sql_in_action
SQL面试题:畅销商品分析
某互联网公司数据分析岗位SQL面试题,要求计算每个卖家销量最高的商品。
-- 商家卖货记录表
CREATE TABLE t5 (seller_id int, buyer_id int, item_id int, num int);
INSERT INTO t5 VALUES (1, 11, 1, 100), (1, 12, 1, 200), (1, 12, 2, 300);
INSERT INTO t5 VALUES (2, 11, 1, 100), (2, 12, 3, 200);-- 计算每个卖家销量最高的商品
SELECT seller_id,item_id,total FROM (
SELECT seller_id,item_id,SUM(num) AS total,RANK() over(PARTITION BY seller_id ORDER BY SUM(num) DESC) AS rk FROM t5 GROUP BY seller_id,item_id) s where s.rk=1;数据分析岗位SQL面试题:自建商品销量占比
某互联网公司数据分析岗位SQL面试题,要求计算每个商家的自建商品销量占总销量的比例。
-- 商家卖货记录表
CREATE TABLE t4 (seller_id integer, buyer_id integer, item_id integer, order_cnt integer, price numeric, source_type tinyint);
INSERT INTO t4 VALUES (1, 11, 1, 5, 9.9, 1), (1, 12, 2, 15, 16.9, 0);
INSERT INTO t4 VALUES (2, 13, 3, 10, 89.9, 0), (2, 14, 4, 11, 1999, 0);-- 商家自建商品销售量占比
SELECT seller_id, SUM(CASE source_type WHEN 1 THEN order_cnt ELSE 0 END)/SUM(order_cnt) AS ratio FROM t4 GROUP BY seller_id;数据分析岗位SQL面试题:累计销售金额
某互联网公司数据分析岗位SQL面试题,要求计算每个用户首次销售日期后 30 天内累计销售金额。
CREATE TABLE t3 (user_id integer, sell_day date, amount NUMERIC);
INSERT INTO t3 VALUES (1, '2021-01-01', 100), (1, '2021-01-30', 100), (1, '2021-02-01', 100);
INSERT INTO t3 VALUES (2, '2021-01-01', 200), (2, '2021-01-11', 200), (2, '2021-01-12', 200);-- 用户id 首次销售日期 30天内累计销售金额
SELECT s.user_id, s.first_day, SUM(t3.amount) AS total
FROM
(SELECT user_id, MIN(sell_day) AS first_day FROM t3 GROUP BY user_id) s
JOIN t3 ON (t3.user_id = s.user_id AND t3.sell_day BETWEEN s.first_day AND s.first_day + INTERVAL '30' DAY)
GROUP BY s.user_id, s.first_day;
某互联网公司SQL面试题:计算直播间的人气值
某互联网(直播带货)公司数据分析师岗位SQL面试题解析,这一题要求计算直播间人气值ACU。ACU 为平均同时在线人数(Average concurrent users),计算方式为:观众侧观看时长/某场直播的开播时长,没有人观看的时候显示为 0。
-- 开播记录表
CREATE TABLE t1 (author_id integer, live_id integer, live_duration integer);
INSERT INTO t1 VALUES (1, 1, 60), (2, 2, 120), (3, 3, 60);-- 观看记录表
CREATE TABLE t2 (user_id integer, live_id integer, watching_duration integer);
INSERT INTO t2 VALUES (11, 1, 60), (12, 1, 30), (13, 1, 60);
INSERT INTO t2 VALUES (12, 2, 30), (14, 2, 90);SELECT t1.author_id, t1.live_id, COALESCE(SUM(t2.watching_duration)/t1.live_duration, 0) AS acu
FROM t1
LEFT JOIN t2 ON (t1.live_id = t2.live_id)
GROUP BY t1.author_id, t1.live_id;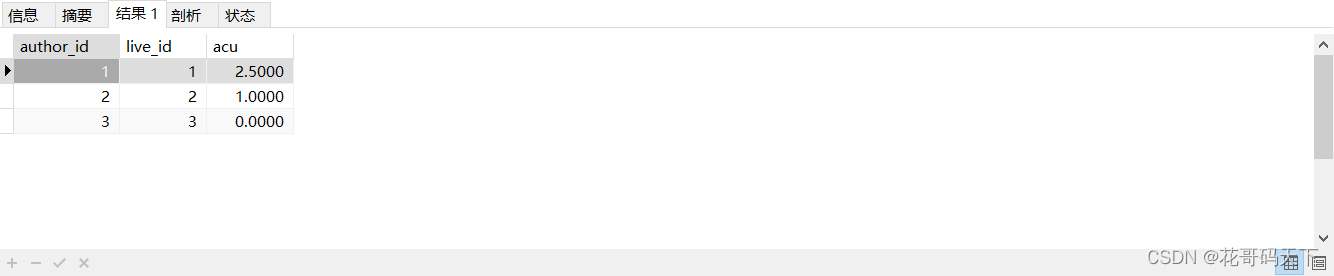
SQL案例分析:地铁换乘线路查询
介绍了SQL递归查询(WITH)的原理,利用递归获取北京查询地铁换乘路线,例如从“王府井”到“积水潭”。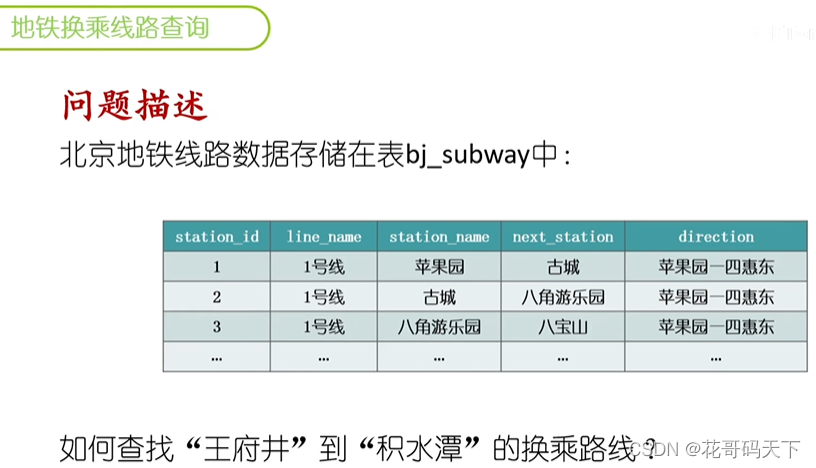
-- 创建地铁线路表
CREATE TABLE bj_subway(station_id INT NOT NULL PRIMARY KEY,line_name VARCHAR(20) NOT NULL,station_name VARCHAR(50) NOT NULL,next_station VARCHAR(50) NOT NULL,direction VARCHAR(50) NOT NULL
);-- 初始化数据,目前只有1号线、2号线和8号线的数据
INSERT INTO bj_subway VALUES (1,'1号线','苹果园','古城','苹果园—四惠东');
INSERT INTO bj_subway VALUES (2,'1号线','古城','八角游乐园','苹果园—四惠东');
INSERT INTO bj_subway VALUES (3,'1号线','八角游乐园','八宝山','苹果园—四惠东');
INSERT INTO bj_subway VALUES (4,'1号线','八宝山','玉泉路','苹果园—四惠东');
INSERT INTO bj_subway VALUES (5,'1号线','玉泉路','五棵松','苹果园—四惠东');
INSERT INTO bj_subway VALUES (6,'1号线','五棵松','万寿路','苹果园—四惠东');
INSERT INTO bj_subway VALUES (7,'1号线','万寿路','公主坟','苹果园—四惠东');
INSERT INTO bj_subway VALUES (8,'1号线','公主坟','军事博物馆','苹果园—四惠东');
INSERT INTO bj_subway VALUES (9,'1号线','军事博物馆','木樨地','苹果园—四惠东');
INSERT INTO bj_subway VALUES (10,'1号线','木樨地','南礼士路','苹果园—四惠东');
INSERT INTO bj_subway VALUES (11,'1号线','南礼士路','复兴门','苹果园—四惠东');
INSERT INTO bj_subway VALUES (12,'1号线','复兴门','西单','苹果园—四惠东');
INSERT INTO bj_subway VALUES (13,'1号线','西单','天安门西','苹果园—四惠东');
INSERT INTO bj_subway VALUES (14,'1号线','天安门西','天安门东','苹果园—四惠东');
INSERT INTO bj_subway VALUES (15,'1号线','天安门东','王府井','苹果园—四惠东');
INSERT INTO bj_subway VALUES (16,'1号线','王府井','东单','苹果园—四惠东');
INSERT INTO bj_subway VALUES (17,'1号线','东单','建国门','苹果园—四惠东');
INSERT INTO bj_subway VALUES (18,'1号线','建国门','永安里','苹果园—四惠东');
INSERT INTO bj_subway VALUES (19,'1号线','永安里','国贸','苹果园—四惠东');
INSERT INTO bj_subway VALUES (20,'1号线','国贸','大望路','苹果园—四惠东');
INSERT INTO bj_subway VALUES (21,'1号线','大望路','四惠','苹果园—四惠东');
INSERT INTO bj_subway VALUES (22,'1号线','四惠','四惠东','苹果园—四惠东');
INSERT INTO bj_subway VALUES (23,'1号线','四惠东','四惠','四惠东—苹果园');
INSERT INTO bj_subway VALUES (24,'1号线','四惠','大望路','四惠东—苹果园');
INSERT INTO bj_subway VALUES (25,'1号线','大望路','国贸','四惠东—苹果园');
INSERT INTO bj_subway VALUES (26,'1号线','国贸','永安里','四惠东—苹果园');
INSERT INTO bj_subway VALUES (27,'1号线','永安里','建国门','四惠东—苹果园');
INSERT INTO bj_subway VALUES (28,'1号线','建国门','东单','四惠东—苹果园');
INSERT INTO bj_subway VALUES (29,'1号线','东单','王府井','四惠东—苹果园');
INSERT INTO bj_subway VALUES (30,'1号线','王府井','天安门东','四惠东—苹果园');
INSERT INTO bj_subway VALUES (31,'1号线','天安门东','天安门西','四惠东—苹果园');
INSERT INTO bj_subway VALUES (32,'1号线','天安门西','西单','四惠东—苹果园');
INSERT INTO bj_subway VALUES (33,'1号线','西单','复兴门','四惠东—苹果园');
INSERT INTO bj_subway VALUES (34,'1号线','复兴门','南礼士路','四惠东—苹果园');
INSERT INTO bj_subway VALUES (35,'1号线','南礼士路','木樨地','四惠东—苹果园');
INSERT INTO bj_subway VALUES (36,'1号线','木樨地','军事博物馆','四惠东—苹果园');
INSERT INTO bj_subway VALUES (37,'1号线','军事博物馆','公主坟','四惠东—苹果园');
INSERT INTO bj_subway VALUES (38,'1号线','公主坟','万寿路','四惠东—苹果园');
INSERT INTO bj_subway VALUES (39,'1号线','万寿路','五棵松','四惠东—苹果园');
INSERT INTO bj_subway VALUES (40,'1号线','五棵松','玉泉路','四惠东—苹果园');
INSERT INTO bj_subway VALUES (41,'1号线','玉泉路','八宝山','四惠东—苹果园');
INSERT INTO bj_subway VALUES (42,'1号线','八宝山','八角游乐园','四惠东—苹果园');
INSERT INTO bj_subway VALUES (43,'1号线','八角游乐园','古城','四惠东—苹果园');
INSERT INTO bj_subway VALUES (44,'1号线','古城','苹果园','四惠东—苹果园');
INSERT INTO bj_subway VALUES (45,'2号线','西直门','积水潭','外环');
INSERT INTO bj_subway VALUES (46,'2号线','积水潭','鼓楼大街','外环');
INSERT INTO bj_subway VALUES (47,'2号线','鼓楼大街','安定门','外环');
INSERT INTO bj_subway VALUES (48,'2号线','安定门','雍和宫','外环');
INSERT INTO bj_subway VALUES (49,'2号线','雍和宫','东直门','外环');
INSERT INTO bj_subway VALUES (50,'2号线','东直门','东四十条','外环');
INSERT INTO bj_subway VALUES (51,'2号线','东四十条','朝阳门','外环');
INSERT INTO bj_subway VALUES (52,'2号线','朝阳门','建国门','外环');
INSERT INTO bj_subway VALUES (53,'2号线','建国门','北京站','外环');
INSERT INTO bj_subway VALUES (54,'2号线','北京站','崇文门','外环');
