MapJoin工作机制
如果不指定MapJoin或者不符合mapJoin的条件,那么HIve解析器会将Join操作转换成Common Join,也就是说在reduce阶完成Join容易发生数据倾斜。
mapJoin工作机制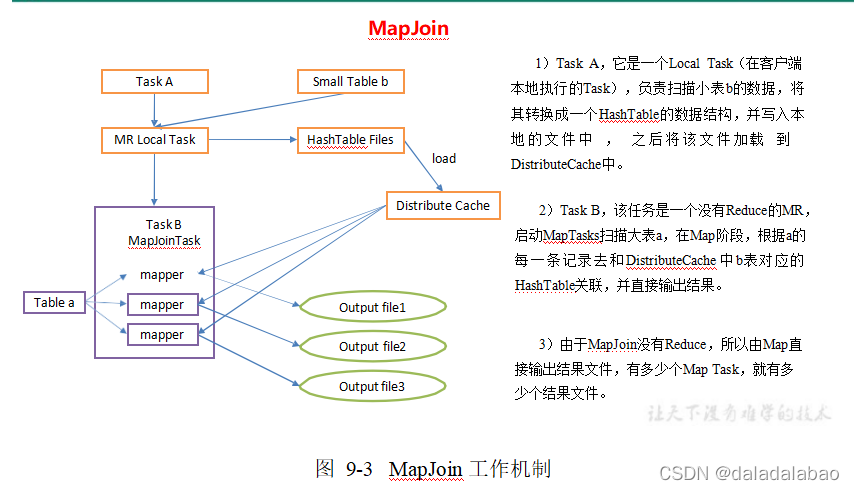
- 通过mapReduce Local Task,将小表读入到内存中生成HashTableFiles 上传到Distributed Cache中,对HashTableFiles进行压缩
- MapReduce Job在Map阶段,每个Mapper从Dristributed Cache 读取HashTableFiles 到内存,顺序扫描大表,在Map阶段直接进程Join,将数据传递给下一个MapReduce
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!