推荐系统初等知识笔记
文章目录
- 前言
- 一: 推荐系统简介
- 二: 推荐系统的架构
- 三: 推荐算法
- 四: 推荐系统的评估
- 五: 推荐系统的冷启动问题
- 六 : LFM
- 七:基于内容的推荐算法用户的标签来自于哪儿
- 八: TF-IDF
前言
对学习相关内容收集到的资源进行整理,内容所有权不在本人
一: 推荐系统简介
推荐系统是不需要⽤户提供明确的需求,通过分析⽤户的历史⾏为给⽤户的兴趣进⾏建模,从⽽主动给⽤户推荐能够满⾜他们兴趣和需求的信息。是一个概率的问题。
而搜索引擎是在有明确需求的前提下进行内容查询
推荐系统有长尾效应,因为为了最大化利益,需要对每个人个性化定制而不能只推送点击率高的内容,需要对每个人正确推送那些比较冷门的但是符合人物属性的内容。即追求持续服务。推荐系统的目的是提高营收指标,而web等技术就是为了承接一个高并发数据等。
相反的是马太效应:遇强则强,尽可能只推给他需要的东西
社会化推荐:朋友关系的推荐
基于内容的推荐:输入一个演员名字,看看返回结果中还有没有什么喜欢的电影
基于流行度的推荐:按照票房的排行榜推荐,推荐热度内容,和用户个人的喜好较远
基于协同过滤的推荐:相似用户的推荐
推荐系统的应用场景:feed流,将内容喂给用户
二: 推荐系统的架构
前端界面,数据(lambda架构),业务知识,算法
Lambda架构:结合实时数据和Hadoop预先计算的数据环境和混合平台,提供一个实时的数据视图。(离线和实时)
Hadoop解决了分布式存储的问题
Hadoop MapReduce和Spark, hive解决了分布式计算的问题
存储的数据库:nosql(HBase/Cassandra),Redis,MySQL等
实时数据收集:flume 和 kafka
实时数据分析:spark streaming/storm/Flink,利用这些进行流式计算
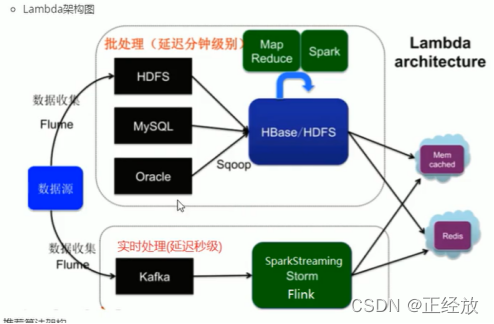
实时和离线的两方面共同计算,实时进行及时的改变,离线在处理之后进行推送
离线处理的数据量可以很大,但是慢
实时的毫秒级别相应,但是数据量小
推荐算法的架构:
召回:决定了最终推荐结果的天花板
常用算法:协同过滤(用户/物品),基于内容(挖掘用户喜好,利用NLP技术挖掘内容上相似的物品,逻辑回归找前几最大值),基于隐语义
排序阶段:排序依照召回实现,决定了最终的推荐效果
CTR预估:点击率预估(LR算法)估计用户是否会点击某个按键,需要用户的点击/访问数据
策略调整的过程:

