CVPR2021活体检测Cross Modal Focal Loss for RGBD Face Anti-Spoofing
论文链接:https://openaccess.thecvf.com/content/CVPR2021/papers/George_Cross_Modal_Focal_Loss_for_RGBD_Face_Anti-Spoofing_CVPR_2021_paper.pdf
代码链接:bob / bob.paper.cross_modal_focal_loss_cvpr2021 · GitLab
动机
近年来活体检测技术发展十分迅速,基于特征的方法层出不穷,比如:颜色特征、纹理特征、运动特征、活性线索(liveliness cue)、局部二值模式等。此外,还有些方法利用辅助信息来监督模型训练,如binary mask、depth map等。但这些方法在面对3D的假体攻击时的泛化性能不够好。因此,一些方法开始利用多模态数据来进行活体检测,多模态数据之间可以信息互补,提升模型在面对未知攻击时的鲁棒性。然而,多模态数据在带来丰富信息的同时,也加大了模型的参数量和计算量,模型也会倾向于过拟合训练集中的数据。为了解决这些问题,作者提出了 Cross Modal Focal Loss for RGBD Face Anti-Spoofing
创新点
1、提出了一个能同时提取RGB以及深度图信息的模型
2、提出了跨模态的focal loss
方法论
Preprocessing
对于RGB图像,作者首先利用MTCNN来对图像进行裁剪、关键点定位及人脸仿射对齐,随后再将对齐后的人脸图像resize到224*224的分辨率。对于深度图,作者利用绝对中值差(median absolute deviation,MAD)来归一化图像,将各像素的深度值限制在8 bit以内,随后再使用与RGB图像相同的预处理来处理归一化后的深度图。MAD的实现细节如下:
# 首先找出图像中深度大于1的深度值
face_c=face_c[face_c>1.0]med = np.median(face_c)
mad = np.median(np.abs(face_c - med))# 将深度值归一化并映射到0~255之间
data_n = ((data-med+n_sigma*mad)/(2.0*n_sigma*mad))*255.0Network Architecture
作者在设计网络结构时使用了多头架构来防止模型的过拟合,如下图所示。
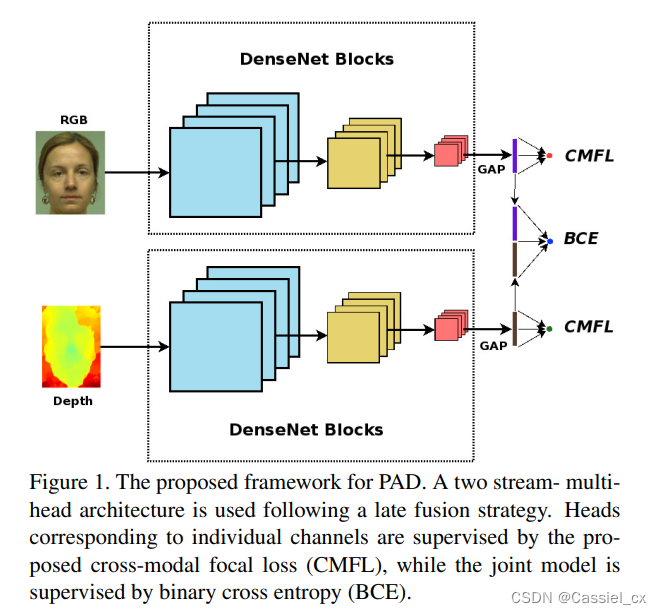
可以看到,该网络包含两个分支,RGB图与深度图在经过各自的densenet blocks以及全局平均池化层后,拼接在一起,形成第三个分支。随后在这三个分支后面都接一个全连接层,以形成最终的分类头。三个分类头都由损失函数进行监督,这就迫使网络从各个通道以及联合表示中学习判别信息,从而减少过拟合的可能性。
前两个分支由 densenet161 的前八个layer组成 (nn.Sequential(*models.densenet161()[0:8]))。作者使用来自 Image Net 数据集的预训练权重来初始化各个分支。RGB 和深度图的输入通道数已分别修改为 3 和 1。对于深度分支,使用三通道权重的平均值来初始化第一层中修改后的卷积核的权重,具体的代码实现如下:
features = nn.Sequential(OrderedDict([('conv0', nn.Conv2d(3, 96, kernel_size=7, stride=2,padding=3, bias=False)),('norm0', nn.BatchNorm2d(96)),('relu0', nn.ReLU(inplace=True)),('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),]))temp_layer = features[0]
mean_weight = np.mean(temp_layer.weight.data.detach().numpy(),axis=1)
new_weight = np.zeros((96,1,7,7))for i in range(1):new_weight[:,i,:,:]=mean_weightfeatures[0]=nn.Conv2d(1, 96, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