INSERT INTO bj_subway VALUES (55,'2号线','崇文门','前门','外环');
INSERT INTO bj_subway VALUES (56,'2号线','前门','和平门','外环');
INSERT INTO bj_subway VALUES (57,'2号线','和平门','宣武门','外环');
INSERT INTO bj_subway VALUES (58,'2号线','宣武门','长椿街','外环');
INSERT INTO bj_subway VALUES (59,'2号线','长椿街','复兴门','外环');
INSERT INTO bj_subway VALUES (60,'2号线','复兴门','阜成门','外环');
INSERT INTO bj_subway VALUES (61,'2号线','阜成门','车公庄','外环');
INSERT INTO bj_subway VALUES (62,'2号线','车公庄','西直门','外环');
INSERT INTO bj_subway VALUES (63,'2号线','车公庄','阜成门','内环');
INSERT INTO bj_subway VALUES (64,'2号线','阜成门','复兴门','内环');
INSERT INTO bj_subway VALUES (65,'2号线','复兴门','长椿街','内环');
INSERT INTO bj_subway VALUES (66,'2号线','长椿街','宣武门','内环');
INSERT INTO bj_subway VALUES (67,'2号线','宣武门','和平门','内环');
INSERT INTO bj_subway VALUES (68,'2号线','和平门','前门','内环');
INSERT INTO bj_subway VALUES (69,'2号线','前门','崇文门','内环');
INSERT INTO bj_subway VALUES (70,'2号线','崇文门','北京站','内环');
INSERT INTO bj_subway VALUES (71,'2号线','北京站','建国门','内环');
INSERT INTO bj_subway VALUES (72,'2号线','建国门','朝阳门','内环');
INSERT INTO bj_subway VALUES (73,'2号线','朝阳门','东四十条','内环');
INSERT INTO bj_subway VALUES (74,'2号线','东四十条','东直门','内环');
INSERT INTO bj_subway VALUES (75,'2号线','东直门','雍和宫','内环');
INSERT INTO bj_subway VALUES (76,'2号线','雍和宫','安定门','内环');
INSERT INTO bj_subway VALUES (77,'2号线','安定门','鼓楼大街','内环');
INSERT INTO bj_subway VALUES (78,'2号线','鼓楼大街','积水潭','内环');
INSERT INTO bj_subway VALUES (79,'2号线','积水潭','西直门','内环');
INSERT INTO bj_subway VALUES (80,'2号线','西直门','车公庄','外环');
INSERT INTO bj_subway VALUES (81, '8号线', '朱辛庄', '育知路', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (82, '8号线', '育知路', '平西府', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (83, '8号线', '平西府', '回龙观东大街', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (84, '8号线', '回龙观东大街', '霍营', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (85, '8号线', '霍营', '育新', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (86, '8号线', '育新', '西小口', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (87, '8号线', '西小口', '永泰庄', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (88, '8号线', '永泰庄', '林萃桥', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (89, '8号线', '林萃桥', '森林公园南门', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (90, '8号线', '森林公园南门', '奥林匹克公园', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (91, '8号线', '奥林匹克公园', '奥体中心', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (92, '8号线', '奥体中心', '北土城', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (93, '8号线', '北土城', '安华桥', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (94, '8号线', '安华桥', '安德里北街', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (95, '8号线', '安德里北街', '鼓楼大街', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (96, '8号线', '鼓楼大街', '什刹海', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (97, '8号线', '什刹海', '南锣鼓巷', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (98, '8号线', '南锣鼓巷', '中国美术馆', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (99, '8号线', '中国美术馆', '金鱼胡同', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (100, '8号线', '金鱼胡同', '王府井', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (101, '8号线', '王府井', '前门', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (102, '8号线', '前门', '珠市口', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (103, '8号线', '珠市口', '天桥', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (104, '8号线', '天桥', '永定门外', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (105, '8号线', '永定门外', '木樨园', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (106, '8号线', '木樨园', '海户屯', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (107, '8号线', '海户屯', '大红门', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (108, '8号线', '大红门', '大红门南', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (109, '8号线', '大红门南', '和义', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (110, '8号线', '和义', '东高地', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (111, '8号线', '东高地', '火箭万源', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (112, '8号线', '火箭万源', '五福堂', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (113, '8号线', '五福堂', '德茂', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (114, '8号线', '德茂', '瀛海', '朱辛庄-瀛海');
INSERT INTO bj_subway VALUES (115, '8号线', '瀛海', '德茂', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (116, '8号线', '德茂', '五福堂', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (117, '8号线', '五福堂', '火箭万源', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (118, '8号线', '火箭万源', '东高地', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (119, '8号线', '东高地', '和义', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (120, '8号线', '和义', '大红门南', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (121, '8号线', '大红门南', '大红门', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (122, '8号线', '大红门', '海户屯', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (123, '8号线', '海户屯', '木樨园', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (124, '8号线', '木樨园', '永定门外', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (125, '8号线', '永定门外', '天桥', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (126, '8号线', '天桥', '珠市口', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (127, '8号线', '珠市口', '前门', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (128, '8号线', '前门', '王府井', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (129, '8号线', '王府井', '金鱼胡同', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (130, '8号线', '金鱼胡同', '中国美术馆', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (131, '8号线', '中国美术馆', '南锣鼓巷', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (132, '8号线', '南锣鼓巷', '什刹海', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (133, '8号线', '什刹海', '鼓楼大街', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (134, '8号线', '鼓楼大街', '安德里北街', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (135, '8号线', '安德里北街', '安华桥', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (136, '8号线', '安华桥', '北土城', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (137, '8号线', '北土城', '奥体中心', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (138, '8号线', '奥体中心', '奥林匹克公园', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (139, '8号线', '奥林匹克公园', '森林公园南门', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (140, '8号线', '森林公园南门', '林萃桥', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (141, '8号线', '林萃桥', '永泰庄', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (142, '8号线', '永泰庄', '西小口', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (143, '8号线', '西小口', '育新', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (144, '8号线', '育新', '霍营', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (145, '8号线', '霍营', '回龙观东大街', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (146, '8号线', '回龙观东大街', '平西府', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (147, '8号线', '平西府', '育知路', '瀛海-朱辛庄');
