基于matlab的强化学习QLearning路径规划性能仿真
目录
1.算法概述
2.仿真效果预览
3.核心MATLAB代码预览
4.完整MATLAB程序
1.算法概述

假设我们的行为准则已经学习好了, 现在我们处于状态s1, 我在写作业, 我有两个行为 a1, a2, 分别是看电视和写作业, 根据我的经验, 在这种 s1 状态下, a2 写作业 带来的潜在奖励要比 a1 看电视高, 这里的潜在奖励我们可以用一个有关于 s 和 a 的 Q 表格代替, 在我的记忆Q表格中, Q(s1, a1)=-2 要小于 Q(s1, a2)=1, 所以我们判断要选择 a2 作为下一个行为. 现在我们的状态更新成 s2 , 我们还是有两个同样的选择, 重复上面的过程, 在行为准则Q 表中寻找 Q(s2, a1) Q(s2, a2) 的值, 并比较他们的大小, 选取较大的一个. 接着根据 a2 我们到达 s3 并在此重复上面的决策过程. Q learning 的方法也就是这样决策的. 看完决策, 我看在来研究一下这张行为准则 Q 表是通过什么样的方式更改, 提升的.
Q-Learning它是强化学习中的一种 values-based 算法,是以QTable表格形式体现,在学习中遇到的任何操作存入QTable中,根据之前的学习选择当前最优操作,也可以根据设置的e_greedy机率随机选择。
Q-Learning的QTable标签更新公式:
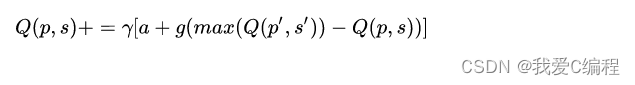
Q-Learning的计算步骤:
1.判断在当前位置可以有几种操作;
2.根据当前位置允许的操作选择一个操作;
3.根据选择的操作进行奖赏;
4.修改当前行为的本次操作权重;
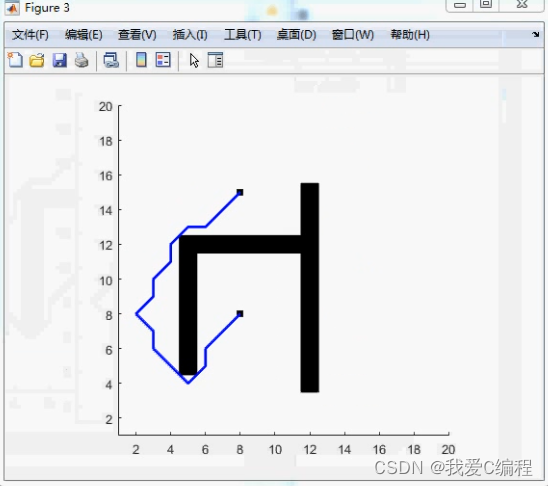
2.仿真效果预览
matlab2022a仿真测试如下:


3.核心MATLAB代码预览
NNPolicy=zeros(prod([driver_actions Xscale Yscale]),1);
for i=1:pathtimesiPositions = stpt; drivers = 0; %开车E = zeros(prod([driver_actions Xscale Yscale]),1);for j=1:maxiter%计算训练驾驶策略if j>=2 Choice = ndi2lin([1 Positions(1) Positions(2)],[driver_actions Xscale Yscale]);Choice2 = ndi2lin([drivers Prestate(1) Prestate(2)],[driver_actions Xscale Yscale]);delta = feedback + cb*max(NNPolicy(Choice:Choice+driver_actions-1))-NNPolicy(Choice2);E(Choice2) = 1;NNPolicy = NNPolicy + ca*delta*E;E = cb*lambda*E*~exploring;end%选择动作Choice = ndi2lin([1 Positions(1) Positions(2)],[driver_actions Xscale Yscale]); Choice = [Choice:Choice+driver_actions-1]; tmps = find(NNPolicy(Choice) == max(NNPolicy(Choice))); %是否转向 drivers = tmps(ceil(rand * length(tmps))); %探索策略if rand32Error(k)=mean(Itertion_times(length(Itertion_times)-32+1:length(Itertion_times))); elseError(k)=mean(Itertion_times(1:length(Itertion_times))); endk=k+1;
end
A_005 4.完整MATLAB程序
matlab源码说明_我爱C编程的博客-CSDN博客
V
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!