person")//注册函数//第一种方式函数已经定义出来了,后面就是函数名加一个空格然后一个下划线session.udf.register("myudf",myudf _)//第二种就是直接定义一个匿名内部类session.udf.register("myudf2",(name:String)=>name.length)session.sql("select name,myudf(name),myudf2(name) from person").show()session.close()}
}UDAF(多个输入一个输出)
聚合函数
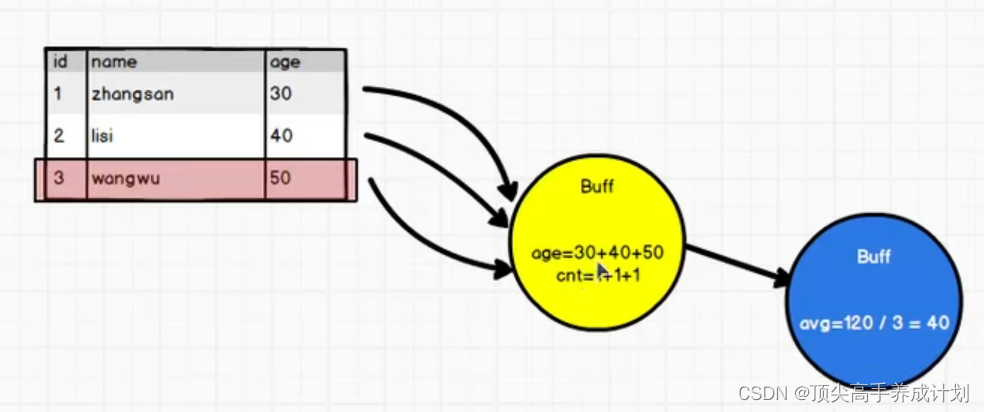
上面是一个好理解的图,我们自己定义一个求总数的聚合函数
object MyUDAF extends UserDefinedAggregateFunction {//这里是输入数据,定义它输入数据的类型override def inputSchema: StructType = {StructType(Array(StructField("", StringType)))}//这里是中间缓存区的类型override def bufferSchema: StructType = {StructType(Array(StructField("", LongType)))}//这里是输出数据的类型override def dataType: DataType = DoubleType// 此函数是否始终在相同输入上返回相同的输出,通常为 trueoverride def deterministic: Boolean = true//缓冲区的初始化操作override def initialize(buffer: MutableAggregationBuffer): Unit = {buffer(0)=0L}//同一个分区的reduce操作,buffer是缓存区的数据,input表示迭代过来的值override def update(buffer: MutableAggregationBuffer, input: Row): Unit = {if (!input.isNullAt(0)) {//由于我们定义的是count的作用,所以每来一条是数据那么就加一buffer(0) = buffer.getLong(0) + 1L}}//不同分区的数据进行聚合操作override def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {buffer1(0)=buffer1.getLong(0) + buffer2.getLong(0)}//计算最终的输出值,这里就是中间的结果怎么结算得到最后输出的结果override def evaluate(buffer: Row): Any = {buffer.getLong(0).toDouble}
}使用
object ScalaHanshu {//定义一个函数def myudf(name:String):Int={name.length}def main(args: Array[String]): Unit = {val c = new SparkConf()c.setAppName("ScalaHanshu").setMaster("local[2]")import org.apache.spark.sql.functions._val session: SparkSession = SparkSession.builder().config(c).getOrCreate()session.read.json("data/person.json").createTempView("person")session.udf.register("mycount", MyUDAF)session.sql("select mycount(courceid) as result from person group by courceid").show()session.close()}
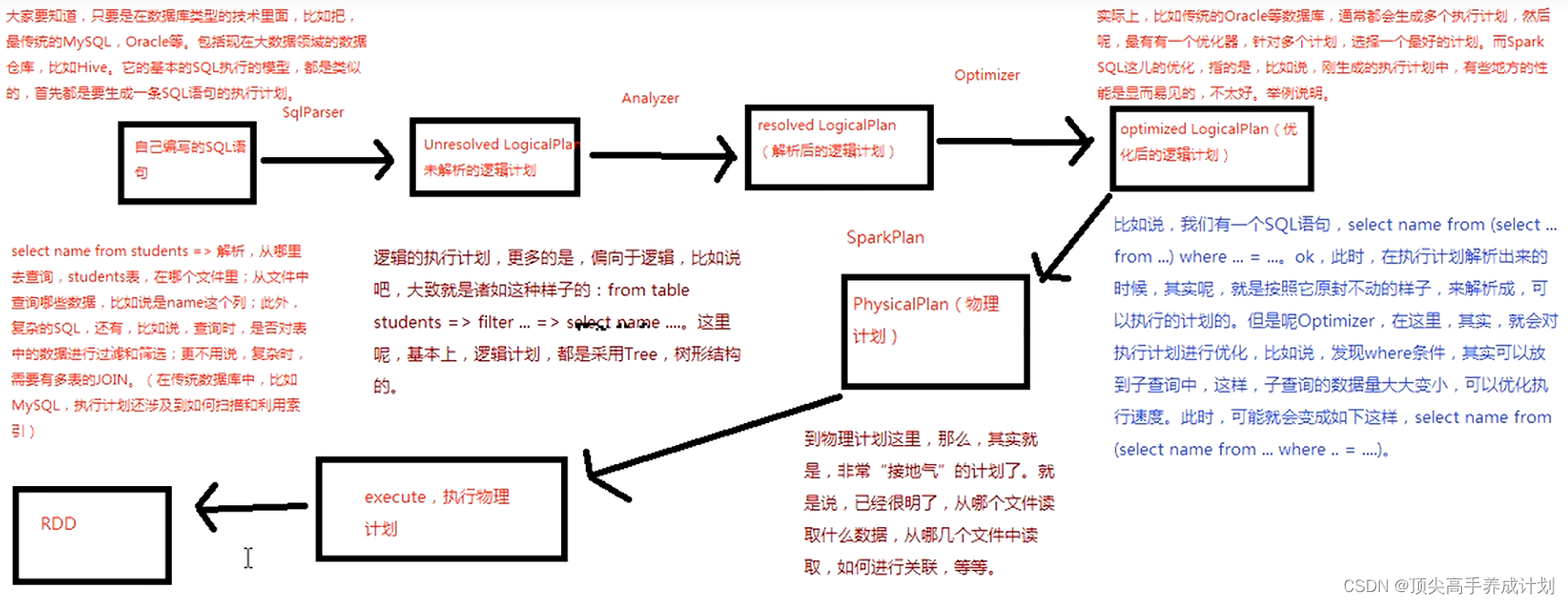
}SparkSql原理
案例实战(每日TOP2热点搜索词统计)
数据格式
日期 用户 搜索词 城市 平台 版本
2015-10-01 leo barbecue beijing android 1.0
2015-10-01 leo barbecue beijing android 1.0
2015-10-01 tom barbecue beijing android 11.0
2015-10-01 jack barbecue beijing android 1.0
2015-10-01 marry barbecue beijing android 1.0
2015-10-01 tom seafood beijing android 1.2
2015-10-01 leo seafood beijing android 1.2
2015-10-01 jack seafood beijing android 1.2
2015-10-01 jack seafood beijing android 1.2
2015-10-01 marytoy beijing android 1.5
2015-10-01 leo toy beijing android 1.5
2015-10-01 leo toy beijing android 1.5
2015-10-01 jack water beijing android 2.0
2015-10-01 whitebarbecue nanjing iphone 2.0
2015-10-02 white seafood beijing android 1.0
2015-10-02 leo seafood beijing android 1.0
2015-10-02 may seafood beijing android 1.0
2015-10-02 tom seafood beijing android 1.0
