【Python爬虫案例教学】超简洁代码采集原神所有角色信息
前言
(。・∀・)ノ゙嗨 大家好,这里是池鱼
原神是由米哈游制作发行的一款开放世界冒险游戏,号称全球玩家5600W,可以说是非常热门了
也就是没抵挡住诱惑,跟着朋友下载后,就开始玩了
不过刚开始对一些角色信息还不是很了解
趁着还会点python,就来采集采集这些角色的数据信息,详细了解一下吧
话不多说,今天咱们就来扒拉扒拉这个网站吧 👇


前期准备
工具

采集内容
所有角色的
- 基础介绍
- 中日语音
- 图片信息
分析数据来源
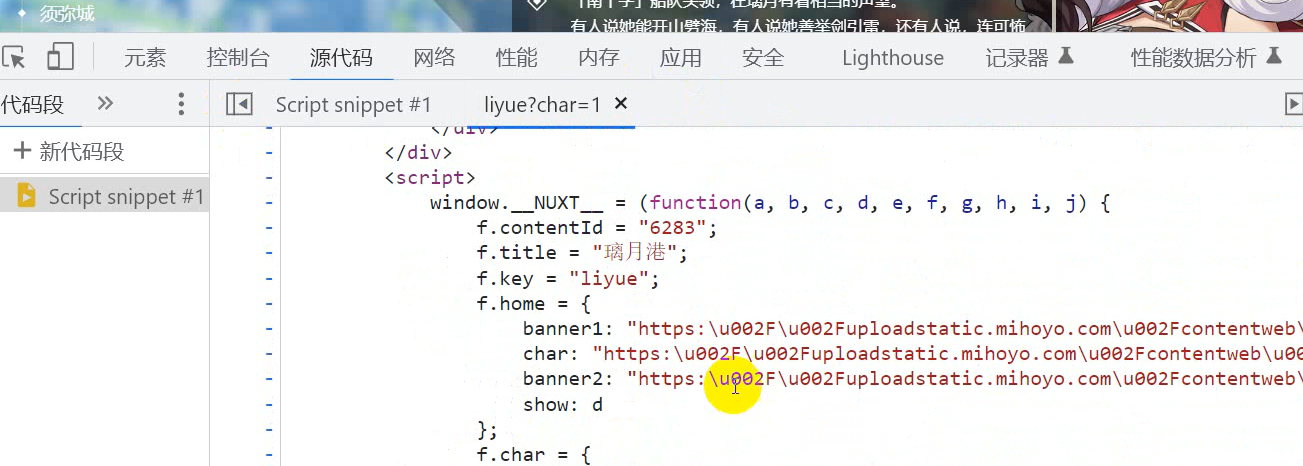
- 右键点击检查 [ 开发者工具 ]
- 刷新网页 找准对应的数据信息

实现代码
导入模块
完整代码点击领取即可
import requests
import re
import subprocess
代码中含有的网站就是这个,那么自行加上去吧,写代码里过不了审 😥
from functools import partial
subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")
import execjs
其他代码
html_data = requests.get(url).text
js_text = re.findall('window.__NUXT__=(.*);', html_data)[0]
result = execjs.eval(js_text)
# pprint.pprint(result)
python学习交流Q群:690643772 ### 源码领取
charList = result['data'][0]['charList']
for char in charList:cover1 = char['cover1']title = char['title']intro = char['intro']audio_list = char['cv'][0]['audio']print(title, intro, cover1, audio_list)

最后
今天的案例分享到这里就结束啦 赶紧去玩会游戏休息休息
对文章有问题的铁汁评论区留言,或者可以私信我哦

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!