INSERT INTO bj_subway VALUES (148, '8号线', '育知路', '朱辛庄', '瀛海-朱辛庄');with recursive temp(start_station,stop_station,stops,paths) as (select station_name,next_station,1 stops,cast(concat(line_name,station_name,'->',line_name,next_station) as char(1000)) pathsfrom bj_subway where station_name='王府井'union allselect t.stop_station,s.next_station,stops+1,concat(paths,'->',s.line_name,s.next_station)from temp t join bj_subway s on (t.stop_station=s.station_name and instr(paths,s.next_station)=0)
)
select * from temp where stop_station='积水潭' order by stops limit 3;
SQL案例分析:银行可疑支付交易监控
通过SQL窗口函数实现银行等金融机构可疑支付交易监控,包括短期累积大额转账,相同收付款人频繁转账交易。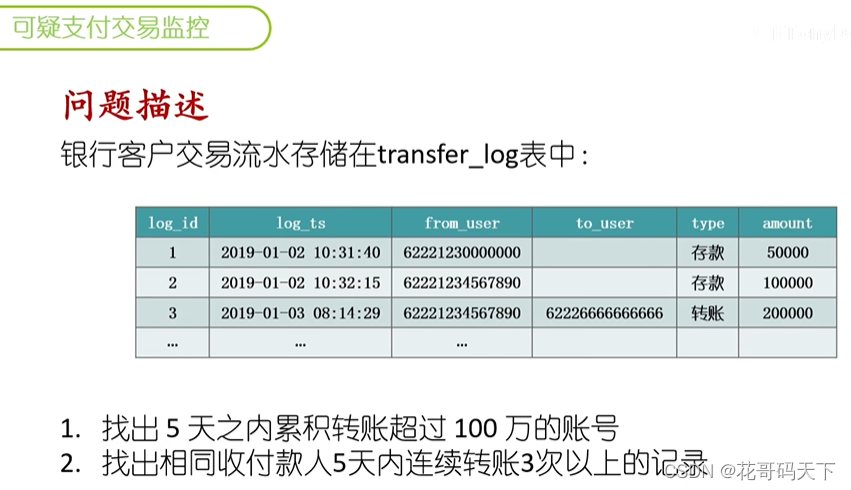
-- 创建交易流水表
CREATE TABLE transfer_log
( log_id INTEGER NOT NULL PRIMARY KEY,log_ts TIMESTAMP NOT NULL,from_user VARCHAR(50) NOT NULL,to_user VARCHAR(50),type VARCHAR(10) NOT NULL,amount NUMERIC(10) NOT NULL
);-- 初始化数据
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (1,'2019-01-02 10:31:40','62221230000000',NULL,'存款',50000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (2,'2019-01-02 10:32:15','62221234567890',NULL,'存款',100000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (3,'2019-01-03 08:14:29','62221234567890','62226666666666','转账',200000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (4,'2019-01-05 13:55:38','62221234567890','62226666666666','转账',150000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (5,'2019-01-07 20:00:31','62221234567890','62227777777777','转账',300000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (6,'2019-01-09 17:28:07','62221234567890','62227777777777','转账',500000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (7,'2019-01-10 07:46:02','62221234567890','62227777777777','转账',100000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (8,'2019-01-11 09:36:53','62221234567890',NULL,'存款',40000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (9,'2019-01-12 07:10:01','62221234567890','62228888888881','转账',10000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (10,'2019-01-12 07:11:12','62221234567890','62228888888882','转账',8000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (11,'2019-01-12 07:12:36','62221234567890','62228888888883','转账',5000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (12,'2019-01-12 07:13:55','62221234567890','62228888888884','转账',6000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (13,'2019-01-12 07:14:24','62221234567890','62228888888885','转账',7000);
INSERT INTO transfer_log (log_id,log_ts,from_user,to_user,type,amount) VALUES (14,'2019-01-21 12:11:16','62221234567890','62228888888885','转账',70000);-- 找出5天之内转账超过100万的账户
select * from (select *,sum(amount) over (partition by from_user order by log_tsrange between interval '5' day preceding and current row ) totalfrom transfer_log where type='转账') temp where total>=1000000;-- 找出相同收付款人5天之内转账超过3次的账户
select *
from (
select *,count(*) over (partition by from_user,to_user order by log_tsrange between interval '5' day preceding and current row ) times
from transfer_log where type='转账')tmep where times>=3;SQL案例分析:微信好友关系
利用SQL递归查询语句(WITH)分析社交网络(微信等)中的好友关系,包括推荐好友。关系链分析等。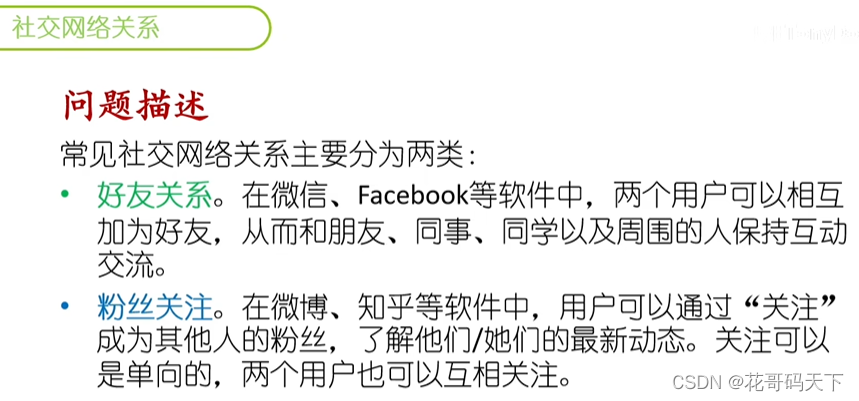
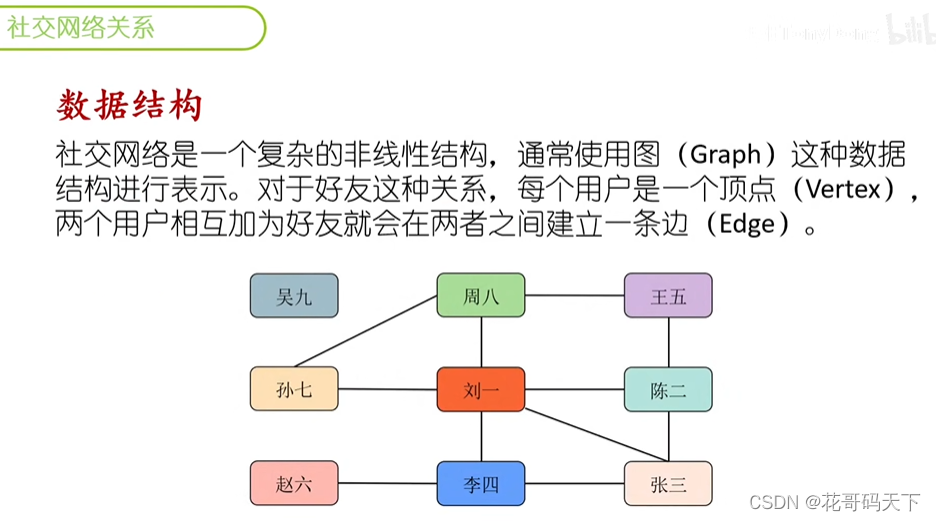
-- 创建示例表
create table t_user(user_id int primary key, user_name varchar(50) not null);insert into t_user values(1, '刘一');
insert into t_user values(2, '陈二');
insert into t_user values(3, '张三');
insert into t_user values(4, '李四');
insert into t_user values(5, '王五');
insert into t_user values(6, '赵六');
insert into t_user values(7, '孙七');
insert into t_user values(8, '周八');
insert into t_user values(9, '吴九');create table t_friend(user_id int not null,friend_id int not null,created_time timestamp not null,primary key (user_id, friend_id)
);insert into t_friend values(1, 2, current_timestamp);
insert into t_friend values(2, 1, current_timestamp);
insert into t_friend values(1, 3, current_timestamp);
insert into t_friend values(3, 1, current_timestamp);
insert into t_friend values(1, 4, current_timestamp);
insert into t_friend values(4, 1, current_timestamp);
insert into t_friend values(1, 7, current_timestamp);
insert into t_friend values(7, 1, current_timestamp);
insert into t_friend values(1, 8, current_timestamp);
insert into t_friend values(8, 1, current_timestamp);
insert into t_friend values(2, 3, current_timestamp);
insert into t_friend values(3, 2, current_timestamp);
insert into t_friend values(2, 5, current_timestamp);
insert into t_friend values(5, 2, current_timestamp);
insert into t_friend values(3, 4, current_timestamp);
insert into t_friend values(4, 3, current_timestamp);
insert into t_friend values(4, 6, current_timestamp);
insert into t_friend values(6, 4, current_timestamp);
insert into t_friend values(5, 8, current_timestamp);
insert into t_friend values(8, 5, current_timestamp);
insert into t_friend values(7, 8, current_timestamp);
insert into t_friend values(8, 7, current_timestamp);-- 查找好友列表
select f.user_id,f.friend_id
from t_friend f
join t_user u on f.user_id = u.user_id
where f.user_id=1;-- 查找用户1和3的共同好友
with f1(user_id,user_name) as (select u.user_id,u.user_namefrom t_friend fjoin t_user u on u.user_id = f.friend_idwhere f.user_id=1
