Python基本语法及使用
Python基本语法及使用
Author: Lijb
Email:lijb1121@163.com
http://www.runoob.com/python3/python3-tutorial.html
Base
- 输出语句
print()---在python3中需要加括号---内置函数
向控制台输出内容
- 输入语句
input(提示信息)
将用户在控制台输入的内容转换城字符串输出
- 变量
1. 赋值后使用---(先定义,后使用)
2. 作用范围:从定义开始到包含它的代码块结束
3. 变量相当于一个标签贴在了数据上(贴在对象上)---python实际上是没有类型的---只有一个类型(对象类型)(str,int,float)书写形式:变量名=变量值- 标识符
名字:变量名,函数名,类名
语法:(强制性 )
1. 合法标识符,字母,数字(不能开头),下划线中文也是合法的标识符(属于字母) 例如:呵呵=10;---强烈不建议用,会出现中文乱码Python2:ASCIIPython3:UTF-8(Unicode)
2. 大小写敏感
3. 关键字不能使用
4. 没有长度限制开发习惯:和Java一样
- 数据类型
1. 整型:int 32:-2^31~2^31-1 64:-2^63~2^63-1
2. 浮点型:float大小没有限制 inf:无限大e计法:科学计数法 1e+10 1乘以10的10次方
3. 字符串:str:'a' "a" '''a''' """a"""(三引号可以换行)
4. 布尔类型:bool:True False
5. 空值:None
6. 复数:实部+虚部 a+bj
不可变数据类型
--------------------------------------------------------
可变数据类型
-
7. 列表:list是一种有序的集合
8. 元组:tuple是一种有序的集合(不可变)
9. 字典:dict 集合set
- 字符串
1. 单引号,双引号,三引号包含的内容---字符串---由一个一个的字符组成
2. 引号成对出现
3. 转义字符---r表示原始字符串:不会发生转义
4. 长字符串:指三引号包含的字符串
5. len():内置函数---参数长度
1. 字符串-->整型:用int()函数 --要求参数必须为数字(`整数`)的字符串
2. 字符串-->浮点型:用float() ---底层整数部分和小数部分是分开的 如:".123"转成浮点型为0.123
3. 浮点型-->整型:用int()函数 --直接去掉小数部分
4. 整型-->浮点型:用float()函数 --参数必须为数字,如果数字较大则采用e计法展示(科学记数法)
5. 浮点型-->字符串:用str()函数
6. 整型-->字符串:用str()函数# int() float() str() list() 但凡与数据类型相关的内置函数-->都是工厂函数-->这种转换模式也是工厂模式
- 获取类型的信息
1. type():查看数据的类型
2. isinstance();参数一:具体当然数据参数二:数据的类型返回值:布尔值--->判断参数一和参数二是否匹配
- 表达式
定义:变量和字面值用某个式子连接的模式
# 表达式必须有固定的字面值
- 运算符
1. 一般运算符:+ - * /(真除法) % //(floor除法) **(幂运算)
2. 赋值运算符:= += -= *= /= %= //=
3. 布尔运算符:(比较运算符)
4. 逻辑运算符:配合布尔运算符and or not
5. 位运算符:>> <<& 按位求与,两者都为1 结果为1否则为0| 按位求或~ 按位求非^ 按位求异或
6. 三元运算符:a=(10 if 1<0 else 20)
- 优先级
1. 先乘除,后加减
2. 幂运算优先
3. 元数越少,优先级越高高--->低幂运算-->正负号-->算术运算符-->比较运算符-->逻辑运算符
流程控制
条件分支流程
- if-else
if 布尔表达式:代码块
--------------------------------------------------------------------------------------
if 布尔表达式:代码块
else:代码块
--------------------------------------------------------------------------------------
if 布尔表达式:代码块
elif:代码块
else:代码块
--------------------------------------------------------------------------------------
三种结构:if if-else if-elif-elif-else 相互之间可以嵌套使用
- 断言
assert
1. 这个关键字后面的条件为假,则系统自动奔溃,抛出异常AssertionError
2. 这个关键字后面的条件为真,则系统正常运行
循环流程
Python提供了for循环和while循环(在Python中没有do..while循环)
while循环
1.语法:while 布尔表达式:代码块示例:
n=1
while n<10:print("while循环")n+=1n=1
while True:print("while循环")n+=1if n==10:break
2.语法while 布尔表达式:代码块1else :代码块2
#注:布尔表达式条件为真执行代码块1,条件为假执行代码块2示例:
count = 0
while count < 5:print count, " is less than 5"count = count + 1
else:print count, " is not less than 5"#补充:while后面可以跟True/False---> 0/1--->任何一个对象(只要对象不为空就一直循环)
list=[1,2,3,4]
while list:front,list=list[0],list[1:]print(front,list)
for循环
也称之为:计数循环
Python中的for循环可以调方法、可以捕获异常
语法:for 目标 in 表达式:目标:变量表达式:元组、列表、字符串--->可迭代对象
示例1:#表达式为字符串
for i in "hello":print(i)示例2:#表达式为列表
list=[1,2,3,4,5,6,7,8,9,0]
for i in list:print(i)示例3:#表达式为元组
tuple=(1,2,3,4,5,6,7,8,9,0)
for i in tuple:print(i)
- range()内置函数
range([start=0],stop,[step=1])1.[]:可选参数2.start:表示从start开始默认为0;stop表示到stop结束;step:表示步幅默认为13.range()函数返回一个range对象(Python2里面返回的是列表)--->可迭代对象 示例1:#如果step为1的话可以直接写成for i in range(10):
for i in range(0,10,2):print(i)
- break
跳出当前循环
- continue
跳过本次循环--->不会影响其他循环
- pass
pass是空语句,是为了保持程序结构的完整性。
- 循环嵌套使用
1.#九九乘法表
for i in range(1,10):for j in range(1,i+1):print("%d*%d=%2d" % (j,i,j*i),end=" ")print (" ")1*1= 1
1*2= 2 2*2= 4
1*3= 3 2*3= 6 3*3= 9
1*4= 4 2*4= 8 3*4=12 4*4=16
1*5= 5 2*5=10 3*5=15 4*5=20 5*5=25
1*6= 6 2*6=12 3*6=18 4*6=24 5*6=30 6*6=36
1*7= 7 2*7=14 3*7=21 4*7=28 5*7=35 6*7=42 7*7=49
1*8= 8 2*8=16 3*8=24 4*8=32 5*8=40 6*8=48 7*8=56 8*8=64
1*9= 9 2*9=18 3*9=27 4*9=36 5*9=45 6*9=54 7*9=63 8*9=72 9*9=812.#输出2~100之间的素数:
i = 2
while (i < 100):j = 2while (j <= (i / j)):if not (i % j): breakj = j + 1if (j > i / j):print(i, " 是素数")i = i + 1
print("Good bye!")