features[0].weight.data = torch.Tensor(new_weight)在每个分支的尾部,都添加了一个全局平均池化层。此外,RGB 和深度嵌入特征还会连接起来形成联合嵌入特征。在每个嵌入特征的后面添加一个全连接层,然后是 sigmoid 激活层,以添加非线性以及使得输出在0~1之间。
Cross Modal Focal Loss function
CMFL 的核心思想是,当其中一个通道能够以足够高的置信度正确分类样本时,可以降低样本在另一个分支中的损失权重。如果一个通道可以自信地正确分类样本,那么我们也不希望另一个分支更多地去惩罚模型。CMFL 的公式如下:

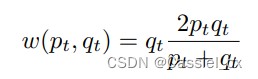
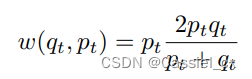
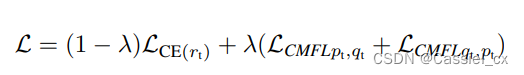
其中,p、q 分别是两个分支的输出,分数越高,模型认为这张图片是真人的概率就越大。
该损失函数的具体代码实现如下:
import torch
import torch.nn as nn
import numpy as np
from torch.nn import functional as F
import torch.nn
from torch.autograd import Variableclass CMFL(nn.Module):"""Cross Modal Focal Loss"""def __init__(self, alpha=1, gamma=2, binary=False, multiplier=2, sg=False):super(CMFL, self).__init__()self.alpha = alphaself.gamma = gammaself.binary = binaryself.multiplier =multiplierself.sg=sgdef forward(self, inputs_a, inputs_b, targets):bce_loss_a = F.binary_cross_entropy(inputs_a, targets, reduce=False)bce_loss_b = F.binary_cross_entropy(inputs_b, targets, reduce=False)pt_a = torch.exp(-bce_loss_a)pt_b = torch.exp(-bce_loss_b)eps = 0.000000001if self.sg:d_pt_a=pt_a.detach()d_pt_b=pt_b.detach()wt_a=((d_pt_b + eps)*(self.multiplier*pt_a*d_pt_b))/(pt_a + d_pt_b + eps)wt_b=((d_pt_a + eps)*(self.multiplier*d_pt_a*pt_b))/(d_pt_a + pt_b + eps)else:wt_a=((pt_b + eps)*(self.multiplier*pt_a*pt_b))/(pt_a + pt_b + eps)wt_b=((pt_a + eps)*(self.multiplier*pt_a*pt_b))/(pt_a + pt_b + eps)if self.binary:wt_a=wt_a * (1-targets)wt_b=wt_b * (1-targets)f_loss_a = self.alpha * (1-wt_a)**self.gamma * bce_loss_af_loss_b = self.alpha * (1-wt_b)**self.gamma * bce_loss_bloss= 0.5*torch.mean(f_loss_a) + 0.5*torch.mean(f_loss_b) return loss实验结果
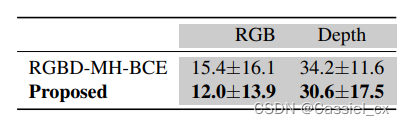
在 WMCA 和 HQ-WMCA 数据集上的实验结果如下所示:


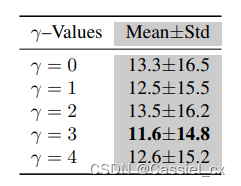
对 γ 和单模态数据的消融实验结果如下:
结论
在这篇文章中,作者提出了一种用于 RGB-D 表示攻击检测的新架构和损失函数,该架构也适用于其他多通道分类问题。提出的 CMFL 可根据各个通道的置信度来调整样本对损失的贡献。该框架可以简单地扩展到多个通道和不同的分类问题。最后,在两个公开数据集中的性能也证明了所提出方法的有效性。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!