【嵌入式硬件芯片开发笔记】EEPROM芯片M24C32配置流程
【嵌入式硬件芯片开发笔记】EEPROM芯片M24C32配置流程
文章目录
- M23C32
- 开始运行
- 初始化
- 代码例程
- 附录:压缩字符串、大小端格式转换
- 压缩字符串
- 浮点数
- 压缩Packed-ASCII字符串
- 大小端转换
- 什么是大端和小端
- 数据传输中的大小端
- 总结
- 大小端转换函数
M23C32
32-Kbit serial I²C bus EEPROM - 105°C operation
适用于M24C32/M24C32-DRE

读取存储的从机地址为:0x50
读取标识页面的从机地址为:0x58
WC引脚接地,存储可以进行写操作
地址长度为16位
存储地址:0x0000-0x0FFF,即4096个Bytes,32K-Bits
标识页面地址:0x0000-0x001F,即32个Bytes
标识页面在进行写操作时,b10为0,即add &= ~(1<<10)
开始运行
- 检查从机设备是否回应
- 读取制造商代码,并对比是否为0x20、0xE0、0x0C
初始化
按要求进行读写操作
- 在Mem地址0x0000-0x0007范围内进行读写测试:清空该区域(写入0x00);依次写入8、9、A、B、C、D、F
- 编译时间操作:
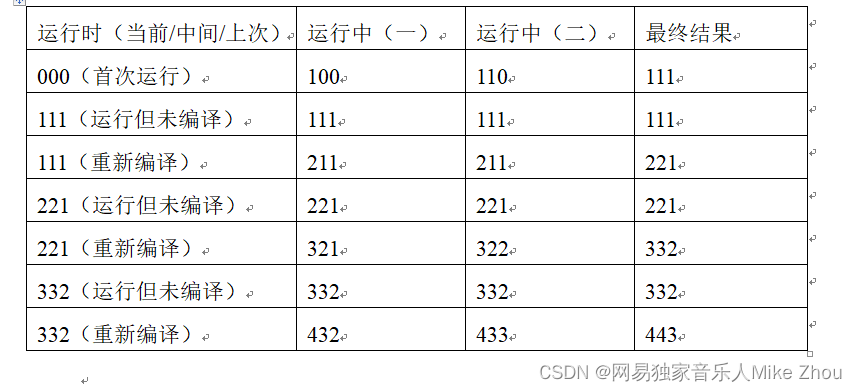
共分3块区域,用于存储当前编译时间、中间编译时间、上次编译时间,分别为0x0008-0x000E,0x0010-0x0006,0x0018-0x001E;且正常写入一次后,0x000F、0x0017、0x001F都为1。
时间存储格式为:yy yy mm dd hh mm ss 1
以十进制的方式,由低到高存储到每个寄存器中,比如2022/11/29 16:45:30,存储后为:
20d 22d 11d 29d 16d 45d 30d 1d,共8个地址存储64位数据
当前编译时间每一次运行都会被写入到0x0008-0x000E中。
当前时间与中间时间相同时,输出“上次运行后未重新编译”;当前时间与中间时间不同时,将中间时间写入到上次时间中,再将当前时间写入到中间时间中;上次时间标志0x001F的值不为1时,将当前时间写入到上次时间中,否则读取上次时间。
以下表格为三种时间地址范围在不同运行状态下的结果:(数字越大表示时间越靠后,为0表示首次运行)
代码例程
static char now_date[16] = __DATE__;
static char now_time[16] = __TIME__;
static char month_names[] = "JanFebMarAprMayJunJulAugSepOctNovDec";
/*!* @brief 初始化M24C32** @param None** @return 0/1: 错误/正确标志*/
uint8_t Init_M24C32(void)
{uint8_t dat=0;uint32_t dat_32=0;uint8_t i=0;char strings[]="";int int_data[3]={0,0,0};uint8_t now_time_buf[8];uint8_t last_time_buf[8];uint8_t mid_time_buf[8];if(I2C_Judge(&hi2c1,M24C32_Mem_Slave_Add)!=true || I2C_Judge(&hi2c1,M24C32_Id_Slave_Add)!=true){return 0;}dat_32=I2C_Read_y(&hi2c1,M24C32_Id_Slave_Add,0x0000,2,3,true);if(dat_32!=0x0020E00C){return 0;}printf("[INFO] 开始Mem写入测试\n");dat=0;for(i=0;i<8;i++){dat=0;I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+i,2,&dat,1,true); if(I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+i,2,1,true)==0){printf("[INFO] Mem 0x000%d 清空正确: %02X\n",i,dat);}else{printf("[INFO] Mem 0x000%d 清空错误: %02X\n",i,dat);printf("[INFO] Mem 清空中断\n");return 0;}dat=i+8;I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+i,2,&dat,1,true);if(I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+i,2,1,true)==i+8){printf("[INFO] Mem 0x000%d 写入正确: %02X\n",i,dat);}else{printf("[INFO] Mem 0x000%d 写入错误: %02X\n",i,dat);printf("[INFO] Mem 写入中断\n");return 0;}}sscanf(now_date, "%s %d %d", strings, &int_data[0], &int_data[1]);int_data[2]=(strstr(month_names, strings)-month_names)/3+1;dat=(uint8_t)(int_data[1]/100);I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x08,2,&dat,1,true); dat=(uint8_t)(int_data[1]%100);I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x09,2,&dat,1,true); dat=(uint8_t)int_data[2];I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x0A,2,&dat,1,true); dat=(uint8_t)int_data[0];I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x0B,2,&dat,1,true);sscanf(now_time, "%d:%d:%d",&int_data[0], &int_data[1],&int_data[2]);dat=(uint8_t)int_data[0];I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x0C,2,&dat,1,true); dat=(uint8_t)int_data[1];I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x0D,2,&dat,1,true); dat=(uint8_t)int_data[2];I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x0E,2,&dat,1,true); dat=1;I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x0F,2,&dat,1,true);for(i=0;i<8;i++){now_time_buf[i]=I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x08+i,2,1,true); mid_time_buf[i]=I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x10+i,2,1,true);}printf("[INFO] 写入当前编译时间:%02d%02d/%02d/%02d %02d:%02d:%02d\n",now_time_buf[0],now_time_buf[1],now_time_buf[2],now_time_buf[3],now_time_buf[4],now_time_buf[5],now_time_buf[6]);if( now_time_buf[0]!=mid_time_buf[0] || now_time_buf[1]!=mid_time_buf[1] || now_time_buf[2]!=mid_time_buf[2] || now_time_buf[3]!=mid_time_buf[3] || now_time_buf[4]!=mid_time_buf[4] || now_time_buf[5]!=mid_time_buf[5] || now_time_buf[6]!=mid_time_buf[6] ){for(i=0;i<8;i++){dat=mid_time_buf[i];I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x18+i,2,&dat,1,true); dat=now_time_buf[i];I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x10+i,2,&dat,1,true);}}else{printf("[INFO] 上次运行后未重新编译\n");}if(I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x1F,2,1,true)==1){for(i=0;i<8;i++){last_time_buf[i]=I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x18+i,2,1,true);}printf("[INFO] 上次编译时间:%02d%02d/%02d/%02d %02d:%02d:%02d\n",last_time_buf[0],last_time_buf[1],last_time_buf[2],last_time_buf[3],last_time_buf[4],last_time_buf[5],last_time_buf[6]);}else{printf("[INFO] 当前编译时间:%s %s\n",now_date,now_time);sscanf(now_date, "%s %d %d", strings, &int_data[0], &int_data[1]);int_data[2]=(strstr(month_names, strings)-month_names)/3+1;dat=(uint8_t)(int_data[1]/100);I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x18,2,&dat,1,true); dat=(uint8_t)(int_data[1]%100);I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x19,2,&dat,1,true); dat=(uint8_t)int_data[2];I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x1A,2,&dat,1,true); dat=(uint8_t)int_data[0];I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x1B,2,&dat,1,true);sscanf(now_time, "%d:%d:%d",&int_data[0], &int_data[1],&int_data[2]);dat=(uint8_t)int_data[0];I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x1C,2,&dat,1,true); dat=(uint8_t)int_data[1];I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x1D,2,&dat,1,true); dat=(uint8_t)int_data[2];I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x1E,2,&dat,1,true); dat=1;I2C_Write_x(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x1F,2,&dat,1,true);printf("[INFO] 写入当前编译时间至上次编译时间:%02d%02d/%02d/%02d %02d:%02d:%02d\n",I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x18,2,1,true),I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x19,2,1,true),I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x1A,2,1,true),I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x1B,2,1,true),I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x1C,2,1,true),I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x1D,2,1,true),I2C_Read_y(&hi2c1,M24C32_Mem_Slave_Add,0x0000+0x1E,2,1,true));}return 1;
}
附录:压缩字符串、大小端格式转换
压缩字符串
首先HART数据格式如下:


重点就是浮点数和字符串类型
Latin-1就不说了 基本用不到
浮点数
浮点数里面 如 0x40 80 00 00表示4.0f
在HART协议里面 浮点数是按大端格式发送的 就是高位先发送 低位后发送
发送出来的数组为:40,80,00,00
但在C语言对浮点数的存储中 是按小端格式来存储的 也就是40在高位 00在低位
浮点数:4.0f
地址0x1000对应00
地址0x1001对应00
地址0x1002对应80
地址0x1003对应40
若直接使用memcpy函数 则需要进行大小端转换 否则会存储为:
地址0x1000对应40
地址0x1001对应80
地址0x1002对应00
地址0x1003对应00
大小端转换:
void swap32(void * p)
{uint32_t *ptr=p;uint32_t x = *ptr;x = (x << 16) | (x >> 16);x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);*ptr=x;
}压缩Packed-ASCII字符串
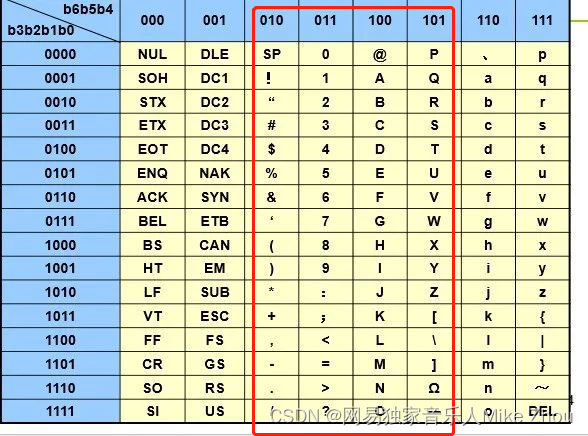
本质上是将原本的ASCII的最高2位去掉 然后拼接起来 比如空格(0x20)
四个空格拼接后就成了
1000 0010 0000 1000 0010 0000
十六进制:82 08 20
对了一下表 0x20之前的识别不了
也就是只能识别0x20-0x5F的ASCII表
压缩/解压函数后面再写:
//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_ASCII_to_Pack(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{if(str_len%4){return 0;}uint8_t i=0;memset(buf,0,str_len/4*3); for(i=0;i<str_len;i++){if(str[i]==0x00){str[i]=0x20;}}for(i=0;i<str_len/4;i++){buf[3*i]=(str[4*i]<<2)|((str[4*i+1]>>4)&0x03);buf[3*i+1]=(str[4*i+1]<<4)|((str[4*i+2]>>2)&0x0F);buf[3*i+2]=(str[4*i+2]<<6)|(str[4*i+3]&0x3F);}return 1;
}//传入的字符串和数字必须提前声明 且字符串大小至少为str_len 数组大小至少为str_len%4*3 str_len必须为4的倍数
uint8_t Trans_Pack_to_ASCII(uint8_t * str,uint8_t * buf,const uint8_t str_len)
