论文阅读——指针网络(Pointer Networks)
论文:Pointer Networks
作者:Oriol Vinyals et al.
1 Introduction
背景:RNN应用于学习序列函数有很多年了,然而以往的框架限制了序列的输入输出长度。最近的研究引进了新的Seq2seq范式解决了这个约束。
问题:这些方法仍然需要预先确定输出字典的大小。由于这个约束,因此这个框架不能应用于组合优化问题(输出字典的大小取决于输入序列的长度)。
解决办法:通过重新利用注意力机制来创建指向输入元素的指针来解决这个限制。
2 Models
2.1 Sequence-to-Sequence Model
给定一个训练对(training pair) ,Seq2seq模型使用参数模型(带有参数
的RNN)计算条件概率
,来估计概率链式法则的项。
其中, 是一个
维向量序列,
是一个拥有
个索引的序列,每个值在1到
之间。
模型参数通过最大化训练集的条件概率来学习获得
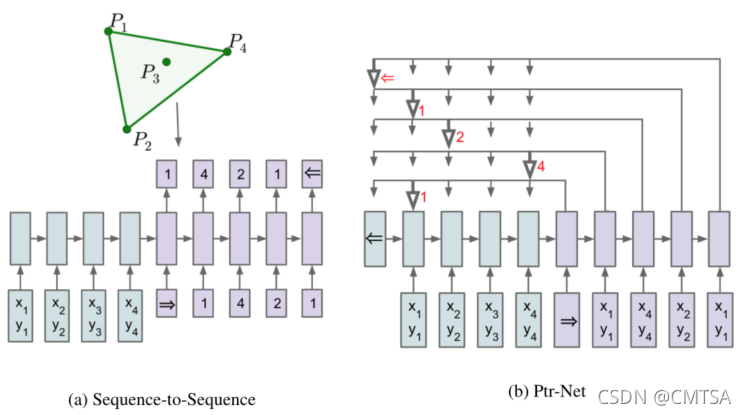
2.2 Content Based Input Attention
普通的序列到序列模型,利用输入序列 的末端识别RNN的固定维度状态,来生成整个输出序列
。这限制了可以流向生成模型的信息和计算量。注意力模型通过使用额外的神经网络增强编码器和解码器 RNN 来改善这个问题,该神经网络在整个编码器 RNN 状态序列上使用注意力机制。
以下是符号说明, 和
分别是编码器和解码器隐藏层状态。对于LSTM RNNs 来说,使用输出门之后的状态(
)。则每个一输出时刻
的注意力向量如下:
这里softmax将 归一化到 (0, 1)来作为输入序列上方的“attention” mask,
、
和
都是可学习参数。
该模型比Seq2seq模型要好,但是不适用于输出字典大小依赖于输入的问题。
2.3 Ptr-Net
经过修改后的模型(Ptr-Net)允许解决组合优化问题(输出字典的大小取决于输入序列中的元素数量)。
Seq2seq模型在固定大小的输出字典上使用一个softmax分布来计算 ,因此不能解决输出字典大小等于输入序列长度的问题。为了解决这个问题,这里使用了注意力机制,公式如下:
这里,不用混合编码器状态来向解码器传播额外信息,相反,使用 作为指向输入元素的指针。类似地,对于
,只需要复制相应的
作为输入。
该方法专门针对输出离散且对应于输入位置的问题。
3 Motivation and Datasets Structure
略
4 Empirical Results
略
5 Conclusions
论文描述了Ptr-Net(一个新的体系结构),其允许我们学习一个序列 通过给定另一个序列
的条件概率,其中
是一个
中位置相对应的离散标记序列。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!