列表
列表:可以存放任何形式的数据(最常用的数据类型之一)
list--->关键字
- 创建列表
三种列表:
1. 普通列表l=[1,2,3]l=['python','java','scala']
2. 混合列表:l=[1,2,3,'hehe']l=[1,2,3,'hhe',[4,5,'hehe']]
3. 空列表l=[]
列表长度:len(1)
- 向列表中添加元素
1. append(object):object:任何对象(万物皆对象)作用:向列表中添加一个元素,并将元素添加到末尾调用形式:list.append(元素)
2. extend(iterable):iterable:可迭代对象作用:将可迭代对象中的元素添加到列表中
3. insert(index,object):index:索引下标objec:要插入的元素- 删除列表元素
1. remove(value):从列表中删除一个元素value:元素注:如果元素不在列表中则会报错抛出异常ValueError
2. pop():弹栈:指的就是把栈顶的元素拿出去删除并返回最后一个元素,如果设置了index则删除并返回index下标处的元素如果列表为空或者下标越界则抛出异常IndexError
3. del:不是一个方法,而是一个语句del 变量名:作用是删除变量,并不会删除列表本身
可以使用 del 语句来删除列表的元素,如下实例:
list1 = ['physics', 'chemistry', 1997, 2000]print list1
del list1[2]
print "After deleting value at index 2 : "
print list1
- 从列表中获取元素
通过下标获取元素:list[index]
访问:1. 读取数据2. 修改数据
遍历:将列表中的元素全部访问一遍,不充分不遗漏list=[1,2,3,4,5,6]
for i in list:print(i)
- 列表的分片
slice:分片/切片
利用索引,获取全部元素
书写方式:list[起始下标 :结束下标]--->[start:end]切片没有下标限制
简写:如果起始下标为0;则可省略 list[:end]如果结束下标为leng-1;则可省略 list[start:]如果全部省略表示整个列表选用 list[:]--->做一些拷贝工作list[起始下标:结束下标:步长]
Python列表截取
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'Taobao' | 读取列表中第三个元素 |
| L[-2] | 'Runoob' | 读取列表中倒数第二个元素 |
| L[1:] | ['Runoob', 'Taobao'] | 从第二个元素开始截取列表 |
Python列表操作符
列表对 + 和 * 的操作符与字符串相似。+ 号用于组合列表,* 号用于重复列表。
如下所示:
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len([1, 2, 3]) | 3 | 长度 |
| [1, 2, 3] + [4, 5, 6] | [1, 2, 3, 4, 5, 6] | 组合 |
| ['Hi!'] * 4 | ['Hi!', 'Hi!', 'Hi!', 'Hi!'] | 重复 |
| 3 in [1, 2, 3] | True | 元素是否存在于列表中 |
| for x in [1, 2, 3]: print x, | 1 2 3 | 迭代 |
- 列表常用运算符
1. 比较运算符布尔运算符:> < >= <= != ==比较每一个元素,从下标为0开始比较,如果相等,则比较下一个元素
2. 逻辑运算符and or not
3. 列表拼接+
4. 重复操作符(运算符)*
5. 成员关系运算符:in /not in
Python列表函数&方法
Python包含以下函数:
| 序号 | 函数 |
|---|---|
| 1 | cmp(list1, list2) 比较两个列表的元素 |
| 2 | len(list) 列表元素个数 |
| 3 | max(list) 返回列表元素最大值 |
| 4 | min(list) 返回列表元素最小值 |
| 5 | list(seq) 将元组转换为列表 |
Python包含以下方法:
| 序号 | 方法 |
|---|---|
| 1 | list.append(obj) 在列表末尾添加新的对象 |
| 2 | list.count(obj) 统计某个元素在列表中出现的次数 |
| 3 | list.extend(seq) 在列表末尾一次性追加另一个序列中的多个值(用新列表扩展原来的列表) |
| 4 | list.index(obj) 从列表中找出某个值第一个匹配项的索引位置 |
| 5 | list.insert(index, obj) 将对象插入列表 |
| 6 | [list.pop(index=-1]) 移除列表中的一个元素(默认最后一个元素),并且返回该元素的值 |
| 7 | list.remove(obj) 移除列表中某个值的第一个匹配项 |
| 8 | list.reverse() 反向列表中元素 |
| 9 | list.sort(cmp=None, key=None, reverse=False) 对原列表进行排序 |
- 列表的浅拷贝
copy()
list切片也是浅拷贝
- 二位列表
一维列表中的一维列表,和Java一样
- 排序
#冒泡排序
list=[5,4,3,9,2,8,6,7,1]
n=len(list)
for i in range(1,n):for j in range(n-i):if list[j]>list[j+1]:#list[j]^=list[j+1]#list[j+1]^=list[j]#list[j]^=list[j+1]list[j],list[j+1]=list[j+1],list[j]
print(list)#选择排序
list=[5,4,3,9,2,8,6,7,1]
n=len(list)
for i in range(0,n-1):for j in range(i+1,n):if list[i]>list[j]:#list[i]^=list[j]#list[j]^=list[i]#list[i]^=list[j]list[j],list[i]=list[i],list[j]
print(list)#两个变量的数据进行交换:在Java里有中间变量、异或运算、加发运算在Python里除了Java优的方法之外还可以写成:a,b=b,a的形式
a=1
b=2
a,b=b,a
交换之后a=2,b=1
元组
- 圆括号(括号运算符)
作用:
1. 控制优先级括号的优先级最高,可以控制优先级
2. 可以作为元组的组成部分
- 元组
tuple列表:可以存放任何数据,可以修改元组:可以存放任何数据,不能修改元组:不可变类型 元组最重要的符号是逗号
- 创建并访问一个元组
1. 直接访问t=(元素1,元素2)--->创建多个元素的元组t=元素1,元素2 --->创建多个元素的元组t=元素 --->创建一个元素的元组t=(元素,) --->创建一个元素的元组
2. tuple()工厂函数创建tuple()--->返回空元组tuple(可迭代对象)--->新元组(元素是可迭代对象中的元素)
3. 访问一个元组通过下标访问(和列表是一样的)
4. 元组的切片t[1:5]
5. 不可以修改直接修改会报错:TypeError可以利用元组的拼接修改
6. 删除元组del 变量--->删除的是变量--->元组本身还在
7. 更新一个元组第一步:利用切片和拼接操作创建新元组第二步:改名
8. 空元组t=()t=tuple()
元组操作符
与字符串一样,元组之间可以使用 + 号和 * 号进行运算。这就意味着他们可以组合和复制,运算后会生成一个新的元组。
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| len((1, 2, 3)) | 3 | 计算元素个数 |
| (1, 2, 3) + (4, 5, 6) | (1, 2, 3, 4, 5, 6) | 连接 |
| ('Hi!',) * 4 | ('Hi!', 'Hi!', 'Hi!', 'Hi!') | 复制 |
| 3 in (1, 2, 3) | True | 元素是否存在 |
| for x in (1, 2, 3): print x, | 1 2 3 | 迭代 |
- 常见操作符
元组索引和截取
因为元组也是一个序列,所以我们可以访问元组中的指定位置的元素,也可以截取索引中的一段元素,如下所示:
元组:
L = ('spam', 'Spam', 'SPAM!')
