kaggle-简街市场预测
文章目录
- 1. 赛题描述
- 1.1 特征工程思路
- 1.2 赛题评分函数
- 2. 结构化赛题知识点
- 2.1 结构化赛题特点
- 2.2 结构化赛题难点
- 2.3 结构化赛题要点
- 3. 特征工程 - 50%
- 3.1 Jane Street: EDA of day 0 and feature importance
- 3.1.1 `train.csv` 大数据量
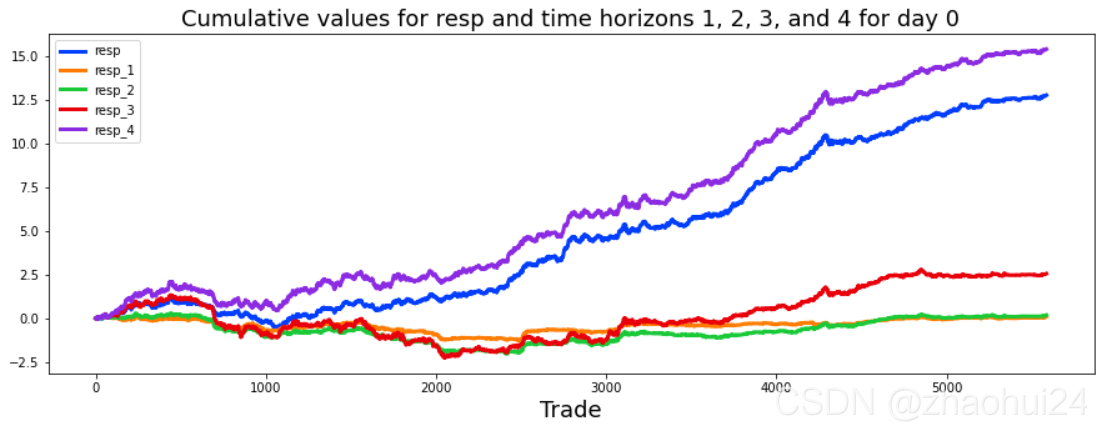
- 3.1.2 `resp` 特征
- 3.1.3 `weight` 特征
- 3.1.4 `date` ,`ts_id` 特征
- 3.1.5 `feature` 特征
- 3.1.5.1 Linear features
- 3.1.6 `action` 特征
- 3.1.7 the first day `day_0` 特征 与 缺失值查看
- 3.1.8 DABL plot
- 3.2 Market Pred-Feature Comparison+Date Analysis
- 3.2.1 `feature.csv`
- 3.2.2 feature 特征的相似性
- 3.3 Feature 0, beyond feature 0
- 3.3.1 TriMap of features 1-130
- 4. 数据划分
- 4.1 数据划分方法
- 4.1.1 时序数据划分方法
- 5. 模型构建
- 5.1 时序建模方法
- 5.1.1 日期因子规则方法
- 5.1.2 日期特征建模方法
- 5.1.3 划窗建模方法
- 5.1.4 序列建模方法
- 5.1.5 注意事项
- 5.2 时序建模工具库
- 5.3 时序比赛常用模型
- 5.3.1 时序特征+树模型
- 5.3.2 序列(多步)预测
- 5.4 模型构建方法
- 6. 量化交易
- 6.1 量化交易介绍
- 6.2 量化策略模型
- 6.2.1 量化策略
- 6.2.2 量化选股模型:多因子模型
- 6.3 赛题数据剖析
- 7. 模型调参
- 7.1 调参方法
- 7.1.1 人工调参
- 7.1.2 网格调参 & 随机调参
- 7.1.3 贝叶斯调参
- 7.2 模型集成
- 7.3 深度学习调参工具
1. 赛题描述
kaggle - Jane Street Market Prediction
赛题数据: 匿名时序结构化 数据;
train.csv训练集,包含历史数据和返回值example_test.csv样例测试集,它展示了看不见的测试集的结构example_sample_submission.csv样例提交文件features.csv匿名特征的元数据

赛题任务:时序数据 的分类任务;
赛题思路:构建 分类模型 来完整;
- 数据字段理解;
- 字段缺失值处理;
- 时序周期建模;
- 模型调参方法;
- 模型集成(树模型 + 神经网络);
1.1 特征工程思路

1.2 赛题评分函数
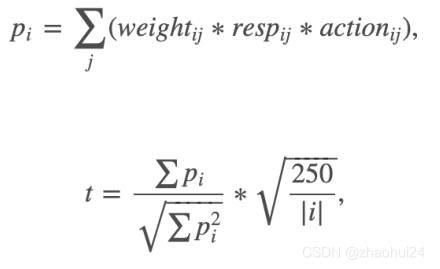
weight字段:含义未知,但参与最终打分;当 weight 取值为 0 时,不参与打分;resp字段:收益回报,有正有负;resp 取值为负,则 action 应该为 0,resp大于0,则action为 1- 250 天是一年工作日的数量(训练集是2年);
2. 结构化赛题知识点

2.1 结构化赛题特点
- 结构化竞赛(Tabular Data Competiton)是最常见的赛题类型;
- 是非常适合入门的赛题类型,对计算资源友好;
- 可以选择用深度学习模型,也可以用树模型;
- 对赛题的字段理解和建模方法决定了最终的精度;
2.2 结构化赛题难点
- 简街数据为匿名数据,需要对字段进行分析和理解;
- 数据字段需要特殊的统计,分析和处理(数据字段的原始形式);
- 数据字段的编码方式和特征提取方式;
匿名数据如何进行分析,如何做特征工程?
- 需要根据字段自身的分布,以及字段和标签的分布,字段属性分析,(可通过画图、可视化),找到字段的相关性后,同时(整合在一起)进行分析。
2.3 结构化赛题要点
- 数据理解与特征工程(50%重要性)
- 数据模型和超参数(20%重要性)
- 模型集成(30%重要性)
3. 特征工程 - 50%
3.1 Jane Street: EDA of day 0 and feature importance
参考链接 - Jane Street: EDA of day 0 and feature importance ⭐️ ⭐️
train.csv 的 dataframe

shape : (2390491, 138),后面未显示是 feature_0 至 feature_129 , ts_id ,action 列。
3.1.1 train.csv 大数据量
使用 datatable 处理,对比 pandas 读取速度快很多。
reading this magnificent kaggle - Tutorial on reading large datasets by Vopani
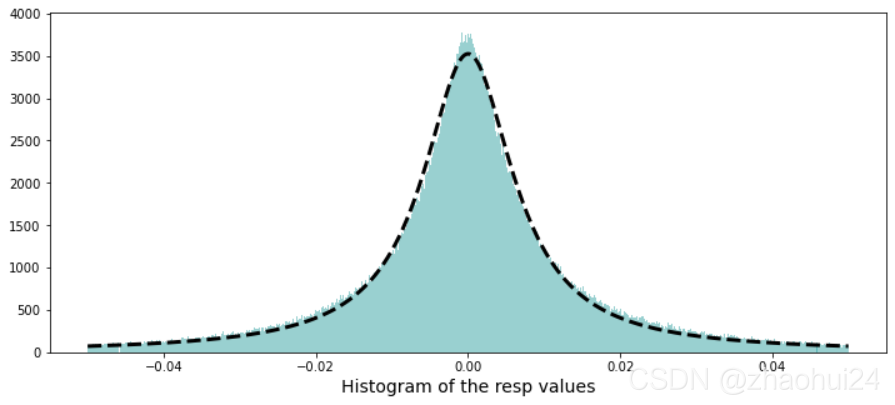
3.1.2 resp 特征
数据格式形式
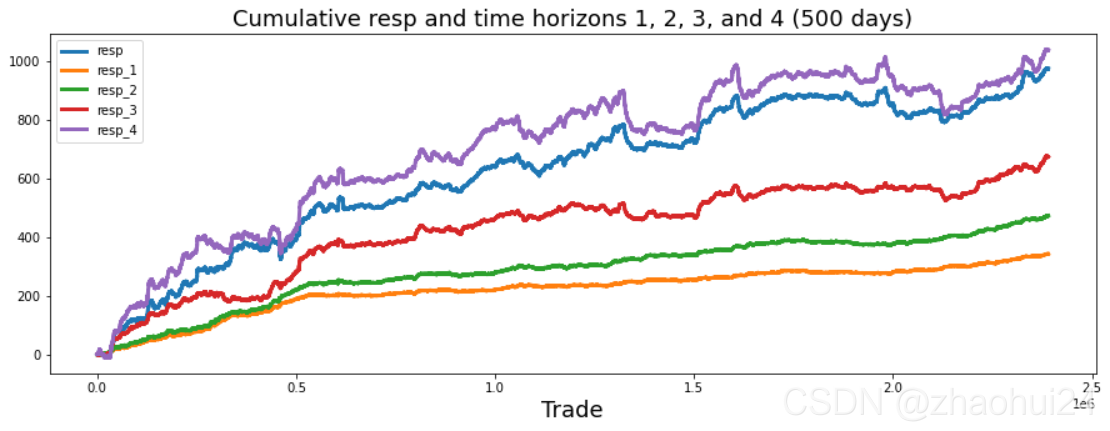
对resp列做画条形图,仅显示值在 -0.05 ~ 0.05 范围。
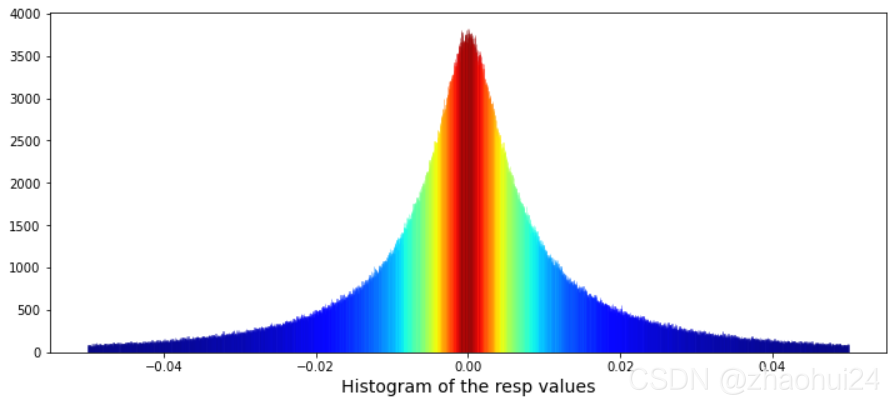
Calculate the skew and kurtosis of this distribution。
-
skew 偏度=0.10,kurtosis 峰度=17.36
-
If the distribution is
symmetric, then the mean is equal to the median, and the distribution has zero skewness.[3] If the distribution is both symmetric andunimodal, then themean=median=mode.

