YOLO-V4论文技术解读
其实我的每篇文章都是同步发到知乎和CSDN的,附上这篇文章的知乎地址吧,也欢迎大家关注哦https://zhuanlan.zhihu.com/p/391187134
附上YOLO-V3和V4的论文地址供大家下载!
YOLO-V4论文地址
YOLO-V3论文地址
【Object Detector】
这个是YOLO-V4论文中提到的有关目标检测的各个部分的一个汇总情况!下面单独介绍YOLO-V4这篇论文中具体用到的各项技术!
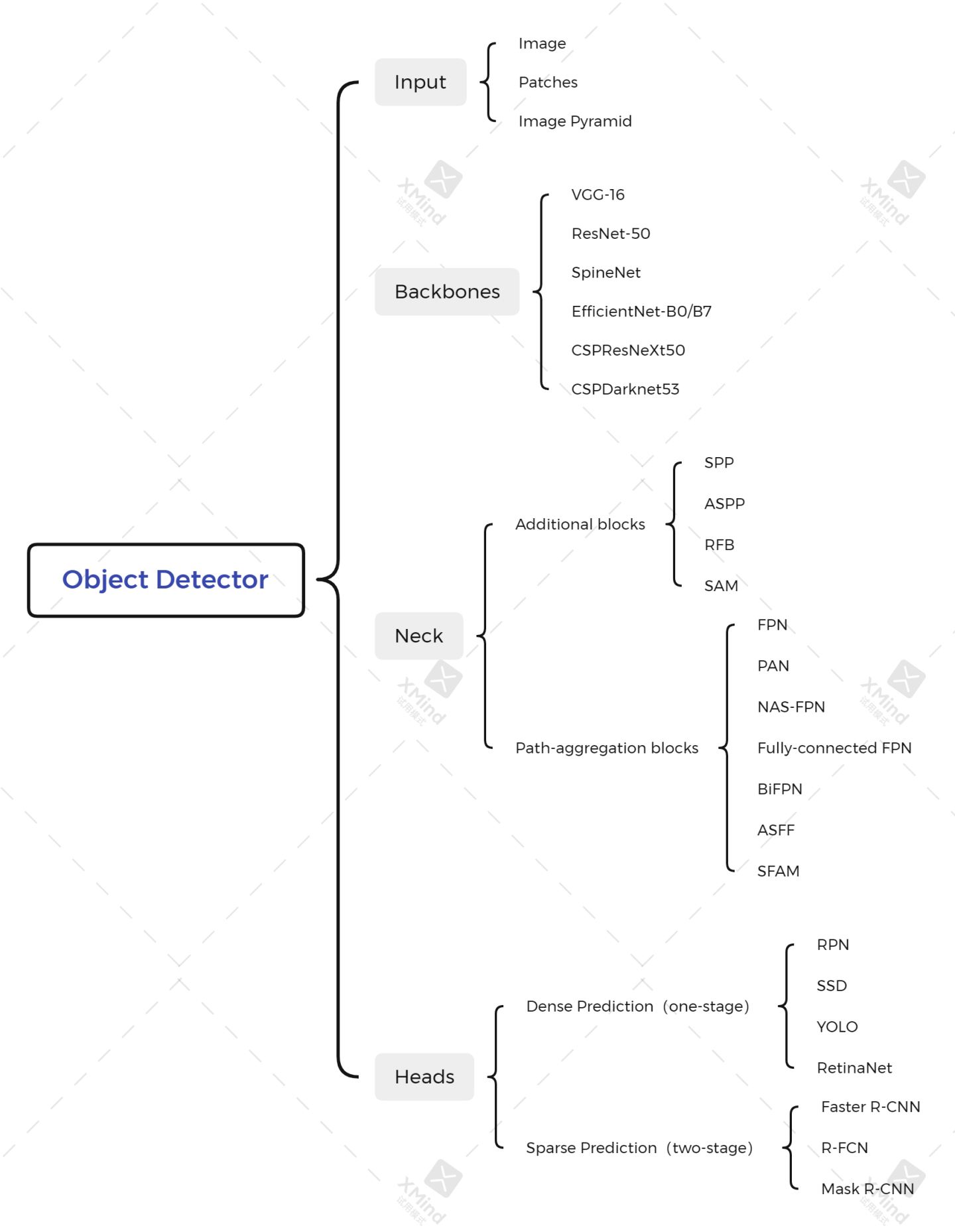
【网络结构图】
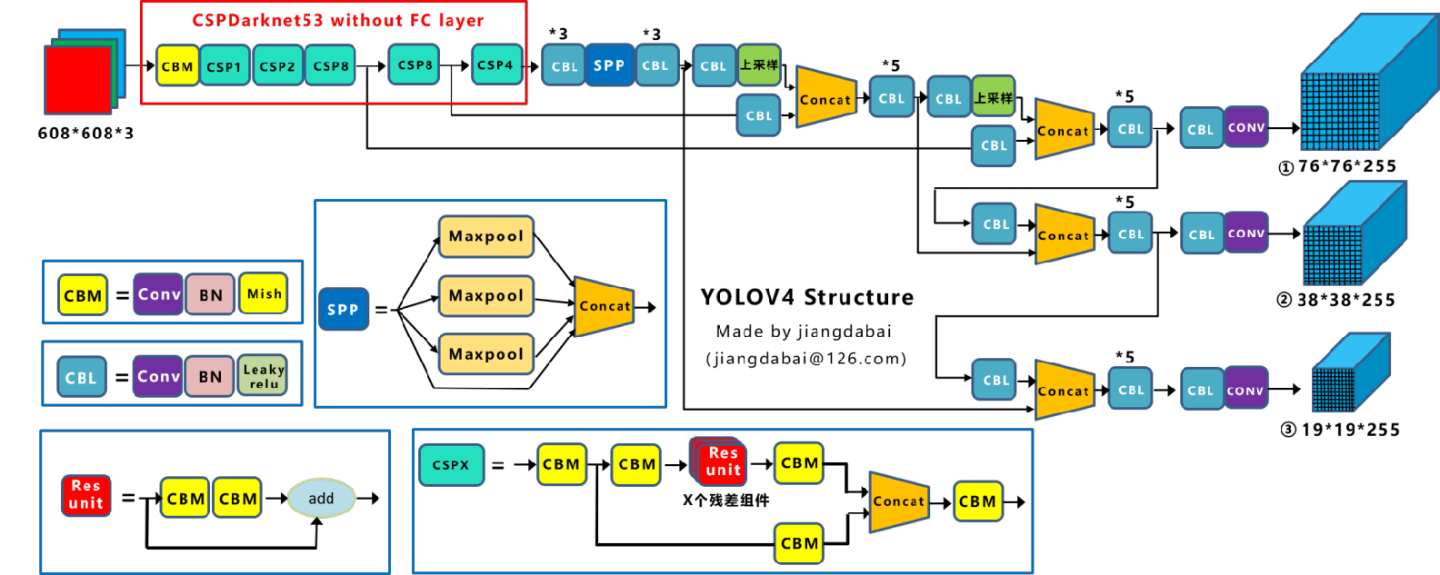
上面是YOLO-V4的网络结构图,取自作者https://blog.csdn.net/nan355655600/article/details/106246625
五个基本组件介绍如下:
-
CBM:Yolov4网络结构中的最小组件,由Conv+BN+Mish激活函数三者组成。
-
CBL:由Conv+BN+Leaky_relu激活函数三者组成。
-
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
-
CSPX:借鉴CSPNet网络结构,由卷积层和X个Res unint模块Concate组成。
-
SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
下面将进行各个部分的介绍!
