【Python实战】Python使用openpyxl实现读写文件
我们可以使用Python调用openpyxl库从而轻松实现对excel文件的读写等处理操作。
数据读取
原始数据
首先,我们要处理的文件数据如下所示:
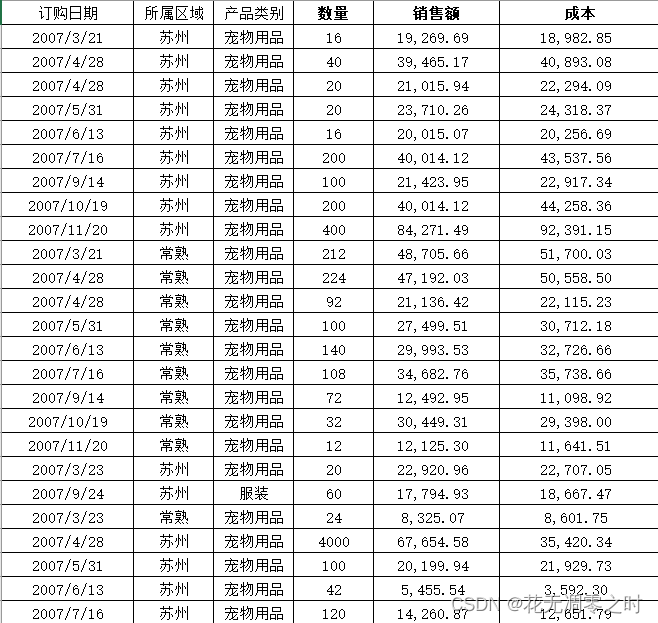
其中包含订购日期、所属区域、产品类别、数量、销售额、成本这几项。
我们要实现的功能为:从原始数据中找到特定城市和特定日期的数据,并依次按照产品类别、数量、销售额、成本以及利润(即销售额-成本)的形式输出成excel文件。
代码实现读取数据
我们可以使用openpyxl.load_workbook()方法进行读取,其中由于原始数据中有些数据是公式的形式,读进来成了str类型的,因此我们可以指定data_only=True,即将所有公式的结果都计算出来并只关注其数据本身。
由于第一行并不是数据,因此我们通过变量i除掉第一行。
filepath = "./" # 设置文件路径
book = openpyxl.load_workbook(filepath + "数据透视表.xlsx", data_only=True)
sheet = book.worksheets[2] # 读取第三个表单
i = 0
for row in sheet.rows:if i == 0: # 第一行不要i = 1continuerow_val = [col.value for col in row]if row_val[0].month == int(month) and row_val[1] == city: # 找出特定城市和月份的数据print(row_val) # testif row_val[2] not in products:products.append(row_val[2])nums.append(row_val[3])sales.append(float(row_val[4]))costs.append(float(row_val[5]))else:index = products.index(row_val[2])nums[index] += row_val[3]sales[index] += float(row_val[4])costs[index] += float(row_val[5])
这里我们再定义一个类将数据进行整合,从而实现数据的排序:
class Data:"""该类别包含一件产品的类别、数量、销售额、成本"""def __init__(self, product, num, sale, cost):self.product = productself.num = numself.sale = saleself.cost = cost# 对数据进行排序
for i in range(len(products)):print(products[i], nums[i], sales[i], costs[i]) # testdataset.append(Data(products[i], nums[i], sales[i], costs[i]))
dataset.sort(key=lambda x: x.num, reverse=True) # 将所有数据按照数量从大到小排序
数据写入
初步写入
我们先实现初步的写入,即设置文件名,工作表名字,以及统计单元格的宽度等,其中,利润那一列我使用了公式的输出,即E(i) = C(i) - D(i),实现让excel自动计算结果。
# 将处理后的数据写入文件
book = openpyxl.Workbook()
sheet = book.active
filename = city + month + "月销售情况.xlsx" # 输出文件名
sheet.title = filename # 工作表名字
sheet.append(["产品类别", "数量", "销售额", "成本", "利润"])col_len = [12, 6, 9, 6, 6] # 默认一个中文字符占3位,数字为总长度*2,初始值为第一行各列的长度# 插入数据
