mysql 标记重复数据_mysql查询表里的重复数据方法
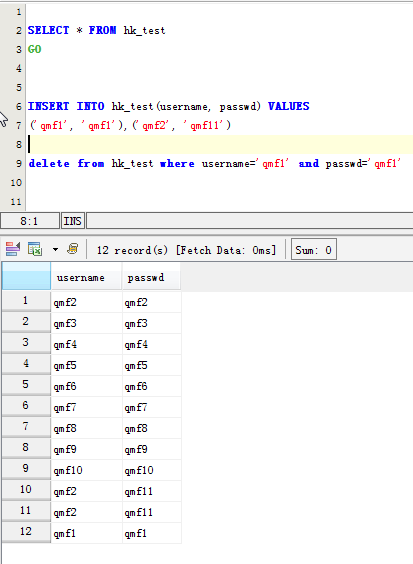
INSERT INTO hk_test(username, passwd) VALUES
('qmf1', 'qmf1'),('qmf2', 'qmf11')
delete from hk_test where username='qmf1' and passwd='qmf1'
MySQL里查询表里的重复数据记录:
先查看重复的原始数据:
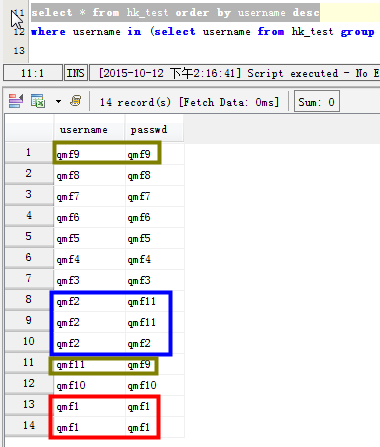
场景一:列出username字段有重读的数据
select username,count(*) as count from hk_test group by username having count>1;
SELECT username,count(username) as count FROM hk_test GROUP BY username HAVING count(username) >1 ORDER BY count DESC;
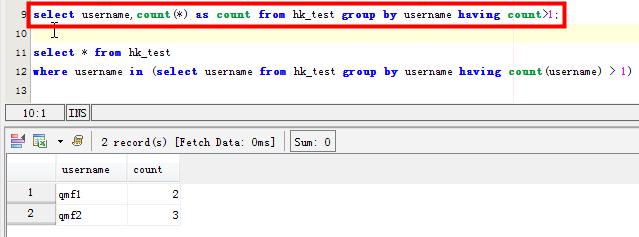
这种方法只是统计了该字段重复对应的具体的个数
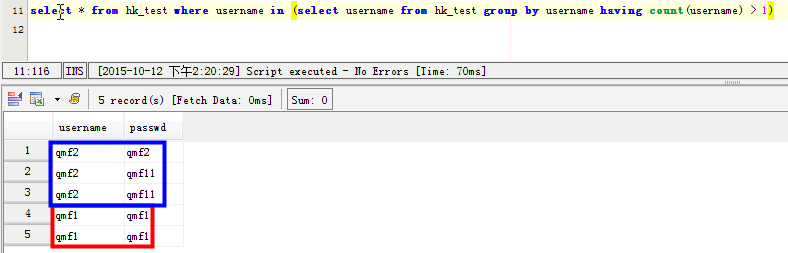
场景二:列出username字段重复记录的具体指:
select * from hk_test where username in (select username from hk_test group by username having count(username) > 1)
SELECT username,passwd FROM hk_test WHERE username in ( SELECT username FROM hk_test GROUP BY username HAVING count(username)>1)
但是这条语句在mysql中效率太差,感觉mysql并没有为子查询生成临时表。在数据量大的时候,耗时很长时间
解决方法:
于是使用先建立临时表
create table `tmptable` as (
SELECT `name`
FROM `table`
GROUP BY `name` HAVING count(`name`) >1
);
然后使用多表连接查询
SELECT a.`id`, a.`name`
FROM `table` a, `tmptable` t
WHERE a.`name` = t.`name`;
结果这次结果很快就出来了。
用 distinct去重复
SELECT distinct a.`id`, a.`name`
FROM `table` a, `tmptable` t
WHER
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!