【Mosaic数据增强】
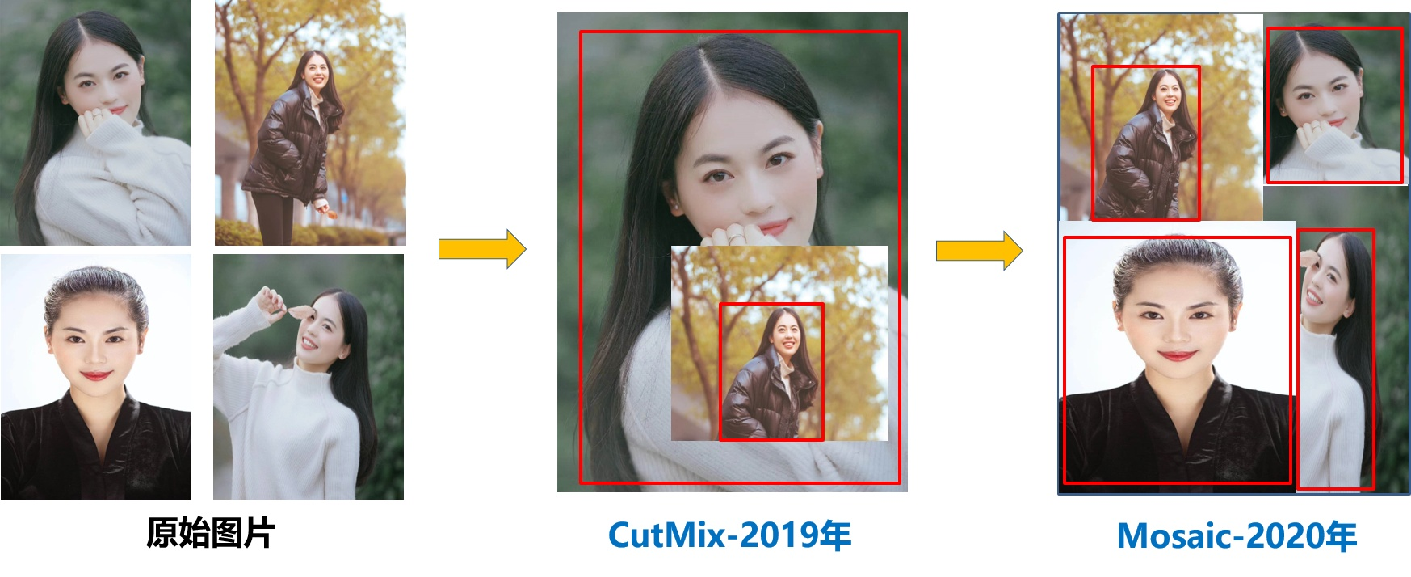

YOLO-V4中使用的Mosaic是参考2019年底提出的CutMix数据增强的方式,但CutMix只使用了两张图片进行拼接,而Mosaic数据增强则采用了4张图片,对4张图片均采用随机缩放、随机裁剪、随机排布等方式进行改造然后拼接在一起;
这样的好处有两个:
-
扩充了原有的数据集;
-
一定程度上增加了小样本的数量;
因为COCO数据集中小样本的占比虽然很大,但是过于集中在一部分图片中(通俗的讲 ,把10个苹果和5个香蕉分给5个人,一个人拿着10个苹果和一个香蕉,其余4个人每人拿一个香蕉,那么这样苹果虽然数量很多,但是过于集中),通过4合1之后,原先可能是大目标或者中目标就变成了中目标或者小目标,如下:
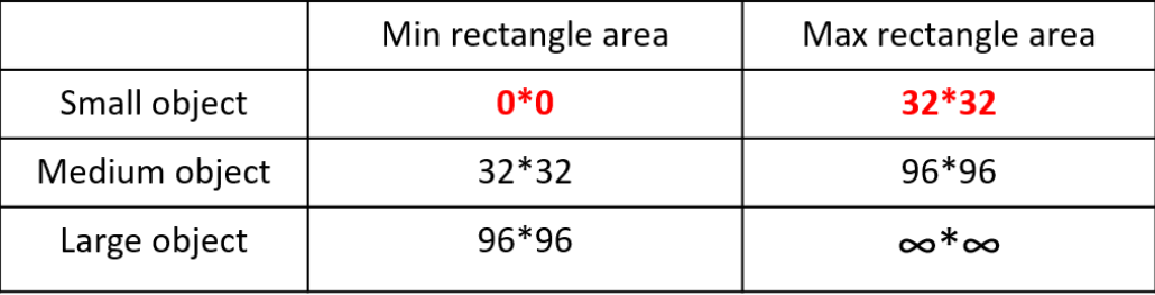
小/中/大目标的定义
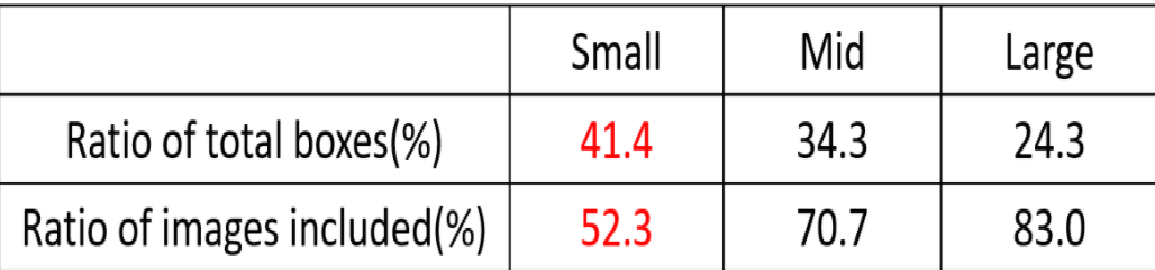
COCO数据集中的占比
附上之前专门写的各类数据增强的链接:数据增强汇总
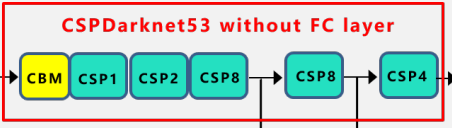
【CSPDarkNet53】