- 链接 Minitab 19 - 偏度和峰度如何影响您的分布,xbmatrix - 偏度(skewness)和峰度(kurtosis)
使用柯西分布进行线性拟合
由于柯西分布具有长尾特性 参考链接 - 神奇的柯西分布,可以对上面条形图进行拟合。
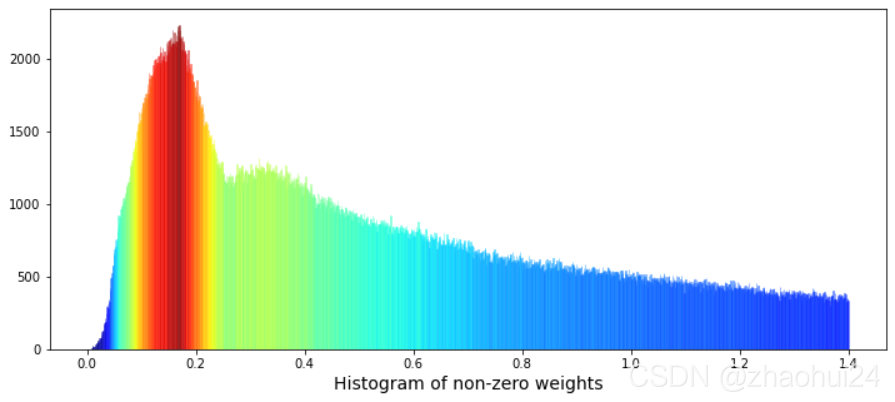
3.1.3 weight 特征
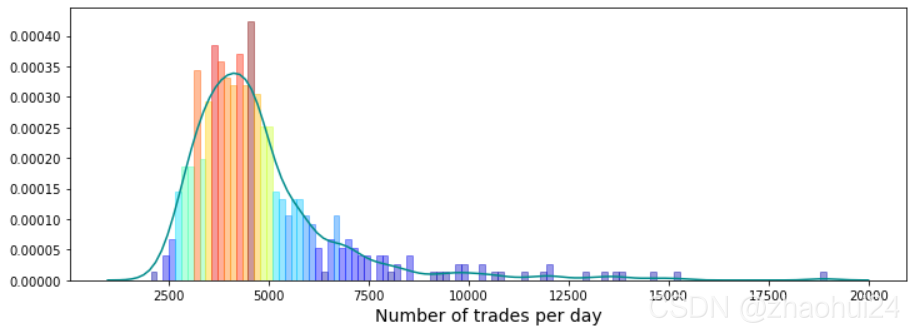
权重值为 0的行进行统计,占 17%。对 weight列画出条形图,显示范围在 0.001~1.4 之间的值。
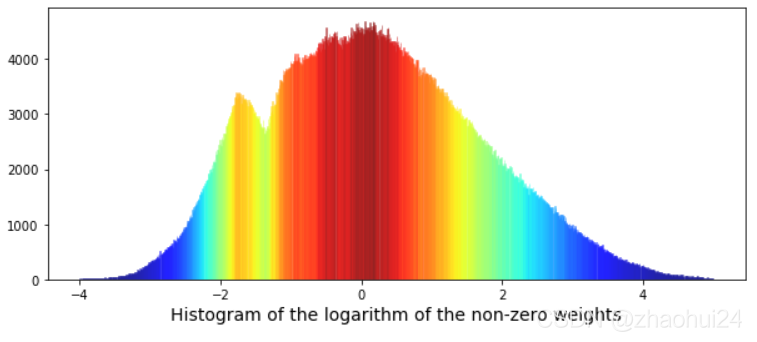
对权重值 weight 进行 降序排序后,再进行画图,发现是一个双峰图。
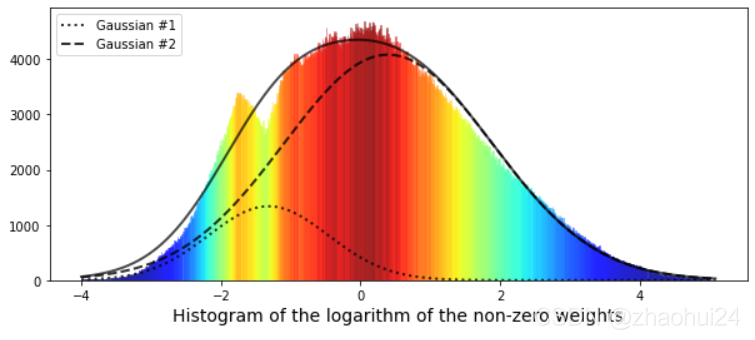
使用 高斯函数 进行拟合,黑色实线 为两条高斯函数曲线的叠加。
3.1.4 date ,ts_id 特征
猜想交易模式发生在第 85 天,分组统计 500天 中的 ts_id 数量。
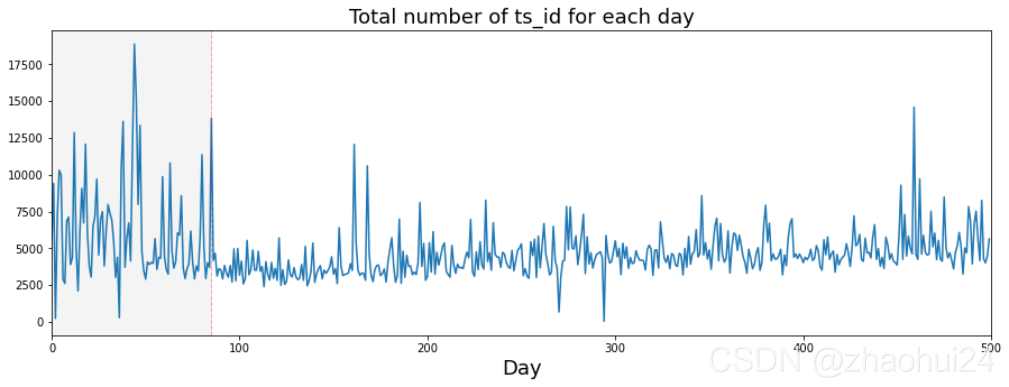
画出每天交易量的条形图
发现 大交易日( more than 9k trades)大多数在 85天 之前。
3.1.5 feature 特征
对特征 feature_0 单独分析,发现值仅有 -1 和 1 两种取值,后面章节对其重点分析。
对 feature_1 至 feature_129 共 129 个特征单独分析,发现似乎有 4 种一般 类型 的特征,下面是4种特征的示例图(举例)