),
f2(user_id,user_name) as (select u.user_id,u.user_namefrom t_friend fjoin t_user u on u.user_id = f.friend_idwhere f.user_id=3)
select f1.*
from f1 join f2 on f1.user_id=f2.user_id;-- 好友推荐,给用户2推荐好友
with f1(user_id,user_name) as ( -- f1:用户2的好友select u.user_id,u.user_namefrom t_friend fjoin t_user u on u.user_id = f.friend_idwhere f.user_id=2
),fof(user_id,user_name) as ( -- fof:好友的好友select u.user_id,u.user_namefrom t_friend fjoin t_user u on u.user_id = f.friend_idjoin f1 on f1.user_id = f.user_idwhere f.friend_id != 2 -- 排除自己and f.friend_id not in (select f1.user_id from f1) -- 排除f1的直接好友)
select user_id,user_name,count(*) from fof -- count:共同好友的数量
group by user_id,user_name order by count(*) desc;-- 用户6的关系网,
with recursive temp(user_id,friend_id,hops,paths) as (select user_id,friend_id,0 hops,concat(',',user_id,',',friend_id) paths from t_friend where user_id = 6union allselect t.user_id,f.friend_id,hops+1,concat(paths,',',f.friend_id) from temp tjoin t_friend f on (t.friend_id = f.user_id and instr(paths, concat(',',f.friend_id,','))=0)where hops <= 6
)
select user_id,friend_id,hops,substr(paths,2) from temp where friend_id=7;-- 用户的平均距离
with recursive temp(user_id,friend_id,hops,paths) as (select user_id,friend_id,0 hops,concat(',',user_id,',',friend_id) paths from t_friendunion allselect t.user_id,f.friend_id,hops+1,concat(paths,',',f.friend_id) from temp tjoin t_friend f on (t.friend_id = f.user_id and instr(paths, concat(',',f.friend_id,','))=0)
),mh as (select user_id,friend_id,min(hops) min_hops from temp group by user_id,friend_id)
select avg(min_hops)
from mh;SQL面试题:索引和性能优化
SQL面试题,主要考察索引的原理和性能优化,使用EXPLIAN查询执行计划。
 索引字段不能使用任何计算,不能使用公式、函数,否则索引会失效
索引字段不能使用任何计算,不能使用公式、函数,否则索引会失效
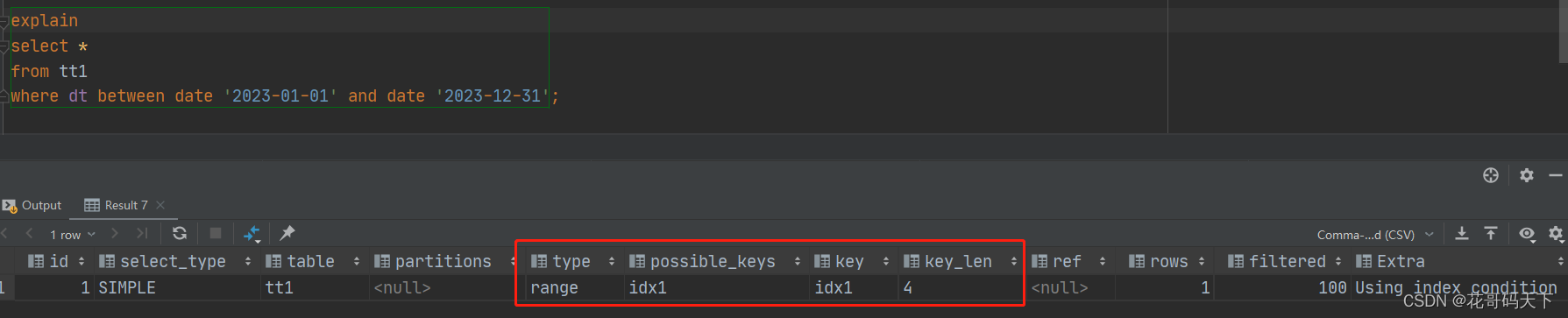

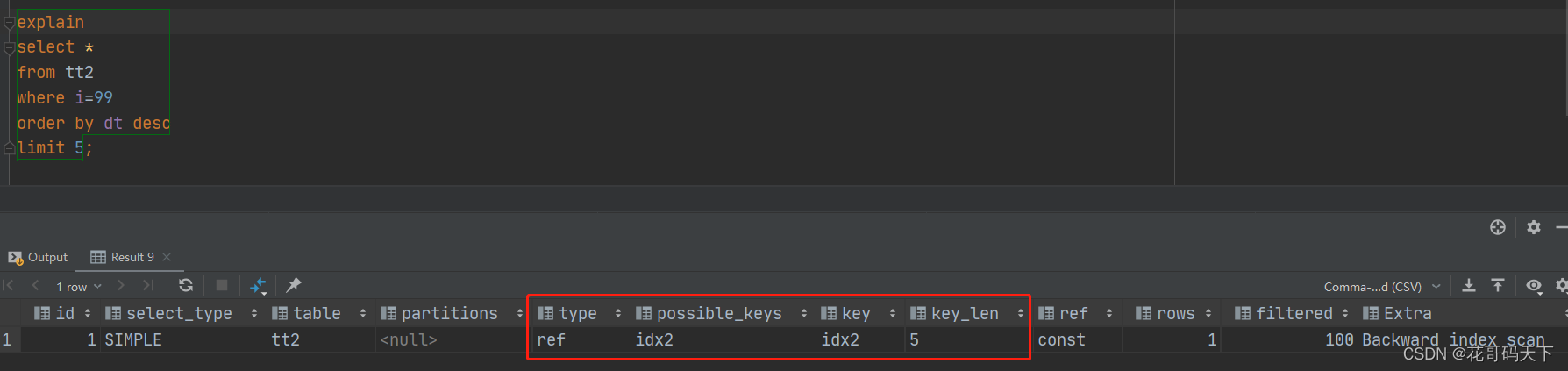
命中索引,无性能问题

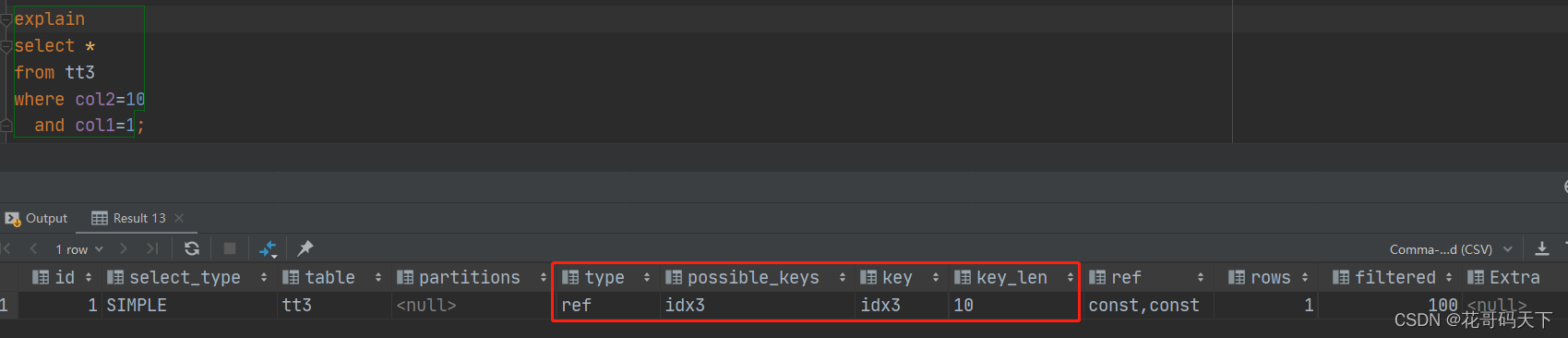

复合索引遵循最左匹配原则,针对本例可以在创建索引时col2放在col1前面,即可都命中索引

未命中索引,like查询的时候%放在后面才能命中索引 
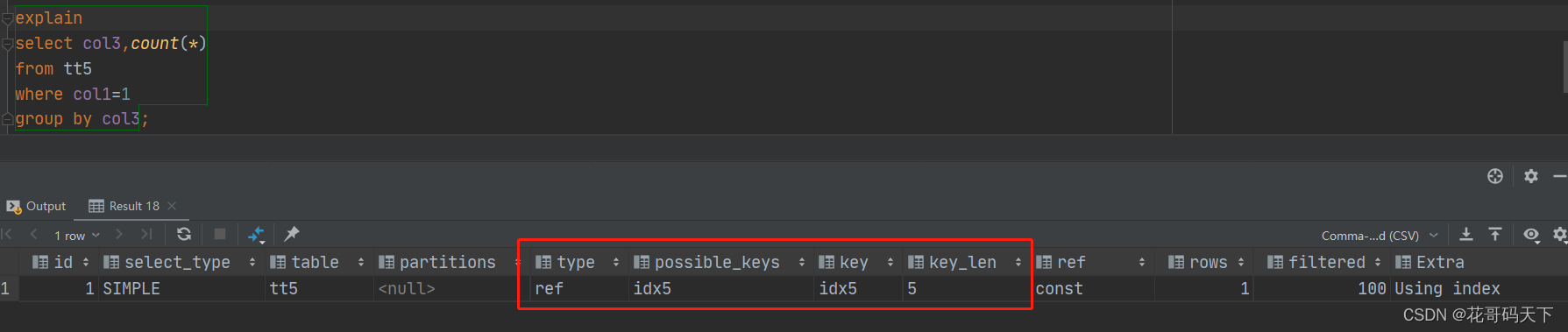
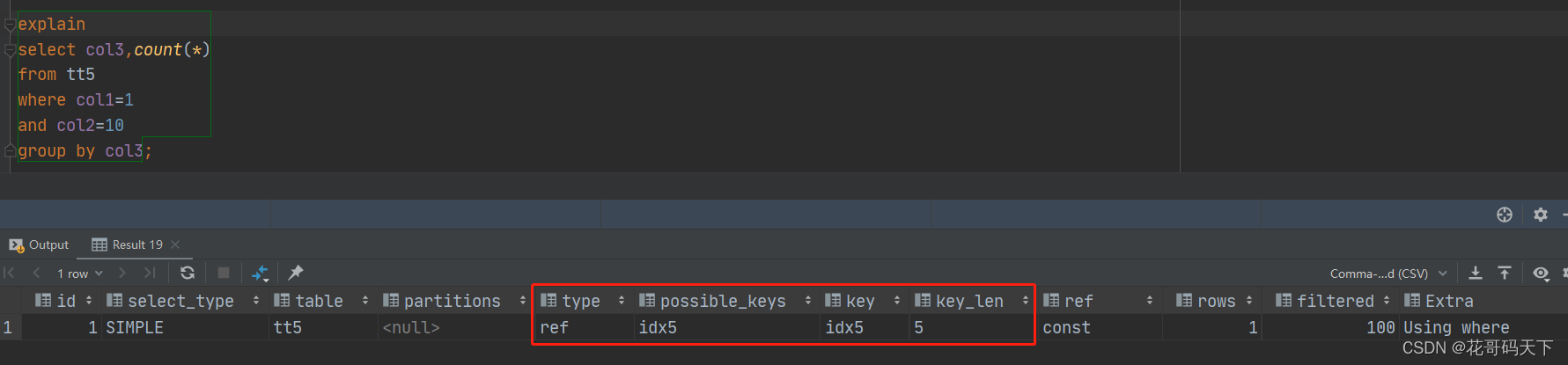
命中索引,且满足索引覆盖,但是using index比using where性能高,using where需要回表
SQL案例分析:京东、亚马逊销量排行榜
介绍如何利用SQL窗口函数RANK和LAG实现电商平台(京东、亚马逊)的销量排行榜以及销量飙升榜。
-- 创建示例表
create table products(product_id integer not null primary key,product_name varchar(100) not null unique,product_subcategory varchar(100) not null,product_category varchar(100) not null
);insert into products values(1, 'iPhone 11', '手机', '手机通讯');
insert into products values(2, 'HUAWEI P40', '手机', '手机通讯');
insert into products values(3, '小米10', '手机', '手机通讯');
insert into products values(4, 'OPPO Reno4', '手机', '手机通讯');
insert into products values(5, 'vivo Y70s', '手机', '手机通讯');
insert into products values(6, '海尔BCD-216STPT', '冰箱', '大家电');
insert into products values(7, '康佳BCD-155C2GBU', '冰箱', '大家电');
insert into products values(8, '容声BCD-529WD11HP', '冰箱', '大家电');
insert into products values(9, '美的BCD-213TM(E)', '冰箱', '大家电');
insert into products values(10, '格力BCD-230WETCL', '冰箱', '大家电');
insert into products values(11, '格力KFR-35GW', '空调', '大家电');
insert into products values(12, '美的KFR-35GW', '空调', '大家电');
insert into products values(13, 'TCLKFRd-26GW', '空调', '大家电');
insert into products values(14, '奥克斯KFR-35GW', '空调', '大家电');
insert into products values(15, '海尔KFR-35GW', '空调', '大家电');create table sales(product_id integer not null,sale_time timestamp not null,quantity integer not null
);-- 生成模拟销量数据
insert into sales
with recursive s(product_id, sale_time, quantity) as (select product_id, '2022-04-01 00:00:00', floor(10*rand(0)) from productsunion allselect product_id, sale_time + interval 1 minute, floor(10*rand(0))from s where sale_time < '2022-04-01 10:00:00'
)
select * from s;# 按照产品的分类,计算2022-04-01 09:00:00到2022-04-01 09:59:59一小时的销量排名
-- MySQL,其他数据库需要替换date_format函数
with hourly_sales(product_id, ymdh, quantity) as (select product_id, date_format(sale_time, '%Y%m%d%H'), sum(quantity)from saleswhere sale_time between '2022-04-01 09:00:00' and '2022-04-01 09:59:59'group by product_id, date_format(sale_time, '%Y%m%d%H')
),
hourly_rank as(select product_category, product_subcategory, product_name, quantity,rank() over (partition by ymdh, product_category order by quantity desc) as rkfrom hourly_sales sjoin products p on (p.product_id = s.product_id)
)
select *
from hourly_rank;# 按照产品子类排名
-- MySQL,其他数据库需要替换date_format函数
with hourly_sales(product_id, ymdh, quantity) as (select product_id, date_format(sale_time, '%Y%m%d%H'), sum(quantity)from saleswhere sale_time between '2022-04-01 09:00:00' and '2022-04-01 09:59:59'group by product_id, date_format(sale_time, '%Y%m%d%H')
),
hourly_rank as(select product_category, product_subcategory, product_name, quantity,rank() over (partition by ymdh, product_category, product_subcategory order by quantity desc) as sub_rkfrom hourly_sales sjoin products p on (p.product_id = s.product_id)
)
select *
from hourly_rank;# 按照产品分类的飙升榜
-- MySQL,其他数据库需要替换date_format函数和ifnull函数
with hourly_sales(product_id, ymdh, quantity) as (select product_id, date_format(sale_time, '%y%m%d%H'), sum(quantity)from saleswhere sale_time between '2022-04-01 08:00:00' and '2022-04-01 09:59:59'group by product_id, date_format(sale_time, '%y%m%d%H')
),
hourly_rank as(select ymdh, product_category, product_subcategory, product_name,rank() over (partition by ymdh, product_category order by quantity desc) as rkfrom hourly_sales sjoin products p on (p.product_id = s.product_id)
),
rank_gain as(select product_category, product_subcategory, product_name,rk, lag(rk, 1) over (partition by product_category, product_name order by ymdh) pre_rk,100 * (ifnull(lag(rk, 1) over (partition by product_category, product_name order by ymdh), 9999) - rk)/rk as gainfrom hourly_rank
),
top_gain as(select *, rank() over (partition by product_category order by gain desc) gain_rkfrom rank_gainwhere pre_rk is not null
)
select product_category, product_subcategory, product_name, pre_rk, rk, concat(gain,'%') gain, gain_rk
from top_gain;SQL案例分析:同比、环比以及复合增长率
使用SQL窗口函数解决财务、销售报表中的同比增长率、环比增长率以及复合增长率问题。