三: 推荐算法
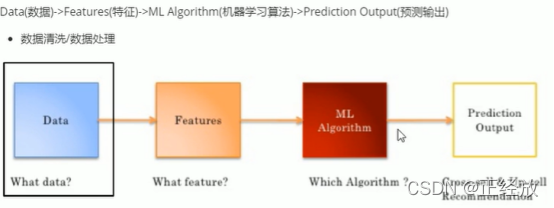
数据来源:
显性:用户的打分,用户评价
隐性:历史订单,购物车,页面浏览,点击,搜索记录
特征提取:协同过滤的例子
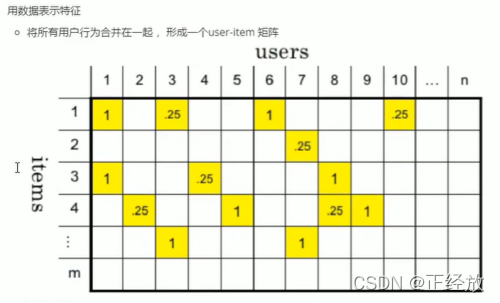
协同过滤:物以类聚,人以群分
User-based CF:CF就是协同过滤
Item-based CF
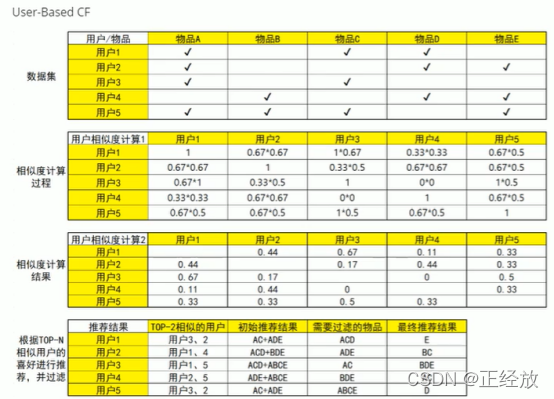
相似度计算:对于1,2两个用户,相似度是:(交集个数/A的集合大小) * (交集个数/B的集合大小)
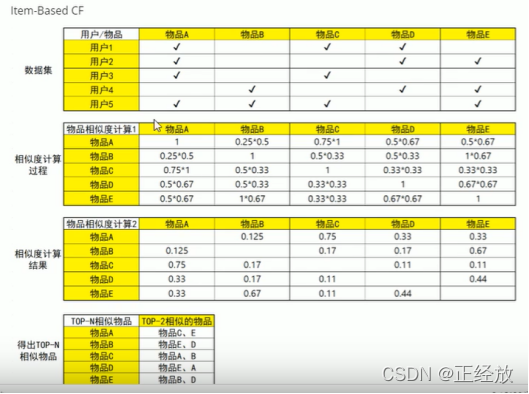
同样的对于物品的协同过滤,也是一样的计算方法。
而且能看出都是对相似度进行排序,取最高的k个项目所对应的集合并集进行推荐。
相似度的计算方法:
欧氏距离,越小两者越近
余弦相似度:
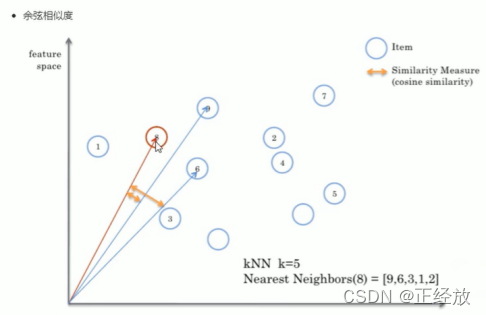
余弦相似度:主要关注的两个向量的夹角cos值,夹角越小会认为方向越相近,但是会遇到一个问题,忽略长度之后,(1,1)的评分和(5,5)的评分相似度会很高,会导致评分逻辑上的错误。于是就会用到以下的皮尔逊相似度。
皮尔逊相似度:

皮尔逊就是多了一步减均值的操作,使得拖后腿的慢向量变成了负值,让cos可以取到负数。
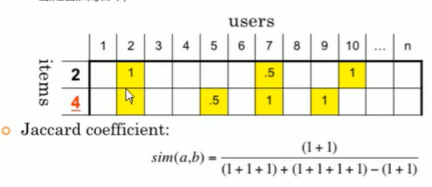
 杰卡德相似度:
杰卡德相似度:
适用于bool值列表的场景,分子是两者交集集合,分母是两集合相加减去交集的项目数
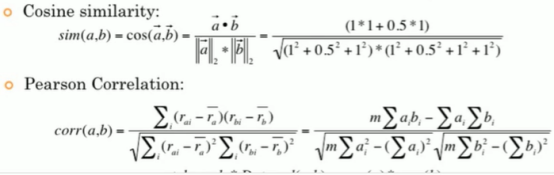
用户买过的物品,该物品的相似物品也可以推荐给用户
买过某物品的用户,也会将该物品推荐给相似的用户
如何使用以上的相似度:

实际上对于商业场景,很多用户只会对部分商品进行评分,矩阵将极其稀疏,于是有了以下的算法:
基于矩阵分解的方法:将在下面详细介绍
基于图模型的算法:可以通过metapath的形式对两个用户或者两个商品之间构建边相连
基于矩阵分解的方法:关键词:梯度下降法,ALS交替最小二乘法
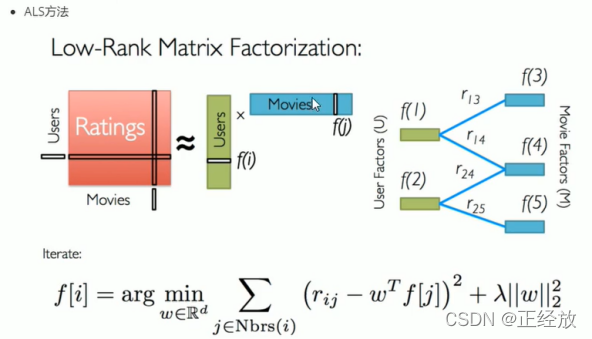