2015-10-02 jack seafood beijing android 1.0
2015-10-02 jack seafood beijing android 1.0
2015-10-02 tom water beijing android 1.2
2015-10-02 1e0 beijing android 1.2
2015-10-02 jack water beijing android 1.2
2015-10-02 jack water beijing android 1.2
2015-10-02 leo barbecue beijing android 1.5
2015-10-02 marry barbecue beijing android 1.5
2015-10-02 marry barbecue beijing android 1.5
2015-10-02 jack toy beijin android 2.0
2015-10-02 white tour nanjing iphone 2.0需求
- 筛选出符合条件(城市,平台,版本)的数据
- 统计每天的uv排名前3的搜索词
- 按照每天的top2搜索词搜索总次数,倒叙排序
java实现代码
public class JavaUV {public static void main(String[] args) {SparkConf sparkConf = new SparkConf();sparkConf.setMaster("local").setAppName("sparkConf");JavaSparkContext javaSparkContext = new JavaSparkContext(sparkConf);SQLContext sqlContext = new SQLContext(javaSparkContext);//第一步得到数据JavaRDD uvInitRDD = javaSparkContext.textFile("data/uvdata.txt");//这里定义查询条件,比方这里用城市,手机型号,版本作为条件HashMap> queryParams = new HashMap<>();queryParams.put("city", Arrays.asList("beijing"));queryParams.put("phone", Arrays.asList("android"));queryParams.put("version", Arrays.asList("1.0", "1.2", "1.5"));//由于查询的数据数量不太大,但是每一个分区的数据都要过滤,那我们就把他做成广播变量Broadcast>> queryParamBroadcast = javaSparkContext.broadcast(queryParams);//第二步对于查询的条件对于数据进行过滤JavaRDD filterLogData = uvInitRDD.filter(new Function() {@Overridepublic Boolean call(String logData) throws Exception {String[] logItem = logData.split(" ");//对于不符合的数据直接过滤if (logItem.length != 6) {return false;}//在分区里面得到广播变量HashMap> queryParamsb = queryParamBroadcast.value();//得到所有的条件数据List city = queryParamsb.get("city");List phone = queryParamsb.get("phone");List version = queryParamsb.get("version");String logCity = logItem[3];String logPhone = logItem[4];String logVersion = logItem[5];if (!city.contains(logCity)) {return false;}if (!phone.contains(logPhone)) {return false;}if (!version.contains(logVersion)) {return false;}return true;}});//第三步对于过滤的数据,由于统计的是每天热点uv所以要对词的搜索,所以我想的是(日期_词,用户)//对于日期_词的key进行分组那么我们就得到了每天每一个词访问的用户,我们还要对用户进行去重操作JavaPairRDD dataKeyWordUser = filterLogData.mapToPair(new PairFunction() {@Overridepublic Tuple2 call(String filterLogDataItem) throws Exception {String[] logDataItem = filterLogDataItem.split(" ");String logdata = logDataItem[0];String logUserName = logDataItem[1];String logdataKeyWord = logDataItem[2];return new Tuple2(logdata + "_" +logdataKeyWord , logUserName);}});//第四步,根据Key分组,把RDD里面所有相同的key的数据shuffle到一起JavaPairRDD> dataKeyWordUsers = dataKeyWordUser.groupByKey();//第五步,把分组以后的数据求出对应的UVJavaPairRDD dataKeyWordUV = dataKeyWordUsers.mapToPair(new PairFunction>, String, Integer>() {@Overridepublic Tuple2 call(Tuple2> initData) throws