聊聊如何写一个网站
1.聊聊如何写一个网站
1.1 有一套自己熟悉的后台模板 x-admin
1.2 至少通过前端框架,自己可以组合出来一个前端页面
- Layui
- bootstap
- semantic-ui
- bootstap可视化布局系统(可以自行拼接组件)
- element-ui

2. JDBC
源码分析
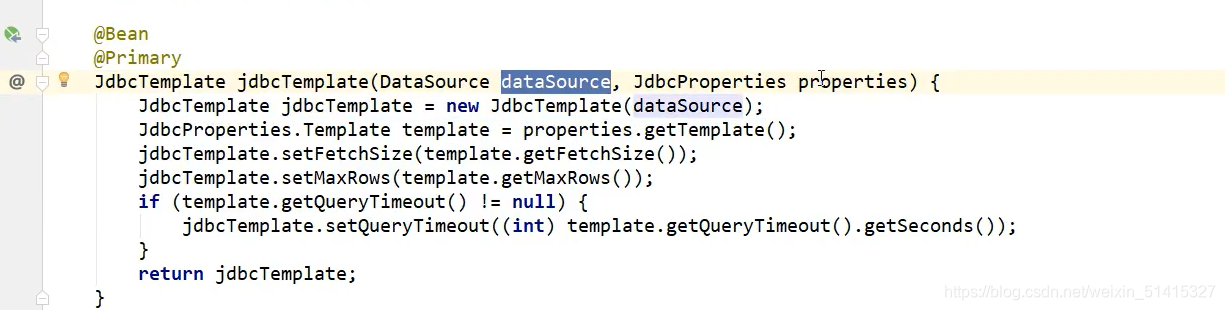
2.1 解决datasource
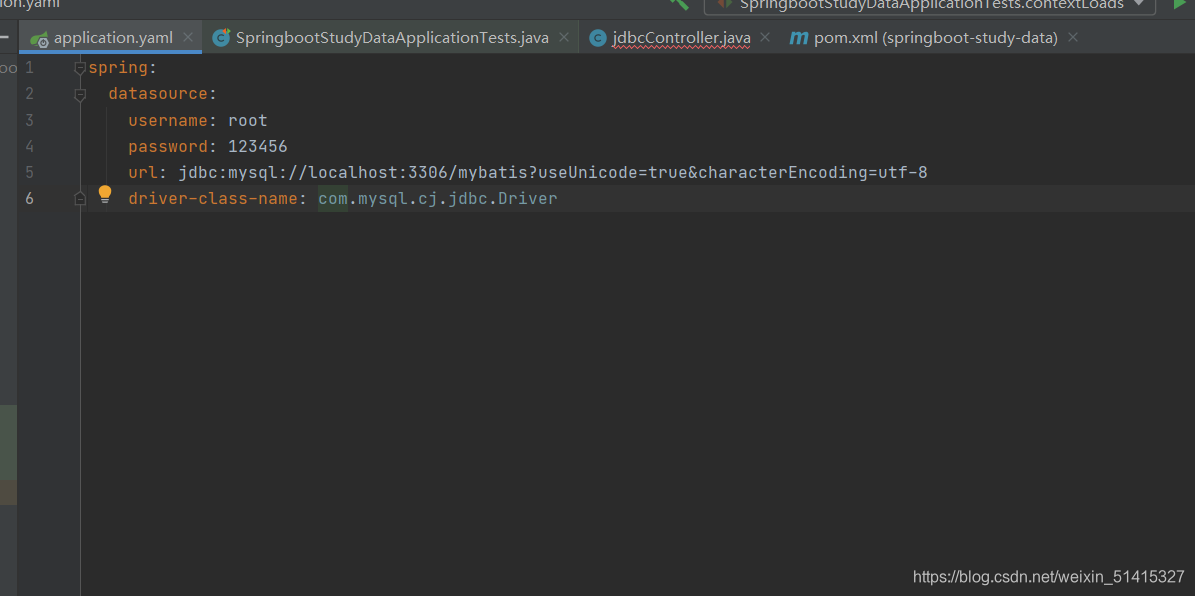
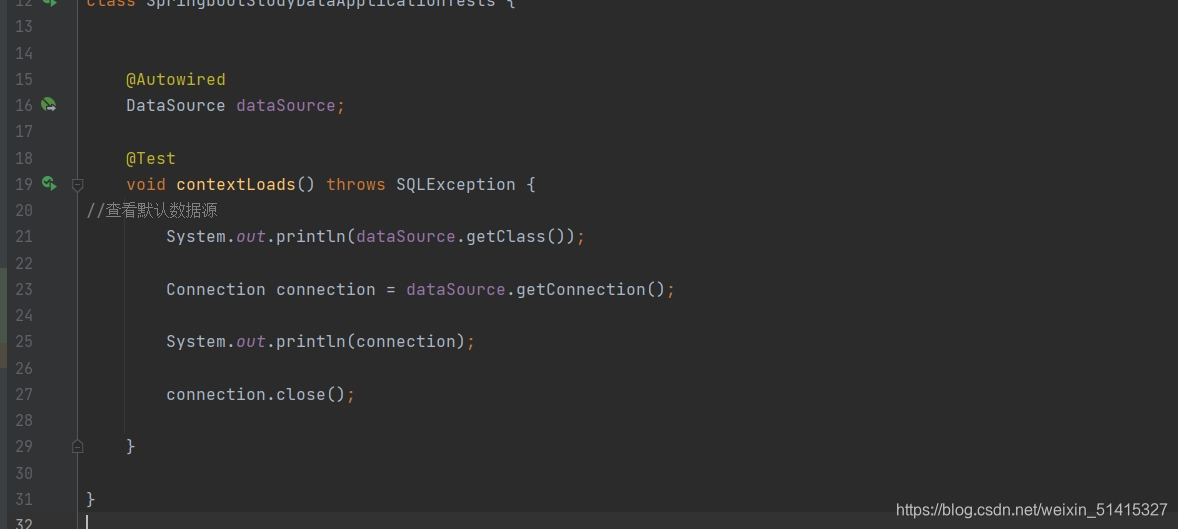
2.2 jdbcTemplate的使用
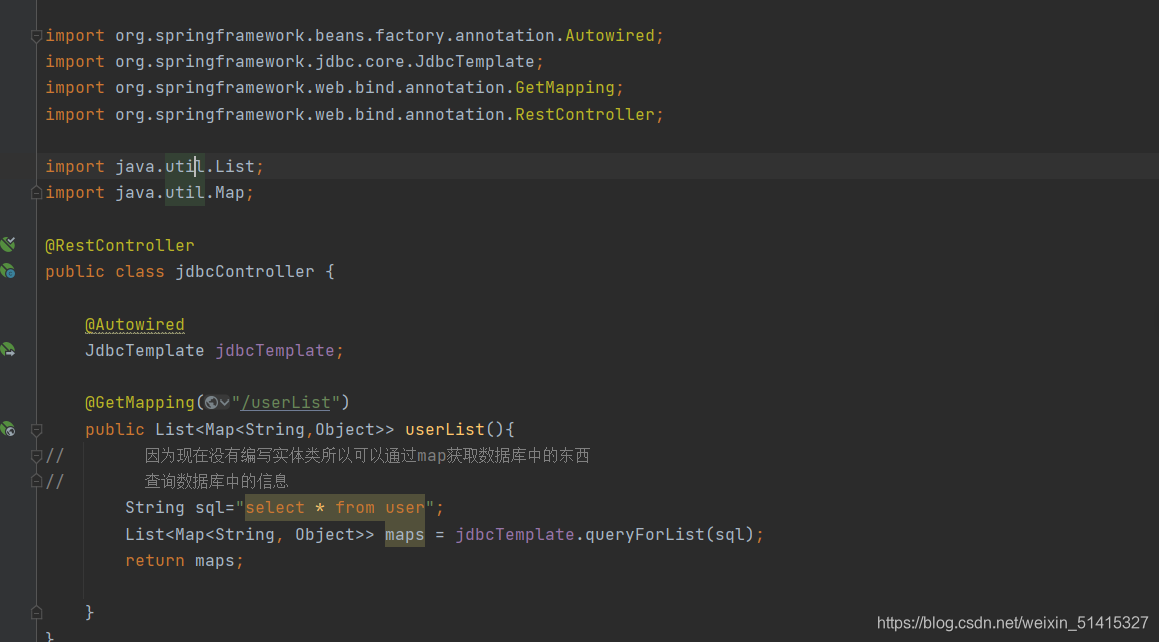
增删改查操作
package com.whx.springbootstudydata.controller;import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.JdbcTemplate;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.PathVariable;
import org.springframework.web.bind.annotation.RestController;import java.util.List;
import java.util.Map;
import java.util.Objects;//@restController相当于@responsebody+@controller返回字符串
@RestController
public class jdbcController {@AutowiredJdbcTemplate jdbcTemplate;@GetMapping("/userList")public List> userList(){