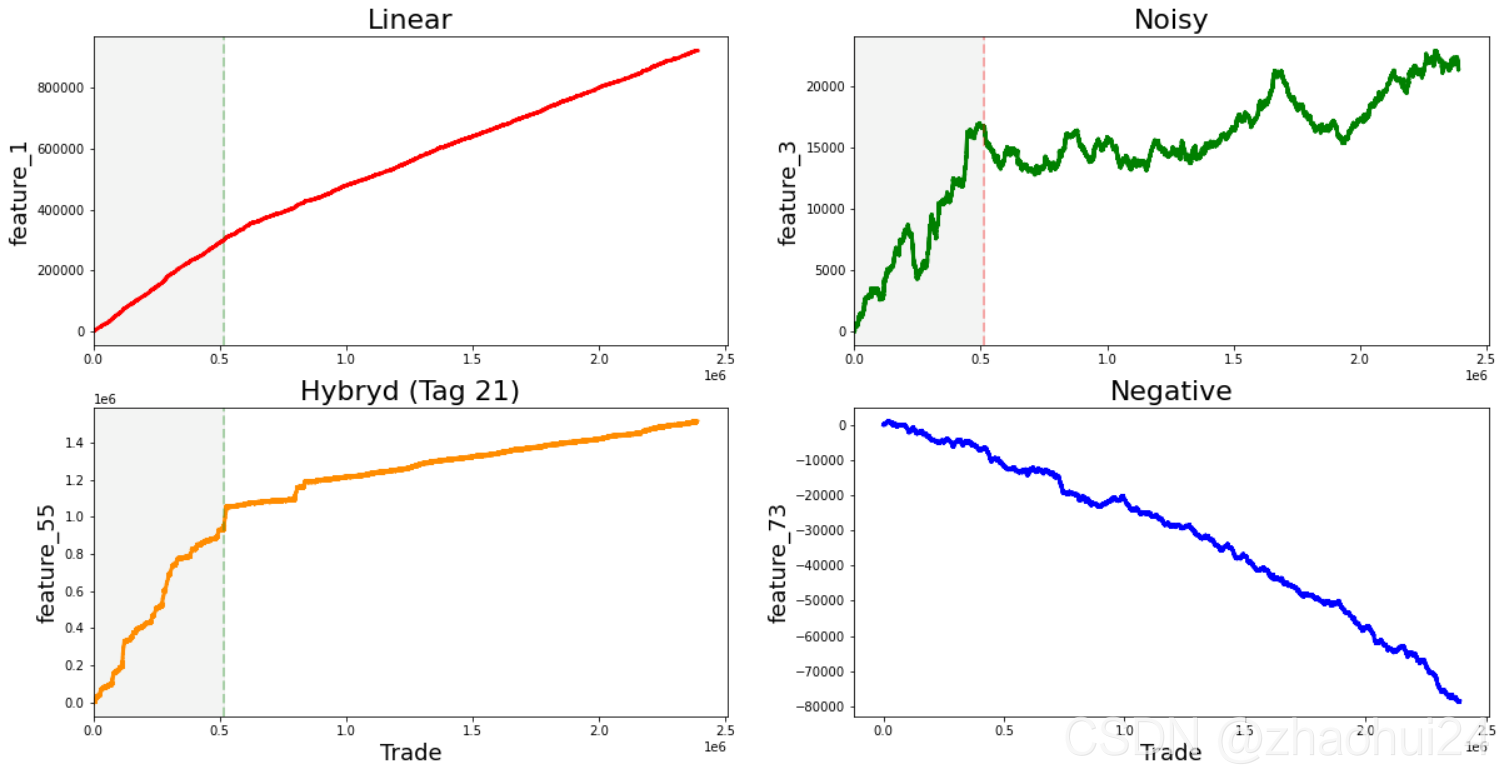
对每一个特征画出其走势图,发现它们符合以上 4 种曲线走势,根据其自身图形进行划分。
3.1.5.1 Linear features
- 1
- 7, 9, 11, 13, 15
- 17, 19, 21, 23, 25
- 18, 20, 22, 24, 26
- 27, 29, 21, 33, 35
- 28, 30, 32, 34, 36
- 84, 85, 86, 87, 88
- 90, 91, 92, 93, 94
- 96, 97, 98, 99, 100
- 102 (strong change in gradient), 103, 104, 105, 106
- as well as 41, 46, 47, 48, 49, 50, 51, 53, 54, 69, 89, 95 (strong change in gradient), 101, 107 (strong change in gradient), 108, 110, 111, 113, 114, 115, 116, 117, 118, 119 (strong change in gradient), 120, 122, and 124.
……
3.1.6 action 特征
action的数值为 0,1 两种形式,统计出每天交易为 1 (action=1)的数量占比。
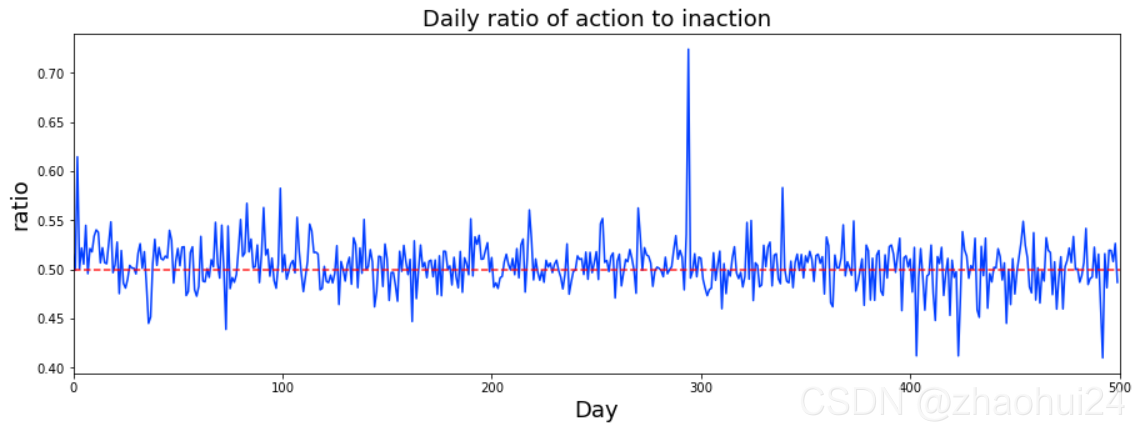
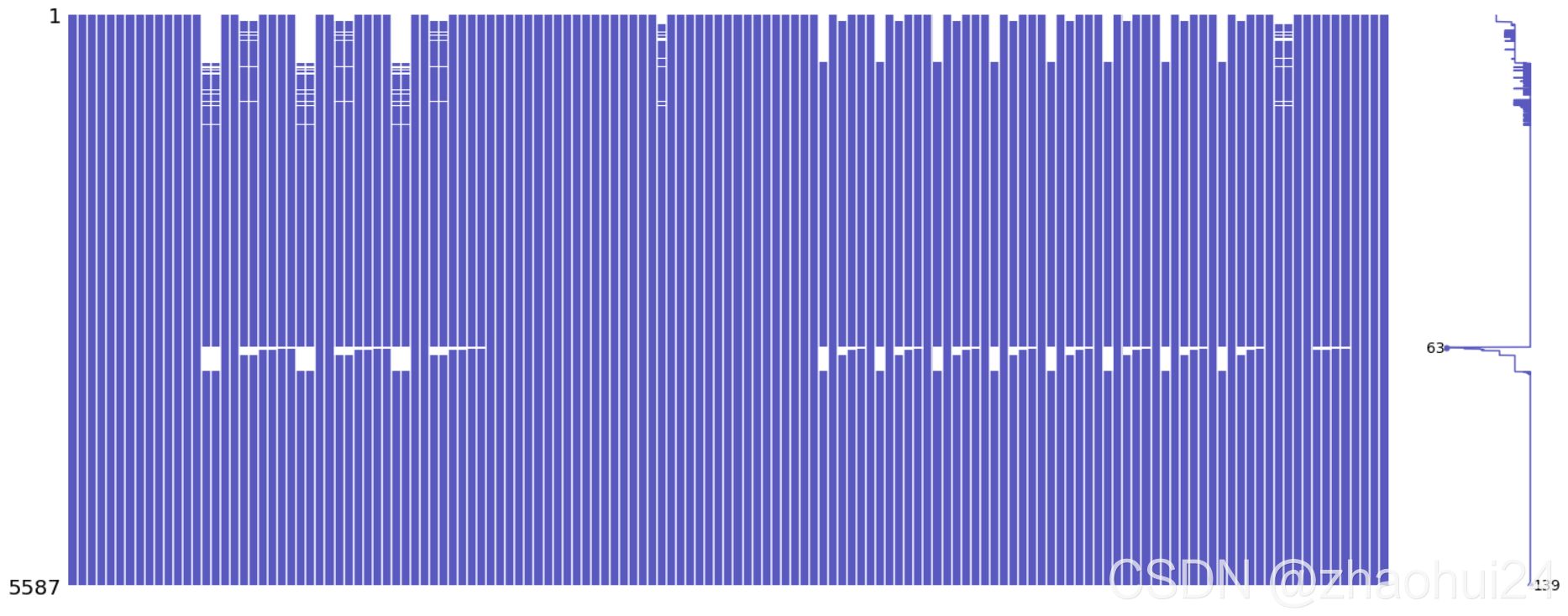
3.1.7 the first day day_0 特征 与 缺失值查看
对 day_0 所有139个特征,缺失值的查看