Exception {String dataKeyWord = initData._1;Iterable strings = initData._2;HashSet res = new HashSet<>();for (String string : strings) {res.add(string);}int size = res.size();return new Tuple2(dataKeyWord, size);}});//第六步统计每天的UV的前3名,我想用sparksql对于每天的数据开窗函数以后求每天的前3的数据JavaRDD dataKeyWordUVRow = dataKeyWordUV.map(new Function, Row>() {@Overridepublic Row call(Tuple2 v1) throws Exception {String dataKeyWord = v1._1;String[] initDataKeyWord = dataKeyWord.split("_");String data = initDataKeyWord[0];String keyWord = initDataKeyWord[1];Integer uv = v1._2;return RowFactory.create(data, keyWord, Integer.valueOf(uv));}});//第七步根据上面的Row构建对于的元数据信息List dataKeyWordStruct = Arrays.asList(DataTypes.createStructField("data", DataTypes.StringType, true),DataTypes.createStructField("keyword", DataTypes.StringType, true),DataTypes.createStructField("uv", DataTypes.IntegerType, true));StructType structType = DataTypes.createStructType(dataKeyWordStruct);//第八步,得到对应的表Dataset dataFrame = sqlContext.createDataFrame(dataKeyWordUVRow, structType);dataFrame.registerTempTable("datakeyuv");//这里得到了每天top3的uv热词//+----------+--------+---+----+//| data| keyword| uv|rank|//+----------+--------+---+----+//|2015-10-02| seafood| 5| 1|//|2015-10-02|barbecue| 2| 2|//|2015-10-01|barbecue| 4| 1|//|2015-10-01| seafood| 3| 2|//+----------+--------+---+----+Dataset rowDataset = sqlContext.sql("select * from" +"(" +"select " +" data," +" keyword," +" uv," +" row_number() over (PARTITION BY data ORDER BY uv DESC) as rank" +" from datakeyuv" +") where rank<=2");//第九步,对于每天的top3的uv求总数,我们用到(日期,uv)分组进行计算rowDataset.javaRDD().mapToPair(new PairFunction() {@Overridepublic Tuple2 call(Row row) throws Exception {return new Tuple2(row.getString(0),row.getInt(2));}}).reduceByKey(new Function2() {@Overridepublic Integer call(Integer num1, Integer num2) throws Exception {return num1+num2;}}).foreach(new VoidFunction>() {@Overridepublic void call(Tuple2 result) throws Exception {//foreach是在每一个分区执行的//最后得到的数据是//(2015-10-01,7)//(2015-10-02,7)System.out.println(result);}});javaSparkContext.close();}
}
scala版本实现
object ScalaUv {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("ScalaUv").setMaster("local")val sparkSql: SparkSession = SparkSession.builder().config(conf).getOrCreate()val sparkContext: SparkContext = sparkSql.sparkContext//这个是用来查询数据的参数val queryParams: mutable.Map[String, List[String]] = scala.collection.mutable.Map[String, List[String]]()queryParams("city") = List("beijing")queryParams("phone") = List("android")queryParams("version") = List("1.0", "1.2", "1.5")val broadValues: Broadcast[mutable.Map[String, List[String]]] = sparkContext.broadcast(queryParams)//得到过滤后的数据val