// 因为现在没有编写实体类所以可以通过map获取数据库中的东西
// 查询数据库中的信息String sql="select * from user";List> maps = jdbcTemplate.queryForList(sql);return maps;}@GetMapping("/addUser")public String addUser(){String sql = "insert into mybatis.user (id,name,pwd) values(8,'张久','55555555')";jdbcTemplate.update(sql);return "插入成功";}@GetMapping("/delete/{id}")public String deleteUser(@PathVariable("id") int id){String sql="delete from mybatis.user where id=?";jdbcTemplate.update(sql,id);return "删除成功";}@GetMapping("/updateUser/{id}")public String updateUser(@PathVariable("id") int id){String sql="update mybatis.user set name=?,pwd=? where id="+id;Object[] objects = new Object[2];objects[0]= "王八蛋";objects[1]= "66666666";jdbcTemplate.update(sql,objects);return "更新成功";}
}
3.整合Druid数据源
yaml配置文件
spring:datasource:username: rootpassword: 123456# 加入时区报错了,就增加一个时区的配置就OK了serverTimezone=UTCurl: jdbc:mysql://localhost:3306/mybatis?useUnicode=true&characterEncoding=utf-8&serverTimezone=UTCdriver-class-name: com.mysql.cj.jdbc.Drivertype: com.alibaba.druid.pool.DruidDataSource # 自定义数据源#Spring Boot 默认是不注入这些属性值的,需要自己绑定#druid 数据源专有配置initialSize: 5minIdle: 5maxActive: 20maxWait: 60000timeBetweenEvictionRunsMillis: 60000minEvictableIdleTimeMillis: 300000validationQuery: SELECT 1 FROM DUALtestWhileIdle: truetestOnBorrow: falsetestOnReturn: falsepoolPreparedStatements: true#配置监控统计拦截的filters,stat:监控统计、log4j:日志记录、wall:防御sql注入#如果允许时报错 java.lang.ClassNotFoundException: org.apache.log4j.Priority#则导入 log4j 依赖即可,Maven 地址:https://mvnrepository.com/artifact/log4j/log4jfilters: stat,wall,log4jmaxPoolPreparedStatementPerConnectionSize: 20useGlobalDataSourceStat: trueconnectionProperties: druid.stat.mergeSql=true;druid.stat.slowSqlMillis=500
配置文件嵌入以后即可以使用