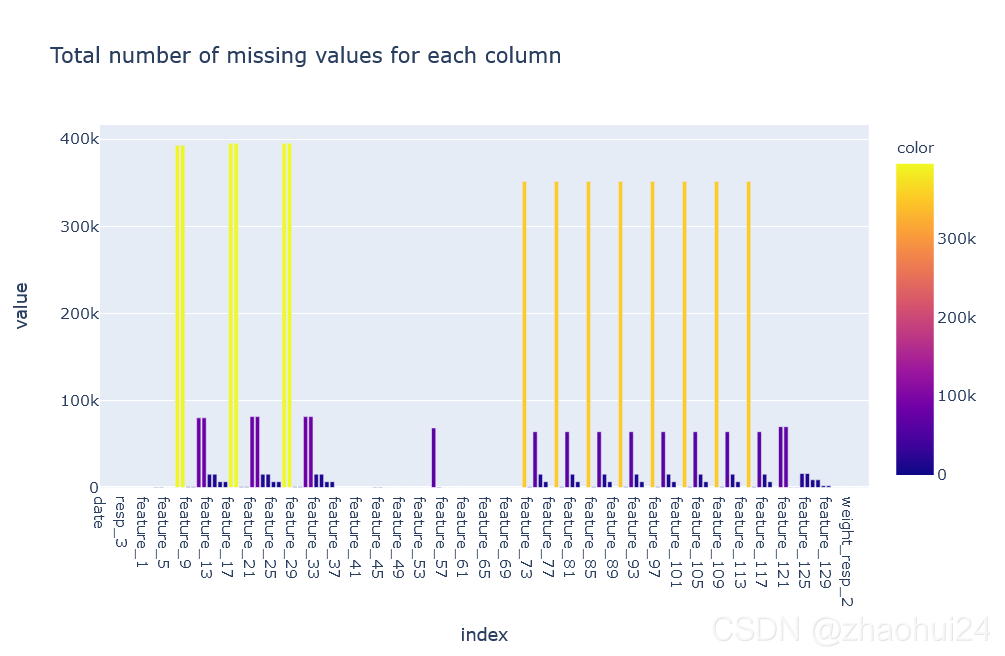
对整个 训练数据集统计缺失值 情况。
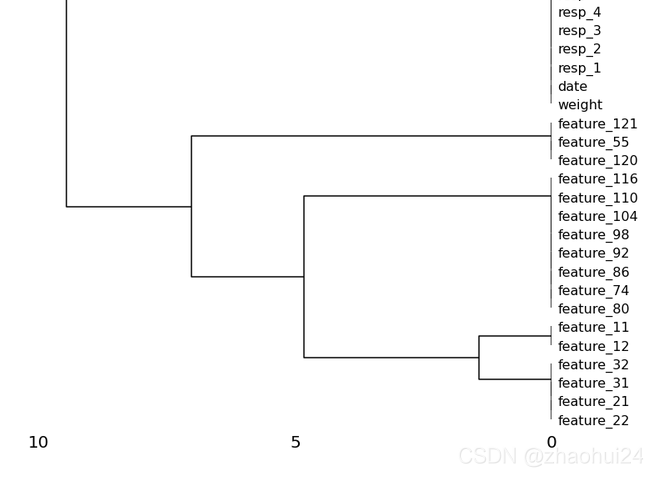
使用 missingno 库画缺失值图
msno.dendrogram(train_data.iloc[:500, :]) # 根据缺失值的特征,将其组合到一起,构成框图
缺失值填充 方法有
- 向前填充;
- 最近邻填充;
- 常数填充;
- 迭代建模填充;
3.1.8 DABL plot
后面可以学习 DABL 库
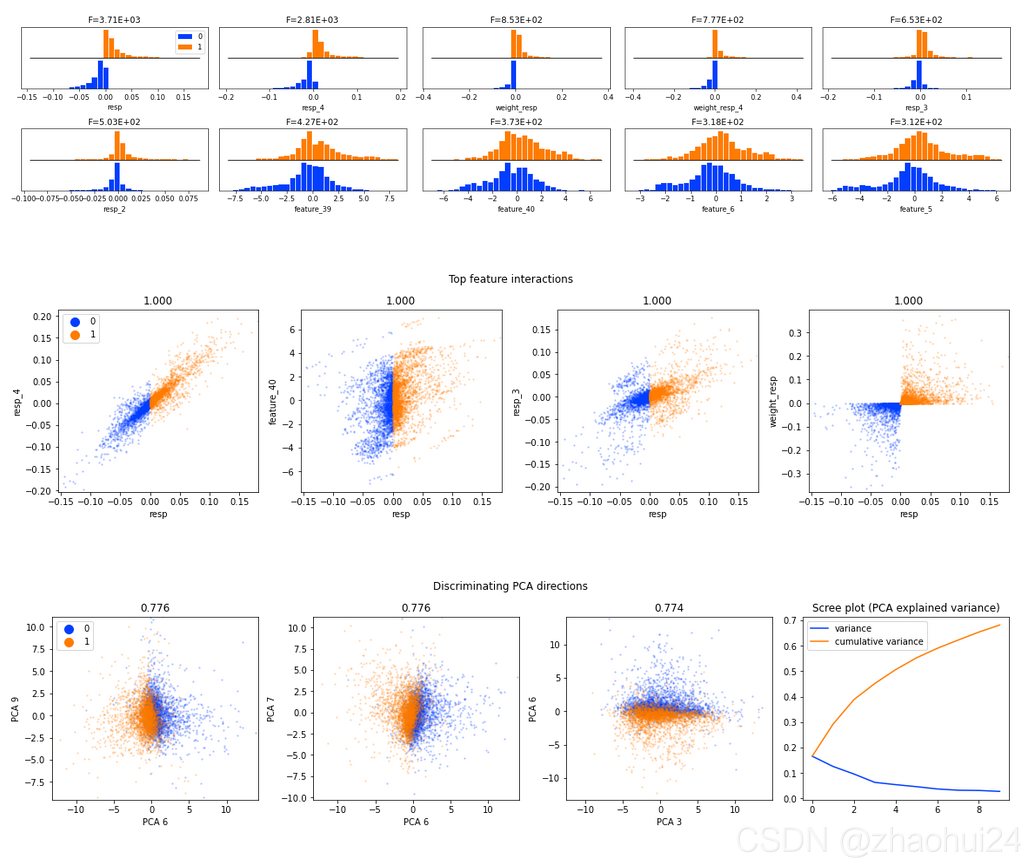
3.2 Market Pred-Feature Comparison+Date Analysis
参考链接 - DoosriJanam - Market Pred-Feature Comparison+Date Analysis
feature.csv 的 dataframe
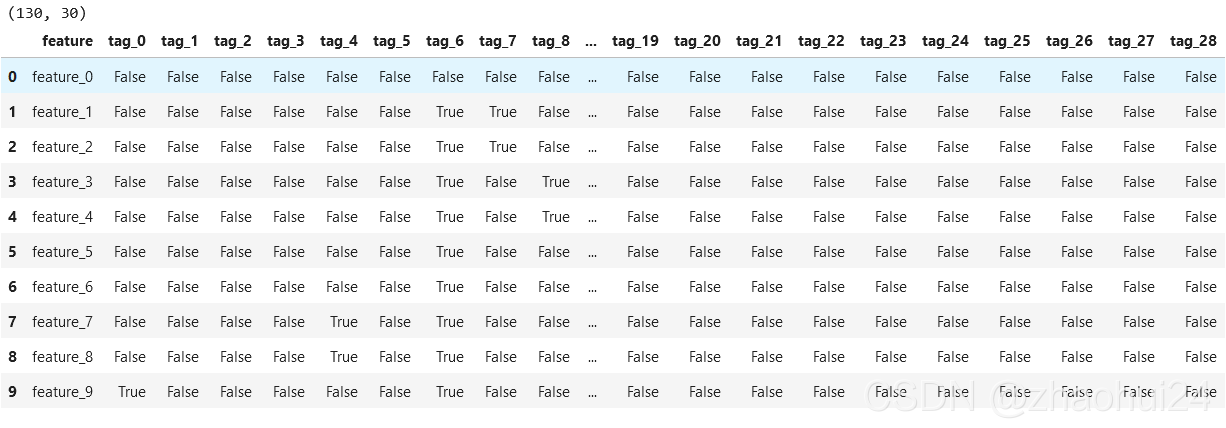
3.2.1 feature.csv
将上面的 dataframe 中的 True 和 False 转为 1 和 0 ,再统计 130 个 feature 特征中对应的 tag 为 1 的个数。
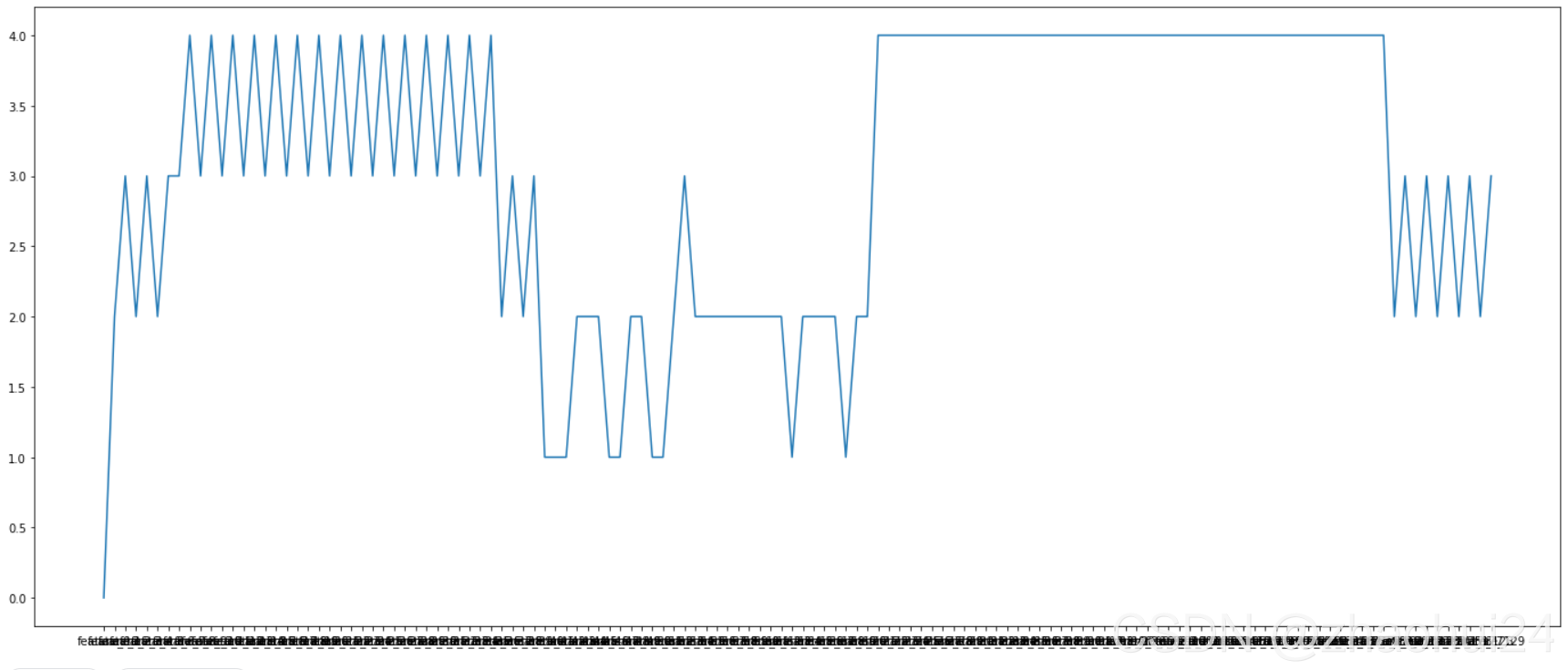
上图中横轴为 130 个 feature,纵轴为统计 1 的个数。
3.2.2 feature 特征的相似性
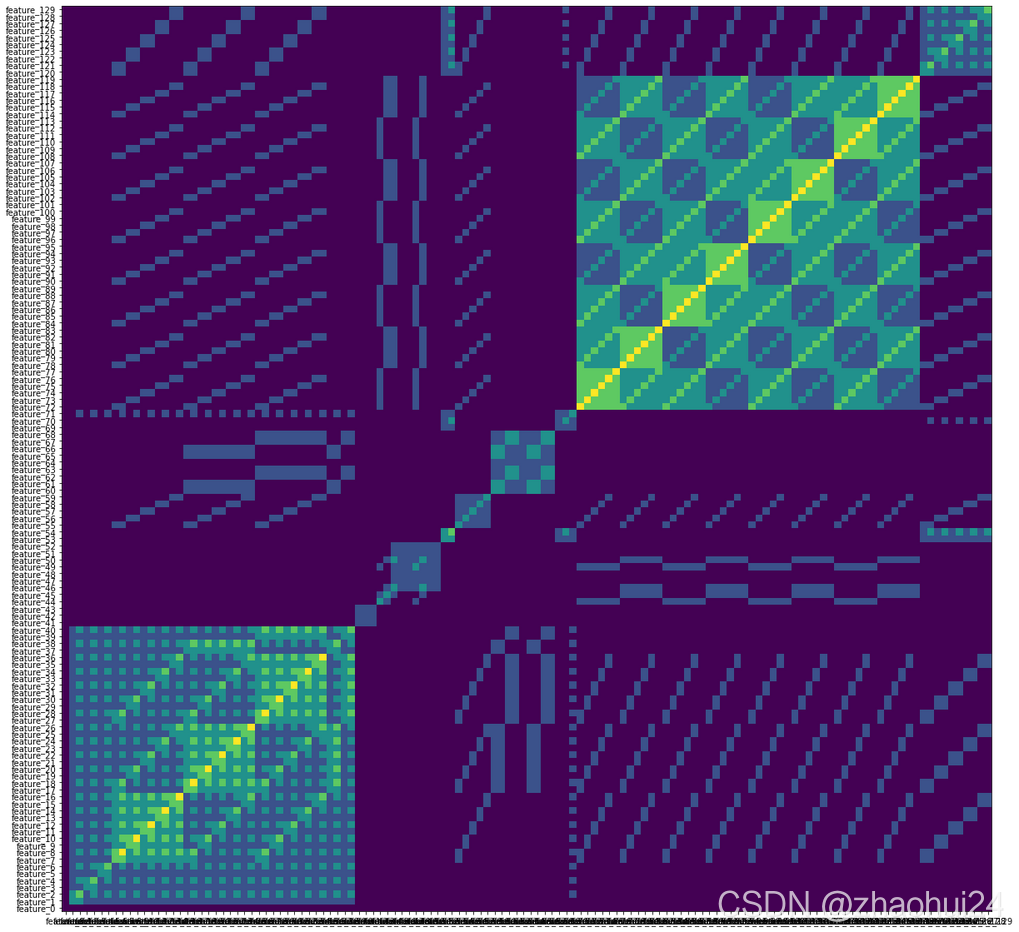
画出 130 个 feature 的 特征相似性 矩阵
