基于LabView的排列熵计算
文章目录
- 1.排列熵算法原理
- 2.功能结构图
- 3.各功能说明
- 4.前面板与程序框图设计
- 4.1产生序列子VI
- 4.2相空间重构子VI
- 4.3符号化子VI
- 4.4序列出现次数子VI
- 4.5排列熵计算子VI
- 4.6发送数据子VI
- 4.7保存数据子VI
- 4.8基本函数信号排列熵计算软件 VI
- 5.结果测试
- 5.1结果测试
- 5.2结果分析
- 6.总结
1.排列熵算法原理
假设一个一维时间序列为{x(i),i=1,2,3,…n},相空间重构的主要思想是按照一定的规则把时间序列从一维拓展到多维,从而逆向构建出原始系统的相空间结构。1981 年,Takens 等提出了著名的嵌入定理,也即TAKENS定理。其主要阐述的原理是对一个无限长的且没有噪声的 d 维混沌吸引子的标量的时间{x(n)}而言,只要 m≥2d+1 ,则总是可以找到一个 m 维的嵌入相空间。根据其定理进行重构,则:

如果参数选择恰当,则该矩阵可描述原系统。其中t为延迟时间,m为嵌入维数,n为时间序列长度,k为重构分量个数,将这m个重构分量{x(j),x(j+t)…x(j+(m-1)t)}按照升序重新排列,
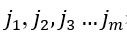
表示重构分量中各个元素的索引,即:
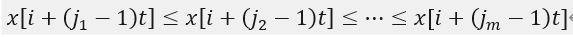
若重构分量中存在相等的值,则按照原序列的顺序进行排序,排序后我们会得到这些数组在原数组中的位置,此时称为符号化 ,
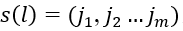
总共的符号序列应为m的全排列即m!种,计算每一种符号出现出现的概率,记为 Pi ,根据香农信息熵的定义形式,定义x(i)的排列熵为:
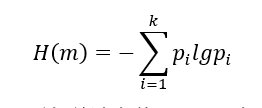
当
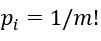