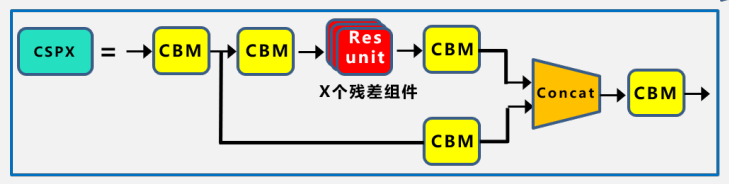
-
在Yolov3主干网络Darknet53的基础上,借鉴2019年CSPNet的经验,产生的BackBone结构,其中包含了5个CSP模块。
-
输入图像是608*608,所以特征图变化的规律是:608->304->152->76->38->19。
-
每一个block按照特征图的channel维度拆分成两部分,借助残差网络的思想,一份正常走网络,另一份直接Concat到这个block的输出,因为作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的,这样跨阶段层次结构将它们合并,可以减少计算量的同时保证准确率。
【Mish激活函数】
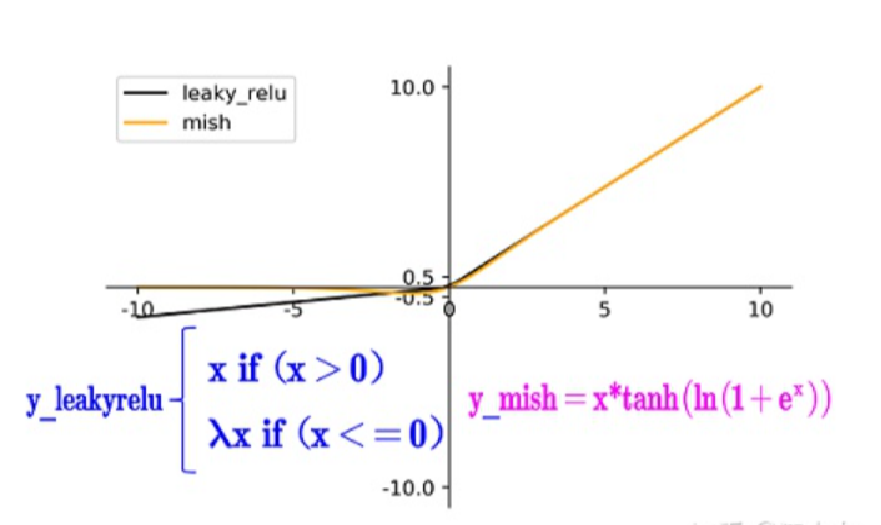
Mish激活函数
Mish激活函数:2019年下半年提出。
BackBone中使用了Mish激活函数,但后面的网络中还是使用了Leaky_relu激活函数。
【Dropblock正则化】
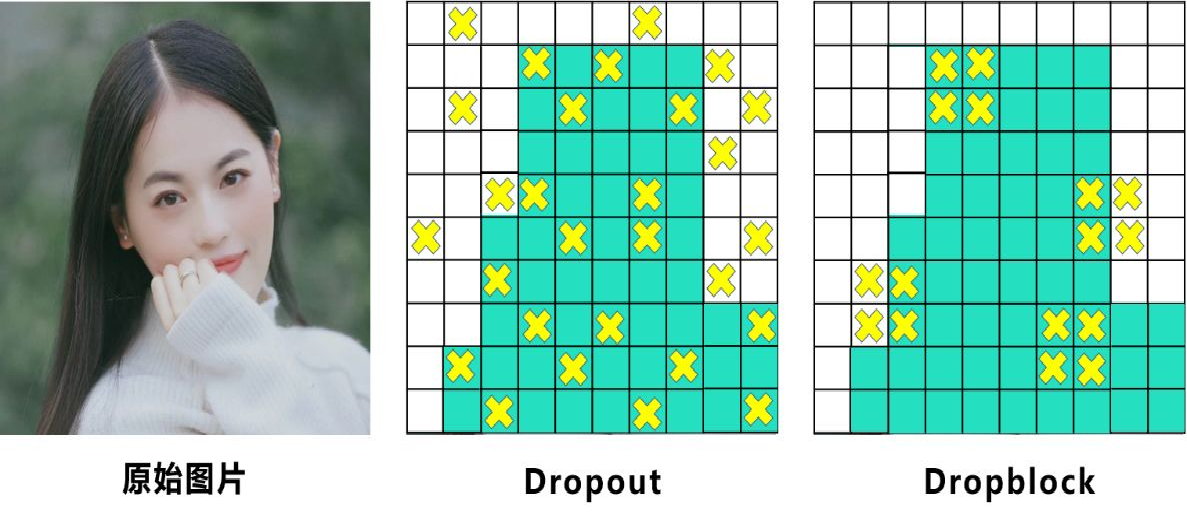
-
Dropout:随机删除丢弃一些信息,让网络变得简单;(但是因为卷积和池化本身就可以通过相邻的区域去提取特征,因此效果一般)