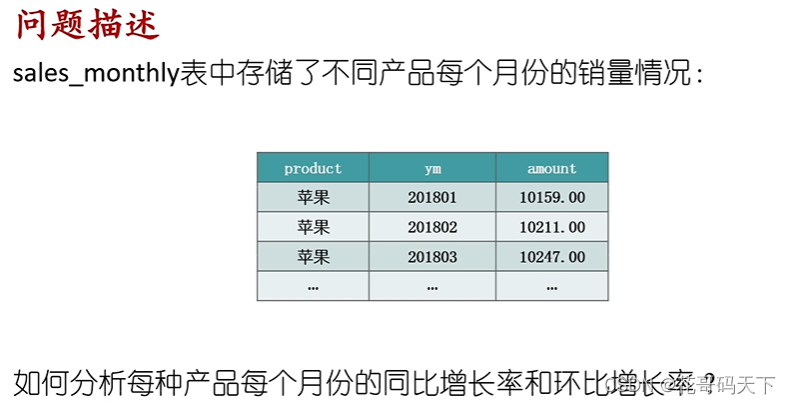

-- 创建销量表sales_monthly
-- product表示产品名称,ym表示年月,amount表示销售金额(元)
CREATE TABLE sales_monthly(product VARCHAR(20), ym VARCHAR(10), amount NUMERIC(10, 2));-- 生成测试数据
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201801',10159.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201802',10211.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201803',10247.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201804',10376.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201805',10400.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201806',10565.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201807',10613.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201808',10696.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201809',10751.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201810',10842.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201811',10900.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201812',10972.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201901',11155.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201902',11202.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201903',11260.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201904',11341.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201905',11459.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('苹果','201906',11560.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201801',10138.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201802',10194.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201803',10328.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201804',10322.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201805',10481.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201806',10502.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201807',10589.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201808',10681.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201809',10798.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201810',10829.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201811',10913.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201812',11056.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201901',11161.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201902',11173.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201903',11288.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201904',11408.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201905',11469.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('香蕉','201906',11528.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201801',10154.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201802',10183.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201803',10245.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201804',10325.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201805',10465.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201806',10505.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201807',10578.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201808',10680.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201809',10788.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201810',10838.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201811',10942.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201812',10988.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201901',11099.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201902',11181.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201903',11302.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201904',11327.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201905',11423.00);
INSERT INTO sales_monthly (product,ym,amount) VALUES ('桔子','201906',11524.00);-- 环比增长率
SELECT product AS "产品", ym "年月", amount "本期销量",LAG(amount, 1) OVER (PARTITION BY product ORDER BY ym) "上期销量",((amount - LAG(amount, 1) OVER (PARTITION BY product ORDER BY ym))/LAG(amount, 1) OVER (PARTITION BY product ORDER BY ym)) * 100AS "环比增长率(%)"
FROM sales_monthly
ORDER BY product, ym;-- 同比增长率
SELECT product AS "产品", ym "年月", amount "本期销量",LAG(amount, 12) OVER (PARTITION BY product ORDER BY ym) "去年同期销量",((amount - LAG(amount, 12) OVER (PARTITION BY product ORDER BY ym))/LAG(amount, 12) OVER (PARTITION BY product ORDER BY ym)) * 100AS "同比增长率(%)"
FROM sales_monthly
ORDER BY product, ym;-- 月均复合增长率
WITH s(product, ym, amount, first_amount, num) AS (SELECT product, ym, amount,FIRST_VALUE(amount) OVER (PARTITION BY product ORDER BY ym),ROW_NUMBER() OVER (PARTITION BY product ORDER BY ym)FROM sales_monthly
)
SELECT product AS "产品", ym "年月", amount "销量",(POWER(1.0*amount/first_amount, 1.0/NULLIF(num-1, 0)) - 1) * 100AS "月均复合增长率(%)"
FROM s
ORDER BY product, ym;
SQL案例分析:保护个人信息,隐藏敏感数据
介绍如何利用 SQL 字符串函数将用户姓名、手机号、身份证号以及银行卡号等的部分内容显示为星号(*),从而实现信息的隐藏,保护信息安全。
-- 创建示例表
CREATE TABLE users( id INTEGER NOT NULL AUTO_INCREMENT PRIMARY KEY, name VARCHAR(50) NOT NULL, phone VARCHAR(20) NOT NULL, id_card VARCHAR(500) NOT NULL);
INSERT INTO users VALUES (1, '张三', '13512345678', '320101200206014057');
INSERT INTO users VALUES (2, '李一飞', '+8613512340000', '320101199901011212');
INSERT INTO users VALUES (3, '诸葛不亮', '+861013512341234', '32010119880202567X');-- MySQL
# 隐藏姓名
SELECT name "隐藏之前",CASE char_length(name)WHEN 2 THEN concat('*', substr(name, 2, 1))WHEN 3 THEN concat(substr(name, 1, char_length(name)-2), '*', substr(name, -1, 1))ELSE concat(substr(name, 1, char_length(name)-2), '**')END "隐藏之后"
FROM users;# 隐藏手机号
SELECT phone "隐藏之前",insert(phone, char_length(phone)-7, 4, '****') "隐藏之后"
FROM users;# 隐藏身份证号
SELECT id_card "隐藏之前",insert(id_card, 7, 8, '*******') "隐藏之后"
FROM users;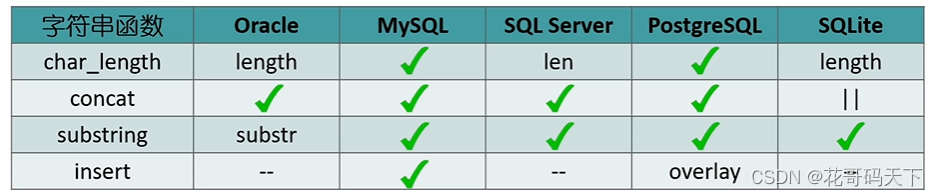
SQL案例分析:字符串的合并与拆分
介绍如何使用SQL聚合函数group_concat/string_agg/listagg将多行字符串合并成一行数据,以及使用递归查询(WITH)将一行字符串拆分成多行数据。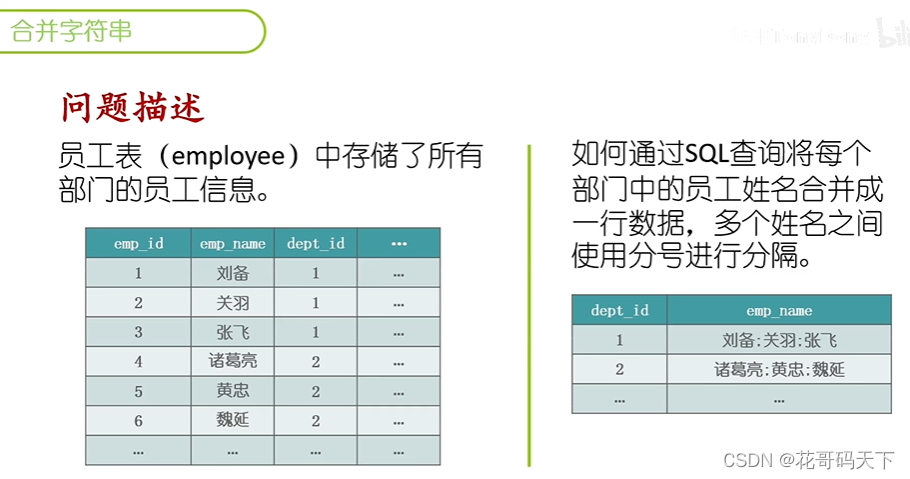
-- 创建 3 个示例表
