python爬虫之多线程扒光北京新发地菜价
所实验网址:
http://www.xinfadi.com.cn/priceDetail.html
首先对网页进行分析:
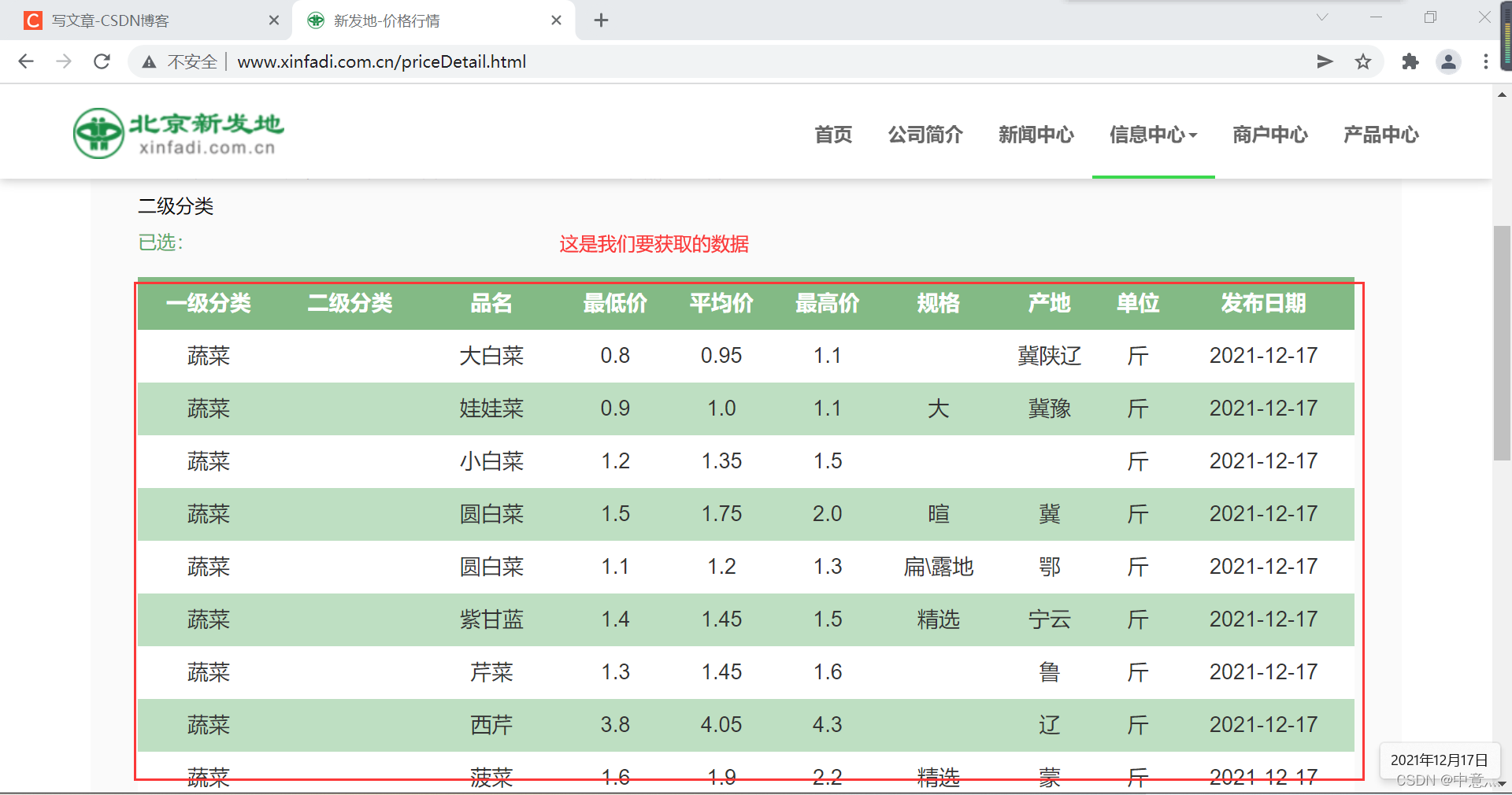
但是很显然,这些内容都不存在网页的源代码,所以这时候我们需要进行抓包
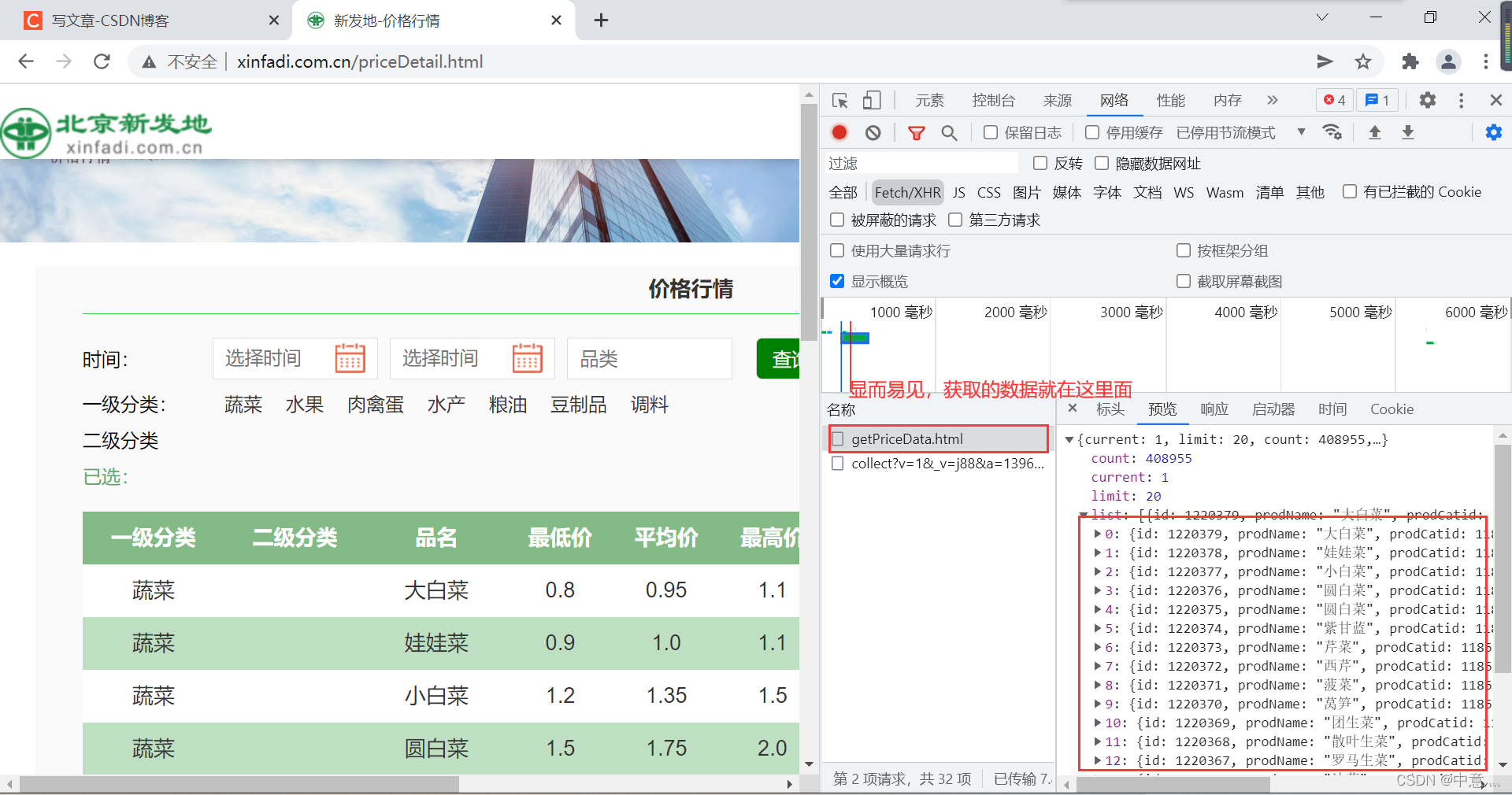
然后我们观察这个的url和请求方式,可以发现这是post类型,于是我们去找到他要传入的参数
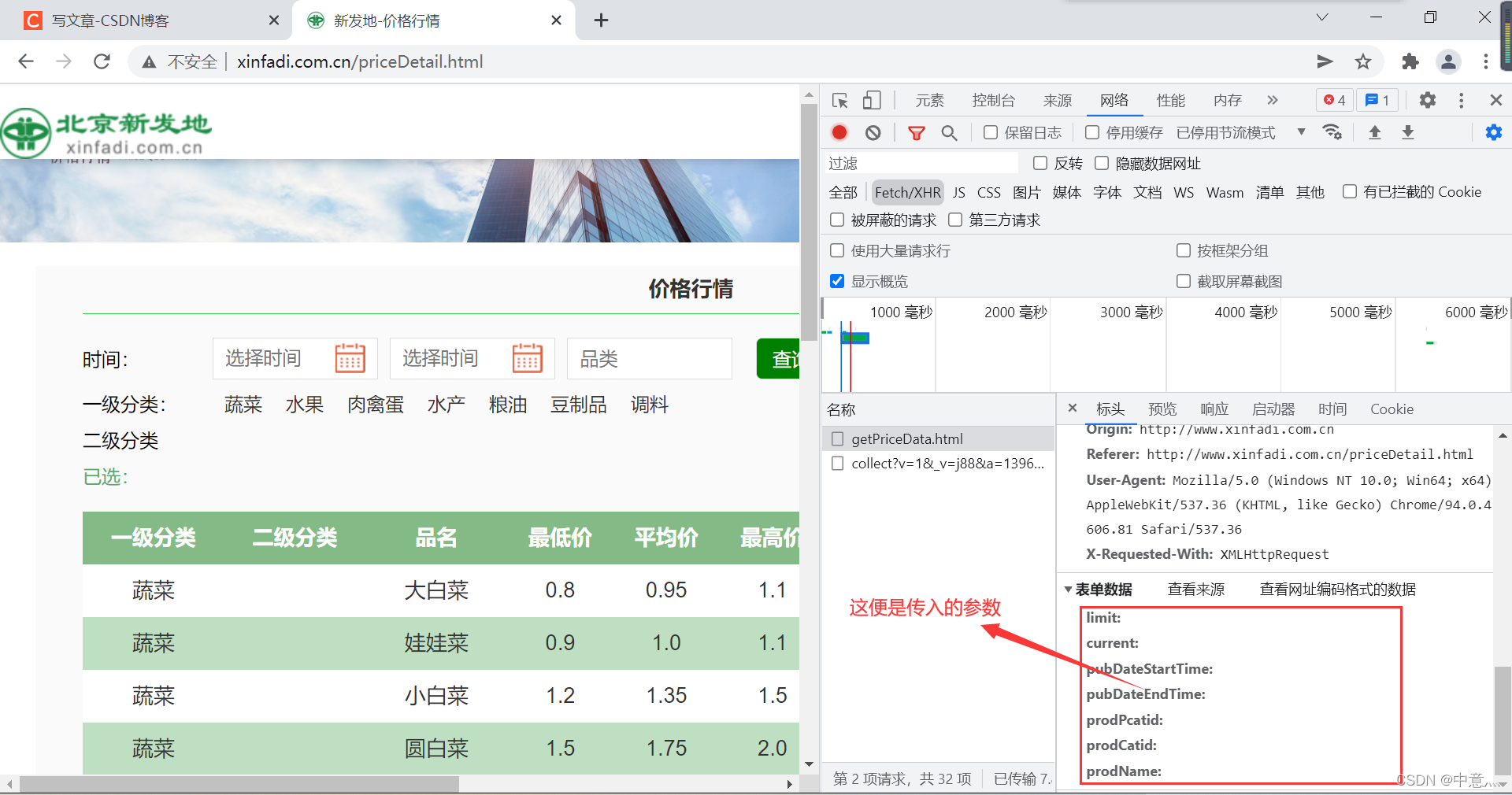
我们通过点击下一页,具体看看哪些是需要传入的
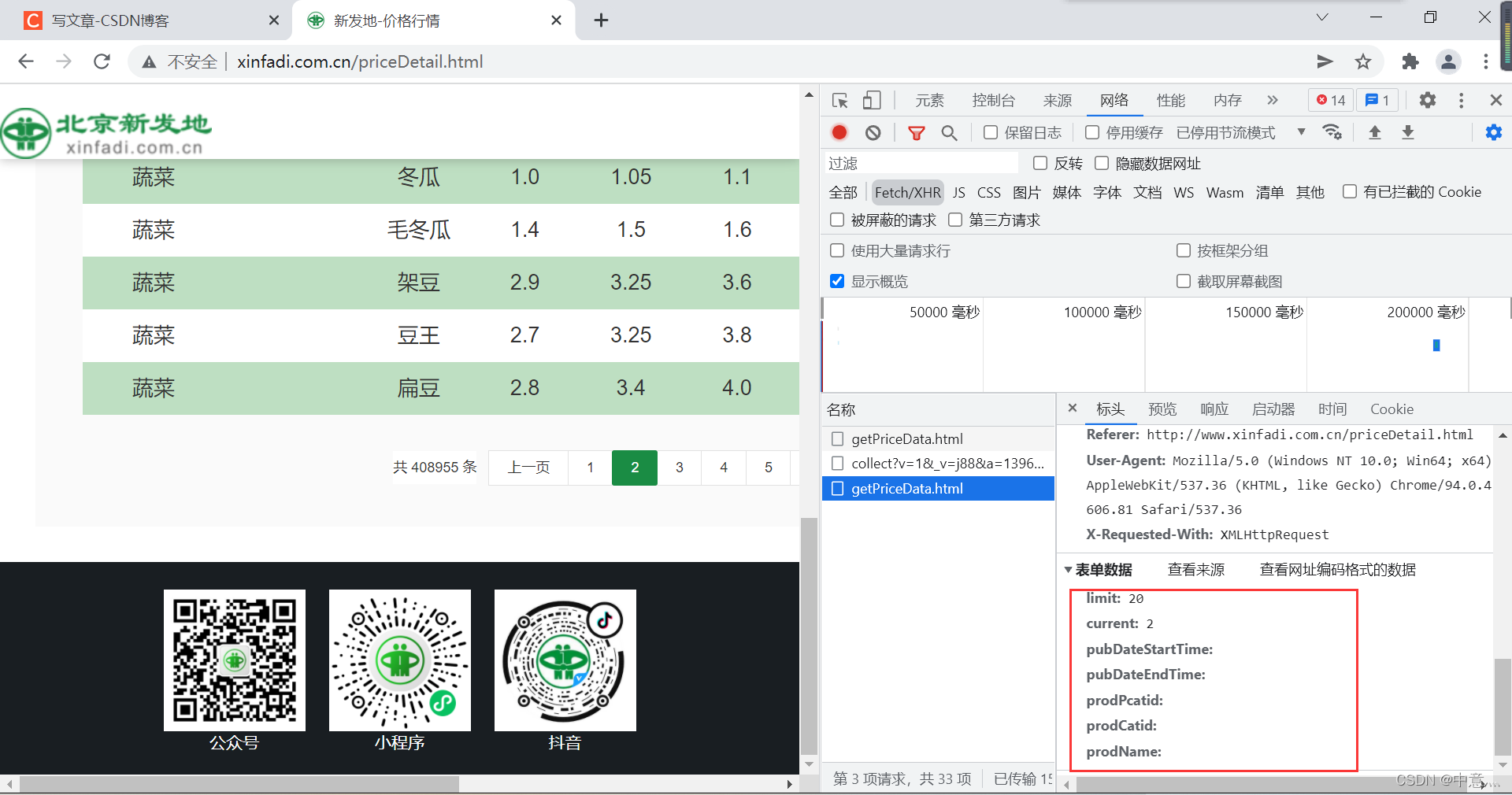