-
Dropblock:和常见网络中的Dropout功能类似,也是缓解过拟合的一种正则化方式,但是删除丢弃的是整个局部区域,能避免通过相邻的激活单元学习到相同的信息,借鉴的是2017年的cutout数据增强方式。
【FPN+PAN】
FPN论文地址:https://arxiv.org/pdf/1612.03144.pdf
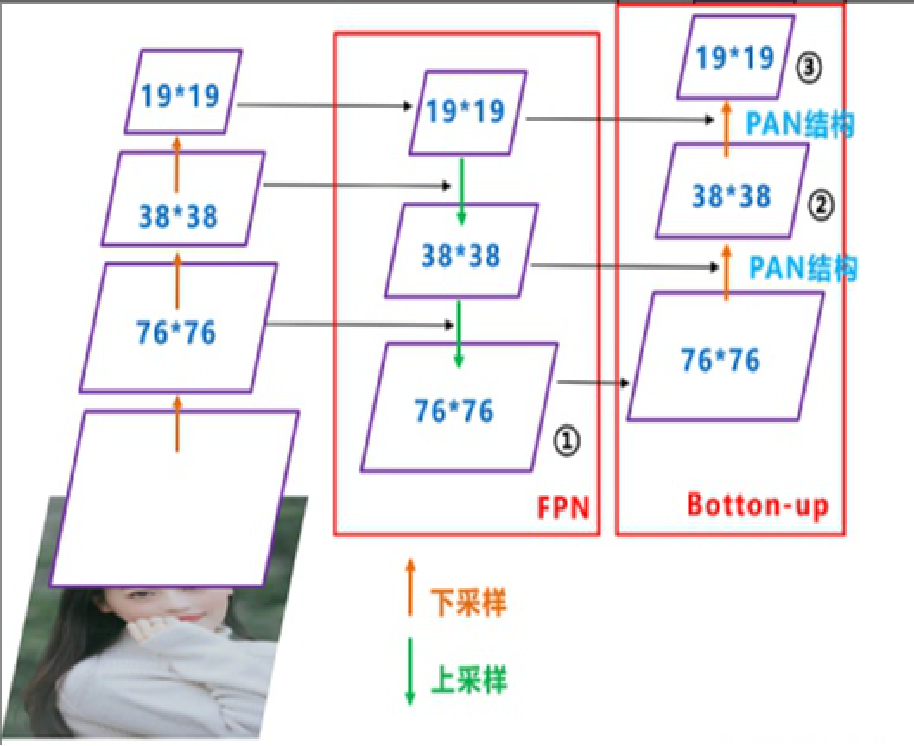
FPN+PAN:借鉴18年的PANet
FPN层自顶向下传达强语义特征,
PAN结构自底向上传达强定位特征;
YOLO-V3的FPN层输出的三个大小不一的特征图直接进行预测;
YOLO-V4的FPN层,只使用最后的一个76*76特征图,而经过两次PAN结构,分别输出预测的特征图。
【Prediction部分Loss的演进】
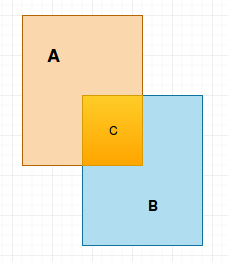
一、IOU
在目标检测当中,有一个重要的概念就是 IOU,一般指代模型预测的 bbox 和 Groud Truth 之间的交并比,如下图所示:
公式:
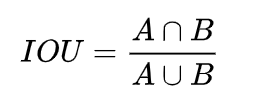
但上述公式存在诸多问题,比如:

问题1:即状态1的情况,当预测框和目标框不相交时,IOU=0,无法反应两个框距离的远近,此时损失函数不可导,IOU_Loss无法优化两个框不相交的情况;
问题2:即状态2和状态3的情况,当两个预测框大小相同,两个IOU也相同,IOU_Loss无法区分两者相交情况的不同。
二、GIOU_Loss
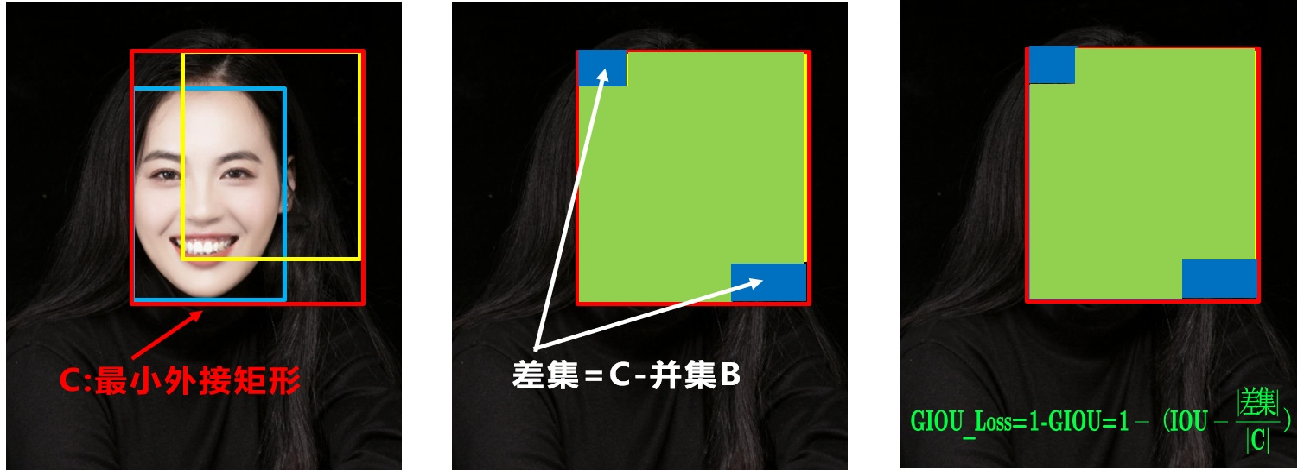
GIOU_Loss:引入最小外接矩形
在以往基础上,引入了最小外接矩形的概念(图示),此时会有差集和并集;
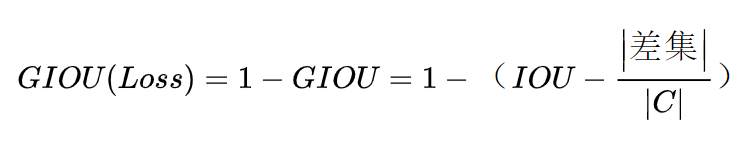
三、DIOU_Loss
所谓道高一尺、魔高一丈:

GIOU_Loss存在的问题:
假设现在状态1、2、3都是预测框在目标框内部且预测框大小一致,这时预测框和目标框的差集都是相同的,因此这三种状态的GIOU值也都是相同的,这时GIOU退化成了IOU,无法区分相对位置关系。
于是,又在考虑了重叠面积之后,又考虑了中心点的距离引出DIOU_Loss,当目标框包裹预测框的时候,直接度量两个框的距离。

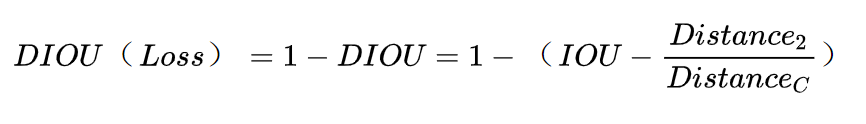
四、CIOU_Loss