filterLogData: RDD[String] = sparkContext.textFile("data/uvdata.txt").filter(logData => {var flag: Boolean = trueval logDataItem: Array[String] = logData.split(" ")if (logDataItem.length != 6) {false} else {val city: String = logDataItem(3)val phone: String = logDataItem(4)val version: String = logDataItem(5)//对于查询数据不满足条件的删除val queryParam: mutable.Map[String, List[String]] = broadValues.valueif (!queryParam("city").contains(city)) {flag = false}if (!queryParam("phone").contains(phone)) {flag = false}if (!queryParam("version").contains(version)) {flag = false}flag}})//得到(日期_搜索词,用户名)val dataKeyWordUser: RDD[(String, String)] = filterLogData.map(filterLogDataItem => {val logdata: Array[String] = filterLogDataItem.split(" ")val data: String = logdata(0)val userName: String = logdata(1)val keyWord: String = logdata(2)(data + "_" + keyWord, userName)})val dataKeyWordGroup: RDD[(String, Iterable[String])] = dataKeyWordUser.groupByKey()//对于每一天搜索相同的搜索词的用户进行求和对于用户去重val dataKeyWorkUV: RDD[(String, Int)] = dataKeyWordGroup.map(dataKeyWordGroupItem => {val dataKeyWord: String = dataKeyWordGroupItem._1val users: Iterable[String] = dataKeyWordGroupItem._2val distinctUser = scala.collection.mutable.Set[String]()for (user <- users) {distinctUser.add(user)}(dataKeyWord, distinctUser.size)})//映射成Rowval dataKeyWordRow: RDD[Row] = dataKeyWorkUV.map(dataKeyWorkUVItem => {val dateKeyWord: String = dataKeyWorkUVItem._1val dateKeyWordStrings: Array[String] = dateKeyWord.split("_")val date: String = dateKeyWordStrings(0)val keyWord: String = dateKeyWordStrings(1)Row(date, keyWord, dataKeyWorkUVItem._2)})//创建一个元数据对象val dataKeyWordStructType: StructType = StructType(Array(StructField("date", DataTypes.StringType, true),StructField("keyword", DataTypes.StringType, true),StructField("uv", DataTypes.IntegerType, true)))//得到对应的DataFrameval dataKeyWordframe: DataFrame = sparkSql.createDataFrame(dataKeyWordRow, dataKeyWordStructType)//这个创建映射表的作用就是,sparksql最后到RDD找数据的关键dataKeyWordframe.createTempView("dataKeyWord")val rankDataFrame: DataFrame = sparkSql.sql("""|select * from|(| select| date,| keyword,| uv,| row_number() over (PARTITION BY date ORDER BY uv DESC) as rank| from dataKeyWord|) where rank<=2|""".stripMargin)//得到的数据
// +----------+--------+---+----+
// | date| keyword| uv|rank|
// +----------+--------+---+----+
// |2015-10-02| seafood| 5| 1|
// |2015-10-02|barbecue| 2| 2|
// |2015-10-01|barbecue| 4| 1|
// |2015-10-01| seafood| 3| 2|
// +----------+--------+---+----+//得到最后的结果rankDataFrame.rdd.map(row=>{(row.getAs[String]("date"),row.getAs[Int]("uv"))}).reduceByKey(_+_).foreach(println)