| Python 表达式 | 结果 | 描述 |
|---|---|---|
| L[2] | 'SPAM!' | 读取第三个元素 |
| L[-2] | 'Spam' | 反向读取,读取倒数第二个元素 |
| L[1:] | ('Spam', 'SPAM!') | 截取元素 |
无关闭分隔符
任意无符号的对象,以逗号隔开,默认为元组,如下实例:
print 'abc', -4.24e93, 18+6.6j, 'xyz'
x, y = 1, 2
print "Value of x , y : ", x,y#运行结果
abc -4.24e+93 (18+6.6j) xyz
Value of x , y : 1 2
元组内置函数
Python元组包含了以下内置函数
| 序号 | 方法及描述 |
|---|---|
| 1 | cmp(tuple1, tuple2) 比较两个元组元素。 |
| 2 | len(tuple) 计算元组元素个数。 |
| 3 | max(tuple) 返回元组中元素最大值。 |
| 4 | min(tuple) 返回元组中元素最小值。 |
| 5 | tuple(seq) 将列表转换为元组。 |
字符串
天生具有跨平台性--os--支持字符串(内因:文本、字母、数字、符号 外因:编码表 a=95)
应用
编辑代码
传输信息
- Python中的字符串
s='abc'
s="abc"
s='''abc''' 可以换行--->默认添加了\n--->多行字符串--->还可以表示文档注释
s="""abc""" 可以换行--->默认添加了\n--->多行字符串--->还可以表示文档注释1. 字符串支持分片操作
2. 字符串时不可变类型--->元组、数字、字符串都是不可变类型列表为可变类型Python字符串转义字符
在需要在字符中使用特殊字符时,python用反斜杠()转义字符。如下表:
| 转义字符 | 描述 |
|---|---|
| (在行尾时) | 续行符 |
| \ | 反斜杠符号 |
| ' | 单引号 |
| " | 双引号 |
| \a | 响铃 |
| \b | 退格(Backspace) |
| \e | 转义 |
| \000 | 空 |
| \n | 换行 |
| \v | 纵向制表符 |
| \t | 横向制表符 |
| \r | 回车 |
| \f | 换页 |
| \oyy | 八进制数,yy代表的字符,例如:\o12代表换行 |
| \xyy | 十六进制数,yy代表的字符,例如:\x0a代表换行 |
| \other | 其它的字符以普通格式输出 |
Python字符串运算符
下表实例变量 a 值为字符串 "Hello",b 变量值为 "Python":
| 操作符 | 描述 | 实例 |
|---|---|---|
| + | 字符串连接 | >>>a + b 'HelloPython' |
| * | 重复输出字符串 | >>>a * 2 'HelloHello' |
| [] | 通过索引获取字符串中字符 | >>>a[1] 'e' |
| [ : ] | 截取字符串中的一部分 | >>>a[1:4] 'ell' |
| in | 成员运算符 - 如果字符串中包含给定的字符返回 True | >>>"H" in a True |
| not in | 成员运算符 - 如果字符串中不包含给定的字符返回 True | >>>"M" not in a True |
| r/R | 原始字符串 - 原始字符串:所有的字符串都是直接按照字面的意思来使用,没有转义特殊或不能打印的字符。 原始字符串除在字符串的第一个引号前加上字母"r"(可以大小写)以外,与普通字符串有着几乎完全相同的语法。 | >>>print r'\n' \n >>> print R'\n' \n |
| % | 格式字符串 | |
| not/or | 逻辑操作符 |
Python 字符串格式化
Python 支持格式化字符串的输出 。尽管这样可能会用到非常复杂的表达式,但最基本的用法是将一个值插入到一个有字符串格式符 %s 的字符串中。
在 Python 中,字符串格式化使用与 C 中 sprintf 函数一样的语法。
如下实例:
print "My name is %s and weight is %d kg!" % ('Zara', 21) #以上实例输出结果:
My name is Zara and weight is 21 kg!