但是,又来但是了(手动d狗头),魔高一丈又来了……
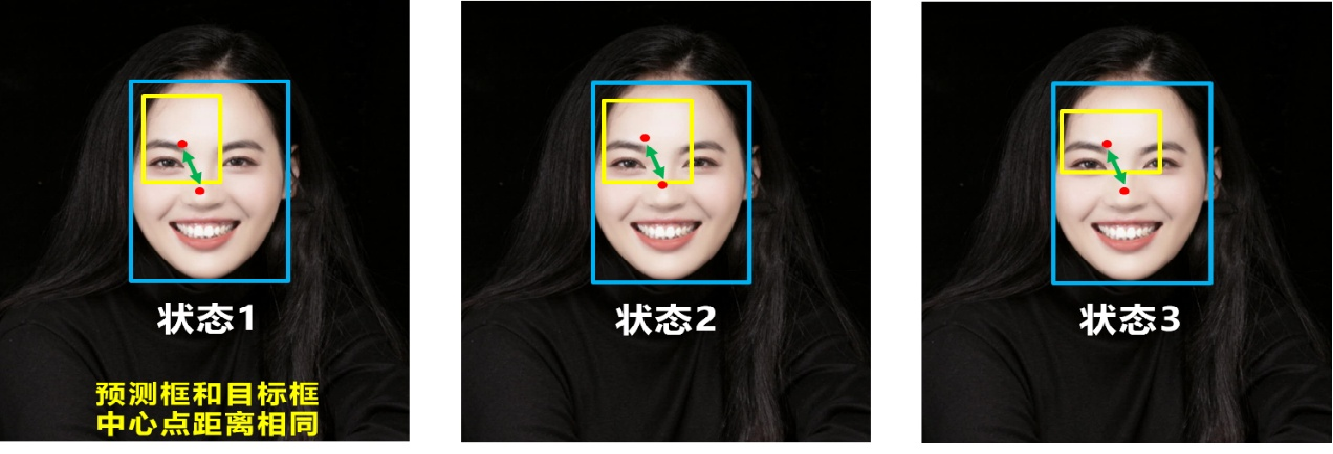
可以发现,上面三个的DIOU_Loss值是一样的,即当重叠面积相同且预测框和目标框中心点距离相同时,就又出问题了!
这个时候又引进了CIOU_Loss:增加了一个影响因子,将预测框和目标框的长宽比都考虑了进去,公式如下:

注释: 代表真实框宽度,
代表真实框高度;
代表预测框宽度,
代表预测框高度!
综上,一个好的目标框回归函数应该考虑三个重要几何因素:重叠面积、中心点距离,长宽比!
汇总:
-
IOU_Loss:主要考虑检测框和目标框重叠面积。
-
GIOU_Loss:在IOU的基础上,解决边界框不重合时的问题。
-
DIOU_Loss:在IOU和GIOU的基础上,考虑重叠面积和边界框中心点距离的信息。
-
CIOU_Loss:在DIOU的基础上,考虑边界框宽高比的尺度信息。
以上就是关于YOLO-V4各个方面的一些介绍,其实原论文自己还没有完全看完,也看了好多这篇论文的相关介绍,这是目标检测领域非常好的一篇论文,很有价值去读,希望大家仔细研读,也欢迎评论区随时交流批评我哦!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!