时,此时的H(m)达到最大值ln(m!),为了方便一般将结果H(m)进行归一化处理,即H(m)/lgm!。H(m)值主要反映了两个方面的问题,其一它能衡量时间序列{x(i),i= 1,2,… n}的随机程度,若Hp值越大就说明该序列越随机,反之表示越规则;其二它能有效地刻画时间序列{x(i),i = 1,2… n}的细微变化。
2.功能结构图
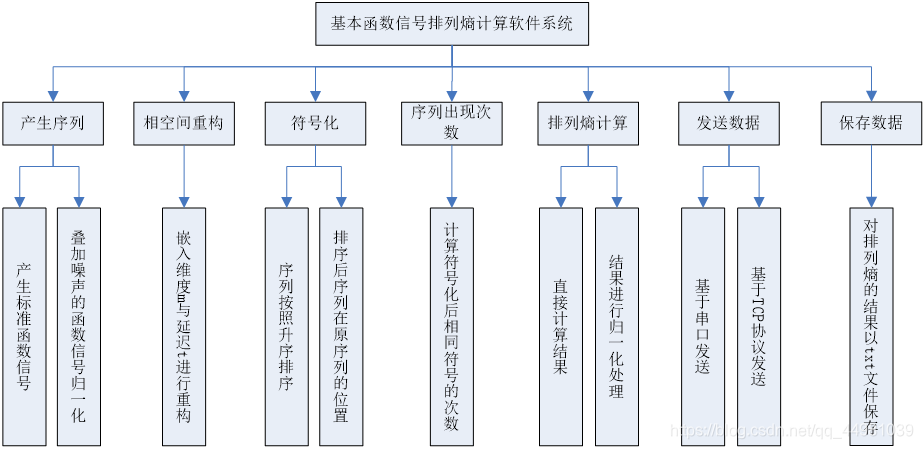
3.各功能说明
①产生序列:产生序列子VI用于序列的产生,序列的产生分为两种,一种是标准函数信号进行波形成分提取得到的一维数组序列,另一种是叠加高斯白噪声并进行归一化得到的一维数组序列,两种信号都使用基本函数发生器进行产生,叠加高斯白噪声的信号再使用高斯白噪声波形进行叠加即可,两种函数节点的设置参数使用同一参数;
②相空间重构:相空间重构根据给定的嵌入维度m和延迟时间t进行相空间重构,利用for循环和索引数组函数节点以及简单的函数节点设计组成,相空间重构是熵计算中的关键步骤;
③符号化:在进行熵计算中,要将给定的序列进行符号化,其符号化中的功能分为两个部分,首先是将序列进行升序排序,利用数组索引和一维数组排序函数节点可完成此功能,其次是找出排序后数组在原数组中的位置,找出之后可得到一串十进制数字,此序列用于后续熵计算的过程,这组十进制的序列称为符号化;
④序列出现次数:符号化之后,需要找到每个符号序列在整体中的频次,以此作为熵计算中的概率,通过两个for循环进行数组索引比较实现此功能;
⑤排列熵计算:此模块可实现两种功能,一种是直接根据公式计算出结果,另一种是将结果进行归一化处理,实现过程为可添加条件结构,当条件为真时,即结果进行归一化处理,将每个概率除以lgm!再进行相加即可,而当条件为假时,直接处理结果;
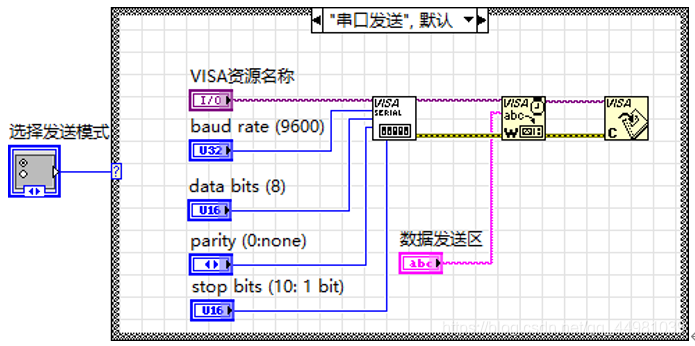
⑥发送数据:此功能用于人机交互,可将计算机计算的结果通过串口往外发送,此模块也可实现两种功能,一种是基于串口通信,直接选择VISA资源名称即可发送数据,另一种是基于TCP协议进行发送,需要进行服务器IP地址的填写以及远程端口或服务器名称和本地端口的填写才可发送数据。
⑦保存数据:此功能用于将计算出来的结果以.txt文件进行保存,拥有发送数据的功能是远远不够的,当发送数据之后,若进行下一个排列熵的求解,则之前的数据会丢失,因此在发送每一个数据之后,将数据以文件形式保存下来,方便后期的查看,也可以进行错误检测。