- python字符串格式化符号
| 符 号 | 描述 |
|---|---|
| %c | 格式化字符及其ASCII码 |
| %s | 格式化字符串 |
| %d | 格式化整数 |
| %u | 格式化无符号整型 |
| %o | 格式化无符号八进制数 |
| %x | 格式化无符号十六进制数 |
| %X | 格式化无符号十六进制数(大写) |
| %f | 格式化浮点数字,可指定小数点后的精度 |
| %e | 用科学计数法格式化浮点数 |
| %E | 作用同%e,用科学计数法格式化浮点数 |
| %g | %f和%e的简写 |
| %G | %f 和 %E 的简写 |
| %p | 用十六进制数格式化变量的地址 |
- 格式化操作符辅助指令
| 符号 | 功能 |
|---|---|
| * | 定义宽度或者小数点精度 |
| - | 用做左对齐 |
| + | 在正数前面显示加号( + ) |
| 在正数前面显示空格 | |
| # | 在八进制数前面显示零('0'),在十六进制前面显示'0x'或者'0X'(取决于用的是'x'还是'X') |
| 0 | 显示的数字前面填充'0'而不是默认的空格 |
| % | '%%'输出一个单一的'%' |
| (var) | 映射变量(字典参数) |
| m.n. | m 是显示的最小总宽度,n 是小数点后的位数(如果可用的话) |
Python2.6 开始,新增了一种格式化字符串的函数 str.format(),它增强了字符串格式化的功能。
- 格式化函数
str.format()
字符串格式化:按照一定的格式输出
format():可变长参数 :*args **kwargs
1. 用{}表示字符串参数,花括号中的数字表示位置参数对传递进来的参数进行格式化整理,并展示最终结果s='{[0]呵呵[1]}'.format('hello','world')--->#hello呵呵world
2. 用{}表示字符串参数,花括号中的字母表示关键字参数s='{a}{b}'.format(a='hello',b='world')--->#helloworld注:如果关键字参数和未知参数混用,则位置参数要放在前边
Python的字符串内置函数
字符串方法是从python1.6到2.0慢慢加进来的——它们也被加到了Jython中。
这些方法实现了string模块的大部分方法,如下表所示列出了目前字符串内建支持的方法,所有的方法都包含了对Unicode的支持,有一些甚至是专门用于Unicode的。
| 方法 | 描述 |
|---|---|
| string.capitalize() | 把字符串的第一个字符大写 |
| string.center(width) | 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串 |
| string.count(str, beg=0, end=len(string)) | 返回 str 在 string 里面出现的次数,如果 beg 或者 end 指定则返回指定范围内 str 出现的次数 |
| string.decode(encoding='UTF-8', errors='strict') | 以 encoding 指定的编码格式解码 string,如果出错默认报一个 ValueError 的 异 常 , 除非 errors 指 定 的 是 'ignore' 或 者'replace' |
| string.encode(encoding='UTF-8', errors='strict') | 以 encoding 指定的编码格式编码 string,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' |
| string.endswith(obj, beg=0, end=len(string)) | 检查字符串是否以 obj 结束,如果beg 或者 end 指定则检查指定的范围内是否以 obj 结束,如果是,返回 True,否则返回 False. |
| string.expandtabs(tabsize=8) | 把字符串 string 中的 tab 符号转为空格,tab 符号默认的空格数是 8。 |
| string.find(str, beg=0, end=len(string)) | 检测 str 是否包含在 string 中,如果 beg 和 end 指定范围,则检查是否包含在指定范围内,如果是返回开始的索引值,否则返回-1 |
| string.format() | 格式化字符串 |
| string.index(str, beg=0, end=len(string)) | 跟find()方法一样,只不过如果str不在 string中会报一个异常. |
| string.isalnum() | 如果 string 至少有一个字符并且所有字符都是字母或数字则返回 True,否则返回 False |
| string.isalpha() | 如果 string 至少有一个字符并且所有字符都是字母则返回 True,否则返回 False |
| string.isdecimal() | 如果 string 只包含十进制数字则返回 True 否则返回 False. |
| string.isdigit() | 如果 string 只包含数字则返回 True 否则返回 False. |
| string.islower() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是小写,则返回 True,否则返回 False |
| string.isnumeric() | 如果 string 中只包含数字字符,则返回 True,否则返回 False |
| string.isspace() | 如果 string 中只包含空格,则返回 True,否则返回 False. |
| string.istitle() | 如果 string 是标题化的(见 title())则返回 True,否则返回 False |
| string.isupper() | 如果 string 中包含至少一个区分大小写的字符,并且所有这些(区分大小写的)字符都是大写,则返回 True,否则返回 False |
| string.join(seq) | 以 string 作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串 |
| string.ljust(width) | 返回一个原字符串左对齐,并使用空格填充至长度 width 的新字符串 |
| string.lower() | 转换 string 中所有大写字符为小写. |
| string.lstrip() | 截掉 string 左边的空格 |
| string.maketrans(intab, outtab]) | maketrans() 方法用于创建字符映射的转换表,对于接受两个参数的最简单的调用方式,第一个参数是字符串,表示需要转换的字符,第二个参数也是字符串表示转换的目标。 |
| max(str) | 返回字符串 str 中最大的字母。 |
| min(str) | 返回字符串 str 中最小的字母。 |
| string.partition(str) | 有点像 find()和 split()的结合体,从 str 出现的第一个位置起,把 字 符 串 string 分 成 一 个 3 元 素 的 元 组 (string_pre_str,str,string_post_str),如果 string 中不包含str 则 string_pre_str == string. |
| string.replace(str1, str2, num=string.count(str1)) | 把 string 中的 str1 替换成 str2,如果 num 指定,则替换不超过 num 次. |
| string.rfind(str, beg=0,end=len(string) ) | 类似于 find()函数,不过是从右边开始查找. |
| string.rindex( str, beg=0,end=len(string)) | 类似于 index(),不过是从右边开始. |
| string.rjust(width) | 返回一个原字符串右对齐,并使用空格填充至长度 width 的新字符串 |
| string.rpartition(str) | 类似于 partition()函数,不过是从右边开始查找 |
