CrossEntropyLoss改进
文章目录
前言
CrossEntropyLoss 是分类任务中经常使用的损失函数,但是在某些情况下,其优化效果并不是很好,本文介绍了最近出现的对CrossEntropyLoss进行改进的新损失函数
一、CrossEntropyLoss
公式:

上图是pytorch版实现的CrossEntropyLoss,可以看出其主要作用是优化了正例对应的logits(logits介绍见上一篇博文)并使其无限大与其他类别的logits,这种过强的要求可能使得模型难以训练至收敛,因而出现了LabelSM版本的CrossEntropy,以及Sparse Softmax
顺带提一句,pytorch版本的CrossEntropyLoss是对dim=1进行的计算,
因而我们需要把各个类别的logits放到dim=1上来
二、SmoothCrossEntropy
公式:
SmoothCrossEntropy对应的公式为:
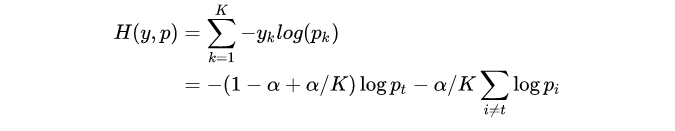
优势:
当 label smoothing 的 loss 函数为 cross entropy 时,如果 loss 取得极值点,则正确类和错误类的 logit 会保持一个常数距离,且正确类和所有错误类的 logits 相差的常数是一样的,都是 log ( K − ( K − 1 ) α α ) \log(\frac{K-(K-1)\alpha}{\alpha}) log(αK−(K−1)α)
证明见:知乎
code:
class SmoothCrossEntropy(nn.Module):"""loss = SmoothCrossEntropy()input = torch.randn(3, 5, requires_grad=True)target = torch.empty(3, dtype=torch.long).random_(5)output = loss(input, target)"""def __init__(self, alpha=0.1):super(SmoothCrossEntropy, self).__init__()self.alpha = alphadef forward(self, logits, labels):num_classes = logits.shape[-1]alpha_div_k = self.alpha / num_classestarget_probs = F.one_hot(labels, num_classes=num_classes).float() * \(1. - self.alpha) + alpha_div_kloss = -(target_probs * torch.log_softmax(logits, dim=-1)).sum(dim=-1)return loss.mean()
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
三、Sparse Softmax
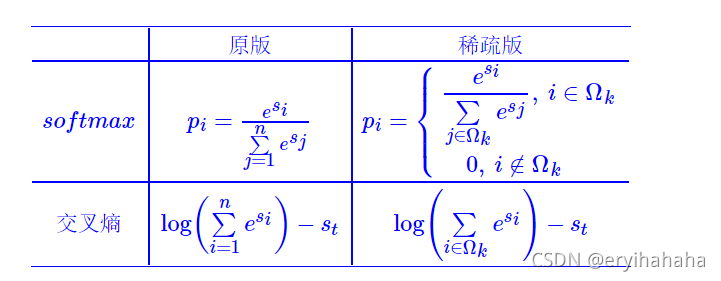
公式:
优势:
这是苏神在CAIL2020中提出的一个类别数过多的预测问题损失函数,我们只需要优化前topK项,使得 s t s_t st 大于topk即可,不必要大于最小的 log ( n − 1 ) \log(n-1) log(n−1)
,只需大于topk中最小的 l o g ( k ) log(k) log(k)即可,可以防止过度训练
证明
pytoch版本:
def Sparse_Softmax(predictions, token_type_id, input_ids, vocab_size):predictions = predictions[:, :-1].contiguous()target_mask = token_type_id[:, 1:].contiguous()"""target_mask : 句子a部分和pad部分全为0, 而句子b部分为1"""predictions = predictions.view(-1, vocab_size)labels = input_ids[:, 1:].contiguous()labels = labels.view(-1)target_mask = target_mask.view(-1).float()# 正losspos_loss = predictions[list(range(predictions.shape[0])), labels]# 负lossy_pred = torch.topk(predictions, k=args.k_sparse)[0]neg_loss = torch.logsumexp(y_pred, dim=-1)loss = neg_loss - pos_lossreturn (loss * target_mask).sum() / target_mask.sum() ## 通过mask 取消 pad 和句子a部分预测的影响L-Softmax、SM-Softmax、AM-Softmax待补充
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!