- Features 1 to 40 form
set 1- Features 61 to 70 form
set 2- Features 71 to 120 form
set 3- Features 121 to 129 form
set 4
3.3 Feature 0, beyond feature 0
参考链接 - NanoMathias - Feature 0, beyond feature 0 ⭐️ ⭐️ 还需仔细推敲
利用 feature_0 的特征,仅 +1 和 -1 两个值,将其进行二分作图。
3.3.1 TriMap of features 1-130
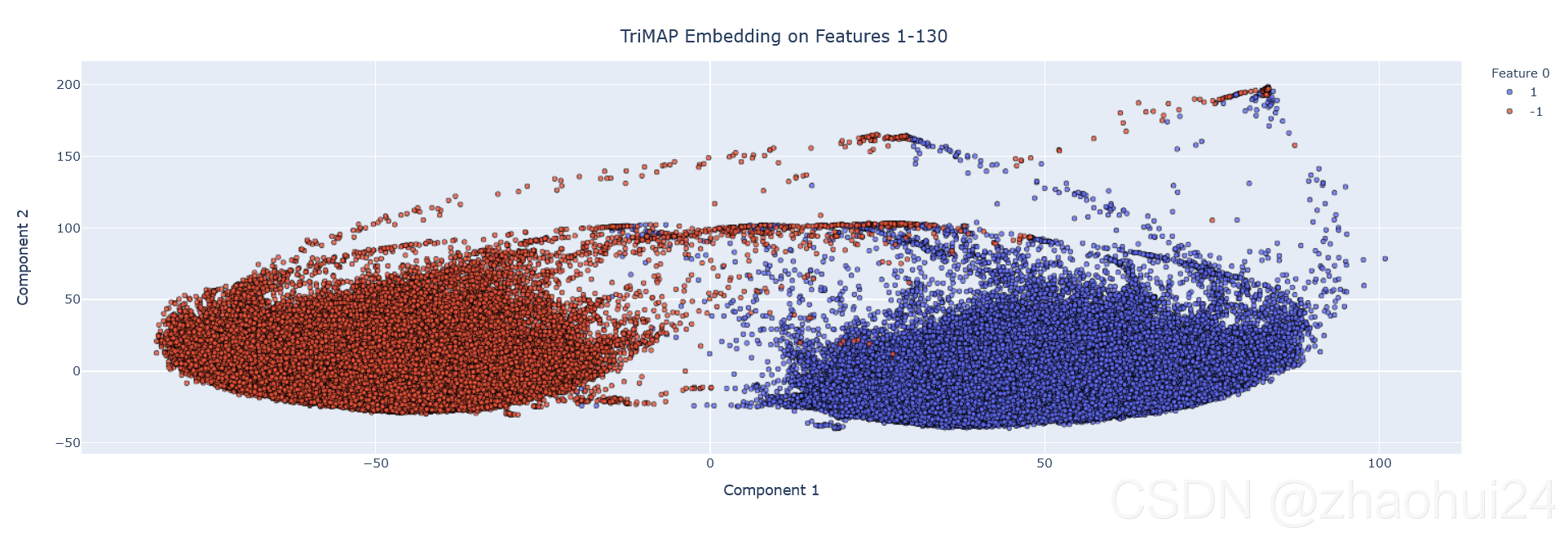
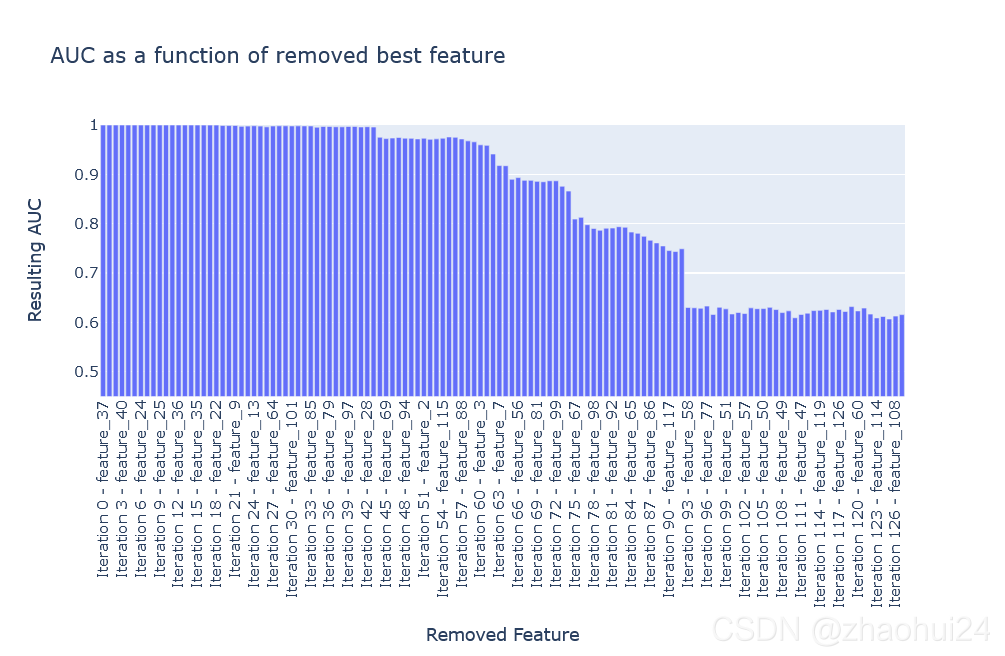
对 feature_0 拿出来单独分析,然后根据AUC值变化,逐个删除特征,找出特征之间的相关性。
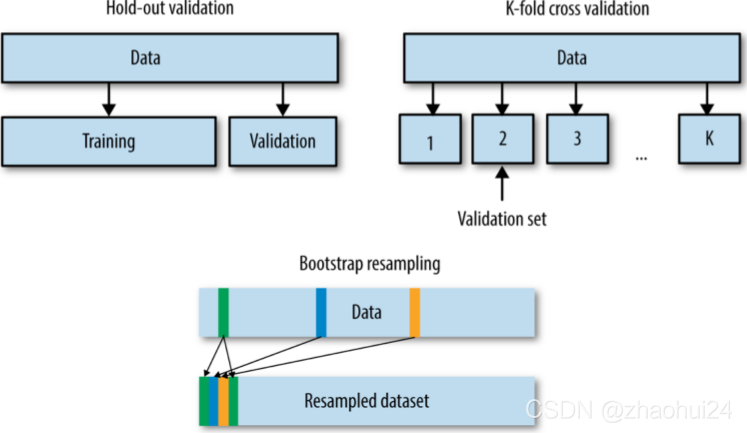
4. 数据划分
参考链接 - scikit leran - 3.1. Cross-validation: evaluating estimator performance

表格图链接
4.1 数据划分方法
- 留出法(Hold-out): 75%训练集,25%验证集
- K折交叉验证(K-fold CV)
- 自助采样(Bootstrap),数据量大不适合。
4.1.1 时序数据划分方法
参考链接 - Jorijn Jacko Smit - Found the Holy Grail: GroupTimeSeriesSplit ⭐️ ⭐️