| string.rstrip() | 删除 string 字符串末尾的空格. |
| string.split(str="", num=string.count(str)) | 以 str 为分隔符切片 string,如果 num 有指定值,则仅分隔 num+ 个子字符串 |
| [string.splitlines(keepends]) | 按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。 |
| string.startswith(obj, beg=0,end=len(string)) | 检查字符串是否是以 obj 开头,是则返回 True,否则返回 False。如果beg 和 end 指定值,则在指定范围内检查. |
| string.strip([obj]) | 在 string 上执行 lstrip()和 rstrip() |
| string.swapcase() | 翻转 string 中的大小写 |
| string.title() | 返回"标题化"的 string,就是说所有单词都是以大写开始,其余字母均为小写(见 istitle()) |
| string.translate(str, del="") | 根据 str 给出的表(包含 256 个字符)转换 string 的字符,要过滤掉的字符放到 del 参数中 |
| string.upper() | 转换 string 中的小写字母为大写 |
| string.zfill(width) | 返回长度为 width 的字符串,原字符串 string 右对齐,前面填充0 |
序列(Sequence)
- 列表、元组、字符串
共同点:1.可迭代对象2.可以通过索引获得相应的元素3.都可以使用分片操作4.有共同的操作符特点:1.可以通过下标操作2.有一一对应的元素序列:列表、元组、字符串
- 序列相关的函数
内置函数:BIF列表、元组、字符串中的内置函数
1. list():list():创建一个空列表list(iterable):创建一个列表
2. tuple():tuple:创建一个元组tuple(iterable):创建元组
3. str(obj=''):将obj转换成字符串
4. len(obj):获取对象obj的长度
5. max(iterable)返回可迭代的对象中最大的元素(数值大,编码大)
6. min(iterable)返回可迭代的对象中最小的元素(数值小,编码小)
7. sum(iterable,start=0)从start开始加起,逐个加迭代对象中的数字
8. sorted()排序(默认升序)
9. reversed():原地翻转返回一个list_reverseiterator对象查看该对象:利用工厂函数进行转换(list(),tuple())利用for循环查看
10. enumerate(iterable[,start]):返回元组序列:(下标,元素)
11. zip(iter1[,iter2[...]])-->):打包
字典(Dictionary)
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值 key=>value 对用冒号 : 分割,每个键值对之间用逗号 , 分割,整个字典包括在花括号 {} 中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }关键字:dict
dict = {'Alice': '2341', 'Beth': '9102', 'Cecil': '3258'}
1. 键一般是唯一的,如果重复最后的一个键值对会替换前面的,值不需要唯一。
2. 值可以取任何数据类型,但键必须是不可变的,如字符串,数字或元组。
3. 字典不是序列--->是映射类型--->是可迭代对象
- 字典的创建
1. 直接创建d = {key1 : value1, key2 : value2 }
2. 利用函数创建1.空字典:dict()2.dict(mapping):参数是一个映射3.dict(*元组):参数是一个可迭代对象
- 字典的访问
读取+修改
1. 读取:字典名[key]
2. 修改:字典名[key]=新值
3. 添加键值对:字典名[key]=value
字典内置函数&方法
Python字典包含了以下内置函数:
| 序号 | 函数及描述 |
|---|---|
| 1 | cmp(dict1, dict2) 比较两个字典元素。 |
| 2 | len(dict) 计算字典元素个数,即键的总数。 |
| 3 | str(dict) 输出字典可打印的字符串表示。 |
| 4 | type(variable) 返回输入的变量类型,如果变量是字典就返回字典类型。 |
Python字典包含了以下内置方法:
| 序号 | 函数及描述 |
|---|---|
| 1 | dict.clear() 删除字典内所有元素 |
| 2 | dict.copy() 返回一个字典的浅复制 |
| 3 | [dict.fromkeys(seq, val]) 创建一个新字典,以序列 seq 中元素做字典的键,val 为字典所有键对应的初始值 |
| 4 | dict.get(key, default=None) 返回指定键的值,如果值不在字典中返回default值 |
| 5 | dict.has_key(key) 如果键在字典dict里返回true,否则返回false |
| 6 | dict.items() 以列表返回可遍历的(键, 值) 元组数组 |
| 7 | dict.keys() 以列表返回一个字典所有的键 |
| 8 | dict.setdefault(key, default=None) 和get()类似, 但如果键不存在于字典中,将会添加键并将值设为default |
| 9 | dict.update(dict2) 把字典dict2的键/值对更新到dict里 |
| 10 | dict.values() 以列表返回字典中的所有值 |
| 11 | [pop(key,default]) 删除字典给定键 key 所对应的值,返回值为被删除的值。key值必须给出。 否则,返回default值。(弹栈) |
| 12 | popitem() 随机返回并删除字典中的一对键和值。弹出键值对 |
函数
- 结果化编程
关键字:def
函数的创建:def 函数名 (形参列表):逻辑代码
函数的调用:函数名(实参列表)
- 函数的特点、运行机制同Java和Scala中的函数一样
1. 避免代码冗余
2. 提高程序的灵活性
3. 提高程序的可维护性
4. 提高代码的重用性
- 函数的定义位置
1. 可以定义在文件顶头
2. 函数可以定义在函数内部参考变量定义函数作用范围:从定义开始到包含它的代码块结束---作为脚本运行
- 函数的结构
1. 函数的声明(定义)def 函数名(参数列表):多个参数用逗号分开,参数个数无限制
2. 函数的内容:代码 没有内容:pass
3. 函数的返回值关键字:return ---如果不写系统自动添加--任何函数一定有返回值函数的参数
- 位置参数
#和java一样严格按照参数的位置进行调用和数据传递
def fun(a,b):内容fun(a,b)
- 关键字参数
定义了关键字的参数,与位置无关
def fun(a,b):print(a,b)fun(b='B',a='A')
1. 利用关键字参数传递与位置无关
2. 位置参数必须在关键字参数前面。(系统为会认为从关键字参数开始后面的参数均为关键字参数)
3. 关键字参数不能多次赋值
- 默认参数
是定义了默认值的参数
#默认参数
def fun(a='A',b='B'):print(a,b)fun('C','D')
- 可变长参数
收集参数
1. 在参数前面加*将所有的参数打包成元组,输出--->不能使用关键字参数
2. 在参数前面加**将所有参数打包成字典。输出--->只能使用关键字参数传递
- 命名关键字参数
*后面定义的形式
def fun(*param,a):print(a)
fun('A','B',a='C')
1. 可变长参数和位置参数共用如果位置参数在后,则实参在指定为位置使用关键字参数如果位置参数在前,直接传参不能使用关键字参数
- 函数的文档
文档的读取
1. help()
2. 函数名._doc_
函数与过程
1. 函数:函数的声明,函数的返回值
2. 过程:函数的实现(内容)函数与过程是相互分离的
返回值