每个功能编写一个子VI在最终的VI中进行调用。
4.前面板与程序框图设计
4.1产生序列子VI
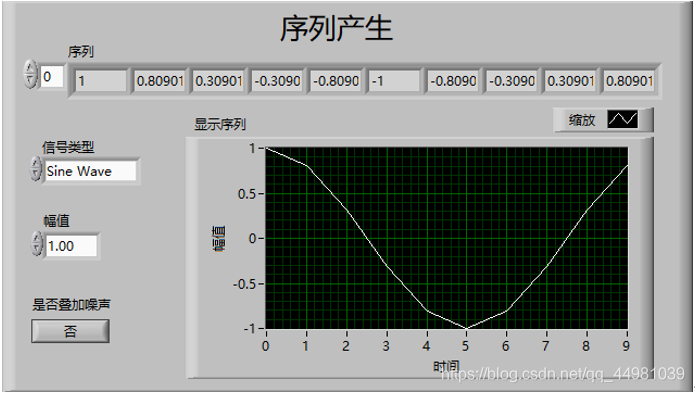
前面板设计:
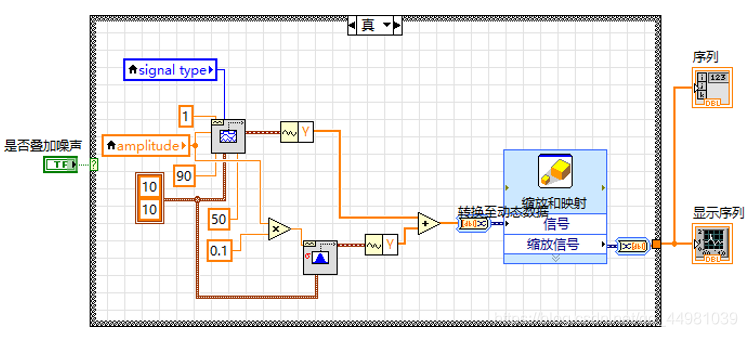
序列产生模块主要为熵计算中序列的产生,其信号分为四种,分别为正弦波,三角波,方波和锯齿波,其次需要能够显示提取出的序列以及显示的波形,此外,序列产生分为两种功能,一种为标准信号,另一种为叠加高斯白噪声的信号,因此需要一个布尔类型的输入控件,因此前面板可分为参数设置与数据显示两部分,参数设置为信号的属性设置及是否叠加高斯白噪声的确定按钮设置,数据显示包括波形的显示及产生序列结果的显示。
程序框图功能设计:
1.标准信号产生
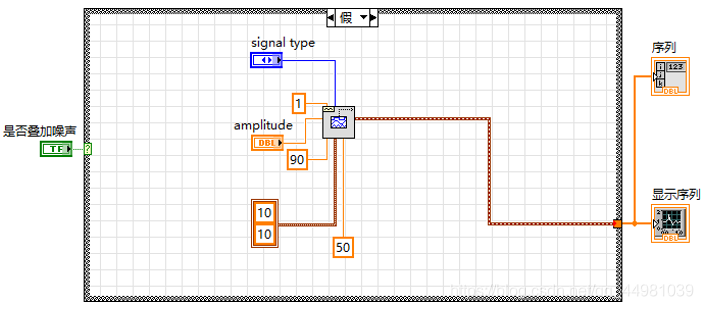
2.叠加高斯噪声并归一化
封装设计:

4.2相空间重构子VI
前面板设计:
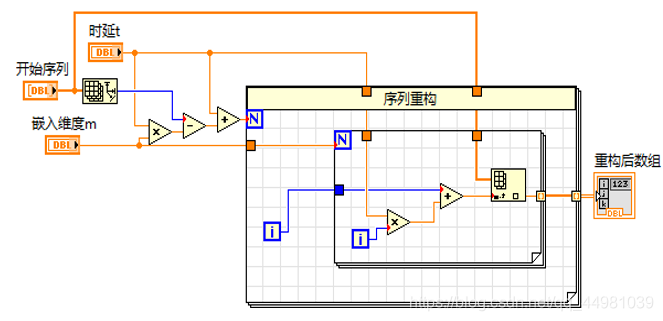
相空间重构是熵计算中的关键步骤,根据用户定义的嵌入维度m与时延t进行相空间重构,其前面板的框架分为两个部分,第一部分为用户定义参数,即嵌入维度m与时延t,和所给定的需要重构的序列,另一部分为重构后数组的显示,为二维数组。

程序框图功能设计:
相空间重构是将一维序列根据用户定义的嵌入维度m与时延t重构为二维数组,因此,在相空间重构的程序框图中,通过两个for循环对原始序列进行重构。
封装设计:

4.3符号化子VI
前面板设计:
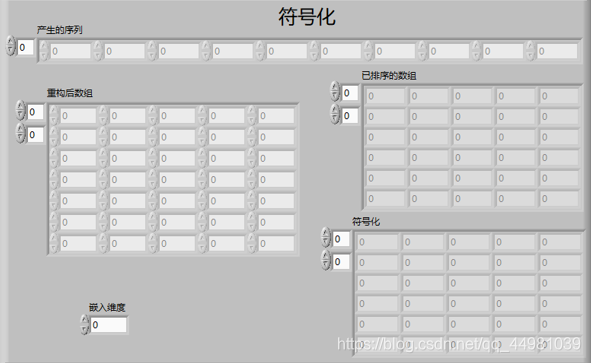
符号化子VI中包含有两个功能实现,第一个实现的功能是对重构后的序列进行排序,其次是找出有序序列在原序列中的位置,因为利用for循环进行索引的时候需要用到产生序列的数组大小和嵌入维度m的数值,因此前面板中需要放一个数值输入控件作为嵌入维度以及一个数组作为产生序列的输入,其次前面板中还需要放重构后的数组,已排序的数组以及有序序列在原序列中的位置数组,即符号化之后。