// (2015-10-01,7)
// (2015-10-02,7)sparkContext.stop()sparkSql.stop()}
}纯sql实现
object ScalaSparkSqlTop {def main(args: Array[String]): Unit = {val conf = new SparkConf()conf.setAppName("ScalaSparkSqlTop").setMaster("local")val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()val sparkContext: SparkContext = sparkSession.sparkContextval queryParams: mutable.Map[String, List[String]] = scala.collection.mutable.Map[String, List[String]]()queryParams("city") = List("beijing")queryParams("phone") = List("android")queryParams("version") = List("1.0", "1.2", "1.5")val broadValues: Broadcast[mutable.Map[String, List[String]]] = sparkContext.broadcast(queryParams)//得到过滤后的数据val filterLogData: RDD[String] = sparkContext.textFile("data/uvdata.txt").filter(logData => {var flag: Boolean = trueval logDataItem: Array[String] = logData.split(" ")if (logDataItem.length != 6) {false} else {val city: String = logDataItem(3)val phone: String = logDataItem(4)val version: String = logDataItem(5)//对于查询数据不满足条件的删除val queryParam: mutable.Map[String, List[String]] = broadValues.valueif (!queryParam("city").contains(city)) {flag = false}if (!queryParam("phone").contains(phone)) {flag = false}if (!queryParam("version").contains(version)) {flag = false}flag}})//得到ROWval logDataRDDRow: RDD[Row] = filterLogData.map(filterLogDataItem => {val logdata: Array[String] = filterLogDataItem.split(" ")val date: String = logdata(0)val userName: String = logdata(1)val keyWord: String = logdata(2)val city: String = logdata(3)val phone: String = logdata(4)val version: String = logdata(5)Row(date, userName, keyWord, city, phone, version)})//创建对应的元数据信息val logDataStructType=StructType(Array(StructField("date",DataTypes.StringType,true),StructField("userName",DataTypes.StringType,true),StructField("keyWord",DataTypes.StringType,true),StructField("city",DataTypes.StringType,true),StructField("phone",DataTypes.StringType,true),StructField("version",DataTypes.StringType,true),))val logDataDataFrame: DataFrame = sparkSession.createDataFrame(logDataRDDRow, logDataStructType)logDataDataFrame.createTempView("logData")//对表进行查询sparkSession.sql("""|select date,sum(uv) from|(| select * from| (| select date,KeyWord,uv,row_number() over (partition by date order by uv desc) rank from| (| select date,KeyWord,count(distinct userName) as uv| from logData| group by date,KeyWord| )| ) where rank<=2|) group by date|""".stripMargin).show()
// 得到的结果
// +----------+-------+
// | date|sum(uv)|
// +----------+-------+
// |2015-10-02| 7|
// |2015-10-01| 7|
// +----------+-------+sparkContext.stop()sparkSession.stop()}
}本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!