python的返回值是动态的,编译器动态的确定具体类型1. return 语句后面一定要有一个参数
2. 函数如果没有书写return则系统会自动的增加一个return None
3. 函数如果没有书写return后面的值,则系统会自动的增加一个None
4. return可以返回多个返回值,多个数据之间用逗号分隔开,本质上封装成了元组
5. return可以返回一个容器类型的数据(容器中可以装多个数据)
6. return后面可以书写一个表达式,函数的调用,返回一个值
- 函数变量的作用域
局部变量、全局变量、作用范围和java里面一样使用
- global
全局变量有关
#可以在函数内部访问全局变量
a=10
def fun():global aa=20print(a)fun()
print(a)
#20 20
- nonlocal
局部变量有关
#可以在内部函数的内部访问外部函数的局部变量
def fun():a=10def fun1():nonlocal aa = 20print(a)fun1()print(a)
fun()
注意:函数不能对全局变量进行增强赋值运算(a=a+1 a+=1)内部函数不能对外部函数的局部变量进行增强运算(a=a+1 a+=1)解决方案:可以利用gloabl和nonlocal声明一下
lambda表达式与匿名函数
匿名函数
python 使用 lambda 来创建匿名函数。
- lambda只是一个表达式,函数体比def简单很多。
- lambda的主体是一个表达式,而不是一个代码块。仅仅能在lambda表达式中封装有限的逻辑进去。
- lambda函数拥有自己的命名空间,且不能访问自有参数列表之外或全局命名空间里的参数。
- 虽然lambda函数看起来只能写一行,却不等同于C或C++的内联函数,后者的目的是调用小函数时不占用栈内存从而增加运行效率。
- 语法
lambda函数的语法只包含一个语句,如下:
语法:lambda [arg1 [,arg2,.....argn]]:expression:左边是参数 :右边式返回值
如下实例:
# 可写函数说明
sum = lambda arg1, arg2: arg1 + arg2;
# 调用sum函数
print "相加后的值为 : ", sum( 10, 20 )
print "相加后的值为 : ", sum( 20, 20 )#以上实例输出结果:
相加后的值为 : 30
相加后的值为 : 40
#普通函数
def fun(x):return 2*x+1
print(fun(5))#lambda表达式改写
a=lambda x:2*x+1
print(a(5))
注意
1.使用场景:只是用一次之后就不用的这种函数就可以用lambda表达式取创建。
2.lambda表达式的运行效率较普通函数更低。
3.lambda表达式的优先级最低。
补充点:(闭包的延时绑定python深层次的知识点)**
概念:1.闭包:函数式编程中的重要语法结构,函数式编程是一种编程范式2.编程范式:对代码进行提炼和抽象的概括,使得代码的重用性更高
# 如果在一个内部函数里面对外部函数的局部变量进行引用,外部函数以内部函数名调用,则这个内部函数就是一个闭包
条件:1.只要内部函数使用了外部函数的局部变量2.如果外层函数返回值为内层函数对象
作用:1.可以在声明较少参数情况下,传递更多的参数2.可以使用内部的函数3.多应用于集群
def fun1():a=10def fun2(x):return a+xreturn fun2
print(fun1()(10))
#结果为:20
Python中的作用域泄露
for i in range(3): # i局部变量--->作用域泄露--->危险a=i*2 # i最终将变成2
print(a) # 4
闭包的延时绑定
def fun():return [lambda x:i*x for i in range(4)] #此处i相对于该函数来说是全局变量
print([m(2) for m in fun()])#结果
[6, 6, 6, 6]
'''
Python 中文档说明:如果i 被赋值(执行for循环),那么可以在for循环之外分享变量如果i并没有被赋值,那么则访问不到
'''#等价于
def fun():list=[]for i in range(4):def lam(x):return x*ilist.append(lam)return list
print([m(2) for m in fun()])- 闭包的延时绑定问题的解决办法
def fun():return [lambda x,n=i:x*n for i in range(4)]
print([m(2) for m in fun()])def fun():list=[]for i in range(4):def lam(x,n=i):return x*nlist.append(lam)return list
print([m(2) for m in fun()])
#只需要取每一次遍历的i即可,不要取最终的i
Python中的高级函数
- filter()
filter(function or None,iterable)
参数一:是一个函数或者None
参数二:是一个可迭代对象如果第一个参数为函数,则将第二个参数中的每一个元素作为参数传递给第一个函数参数注意:1.如果第一个参数为None,则返回第二参数(可迭代对象)中的非False(0,False,所有的空值)2.第一个参数的返回值--->只返回True或者False--->布尔函数
def fun(x):return x%2
print(list(filter(fun,[1,2,3,4,5,6,7,8,9,10])))
#结果为:[1, 3, 5, 7, 9]def fun1(x):if x%2==0:return Trueelse:return False
print(list(filter(fun1,[1,2,3,4,5,6,7,8,9,10])))
#结果为:[2, 4, 6, 8, 10]# filter()函数要做的事情就是把所有为False的去除
- map()
map(func,*iterable)参数一:函数参数二:多个可迭代对象
1. 将每一个参数的元素进行运算,直到每个元素都进行运算完毕,将运算后的整体构建成新的序列
def fun(x):return x*2
print(list(map(fun,[1,2,3,4,5])))#结果为:[2, 4, 6, 8, 10]
改成lambda形式
print(list(map(lambda x:x*2,[1,2,3,4,5])))
- reduce()
Python3:functiontools.reduce() #需要引入该模块
1. reduce(function(),sequence[,initial])对序列中的一对元素进行计算,这个计算结果将和第三个元素继续进行计算,以此类推。第一个参数:函数第二个参数:序列第三个参数:初始值,如果给了初始值则先计算初始值
#没有初始值情况:
import functools
def fun(x,y):return x+y
print(functools.reduce(fun,[1,2,3,4,5,6]))# 结果为:21#有初始值情况
import functools
def fun(x,y):return x+y
print(functools.reduce(fun,[1,2,3,4,5,6],10))# 结果为:31
函数嵌套和递归
函数嵌套:在一个函数里面调用另一个函数
执行流程和java一样的
- 一元二次方程
$ax^2+bx+c=0$
$x=\frac{-b\pm\sqrt{b^2-4ac}}{2a}$
# 解一元二次方程
def fun(a, b, c):# 判断是否有解delta = b ** 2 - 4 * a * cif existSolution(a, b, c):x1 = (-b + delta ** 0.5) / 2 * ax2 = (-b + delta ** 0.5) / 2 * aprint('方程有解,x1=%s x2=%s' %(x1,x2))else:print("方程无解")# 判断是否有解,有解返回True无解返回False
def existSolution(a, b, c):delta = b ** 2 - 4 * a * cif delta >= 0:return Trueelse:return False#调用
fun(1,0,-4)#结果:方程有解,x1=2.0 x2=2.0
