天池竞赛查漏补缺:CSV结果数据融合
模型数据融合:取模型1的itemcf与模型usercf的结果,并将其融合在一起
test_usercf_item=pd.merge(test_usercf,result_item,on=[‘user_id’],how=‘left’)
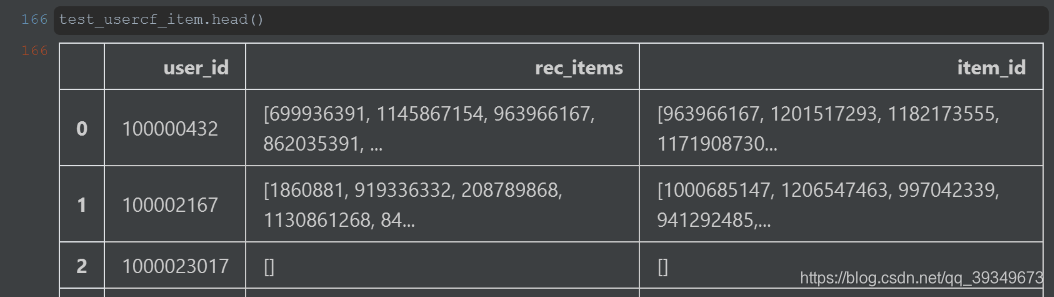
top前50热卖商品列表:
top=[1089679943, 1057098687, 1213502497, 1222231185, 210044365, 1184907650, 1182940081, 719093075, 945072059, 1034988387, 1181869540, 473914236, 1181415108, 1221849181, 812566288, 1027136273, 1191690984, 1125212165, 1058639181, 1147108060, 333921, 208789868, 325284569, 1215274749, 799256404, 135247206, 883229628, 1179543312, 704643366, 955193033, 1164287835, 1176276872, 331431843, 983522798, 877095771, 1229715123, 991641432, 893336129, 1152853911, 862140987, 1229789483, 1230367534, 1177605700, 862784080, 518881107, 1152764912, 1141201470, 1112732679, 1086203236, 953063189]
将top50合并成一个字符串
top_str=",".join(str(y) for y in top)
type(top_str)
生成新的一个[‘tuijian’]列作为结果合并的列
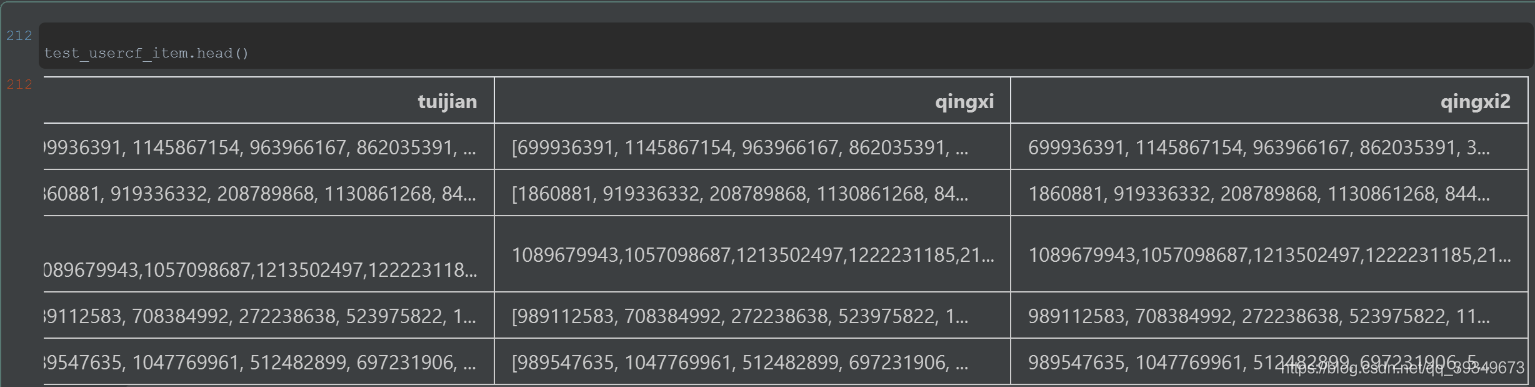
test_usercf_item[‘tuijian’]=test_usercf_item[‘rec_items’]+test_usercf_item[‘item_id’]+top_str

对tuijian结果进行数据清洗:
test_usercf_item=pd.DataFrame(test_usercf_item[‘tuijian’].astype(str))
test_usercf_item[‘qingxi’] = test_usercf_item.tuijian.apply(lambda x: (x.replace(’[]’,’’)))
上一轮清洗不彻底,实际可以一次多次清洗一步到位:
test_usercf_item[‘qingxi2’] = test_usercf_item.qingxi.astype(str ).apply(lambda x: (x.replace(’[’,’’).replace(’]’,’’)))
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!