for i in range(len(dataset)):dataset[i].sale = round(dataset[i].sale, 2) # 浮点数四舍五入只保留小数点后两位dataset[i].cost = round(dataset[i].cost, 2)print(dataset[i].product, dataset[i].num, dataset[i].sale, dataset[i].cost) # testsheet.append([dataset[i].product, dataset[i].num, dataset[i].sale, dataset[i].cost])sheet["E" + str(i + 2)] = "={}-{}".format("C" + str(i + 2), "D" + str(i + 2)) # 设置利润公式# 更新最大列宽col_len[0] = max(col_len[0], len(dataset[i].product) * 3)col_len[1] = max(col_len[1], len(str(dataset[i].num)) * 2)col_len[2] = max(col_len[2], len(str(dataset[i].sale)) * 2)col_len[3] = max(col_len[3], len(str(dataset[i].cost)) * 2)col_len[4] = max(col_len[2], col_len[3], col_len[4])
优化
添加单元格颜色
我们可以设置第一行的单元格背景为绿色:
# 将第一行设置为绿色
rangeCell = sheet["A1:E1"] # 选取这一个范围的单元格
for r in rangeCell:for c in r:c.fill = PatternFill(patternType="solid", fgColor="00ff00")
设置列宽
由于数据长短不一,因此每列的单元格的宽度也不一样,我们可以自己手动设置,从而可以避免打开后出现###这种需要手动拉大的情况:
# 设置列宽
for i in range(1, sheet.max_column + 1):k = get_column_letter(i)sheet.column_dimensions[k].width = col_len[i - 1]
其中col_len在前面初步写入数据的时候就已经统计好了。
设置销售额、成本、利润都显示为带逗号的那种形式
有时候由于数字比较大,因此我们需要让数字显示为带逗号的那种形式方便我们查看:
# 设置销售额、成本、利润都显示为带逗号的那种形式
for i in range(2, sheet.max_row + 1):for j in range(3, sheet.max_column + 1):k = get_column_letter(j)sheet[k + str(i)].number_format = "#,##0.00" # 浮点数保留两位小数
设置文字居中对齐
我们也可以设置文字对齐方式:
# 设置文字居中对齐
for i in range(1, sheet.max_row + 1):for j in range(1, sheet.max_column + 1):k = get_column_letter(j)sheet[k + str(i)].alignment = Alignment(horizontal="center", vertical="center")
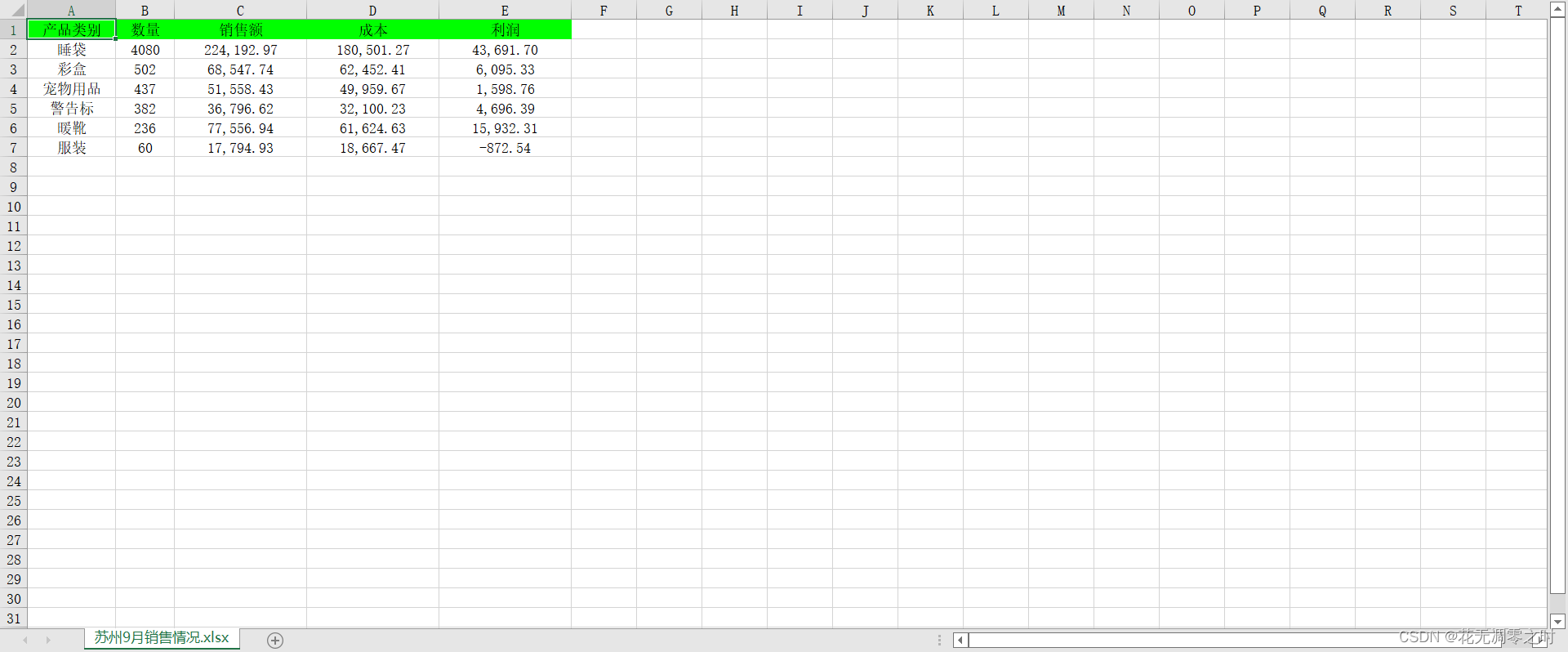
最后我们可以得到如下效果,假设我们选取的是苏州9月份的数据:
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!