简单划窗
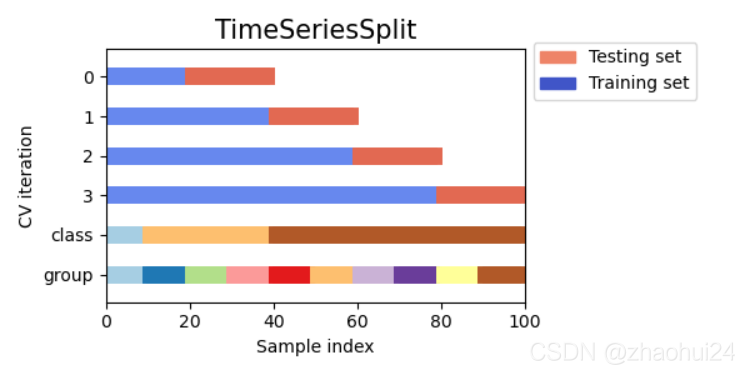
图中纵轴 0-3 训练集比例不断增加,但是这种时间序列划分的方法,并没有考虑到类别,类别整体的比例、分组等没有考虑到。
分组划窗 sklearn.model_selection.GroupKFold
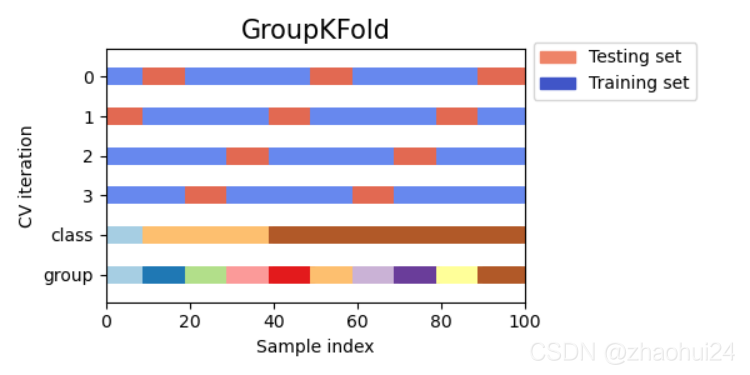
划分训练集合验证集时可以按照 分组 来进行划分,但是 GroupKFold 不支持时间顺序,导致可能出现交叉穿越现象。
最后采用 GroupTimeSeriesSplit 。
5. 模型构建
5.1 时序建模方法
5.1.1 日期因子规则方法
当序列存在 周期性 时;可参考 链接 - 时间序列规则法快速入门
- 计算周期因子;
- 计算周期平均值;
- 预测 = 因子 * 平均值
5.1.2 日期特征建模方法
当序列与 日期强相关 时;
- 星期从周一至周天,共 7 个变量;
- 节假日转化为 0-1 变量;
- 距离节假日的天数;
5.1.3 划窗建模方法
当序列 有长有短 时;
- 使用 时序交叉验证;
- 使用不同时间窗口统计;
5.1.4 序列建模方法
当 数据量足够大,且预测周期长;
- 可采用 LSTM / Seq2Seq 建模;
5.1.5 注意事项
- 是 自回归,还是 多元回归;
案例:利用前10天温度预测明天的温度;利用学生的体重、作业和睡眠预测成绩;
回归 和 自回归不是同一个问题。回归 是建立模型,是输入输出之间的固定关系,自回归 是时间序列模型,训练得到的模型表示了随时间变化的 y 之间的相互依赖性与相关性。参考链接 - 预测,回归,自回归的区别是什么?
