CUDA C编程3 - 并行性衡量指标
系列文章目录
文章目录
- 系列文章目录
- 前言
- 一. CUDA C并行性衡量指标介绍
- 二、案例介绍
- 1. 案例说明
- 2. 案例实现
- 3. 结果分析
- 总结
- 参考资料
前言
CUDA编程,就是利用GPU设备的并行计算能力实现程序的高速执行。CUDA内核函数关于网格(Grid)和模块(Block)大小的最优设置才能保证CPU设备的这种并行计算能力得到充分应用。这里介绍并行性衡量指标,可以衡量最优性能的网格和模块大小设置。
一. CUDA C并行性衡量指标介绍
占用率(nvprof 中的achieved occupancy):
占用率指的是活跃线程束与最大线程束的比率。活跃线程束足够多,可以保证并行性的充分执行(有利于延迟隐藏)。占用率达到一定高度,再增加也不会提高性能,所以占用率不是衡量性能的唯一标准。
延迟隐藏:一个线程束的延迟可以被其他线程束执行所隐藏。
线程束执行率(nvprof中的warp executation effeciency)
线程束中线程的执行
分支率(nvprof中的branch effeciency):
分支率是指未分化的分支数与所有分支数的比率,可以理解为这个数值越高,并行执行能力越强。这里的未分化的分支,是相对于线程束分化而言,线程束分化是指在同一个线程束中的线程执行不同的指令,比如在核函数中存在的if/else这种条件控制语句。同一线程束中的线程执行相同的指令,性能是最好的。nvcc编译器能够优化短的if/else 条件语句的分化问题,也就是说,你可能看到有条件语句的核函数执行时的分支率为100%,这就是CUDA编译器的功劳。当然,对于很长的if/else条件语句一定会产生线程束分化,也就是说,分支率<100%;
避免线程束分化的方法:调整分支粒度适应线程束大小的整数倍
每个线程束的指令数(nvprof中instructions per warp):
每个线程束上执行指令的平均数
全局加载效率(nvprof中 global memory load effeciency):
被请求的全局加载吞吐量与所需的全局加载吞吐量的比率,可以衡量应用程序的加载操作利用设备内存带宽的程度
全局加载吞吐量(nvprof中 global load throughout):
检查内核的内存读取效率,更高的加载吞吐量不一定意味着更高的性能。
二、案例介绍
1. 案例说明
这里以整数规约(数据累加求和)为例,实现了三种不同的内核函数,交错规约性能最好。
reduceNeighbored 内核函数流程(下图引用《CUDA C 编程权威指南》):
 reduceNeighboredLess 内核函数流程(下图引用《CUDA C 编程权威指南》):
reduceNeighboredLess 内核函数流程(下图引用《CUDA C 编程权威指南》):
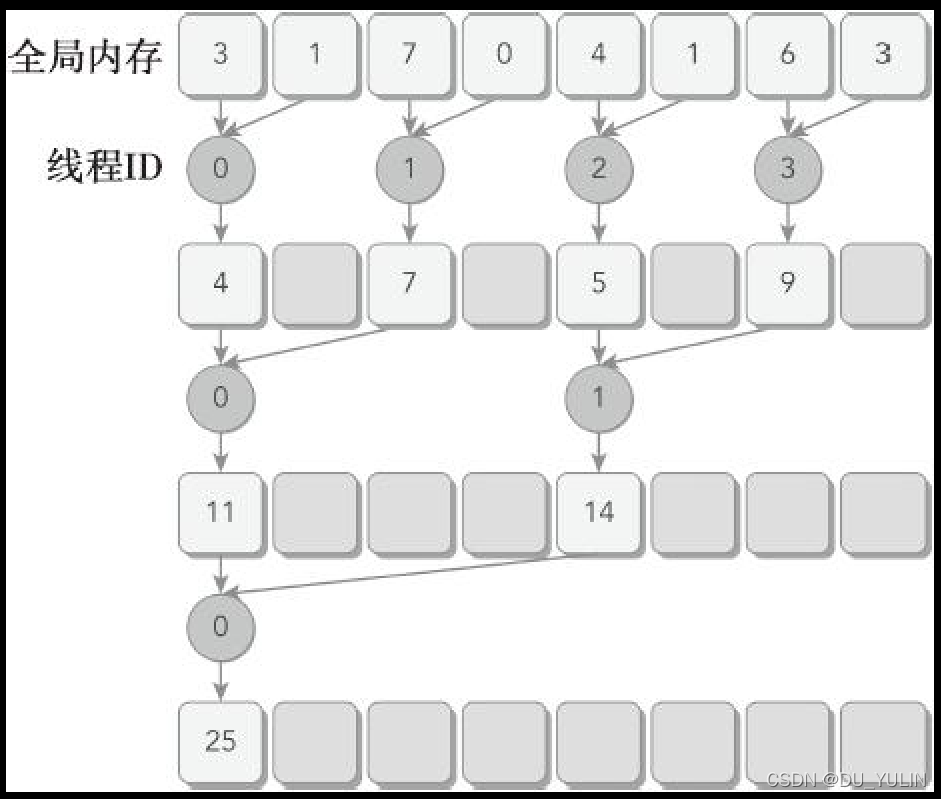 reduceInterLeave 内核函数流程(下图引用《CUDA C 编程权威指南》):
reduceInterLeave 内核函数流程(下图引用《CUDA C 编程权威指南》):

2. 案例实现
#include 3. 结果分析
 从运行时间看,reduceNeighbored内核函数最慢(线程束执行效率最低),reduceInterLeave内核函数最快(线程束执行效率最高)。
从运行时间看,reduceNeighbored内核函数最慢(线程束执行效率最低),reduceInterLeave内核函数最快(线程束执行效率最高)。
总结
衡量并行性的指标有很多,除了上面介绍的这些外,还有很多其他指标,通过均衡多个指标,评估并行能力,得到一个近似最优的网格和模块大小;通过后面的案例可以发现,最优的并行能力并不一定每一项衡量指标都是最优的。
参考资料
《CUDA C编程权威指南》
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!