四: 推荐系统的评估
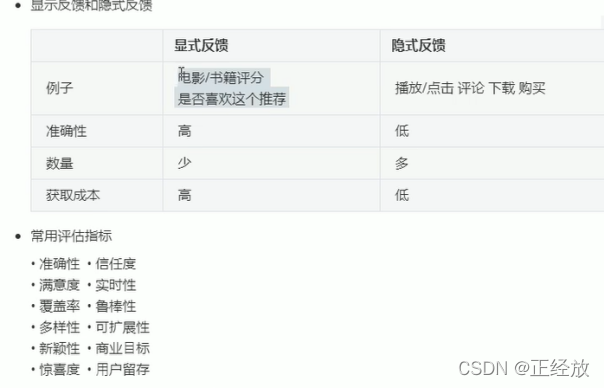


五: 推荐系统的冷启动问题
用户冷启动:尽可能收集用户的信息,性别年龄地区定位手机app社交信息推广素材安装来源,引导用户填写兴趣,使用该用户在其他站点的信息,新用户冷启动倾向于热门,老用户会需要考虑长尾推荐
物品冷启动:给物品打标签,利用物品的内容信息,将新物品先投放给(曾经喜欢过和他内容相似的其他物品的)用户——>基于内容的推荐
系统冷启动:早期做基于内容的推荐,随着用户行为的增多添加协同过滤步骤,最后将两者加权求和得到最终的结果
基于内容的推荐:
首先给物品打标签,然后利用NLP将标签转换成向量(word2vec),利用词向量构建物品的向量(N个关键词向量加权求和得到),进而计算相似度(pearson等)
标签的获取:物品属性,用户填写,并计算词的权重(td-idf和textrank)注:term frequency 是词频,inverse term frequency 是逆文档频率

td是本段落的占比,idf是在整个文章的占比
六 : LFM



因为定义了上图的损失函数,所以可以得到一个回归训练模型。

Baseline解决用户协同过滤的问题,计算出所有用户对所有物品评分的平均值之后,训练用户偏置和物品偏置,转换成了损失优化问题。
只需要训练Linear层就可以训练出
很大的好处就是可以训练稀疏的矩阵
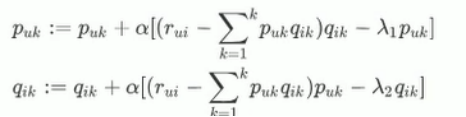
七:基于内容的推荐算法用户的标签来自于哪儿
PGC(专业生产内容)一般指商品自带属性、服务方设定的属性、爬虫获取属性等
UGC(生产内容)一般指用户在享受服务中提供的评论、话题等
根据PGC内容构建的物品画像可以解决物品的冷启动问题
基于内容的推荐算法流程:根据PGC/UGC内容构建物品画像,根据用户行为记录生成用户画像、根据用户画像从五品寻找最匹配的TOPN物品进行推荐
物品画像:分类信息,标题,主演歌手主题等
用户画像:喜好,活跃成都,人口学属性,风控维度
一般画像得有五六十条以上
八: TF-IDF
注:term frequency 是词频,inverse term frequency 是逆文档频率

td是本段落的占比,idf是在整个文章的占比
这样可以算出词语的权重大小,
基于内容推荐的流程
建立物品画像:1,用户打标签 2. 电影的分类值、
根据电影的id把标签和分类值合并起来,求tf-idf
根绝tf-idf的结果,为每一部电影筛选出top-n个关键词
电影id-关键词-关键词权重
建立倒排索引:通过关键词找到电影,遍历电影ID-关键词-关键词权重矩阵,读取每一个关 键词,用关键词作为key 关键词对应的电影id作为value保存到dict当中
用户画像:看用户看过哪些电影,在矩阵中找到电影对应的关键词,把用户看过的所有关键 词放到一起,统计词频,出现次数最多的关键词就是用户的兴趣词
根据用户的兴趣词,找到兴趣词对应的电影,多个兴趣词可能对应一个电影(将同一电影的 关键词权重求和作为该电影对用户的求和)
九: word2vec构建词向量
利用嵌入Skip-gram算法的w2v
Model = gensim.models.Word2Vec(sentences, size=100 ,window=3, min_count=1, iter=20)
各参数:
sentences (iterable of iterables, optional) – 供训练的句子,可以使用简单的列表,但是对于大语料库,建议直接从磁盘/网络流迭代传输句子。参阅word2vec模块中的BrownCorpus,Text8Corpus或LineSentence。
size (int, optional) – word向量的维度。
window (int, optional) – 一个句子中当前单词和被预测单词的最大距离。
min_count (int, optional) – 忽略词频小于此值的单词。
sg ({0, 1}, optional) – 模型的训练算法: 1: skip-gram; 0: CBOW.
iter (int, optional) – 迭代次数。
两个词向量的相似度比较高则这两个词是近义词
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!