回归预测:训练得到的回归模型表示了因变量 y y y (目标)与自变量 x x x ( x ∈ R n ) (x\in \mathbf{R}^n) (x∈Rn)(预测因子)之间的相关性,即一个或多个自变量对一个因变量的影响程度,适用于给定新的 x 来预测 y 的情况。
时间序列预测:训练得到的模型表示了随时间变化的 y 之间的相互依赖性与相关性,适用于预测未来一段时间内 y 的变化情况。参考链接 - 回归预测 OR 时间序列预测
- 需要预测 1天,还是需要预测 多天;
案例:利用前10天温度预测明天的温度;利用前10天温度预测下周七天温度;
5.2 时序建模工具库
1️⃣ Facebook-prophet,比较适合用在有周期性 自回归 场景,不适合 多元回归。
Prophet采用时间序列趋势分解法的模型,得到三个部分:- trend (趋势部分)
- seasonality (周期性部分,可以包括daily、weekly、yearly)
- holidays (假期影响因子)
y ( t ) = g ( t ) + s ( t ) + h ( t ) + ϵ t y(t)=g(t)+s(t)+h(t)+\epsilon_{t} y(t)=g(t)+s(t)+h(t)+ϵt
链接 - Facebook 时间序列预测算法 Prophet 的研究
2️⃣ tslearn
3️⃣ tsfresh 适合时序数据的关系抽取,适合 多元线性分类,回归 中特征提取功能,无建模功能。
tsfresh是处理时间序列的关系数据库的特征工程工具- 时间序列的基本特征,如峰数、平均值或最大值或更复杂的特征;
- 根据时序相关性筛选部分特征;
4️⃣ pyts 侧重于: 特征提取, 时序分类, 成像时间序列。⭐️
5️⃣ sktime
sktime是比较新的时序回归、预测库,提供了机器学习和深度学习方法。- 支持时序回归
- 时序分类
- 时序聚类
Prophet、tsfresh、pyts、sklearn 简单代码介绍
5.3 时序比赛常用模型
5.3.1 时序特征+树模型
注意事项:
- 构造时序特征时一定要算好时间窗口;
- 特征加上去效果会变差,大概率是因为 过拟合 了;
ont-hot(特征离散化) 对 树模型 效果的提升很显著
5.3.2 序列(多步)预测
用途:非单步预测,多步 / 值预测(预测多个值);
建模方法:seq2seq、WaveNet、transformer。transformer 理解
5.4 模型构建方法
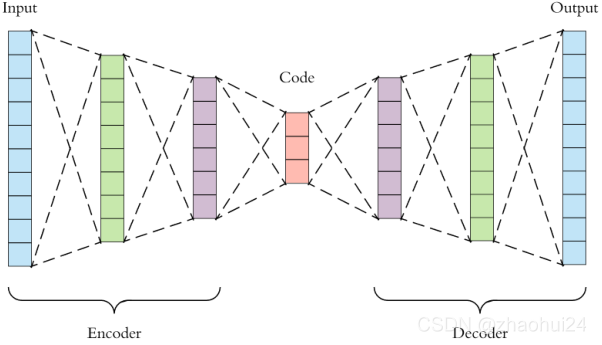
按照 自编码器 + MLP 思路:
- 对模型进行调参:加入随机网络搜索,但随机性比较大;
- 对模型数据进行归一化,增加随机性;
自编码器: x = decoder ( encoder ( x ) ) \text{x}=\text{decoder}(\text{encoder}(x)) x=decoder(encoder(x)),keras 代码实现相关细节,参考链接 - Building Autoencoders in Keras
- 编码器 + 解码器构成;
- 编码器:模型降维;
- 解码器:从 code 恢复;
降噪自编码器: x = decoder ( encoder ( x ~ ) ) \text{x}=\text{decoder}(\text{encoder}(\tilde{x})) x=decoder(encoder(x~))
- 输入的样本加入噪音;
尝试其它模型:
- XGB / CatBoost / LightGBM
- 在现有模型中加入 Bagging 思路;
6. 量化交易
量化 可称为 量化投资 或是 量化交易,以数量化方式及计算机程序化发出买卖指令,以获取稳定收益为目。
量化交易 相关博文描述 What is Quantitative Trading and How Do I Learn It?
6.1 量化交易介绍
量化交易包含
- 选股:可以帮你在几千只 A 股当中选择符合要求条件的股票
- 策略:选择买进、卖出、以及平仓的时机,管理仓位风险
…
量化交易 难点
- 信号很多(市场、政府、新闻、时政、汇率);
- 没有通用规则,每个股票使用的策略不同;
- 反人性,很多信息很难数字化,需要人工参与;
数据获取 工具
- 证券宝 - baostack
- Tushare 金融大数据开放社区
量化学习 平台
- 聚宽 - JoinQuant
- BigQuant AI 量化平台
- MindGo - 同花顺
6.2 量化策略模型
6.2.1 量化策略
策略:一系列预设的行为模式,分别在不同的触发条件会被启用。在证券交易中,策略是指当预先设定的事件或信号发生时,就采取相应的交易动作。
量化策略:行为模式中的事件或信号数字化,通过一套固定的逻辑来分析,而不是单凭人的感觉或直觉进行判断和决策。
策略周期:实现策略、检验策略、运行策略、策略失效;
策略流程:选股、触发、仓位、止盈止损;
6.2.2 量化选股模型:多因子模型
原理:采用一系列的因子作为选股的条件,满足因子的股票则买入,不满足则卖出;
优点:简单、比较稳定;
因子类型:公司、环境、市场等;
- 公司:财务指标、利润、负债等;
- 环境:宏观经济、利率、汇率等;
- 市场:资金流向、市场动量;

公司市值 v v v:公司技术指标 f f f 和权重 a a a 决定;
v = α 0 × f 0 + α 1 × f 1 + , … , α M × f M v=\alpha_{0} \times f_{0}+\alpha_{1} \times f_{1}+, \ldots, \alpha_{M} \times f_{M} v=α0×f0+α1×f1+,…,αM×fM
6.3 赛题数据剖析
赛题数据思考
- 赛题数据中哪些指标是与公司 往期股价(短期指标)相关的?
- 赛题数据中哪些指标是与公司 整体利润(中长期指标)相关的?
- 赛题数据中哪些指标是与 环境整体(与股票无关)相关的?
赛题数据是怎么来的?