CREATE TABLE department( dept_id INTEGER NOT NULL PRIMARY KEY, dept_name VARCHAR(50) NOT NULL) ;
CREATE TABLE job( job_id INTEGER NOT NULL PRIMARY KEY, job_title VARCHAR(50) NOT NULL) ;
CREATE TABLE employee( emp_id INTEGER NOT NULL PRIMARY KEY, emp_name VARCHAR(50) NOT NULL, sex VARCHAR(10) NOT NULL, dept_id INTEGER NOT NULL, manager INTEGER, hire_date DATE NOT NULL, job_id INTEGER NOT NULL, salary NUMERIC(8,2) NOT NULL, bonus NUMERIC(8,2), email VARCHAR(100) NOT NULL, CONSTRAINT ck_emp_sex CHECK (sex IN ('男', '女')), CONSTRAINT ck_emp_salary CHECK (salary > 0), CONSTRAINT uk_emp_email UNIQUE (email), CONSTRAINT fk_emp_dept FOREIGN KEY (dept_id) REFERENCES department(dept_id), CONSTRAINT fk_emp_job FOREIGN KEY (job_id) REFERENCES job(job_id), CONSTRAINT fk_emp_manager FOREIGN KEY (manager) REFERENCES employee(emp_id)) ;
CREATE INDEX idx_emp_name ON employee(emp_name);
CREATE INDEX idx_emp_dept ON employee(dept_id);
CREATE INDEX idx_emp_job ON employee(job_id);
CREATE INDEX idx_emp_manager ON employee(manager);-- 生成 MySQL 初始化数据
INSERT INTO department(dept_id, dept_name) VALUES (1, '行政管理部');
INSERT INTO department(dept_id, dept_name) VALUES (2, '人力资源部');
INSERT INTO department(dept_id, dept_name) VALUES (3, '财务部');
INSERT INTO department(dept_id, dept_name) VALUES (4, '研发部');
INSERT INTO department(dept_id, dept_name) VALUES (5, '销售部');
INSERT INTO department(dept_id, dept_name) VALUES (6, '保卫部');INSERT INTO job(job_id, job_title) VALUES (1, '总经理');
INSERT INTO job(job_id, job_title) VALUES (2, '副总经理');
INSERT INTO job(job_id, job_title) VALUES (3, '人力资源总监');
INSERT INTO job(job_id, job_title) VALUES (4, '人力资源专员');
INSERT INTO job(job_id, job_title) VALUES (5, '财务经理');
INSERT INTO job(job_id, job_title) VALUES (6, '会计');
INSERT INTO job(job_id, job_title) VALUES (7, '开发经理');
INSERT INTO job(job_id, job_title) VALUES (8, '程序员');
INSERT INTO job(job_id, job_title) VALUES (9, '销售经理');
INSERT INTO job(job_id, job_title) VALUES (10, '销售人员');INSERT INTO employee VALUES (1, '刘备', '男', 1, NULL, DATE('2000-01-01'), 1, 30000, 10000, 'liubei@shuguo.com');
INSERT INTO employee VALUES (2, '关羽', '男', 1, 1, DATE('2000-01-01'), 2, 26000, 10000, 'guanyu@shuguo.com');
INSERT INTO employee VALUES (3, '张飞', '男', 1, 1, DATE('2000-01-01'), 2, 24000, 10000, 'zhangfei@shuguo.com');
INSERT INTO employee VALUES (4, '诸葛亮', '男', 2, 1, DATE('2006-03-15'), 3, 24000, 8000, 'zhugeliang@shuguo.com');
INSERT INTO employee VALUES (5, '黄忠', '男', 2, 4, DATE('2008-10-25'), 4, 8000, NULL, 'huangzhong@shuguo.com');
INSERT INTO employee VALUES (6, '魏延', '男', 2, 4, DATE('2007-04-01'), 4, 7500, NULL, 'weiyan@shuguo.com');
INSERT INTO employee VALUES (7, '孙尚香', '女', 3, 1, DATE('2002-08-08'), 5, 12000, 5000, 'sunshangxiang@shuguo.com');
INSERT INTO employee VALUES (8, '孙丫鬟', '女', 3, 7, DATE('2002-08-08'), 6, 6000, NULL, 'sunyahuan@shuguo.com');
INSERT INTO employee VALUES (9, '赵云', '男', 4, 1, DATE('2005-12-19'), 7, 15000, 6000, 'zhaoyun@shuguo.com');
INSERT INTO employee VALUES (10, '廖化', '男', 4, 9, DATE('2009-02-17'), 8, 6500, NULL, 'liaohua@shuguo.com');
INSERT INTO employee VALUES (11, '关平', '男', 4, 9, DATE('2011-07-24'), 8, 6800, NULL, 'guanping@shuguo.com');
INSERT INTO employee VALUES (12, '赵氏', '女', 4, 9, DATE('2011-11-10'), 8, 6600, NULL, 'zhaoshi@shuguo.com');
INSERT INTO employee VALUES (13, '关兴', '男', 4, 9, DATE('2011-07-30'), 8, 7000, NULL, 'guanxing@shuguo.com');
INSERT INTO employee VALUES (14, '张苞', '男', 4, 9, DATE('2012-05-31'), 8, 6500, NULL, 'zhangbao@shuguo.com');
INSERT INTO employee VALUES (15, '赵统', '男', 4, 9, DATE('2012-05-03'), 8, 6000, NULL, 'zhaotong@shuguo.com');
INSERT INTO employee VALUES (16, '周仓', '男', 4, 9, DATE('2010-02-20'), 8, 8000, NULL, 'zhoucang@shuguo.com');
INSERT INTO employee VALUES (17, '马岱', '男', 4, 9, DATE('2014-09-16'), 8, 5800, NULL, 'madai@shuguo.com');
INSERT INTO employee VALUES (18, '法正', '男', 5, 2, DATE('2017-04-09'), 9, 10000, 5000, 'fazheng@shuguo.com');
INSERT INTO employee VALUES (19, '庞统', '男', 5, 18, DATE('2017-06-06'), 10, 4100, 2000, 'pangtong@shuguo.com');
INSERT INTO employee VALUES (20, '蒋琬', '男', 5, 18, DATE('2018-01-28'), 10, 4000, 1500, 'jiangwan@shuguo.com');
INSERT INTO employee VALUES (21, '黄权', '男', 5, 18, DATE('2018-03-14'), 10, 4200, NULL, 'huangquan@shuguo.com');
INSERT INTO employee VALUES (22, '糜竺', '男', 5, 18, DATE('2018-03-27'), 10, 4300, NULL, 'mizhu@shuguo.com');
INSERT INTO employee VALUES (23, '邓芝', '男', 5, 18, DATE('2018-11-11'), 10, 4000, NULL, 'dengzhi@shuguo.com');
INSERT INTO employee VALUES (24, '简雍', '男', 5, 18, DATE('2019-05-11'), 10, 4800, NULL, 'jianyong@shuguo.com');
INSERT INTO employee VALUES (25, '孙乾', '男', 5, 18, DATE('2018-10-09'), 10, 4700, NULL, 'sunqian@shuguo.com');# 将每个部门中的多个员工姓名合并成一行数据,多个姓名之间使用分号进行分隔
SELECT d.dept_name, GROUP_CONCAT(e.emp_name)
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id)
GROUP BY dept_name;SELECT d.dept_name, GROUP_CONCAT(e.emp_name SEPARATOR ';')
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id)
GROUP BY dept_name;# 对于每个部门中的员工,按照入职日期进行排序,入职日期相同按照工号进行排序
SELECT d.dept_name, GROUP_CONCAT(e.emp_name ORDER BY e.hire_date, e.emp_id SEPARATOR ';')
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id)
GROUP BY dept_name;# 使用DISTINCT排除每个分组中的重复数据
SELECT d.dept_name, GROUP_CONCAT(DISTINCT sex)
FROM employee e
JOIN department d ON (e.dept_id = d.dept_id)
GROUP BY dept_name;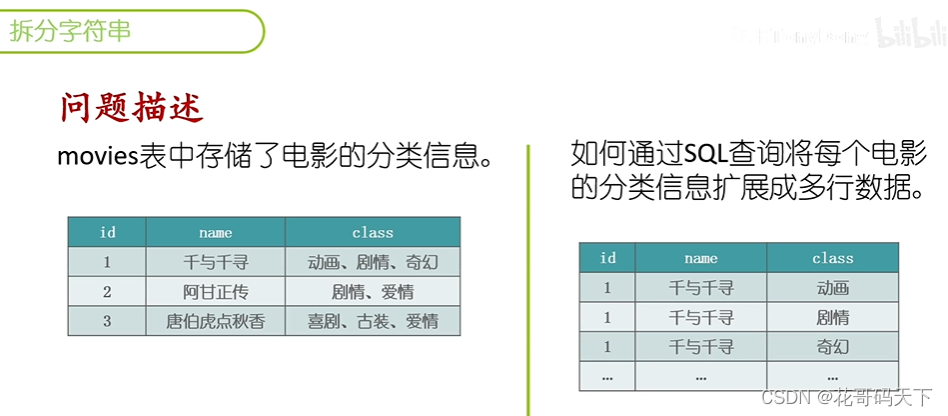
# 创建示例表合数据
CREATE TABLE movies(id int primary key, name varchar(50), class varchar(200));
INSERT INTO movies VALUES (1, '千与千寻', '动画、剧情、奇幻');
INSERT INTO movies VALUES (2, '阿甘正传', '剧情、爱情');
INSERT INTO movies VALUES (3, '唐伯虎点秋香', '喜剧、古装、爱情’);# 拆分字符串
WITH RECURSIVE t(id, name, sub, str) AS (SELECT id, name, substr(concat(class,'、'), 1, instr(concat(class,'、'), '、')-1), substr(concat(class,'、'), instr(concat(class,'、'), '、')+1) FROM moviesUNION ALLSELECT id, name,substr(str, 1, instr(str, '、')-1), substr(str, instr(str, '、')+1)FROM t WHERE instr(str, '、')>0
)
SELECT id, name, sub, str
FROM t
ORDER BY id;
SQL案例分析:分页查询,你写对了吗?