package com.whx.springbootstudydata.config;import com.alibaba.druid.pool.DruidDataSource;
import com.alibaba.druid.support.http.StatViewServlet;
import com.alibaba.druid.support.http.WebStatFilter;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.boot.web.servlet.FilterRegistrationBean;
import org.springframework.boot.web.servlet.ServletRegistrationBean;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import javax.servlet.Filter;
import javax.sql.DataSource;
import java.util.HashMap;
import java.util.Map;@Configuration
public class DruidConfig {@ConfigurationProperties(prefix = "spring.datasource")@Beanpublic DataSource druidDataSource() {return new DruidDataSource();}// 后台监控:web.xml, ServletRegistrationBean// 因为SpringBoot 内置了 servlet容器,所以没有web.xml,替代方法ServletRegistrationBean@Beanpublic ServletRegistrationBean statViewServlet() {ServletRegistrationBean bean = new ServletRegistrationBean<>(new StatViewServlet(), "/druid/*");//后台需要有人登陆,账号密码Map initParameters = new HashMap<>();//增加配置initParameters.put("loginUsername", "root");//登陆key 是固定的loginUsername loginPasswordinitParameters.put("loginPassword", "admin");// 允许谁可以访问initParameters.put("allow", "");//禁止谁能访问//initParameters.put("kuangshen","192.168.1.2");bean.setInitParameters(initParameters);//设置初始化参数return bean;}// filter过滤器@Beanpublic FilterRegistrationBean webStatilter() {FilterRegistrationBean bean = new FilterRegistrationBean<>();bean.setFilter(new WebStatFilter());//可以过滤那些请求Map initParameters = new HashMap<>();//这些东西不进行统计initParameters.put("exclusions", "*.js,*.cs,/druid/*");bean.setInitParameters(initParameters);return bean;}
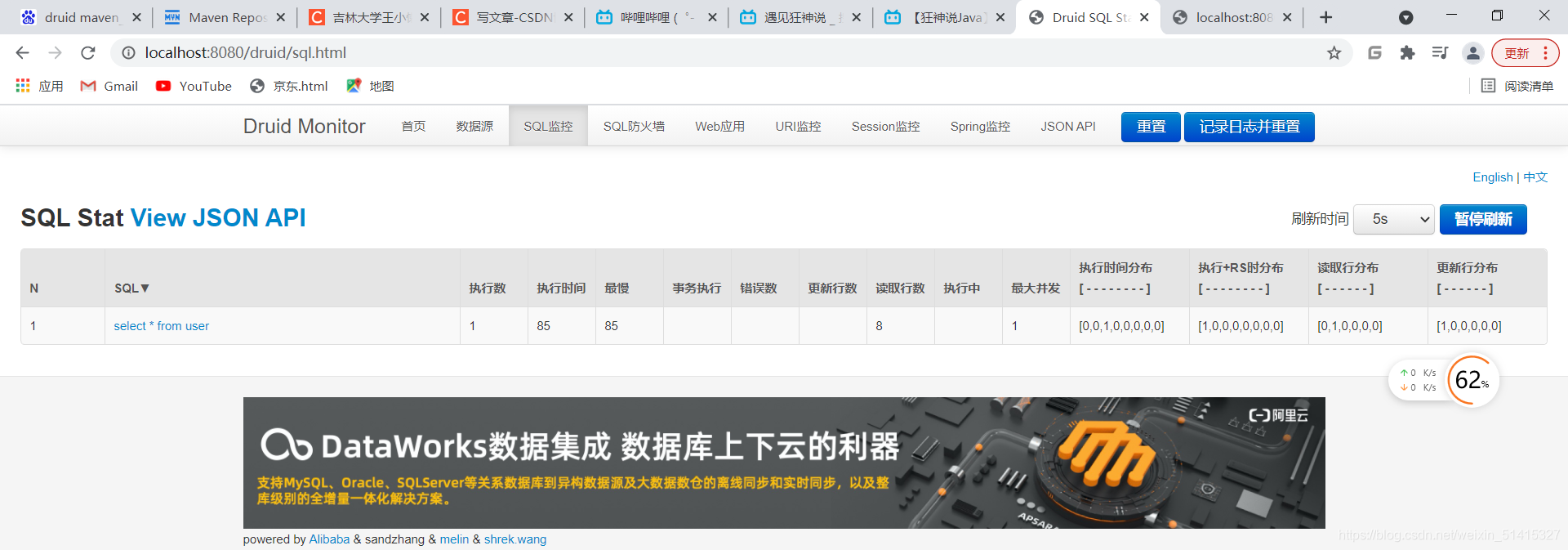
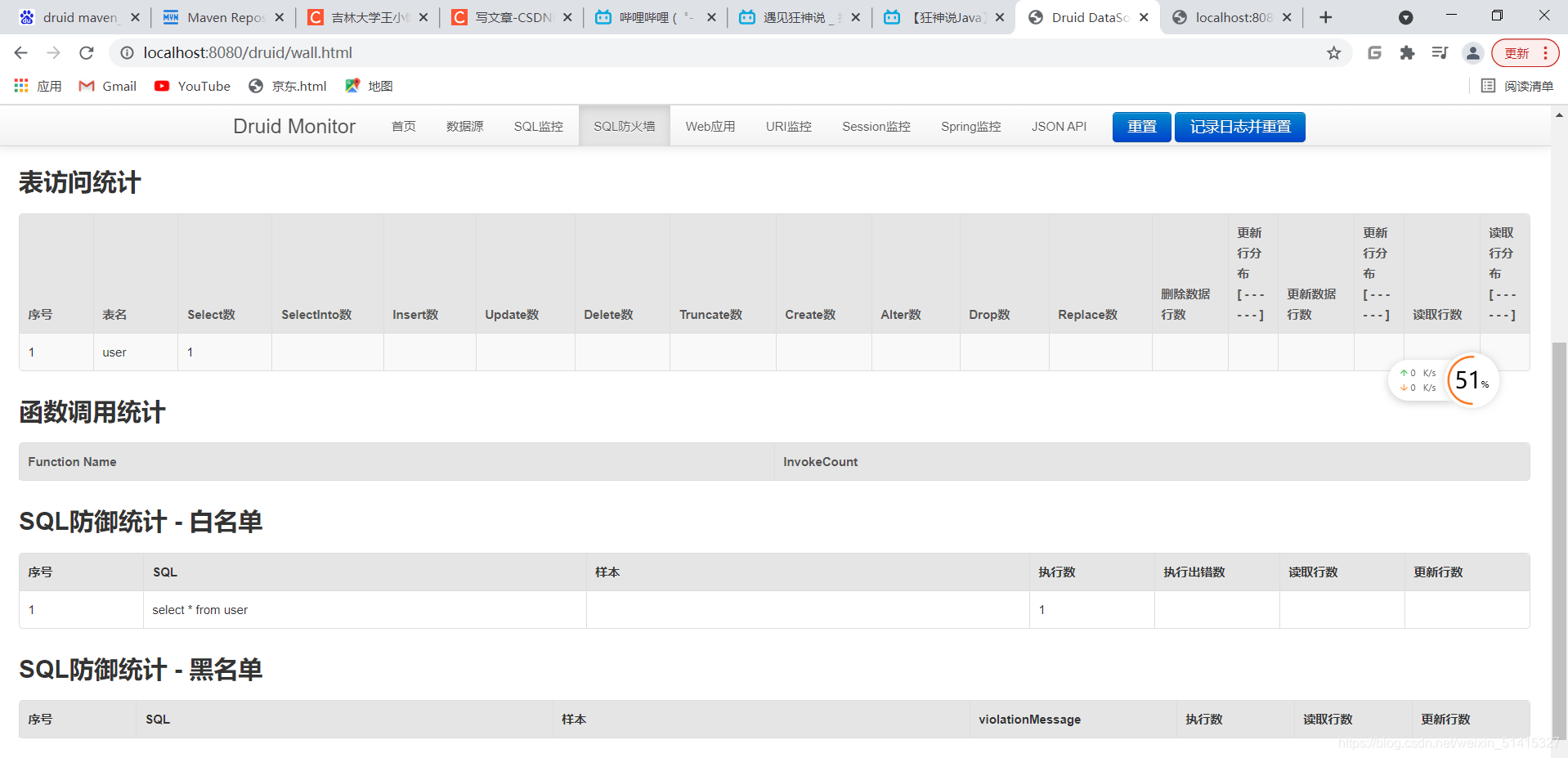
} 然后通过访问相关url获取在druid中的记录
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!