- 赛题数据由多个股票 / 期货等金融商品构成;

上图训练集 dataframe 中,feature_1, feature_2, feature_5 是相同的,且都是在同一天,可以猜想这两条数据属于同一个金融商品。
# 以 特征71 为例子
for feature_71 in train_data['feature_71'].value_counts().index[:100]: # 这里也可以取少量值d0_same = train_data[np.abs(train_data['feature_71'] - feature_71) < 0.001] # 与 特征71 重复的if d0_same['feature_2'].value_counts().max() == 1 or d0_same['feature_1'].value_counts().max() == 1: # 假设 特征1 或者 特征2 无重复,跳过print('pass')continue# 用特征2出现次数最多的再做一次筛选d0_same = d0_same[d0_same['feature_2'] == d0_same['feature_2'].value_counts().index[0]]# print(d0_same.shape, np.mean(d0_same['resp'] > 0), np.std(d0_same['resp'] > 0)) d0_same[['resp', 'feature_1', 'feature_2', 'feature_69', 'feature_70', 'feature_71']]
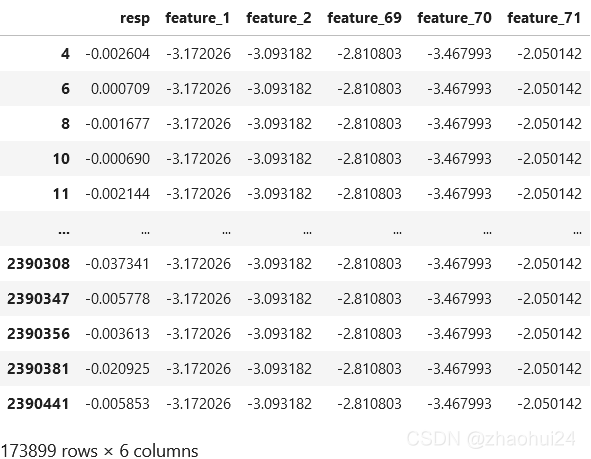
发现 feature_1, feature_2, feature_69, feature_70, feature_71 是相同的,它们很有可能是同一只股票。
- 赛题数据记录每次触发策略时该金融商品的信息;
可以去做
- 识别出训练集中每天的股票,从原始数据集中分析出来;
- 分析一只股票在一天变化的趋势,对 resp 的影响;
- 如果是一天内 resp 有变化;
- 如果是一天内 resp 无变化;
- 对股票进行跨天分析;
建模方法:对单天股票数据进行建模、对多天股票数据进行建模;
7. 模型调参
参数:能够从数据集中学到部分,超参数:需要人工提前设置。
模型 参数 是根据数据自动估算的,但模型 超参数 是手动设置的,并且在过程中用于帮助估计模型参数。
7.1 调参方法
参考链接 - Datawhale - 机器学习调参自动优化方法 ,可具体查看里面的代码。👍 👍
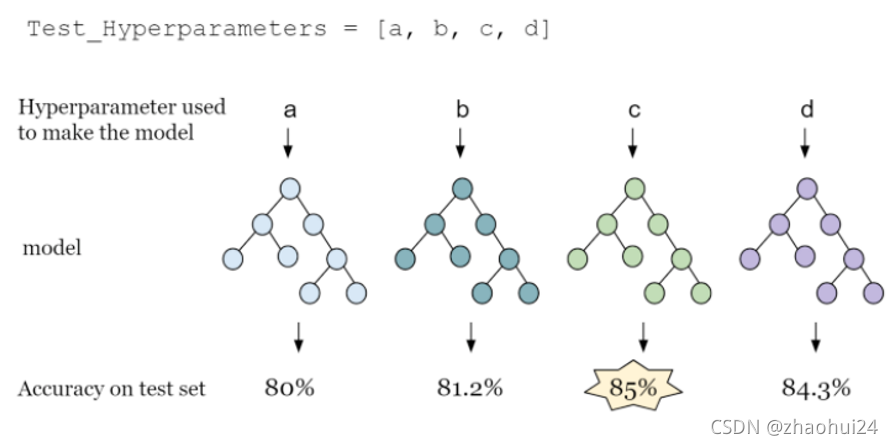
7.1.1 人工调参
模型超参数选择:通过验证集精度选择模型参数,类似人工筛选;
- 优点:靠谱的方法,需要较少的计算资源;
- 缺点:需要人工参与和人工知识;人工选择 [a, b, c, d] 这四个参数空间。
7.1.2 网格调参 & 随机调参
模型超参数选择:通过 网格搜索 和 随机搜索 选择参数;可参考 sklearn 链接。
- 优点:对参数空间进行完备的搜索;
- 缺点:计算量比较大;

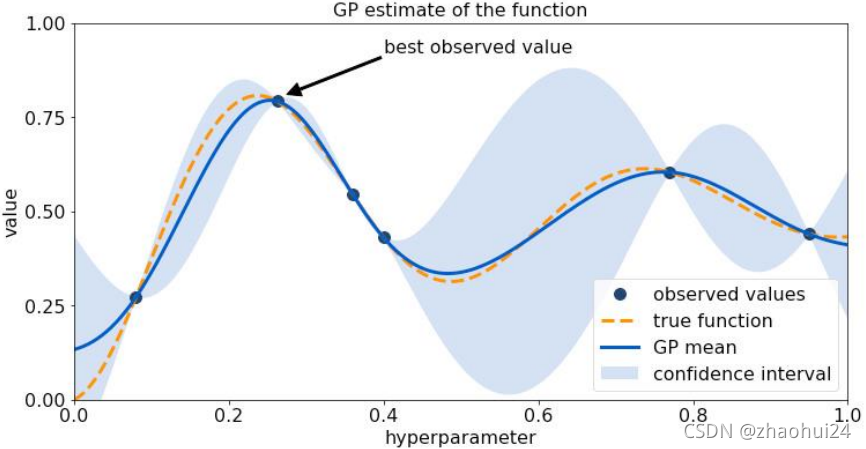
7.1.3 贝叶斯调参
模型超参数选择:通过贝叶斯优化或遗传算法
- 优点:能够减少参数搜索空间;
- 缺点:计算量较大
7.2 模型集成
参考链接 - Introduction to Python Ensembles,中文翻译版本 - 每个Kaggle冠军的获胜法门:揭秘Python中的模型集成 。
参考链接 - 机器学习与深度学习模型集成概述
参考链接 - datawhale - 模型融合方法最全总结! 👍 👍
深度学习中模型集成方法:
Dropout,方法:在训练过程中加入随机性;- Test Time Augmentation (
TTA),方法:在预测结果对样本加入数据增强;
- 测试集数据扩增(TTA)也是常用的集成学习技巧,数据扩增不仅可以在训练时候用,而且可以同样在预测时候进行数据扩增,对同一个样本预测三次,然后对三次结果进行平均。
- Snapshot Ensemble / Stochastic Weight Averaging,方法:训练过程中保存多个中间权重,进行集成;
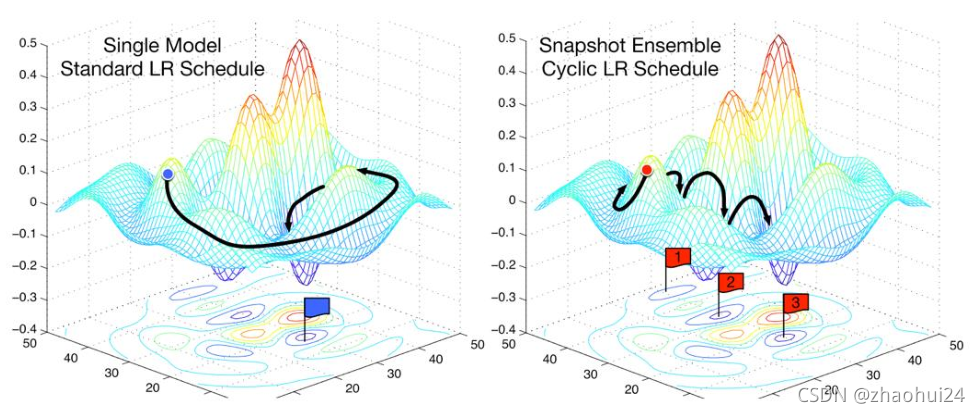
集成学习案例 - 信用卡交易欺诈数据检测 - 链接
7.3 深度学习调参工具
1️⃣ keras-tuner
keras-tuner 是 keras 环境下的调参工具,支持学习率、网络结构和预训练CNN网络进行搜索; 支持RandomSearch 和 Hyperband。
案例链接 - kaggle-JaneStreet - Bottleneck encoder + MLP + Keras Tuner 8601c5
2️⃣ hyperopt
hyperopt 是 给定损失函数下的参数搜索工具, 适合具体优化情况简单目标函数的搜索;支持Random Search、Tree of Parzen Estimators 和 Adaptive TPE。
3️⃣ ray
ray 是分布式调参工具,支持深度学习(Pytorch、TF和Keras)和机器学习;支持Population Based Training, Vizier’s Median Stopping, HyperBand。
4️⃣ nni ⭐️ ⭐️
nni 是 比较成熟的深度学习调参框架,支持主流的深度学习/机器学习框架;支持教全的调参方法。
案例链接 - KDDCUP 2019
代码实现库
参考链接 - 深度之眼 - 【Kaggle大赛】简街市场预测大赛指导(金融量化·时间序列·数据科学)
xgboost
keras -nn
catboost
lstm
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!