- 递归
和Java一样,递归是一种特殊的函数嵌套调用,自己调用自己避免无穷递归--->要加收敛条件
def fact(n):if n == 1:return 1else:ret = n * fact(n - 1)return ret
n = int(input("请输入一个数:"))
print('%s 的阶乘为%s' %(n,fact(n)))#结果为:请输入一个数:55 的阶乘为120
- 斐波那契数列
#斐波那契额数列
def feibo(n):a=1b=1for i in range(1,n+1):if i<3:print(1,end=' ')else:a,b=b,a+bprint(b,end=' ')
feibo(12)#结果为:1 1 2 3 5 8 13 21 34 55 89 144 #用递归实现
def feibo(n):if n<3:return 1else:return feibo(n-1)+feibo(n-2)
for i in range(1,13):print(feibo(i),end=' ')
#结果为:1 1 2 3 5 8 13 21 34 55 89 144
- 汉诺塔问题
递归中的经典问题
#a,b,c柱子名称(从a将n个盘子挪到b,借助c);n表示共有几个盘子
def hannoi(a,b,c,n):if n==1:print('%s --->%s'%(a,b))returnhannoi(a,c,b,n-1)print('%s ---> %s' %(a,b))hannoi(c,b,a,n-1)hannoi('A','B','C',3)#结果为:
A --->B
A ---> C
B --->C
A ---> B
C --->A
C ---> B
A --->B
Python 内置函数
| 内置函数 | ||||
|---|---|---|---|---|
| abs() | divmod() | input() | open() | staticmethod() |
| all() | enumerate() | int() | ord() | str() |
| any() | eval() | isinstance() | pow() | sum() |
| basestring() | execfile() | issubclass() | print() | super() |
| bin() | file() | iter() | property() | tuple() |
| bool() | filter() | len() | range() | type() |
| bytearray() | float() | list() | raw_input() | unichr() |
| callable() | format() | locals() | reduce() | unicode() |
| chr() | frozenset() | long() | reload() | vars() |
| classmethod() | getattr() | map() | repr() | xrange() |
| cmp() | globals() | max() | reverse() | zip() |
| compile() | hasattr() | memoryview() | round() | import() |
| complex() | hash() | min() | set() | |
| delattr() | help() | next() | setattr() | |
| dict() | hex() | object() | slice() | |
| dir() | id() | oct() | sorted() | exec 内置表达式 |
__init__ : 构造函数,在生成对象时调用
__new__ :创建对象
__del__ : 析构函数,释放对象时使用,析构器/垃圾回收器
__repr__ : 打印,转换
__setitem__ : 按照索引赋值
__getitem__: 按照索引获取值
__len__: 获得长度
__cmp__: 比较运算
__call__: 函数调用
__add__: 加运算
__sub__: 减运算
__mul__: 乘运算
__truediv__: 除运算
__mod__: 求余运算
__pow__: 乘方
集合
1. 集合中的元素是无序的、唯一的字典的key是集合实现的 所以是无序的唯一的不重复的
- 集合的创建
集合(set)是一个无序的不重复元素序列。 可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
1. 直接创建
2. 使用set()工厂函数:set():返回一个空集合对象--->没有空集合set(iterable):去重转集合
- 集合的访问
# 其他访问的函数下表总结
1. 遍历:利用for循环进行遍历
2. 成员运算符:in 包含 not in 不包含
3. 比较运算符:参考数学中集合的比较概念:比大小是比包含关系的不是拿元素内容比的
- 并集、交集、差集
和数学中的概念是一样的
1. 交集:&
2. 并集:or python2中支持+
3. 差集:-
- 不可变集合
关键字:frozenset a=frozenset([1,2,3])
返回一个frozenset对象
- enumerate
enumerate(iterable[,start])返回一个enumerate对象,该对象封装可迭代对象的元素和下标--->封装成了(index,value)形式list=[1,2,3,4,5]
for i in enumerate(list):print(i)#结果为:(0, 1)(1, 2)(2, 3)(3, 4)(4, 5)
集合内置方法
| 方法 | 描述 |
|---|---|
| add() | 为集合添加元素,如果该元素存在则不添加 |
| clear() | 移除集合中的所有元素 |
| copy() | 拷贝一个集合 |
| difference() | 返回多个集合的差集 |
| difference_update() | 移除集合中的元素,该元素在指定的集合也存在。 |
| discard() | 删除集合中指定的元素 |
| intersection() | 返回集合的交集 |
| intersection_update() | 删除集合中的元素,该元素在指定的集合中不存在。 |
| isdisjoint() | 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。 |
| issubset() | 判断指定集合是否为该方法参数集合的子集。 |
| issuperset() | 判断该方法的参数集合是否为指定集合的子集 |
| pop() | 随机移除元素 |
| remove() | 移除指定元素 |
| symmetric_difference() | 返回两个集合中不重复的元素集合。 |
| symmetric_difference_update() | 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。 |
| union() | 返回两个集合的并集 |
| update() | 给集合添加元素 |
面向对象
面向对象的几个概念
1. 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
2. 方法:类中定义的函数。
3. 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
4. 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
5. 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
6. 局部变量:定义在方法中的变量,只作用于当前实例的类。
7. 实例变量:在类的声明中,属性是用变量来表示的。这种变量就称为实例变量,是在类声明的内部但是在类的其他成员方法之外声明的。
8. 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
9. 实例化:创建一个类的实例,类的具体对象。
10. 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