{if(str_len%4){return 0;}uint8_t i=0;memset(str,0,str_len);for(i=0;i<str_len/4;i++){str[4*i]=(buf[3*i]>>2)&0x3F;str[4*i+1]=((buf[3*i]<<4)&0x30)|(buf[3*i+1]>>4);str[4*i+2]=((buf[3*i+1]<<2)&0x3C)|(buf[3*i+2]>>6);str[4*i+3]=buf[3*i+2]&0x3F;}return 1;
}大小端转换
在串口等数据解析中 难免遇到大小端格式问题
什么是大端和小端
所谓的大端模式,就是高位字节排放在内存的低地址端,低位字节排放在内存的高地址端。
所谓的小端模式,就是低位字节排放在内存的低地址端,高位字节排放在内存的高地址端。
简单来说:大端——高尾端,小端——低尾端
举个例子,比如数字 0x12 34 56 78在内存中的表示形式为:
1)大端模式:
低地址 -----------------> 高地址
0x12 | 0x34 | 0x56 | 0x78
2)小端模式:
低地址 ------------------> 高地址
0x78 | 0x56 | 0x34 | 0x12
可见,大端模式和字符串的存储模式类似。
数据传输中的大小端
比如地址位、起止位一般都是大端格式
如:
起始位:0x520A
则发送的buf应为{0x52,0x0A}
而数据位一般是小端格式(单字节无大小端之分)
如:
一个16位的数据发送出来为{0x52,0x0A}
则对应的uint16_t类型数为: 0x0A52
而对于浮点数4.0f 转为32位应是:
40 80 00 00
以大端存储来说 发送出来的buf就是依次发送 40 80 00 00
以小端存储来说 则发送 00 00 80 40
由于memcpy等函数 是按字节地址进行复制 其复制的格式为小端格式 所以当数据为小端存储时 不用进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x00,0x00,0x80,0x40};memcpy(&dat,buf,4);float f=0.0f;f=*((float*)&dat); //地址强转printf("%f",f);
或更优解:
uint8_t buf[]={0x00,0x00,0x80,0x40}; float f=0.0f;memcpy(&f,buf,4);
而对于大端存储的数据(如HART协议数据 全为大端格式) 其复制的格式仍然为小端格式 所以当数据为小端存储时 要进行大小端转换
如:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};memcpy(&dat,buf,4);float f=0.0f;swap32(&dat); //大小端转换f=*((float*)&dat); //地址强转printf("%f",f);
或:
uint8_t buf[]={0x40,0x80,0x00,0x00};memcpy(&dat,buf,4);float f=0.0f;swap32(&f); //大小端转换printf("%f",f);
或更优解:
uint32_t dat=0;
uint8_t buf[]={0x40,0x80,0x00,0x00};float f=0.0f;dat=(buf[0]<<24)|(buf[0]<<16)|(buf[0]<<8)|(buf[0]<<0)f=*((float*)&dat);
总结
固 若数据为小端格式 则可以直接用memcpy函数进行转换 否则通过移位的方式再进行地址强转
对于多位数据 比如同时传两个浮点数 则可以定义结构体之后进行memcpy复制(数据为小端格式)
对于小端数据 直接用memcpy写入即可 若是浮点数 也不用再进行强转
对于大端数据 如果不嫌麻烦 或想使代码更加简洁(但执行效率会降低) 也可以先用memcpy写入结构体之后再调用大小端转换函数 但这里需要注意的是 结构体必须全为无符号整型 浮点型只能在大小端转换写入之后再次强转 若结构体内采用浮点型 则需要强转两次
所以对于大端数据 推荐通过移位的方式来进行赋值 然后再进行个别数的强转 再往通用结构体进行写入
多个不同变量大小的结构体 要主要字节对齐的问题
可以用#pragma pack(1) 使其对齐为1
但会影响效率
大小端转换函数
直接通过对地址的操作来实现 传入的变量为32位的变量
中间变量ptr是传入变量的地址
void swap16(void * p)
{uint16_t *ptr=p;uint16_t x = *ptr;x = (x << 8) | (x >> 8);*ptr=x;
}void swap32(void * p)
{uint32_t *ptr=p;uint32_t x = *ptr;x = (x << 16) | (x >> 16);x = ((x & 0x00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF);*ptr=x;
}void swap64(void * p)
{uint64_t *ptr=p;uint64_t x = *ptr;x = (x << 32) | (x >> 32);x = ((x & 0x0000FFFF0000FFFF) << 16) | ((x >> 16) & 0x0000FFFF0000FFFF);x = ((x & 0x00FF00FF00FF00FF) << 8) | ((x >> 8) & 0x00FF00FF00FF00FF);*ptr=x;
}
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!