分页查询是指为了改善前端用户的体验和系统性能,将查询结果分批返回和展示。分页查询常用的两种方式:OFFSET分页,利用SQL标准OFFSET FETCH或者LIMIT OFFSET子句指定偏移量和返回的行数,性能随着偏移量的增加明显下降。Keyset分页,利用每次返回的记录集查找下一次的数据,性能不受数据量和偏移量的影响。可以实现页面无限滚动效果。
-- 创建示例表
CREATE TABLE users(id integer PRIMARY KEY,name varchar(50) NOT NULL,pswd varchar(50) NOT NULL,email varchar(50),create_time timestamp NOT NULL,notes varchar(200)
);-- 生成示例数据
-- MySQL语法
INSERT INTO users(id, name, pswd, email,create_time)
WITH RECURSIVE t(id, name, pswd, email,create_time) AS (
SELECT 1, CAST(concat('user', 1) AS char(50)), 'e10adc3949ba59abbe56e057f20f883e', CAST(concat('user',1,'@test.com') AS char(50)), '2020-01-01 00:00:00'
UNION ALL
SELECT id+1, concat('user', id+1), pswd, concat('user',id+1,'@test.com'), create_time+ INTERVAL mod(id,2) MINUTE
FROM t WHERE id<1000000
)
SELECT /*+ SET_VAR(cte_max_recursion_depth = 1M) */* FROM t;-- 创建索引
CREATE INDEX idx_user_ct ON users(create_time);-- OFFSET分页
SELECT count(*) FROM users;EXPLAIN
SELECT *
FROM users
ORDER BY create_time, id
LIMIT 20 offset 100000;-- KEYSET分页
EXPLAIN
SELECT *
FROM users
WHERE create_time>='2020-11-01 00:10:00' and id>20
ORDER BY create_time, id
LIMIT 20;SQL面试题:基于扫码记录查找密接人员
如何使用SQL语句基于扫码信息获取用户活动轨迹,基于轨迹交集获取时空伴随者(密接人员)。
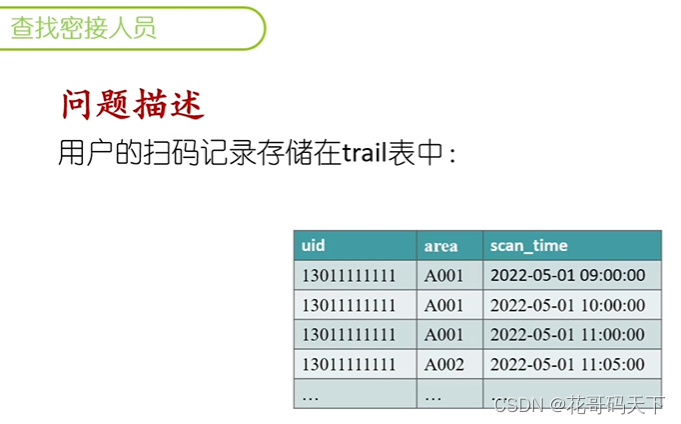
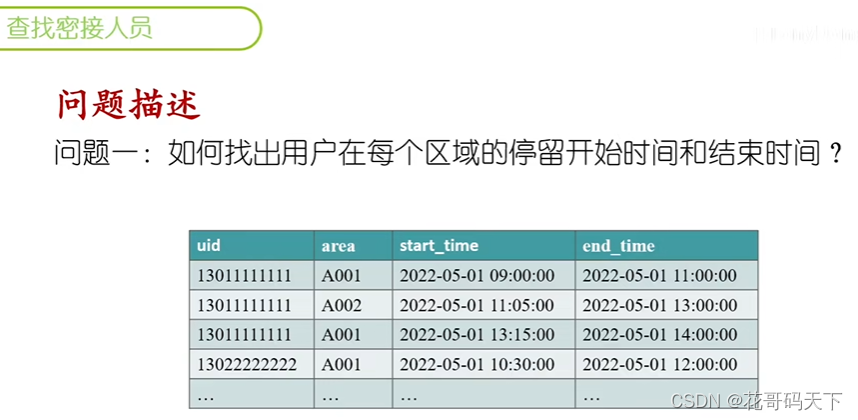
-- 创建示例表和数据
CREATE TABLE trail(uid varchar(11) NOT NULL,area varchar(10) NOT NULL,scan_time timestamp);INSERT INTO trail VALUES ('13011111111', 'A001', '2022-05-01 09:00:00');
INSERT INTO trail VALUES ('13011111111', 'A001', '2022-05-01 10:00:00');
INSERT INTO trail VALUES ('13011111111', 'A001', '2022-05-01 11:00:00');
INSERT INTO trail VALUES ('13011111111', 'A002', '2022-05-01 11:05:00');
INSERT INTO trail VALUES ('13011111111', 'A002', '2022-05-01 13:00:00');
INSERT INTO trail VALUES ('13011111111', 'A001', '2022-05-01 13:15:00');
INSERT INTO trail VALUES ('13011111111', 'A001', '2022-05-01 14:00:00');
INSERT INTO trail VALUES ('13022222222', 'A001', '2022-05-01 10:30:00');
INSERT INTO trail VALUES ('13022222222', 'A001', '2022-05-01 12:00:00');
INSERT INTO trail VALUES ('13033333333', 'A001', '2022-05-01 11:00:00');
INSERT INTO trail VALUES ('13033333333', 'A001', '2022-05-01 12:00:00');
INSERT INTO trail VALUES ('13033333333', 'A001', '2022-05-01 13:00:00');-- 问题一:如何找出用户在每个区域的停留开始时间和结束时间?
WITH tmp AS (
SELECT uid, area, scan_time,
-- num1 - num2 相同,表示在同一个小区
ROW_NUMBER() over(PARTITION BY uid ORDER BY scan_time) num1,
ROW_NUMBER() over(PARTITION BY uid,area ORDER BY scan_time) num2,
rank() OVER (PARTITION BY uid ORDER BY scan_time) - rank() OVER (PARTITION BY uid, area ORDER BY scan_time) diff
FROM trail)
SELECT uid, area, min(scan_time) start_time, max(scan_time) end_time
FROM tmp
GROUP BY uid, area, diff
ORDER BY uid, start_time;
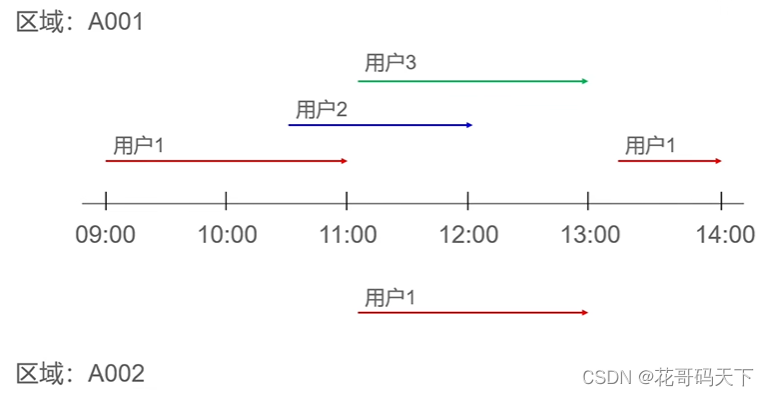
-- 问题二:假如某个用户核酸检查为阳性,找出他的伴随人员?
WITH tmp AS (
SELECT uid, area, scan_time,rank() OVER (PARTITION BY uid ORDER BY scan_time) - rank() OVER (PARTITION BY uid, area ORDER BY scan_time) diff
FROM trail),
tmp2 AS (
SELECT uid, area, min(scan_time) start_time, max(scan_time) end_time
FROM tmp
GROUP BY uid, area, diff
HAVING min(scan_time) + INTERVAL 30 MINUTE <= max(scan_time)
)
SELECT *
FROM tmp2 u1
JOIN tmp2 u2
ON (u1.uid <> u2.uid AND u1.area = u2.areaAND u1.start_time + INTERVAL 10 MINUTE <= u2.end_timeAND u2.start_time + INTERVAL 10 MINUTE <= u1.end_time)
WHERE u1.uid = '13011111111';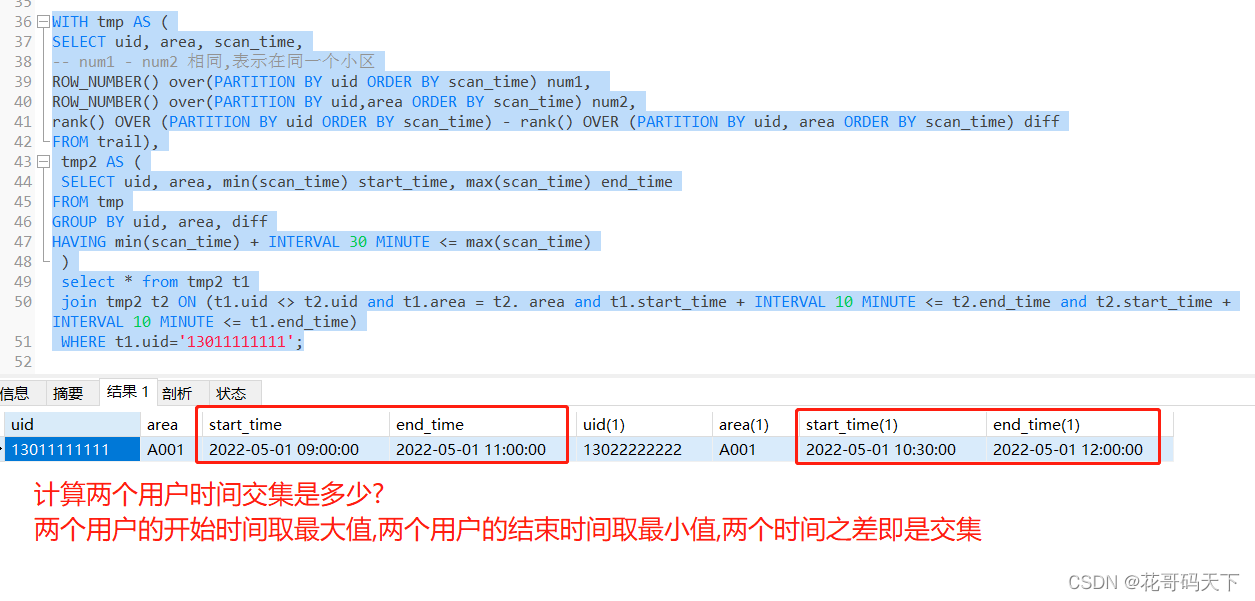
SQL面试题:连续登录问题
互联网大厂经典SQL面试题,连续登录、连续购买等。
-- 创建示例表
CREATE TABLE t_login(uid int, login_time timestamp);
INSERT INTO t_login VALUES (1, '2022-01-01 08:05:11');
INSERT INTO t_login VALUES (2, '2022-01-01 10:00:00');
INSERT INTO t_login VALUES (3, '2022-01-01 12:13:14');
INSERT INTO t_login VALUES (1, '2022-01-01 19:30:00');
INSERT INTO t_login VALUES (1, '2022-01-02 07:59:30');
INSERT INTO t_login VALUES (2, '2022-01-02 14:00:00');
INSERT INTO t_login VALUES (2, '2022-01-03 11:15:00');
INSERT INTO t_login VALUES (3, '2022-01-03 16:00:00');
INSERT INTO t_login VALUES (1, '2022-01-04 07:20:00');
INSERT INTO t_login VALUES (2, '2022-01-04 07:45:00');
INSERT INTO t_login VALUES (3, '2022-01-04 10:30:30');
INSERT INTO t_login VALUES (1, '2022-01-05 13:00:00');
INSERT INTO t_login VALUES (1, '2022-01-06 17:18:19');
INSERT INTO t_login VALUES (1, '2022-01-07 20:00:00');
INSERT INTO t_login VALUES (2, '2022-01-07 21:00:00');-- 如何通过SQL查询找出2022年1月连续登录3天以上的用户?