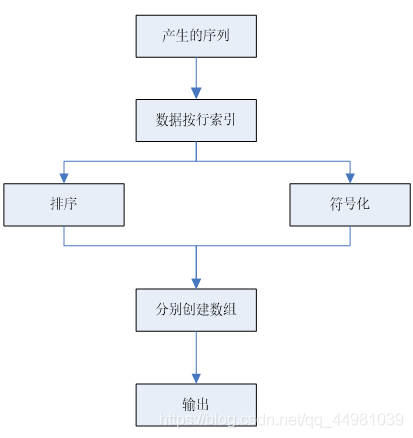
程序框图功能设计:
流程图:
框图:
封装设计:
4.4序列出现次数子VI
前面板设计:
序列出现次数主要功能为计算一个序列出现了多少次,因此在前面板设计中,首先需要序列的输入,即符号化之后的数组,最后要显示出每行序列符号化之后出现的次数,使用一维数组表达即可。
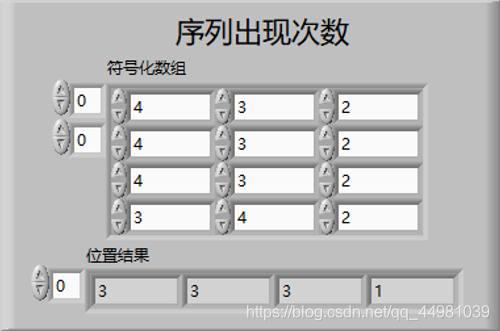
程序框图功能设计:
此子VI的功能是利用双层for循环嵌套,比较数组中相同行数的行数,行数除以m!作为此行序列的概率,最后利用香农公式对排列熵进行求解。
封装设计:

4.5排列熵计算子VI
前面板设计:
此VI功能主要为描述性功能,即香农公式的实现,
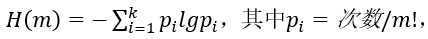
即在前面板中需要有所有次数所构成的数组输入控件以及能够输入m的数值输入控件和排列熵结果的显示,此外,在这个子VI中,有两个功能所要实现,第一个是排列熵结果的直接输出,第二个是对结果进行归一化处理,因此在前面板中需要添加一个布尔变量。
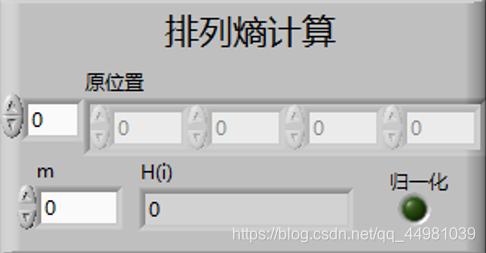
程序框图功能设计:
封装设计:

4.6发送数据子VI
前面板设计:
数据发送是基于两种模式下的数据发送,一种是利用串口通信,需要用到VISA驱动,其次需要用到虚拟串口软件,在一台计算机上实现串口通信功能,另一种是基于TCP协议的通信,因此在前面板的设计中,需要一个用来选择模式的单选控件,其次分别完成通信所用到的参数设置等其他控件。

程序框图功能设计:
1.串口发送
2.基于TCP协议发送
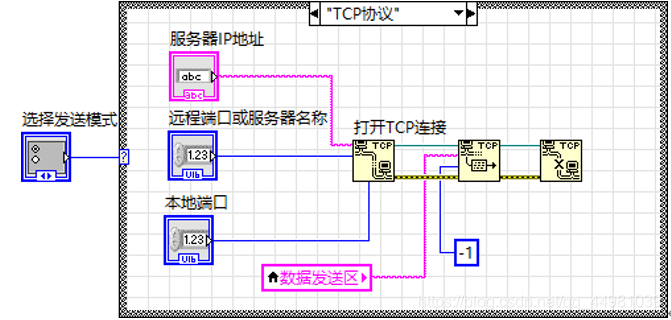
封装设计:

4.7保存数据子VI
前面板设计:
首先,保存数据只需利用labview自带的函数节点创建文件,写入文件,之后关闭文件即可,因此在前面板上只需留有一个字符串输入控件来供用户写入需要保存的数据即可。
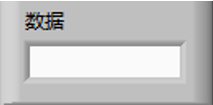
程序框图功能设计:
保存数据利用labview自带的函数节点,很方便的对文件进行了保存,在保存时可以选择自己要保存的路径,在查看时选择记事本进行查看。
封装设计:

4.8基本函数信号排列熵计算软件 VI
前面板设计:

程序框图功能设计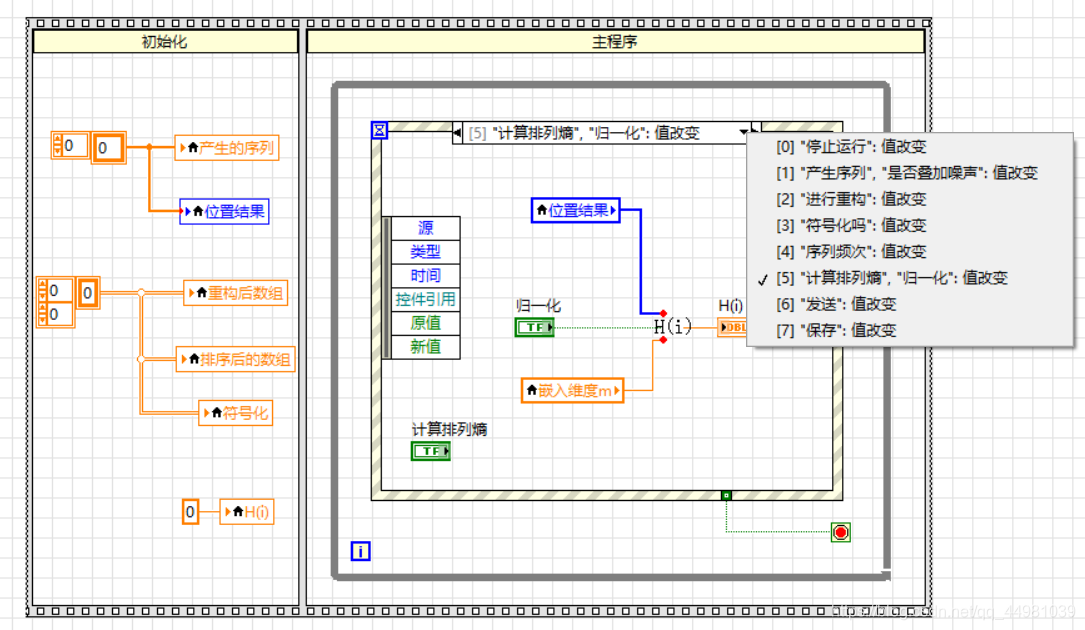
5.结果测试
5.1结果测试
在逐项测试中,所有功能均显示正确,数据结果如下表所示:
参数相同,波形不同的测试结果(t为1):
| 波形 参数 | Sine Wave | Triangle | Square Wave | Sawtooth |
|---|---|---|---|---|
| m=3 不归一化 | 1.320802 | 1.320802 | 0.861654 | 0.861654 |
| 加入噪声 | 1.861654 | 2.113283 | 2.77995 | 2.446617 |
| 结果归一化 | 0.510956 | 0.510956 | 0.333333 | 0.333333 |
波形相同,参数不同的测试结果(t为1,结果不进行归一化处理):
| 参数 波形 | m=2 | m=3 | m=4 | m=5 |
|---|---|---|---|---|
| Sine Wave | -5.30482 | 1.320802 | 1.055827 | 0.328678 |
| Triangle | -5.30482 | 1.320802 | 1.055827 | 0.328678 |
| Square Wave | -7.5 | 0.861654 | 1.003947 | 0.30572 |
| Sawtooth | -7.5 | 0.861654 | 1.003947 | 0.30572 |
5.2结果分析
在结果测试中可以看到,正弦波和三角波的排列熵近似,方波和锯齿波的排列熵近似。这是由于取出信号的序列,而正弦与三角波的序列近似,方波和锯齿波的序列近似。
- 1.在参数相同波形不同的测试数据结果中可以看到正弦波和三角波的排列熵相对于方波和锯齿波的数值偏大,排列熵是度量时间序列复杂度的一种方法,简单的来说是就是混乱度的描述,因此可以看出正弦波和三角波时间序列复杂度稍大于方波和锯齿波;