我们会发现,current是我们需要具体传入的参数,而他就是代表页数,而这个limit是表示每页出现的数据量只能有20条。
我们分析完网页后,我们就可以开始编写程序了,那么直接上代码:(有点提示,如果嫌运行慢,可以多增加线程个数,比如把1000个线程改为10000,这样就会快很多)
# @Time:2021/12/1710:05
# @Author:中意灬
# @File:新发地.py
# @ps:tutu qqnum:2117472285
import csv
from concurrent.futures import ThreadPoolExecutor
import requests
from bs4 import BeautifulSoup
with open('北京新发地菜价.csv',mode='w', encoding='utf-8',newline='') as f:wirter = csv.writer(f)#创建一个写入的对象wirter.writerow(['菜名', '最低价(元)', '最高价(元)', '平均价(元)', '产地','发布日期'])def get_one_page(pageNo):data={"limit":20,"current":pageNo,}url="http://www.xinfadi.com.cn/getPriceData.html"resp=requests.post(url,data=data)html=resp.json()list=html['list']# print(list)for i in list:if i['place']=='':i['place']='产地不详'wirter.writerow([i['prodName'],i['lowPrice'],i['highPrice'],i['avgPrice'],i['place'],i['pubDate']])if __name__ == '__main__':# get_one_page(1)with ThreadPoolExecutor(10000) as t:#创建10000个线程for i in range(1,20448):#所有页数t.submit(get_one_page,pageNo=i)print('over!')print('点赞不白嫖(狗头)')运行结果:

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!