-- 自连接查询
SELECT t1.uid,t1.ymd,t2.ymd,t3.ymd FROM
(SELECT DISTINCT uid,date(login_time) ymd FROM t_login WHERE login_time BETWEEN timestamp '2022-01-01 00:00:00' and timestamp '2022-01-31 23:59:59') t1
JOIN (SELECT DISTINCT uid,date(login_time) ymd FROM t_login WHERE login_time BETWEEN timestamp '2022-01-01 00:00:00' and timestamp '2022-01-31 23:59:59') t2 on (t1.uid=t2.uid and DATEDIFF(t2.ymd,t1.ymd)=1)
JOIN (SELECT DISTINCT uid, date(login_time) ymd FROM t_login WHERE login_time BETWEEN timestamp '2022-01-01 00:00:00' AND '2022-01-31 23:59:59') t3 ON (t2.uid = t3.uid AND datediff(t3.ymd, t2.ymd)=1);-- 窗口函数ROW_NUMBER
with t1 AS (
SELECT DISTINCT uid,date(login_time) ymd FROM t_login WHERE login_time BETWEEN timestamp '2022-01-01 00:00:00' and timestamp '2022-01-31 23:59:59'),t2 AS (SELECT uid, ymd, ROW_NUMBER() OVER (PARTITION BY uid ORDER BY ymd) num,DATE_SUB(ymd,INTERVAL ROW_NUMBER() OVER (PARTITION BY uid ORDER BY ymd) DAY) diffFROM t1)
SELECT uid,count(*),min(ymd),max(ymd),group_concat(ymd) FROM t2 GROUP BY uid,diff HAVING count(*)>=3;-- 窗口函数LAG
WITH t1 AS (SELECT DISTINCT uid, date(login_time) ymd
FROM t_login
WHERE login_time BETWEEN timestamp '2022-01-01 00:00:00' AND '2022-01-31 23:59:59'),
t2 AS (
SELECT uid, ymd,datediff(ymd, lag(ymd, 2) OVER (PARTITION BY uid ORDER BY ymd)) diff
FROM t1)
SELECT uid,date_sub(ymd,INTERVAL 2 day) min_date, ymd max_date, diff
FROM t2
WHERE diff = 2;SQL案例分析:一条查询语句的执行过程
从客户端建立连接开始,到解析器进行语法、语义分析和权限检查,然后优化器生成执行计划,执行器调用存储引擎获取物理文件中的数据,最后返回客户端。同时数据库为了提高性能,还提供了查询计划缓存和热点数据缓存。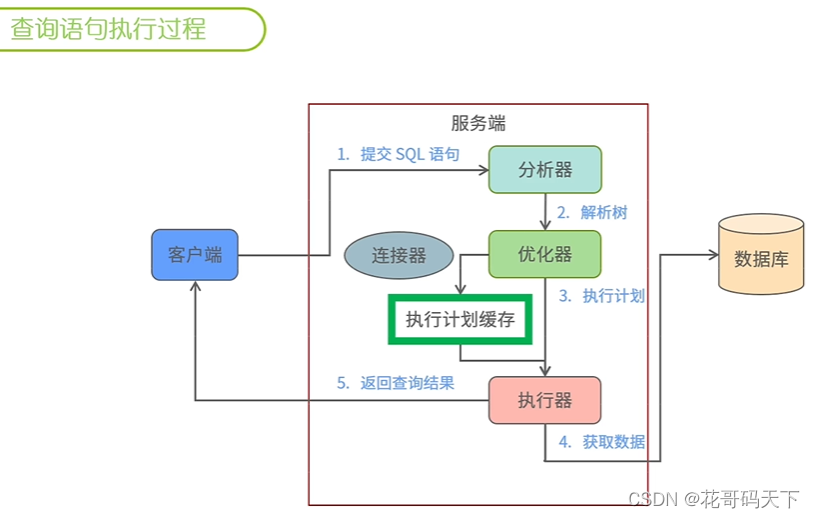
SQL面试题:用户留存率分析
某一天新增用户在之后的第N天仍然登录的比例,称为第N日留存率。使用SQL分析留存率一般有两种方法:多表连接和窗口函数。
-- 示例表
DROP TABLE t_user;
CREATE TABLE t_user(id INT AUTO_INCREMENT PRIMARY KEY,user_name VARCHAR(50) NOT NULL,register_time DATETIME NOT NULL
);SET SESSION cte_max_recursion_depth=9999999;INSERT INTO t_user(user_name, register_time)
WITH RECURSIVE t AS (SELECT 1 n, '2022-01-01 00:00:00' dUNION ALLSELECT n+1, d + INTERVAL '1' MINUTE FROM tWHERE n<10000
)
SELECT concat('user', n), d FROM t;SELECT date(register_time), count(*) FROM t_user GROUP BY date(register_time);DROP TABLE t_user_login;
CREATE TABLE t_user_login(id INT AUTO_INCREMENT PRIMARY KEY,uid INT NOT NULL,login_time DATETIME NOT NULL
);SET SESSION cte_max_recursion_depth=9999999;INSERT INTO t_user_login(uid, login_time)
WITH RECURSIVE t AS (SELECT 1 n, rand()*10000 id, '2022-01-01 00:00:00' dUNION ALLSELECT n+1, rand()*10000, d + INTERVAL CEIL(n/3000) secondFROM tWHERE n<500000
)
SELECT CEIL(id), d FROM t;-- 多表连接
SELECT date(u.register_time),100*count(DISTINCT ul1.uid)/count(DISTINCT u.id) rr1,100*count(DISTINCT ul2.uid)/count(DISTINCT u.id) rr3,100*count(DISTINCT ul3.uid)/count(DISTINCT u.id) rr7,100*count(DISTINCT ul4.uid)/count(DISTINCT u.id) rr30
FROM t_user u
LEFT JOIN t_user_login ul1 ON (ul1.uid = u.id AND date(ul1.login_time) = date(u.register_time) + INTERVAL '1' DAY)
LEFT JOIN t_user_login ul2 ON (ul2.uid = u.id AND date(ul2.login_time) = date(u.register_time) + INTERVAL '3' DAY)
LEFT JOIN t_user_login ul3 ON (ul3.uid = u.id AND date(ul3.login_time) = date(u.register_time) + INTERVAL '7' DAY)
LEFT JOIN t_user_login ul4 ON (ul4.uid = u.id AND date(ul4.login_time) = date(u.register_time) + INTERVAL '30' DAY)
GROUP BY date(u.register_time);-- 窗口函数
WITH t1 AS (
SELECT u.id, u.user_name, date(u.register_time) reg_date, date(l.login_time) login_date,DENSE_RANK() OVER (PARTITION BY date(u.register_time) ORDER BY u.id) daily_reg,DENSE_RANK() OVER (PARTITION BY date(u.register_time), date(l.login_time) ORDER BY l.uid) daily_login
FROM t_user u
LEFT JOIN t_user_login l
ON (l.uid = u.id AND date(l.login_time) BETWEEN date(u.register_time) + INTERVAL '1' DAY AND date(u.register_time) + INTERVAL '30' DAY)
),
t2 AS (
SELECT reg_date, max(daily_reg) daily_reg, login_date, max(daily_login) daily_login
FROM t1
GROUP BY reg_date, login_date)
SELECT reg_date, max(daily_reg),100*max(CASE WHEN login_date = reg_date + INTERVAL '1' DAY THEN daily_login END)/max(daily_reg) rr1,100*max(CASE WHEN login_date = reg_date + INTERVAL '3' DAY THEN daily_login END)/max(daily_reg) rr3,100*max(CASE WHEN login_date = reg_date + INTERVAL '7' DAY THEN daily_login END)/max(daily_reg) rr7,100*max(CASE WHEN login_date = reg_date + INTERVAL '30' DAY THEN daily_login END)/max(daily_reg) rr30
FROM t2
GROUP BY reg_date;
SQL案例分析:年会抽奖程序
分享一个使用SQL实现抽奖的程序,涉及MySQL随机数函数以及存储过程。
CREATE TABLE luck_emp(emp_id int, emp_name varchar(50), prize varchar(10));delimiter $$
CREATE PROCEDURE luck_draw(IN p_prize varchar(10), IN p_num int)
BEGIN
INSERT INTO luck_emp (emp_id, emp_name, prize)
SELECT emp_id, emp_name, p_prize
FROM employee e
WHERE emp_id NOT IN (SELECT emp_id FROM luck_emp)
ORDER BY RAND()
LIMIT p_num;SELECT * FROM luck_emp;
END$$
delimiter ;CALL luck_draw('三等奖', 3);
CALL luck_draw('二等奖', 2);
CALL luck_draw('一等奖', 1);本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!