- 2.对于波形相同参数不同的测试数据结果,可看出当嵌入维度m从2-5进行变化时,同一波形的数据并不是随着嵌入维度递增或递减,而是存在一个极点,说明对于每一种波形,都有一个合适的嵌入维度。但是对于嵌入维度m的选择,Christoph Bandt和Bernd Pompe推荐的嵌入维度m的值为3-7,而我们常常所选取的3或者4仍然比较小,而实验证明5,6或7可能是合适的。
此外,数据发送与数据保存功能可正常运行。
在此次进行排列熵计算的过程中,也发现了一些问题,由于之前程序的设计出现错误,出现了在进行方波测试时程序不运行的情况,对整体问题进行分析了之后,发现方波的特点时重复的数值较多,在找出问题后修改了程序,问题得以解决。
因此,在排列熵的求法中,当序列的数值有相等的时候,我们通常采用的是利用原序列中数值的出现顺序进行符号化处理,但是Christoph Bandt和Bernd Pompe等也针对这一问题提出了一种解决的办法,即在原时间序列中加入人为噪声,来避免相同数值出现的情况,此方法在本次实验中也已体现,通过高斯白噪声与其相加,但并没有预想结果的好,针对于方波这种重复数值多的序列,并没有解决本质上的问题,因为我们采集的数值采样率低,仅仅用于实验,本身出现相同数值的概率就比较大,而此时在输出端与高斯白噪声进行叠加,一是基本不会影响符号化的结果,即没有解决本质上的问题,二是在这种情况下加入噪声,可能输出的序列已经不能够描述原系统,经过重构,符号化之后,排列熵计算的结果可能会出现错误。针对这个问题,在查询了资料之后,发现了有一种改进排列熵的算法,改进排列熵与排列熵大体算法相同,但是在进行符号化的过程中,若出现等值的数值,不是用原序列中的位置,而是用相同的位置表示,这种改进的方法也使用于数值采样率低的系统,可以提高根据排列熵计算时间序列规则性的高效性。
6.总结
LabView不但有对每个函数节点的详细解释,同时还有它的实例可供学习,而LabView在通信方面的设计也非常方便,只需下载串口模拟软件,便可实现两个串口之间的通信。
不足之处还望各位大佬指出~~~
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!