- 类的定义
#定义类
class Student:name='lijb'age=18sex=True#定义方法def learn(self,name):print('Students %s are learning...' %(name))#创建对象
s=Student()
#调用对象的属性
print(s.name)
#调用对象的方法
s.learn('luanp')
- 属性
1. 属性的分类(变量)示例属性:在方法内部定义,定义方式(self.属性名=属性值)类属性:在类的内部,方法的外部定义
2. 访问形式:对象.属性名
3. 类属性创建:直接定义,需要默认值访问形似:对象.属性名
4. 实例属性:创建:通过self.属性名优势:直接使用属性而不用定义,该定义形式可以避免创建时必须赋值的情况在类的内部访问:self.属性名利用对象去访问:对象名.属性名
- 实例属性和类属性的区分
实例属性:每个实例各自拥有,互不影响
类属性:全类所有
- 方法
1. 方法:声明+实现
2. self(指当前对象)方法可以多个参数,用逗号隔开self:在调用时,自动传递,不需要手动传递
3. 方法:只能在创建对象之后调用,放法绑定到对象(实例)上
- 构造方法
1. __init__(self):在创建对象时默认调用1次,可以手工调用但是不需要手工调用
2. __init__(self,param1,param2,...):构造方法可以有多个参数,用逗号隔开
3. 如果一个类中没有任何构造方法,默认调用的是父类的构造方法
4. 一个类中可以定义多个构造方法,但是只会执行最后一个构造方法(后面的构造方法将前面的覆盖)
5. 构造方法的返回值为None
- 创建对象
1. 创建对象变量名=类名(构造参数)d=Dog()Dog()这种没有引用的对象会被标记为垃圾,垃圾回收机制
2. 创建的对象统称为实例--instance和实例相关的属性:实例属性---绑定属性和实例相关的方法:实例方法---绑定方法
- 组合
一个类的属性是另一个对象称之为组合
注意:1.如果实例属性和方法发生命名冲突,则方法无法调用2.如果类属性和方法发生命名冲突,则类属性无法被调用(调用时显示为同名方法的地址)
- 公有和私有问题
成员私有化
1. 私有化:name mangling---名字重造
2. 在成员名前加__两个下划线
3. 私有成员 不能在类之外被访问,只能在本类重访问成员私有化后要提供对应的get/set方法
4. python的私有化为伪私有化将成员名修改为:_类名_成员名
1. 类的私有属性
__private_attrs:两个下划线开头,声明该属性为私有,不能在类的外部被使用或直接访问。在类内部的方法中使用时 self.__private_attrs。
类的方法
在类的内部,使用 def 关键字来定义一个方法,与一般函数定义不同,类方法必须包含参数 self,且为第一个参数,self 代表的是类的实例。self 的名字并不是规定死的,也可以使用 this,但是最好还是按照约定是用 self。
2. 类的私有方法
__private_method:两个下划线开头,声明该方法为私有方法,只能在类的内部调用 ,不能在类的外部调用。self.__private_methods。
封装
和Java一样,数据隐藏,属性私有化
继承
定义形式:class 子类类名(父类类名):#父类类名不写默认为object
继承特点:
1. 子类可以继承父类的方法和属性
2. 可扩展性
3. 父类中的私有成员不能被继承(不能直接访问)
4. 子类中没有构造方放时默认调用父类的构造方法
子类调用父类的构造方法:A.父类名.__init__(self): ---在子类内部调用B.父类名.__init__(当前对象):---在子类外部调用C.super().__init__(): ---利用super()函数---不用传self参数因为系统自动给super传了
5. 子类有构造方法时调用自己的构造方法其特点和Java一样
单继承
class DerivedClassName(BaseClassName1):...
需要注意圆括号中基类的顺序,若是基类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找基类中是否包含方法。
BaseClassName(示例中的基类名)必须与派生类定义在一个作用域内。除了类,还可以用表达式,基类定义在另一个模块中时这一点非常有用:
#类定义
class people:#定义基本属性name = ''age = 0#定义私有属性,私有属性在类外部无法直接进行访问__weight = 0#定义构造方法def __init__(self,n,a,w):self.name = nself.age = aself.__weight = wdef speak(self):print("%s 说: 我 %d 岁。" %(self.name,self.age))#单继承示例
class student(people):grade = ''def __init__(self,n,a,w,g):#调用父类的构函people.__init__(self,n,a,w)self.grade = g#覆写父类的方法def speak(self):print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))s = student('ken',10,60,3)
s.speak()
多继承
class DerivedClassName(Base1, Base2, Base3):...
需要注意圆括号中父类的顺序,若是父类中有相同的方法名,而在子类使用时未指定,python从左至右搜索 即方法在子类中未找到时,从左到右查找父类中是否包含方法。
特点:多继承要不断的创建父类对象占内存浪费资源
#类定义
class people:#定义基本属性name = ''age = 0#定义私有属性,私有属性在类外部无法直接进行访问__weight = 0#定义构造方法def __init__(self,n,a,w):self.name = nself.age = aself.__weight = wdef speak(self):print("%s 说: 我 %d 岁。" %(self.name,self.age))#单继承示例
class student(people):grade = ''def __init__(self,n,a,w,g):#调用父类的构函people.__init__(self,n,a,w)self.grade = g#覆写父类的方法def speak(self):print("%s 说: 我 %d 岁了,我在读 %d 年级"%(self.name,self.age,self.grade))#另一个类,多重继承之前的准备
class speaker():topic = ''name = ''def __init__(self,n,t):self.name = nself.topic = tdef speak(self):print("我叫 %s,我是一个演说家,我演讲的主题是 %s"%(self.name,self.topic))#多重继承
class sample(speaker,student):a =''def __init__(self,n,a,w,g,t):student.__init__(self,n,a,w,g)speaker.__init__(self,n,t)test = sample("Tim",25,80,4,"Python")
test.speak() #方法名同,默认调用的是在括号中排前地父类的方法
Python中的继承时多继承---钻石继承问题--多继承要不断的创建父类对象占内存浪费资源--解决办法为:super()
super()底层是mro内核(继承链关系)实现的
方法重写
如果父类方法的功能不能满足你的需求,你可以在子类重写你父类的方法,实例如下:
class Parent: # 定义父类def myMethod(self):print ('调用父类方法')class Child(Parent): # 定义子类def myMethod(self):print ('调用子类方法')c = Child() # 子类实例
c.myMethod() # 子类调用重写方法
super(Child,c).myMethod() #用子类对象调用父类已被覆盖的方法
执行以上程序输出结果为:
调用子类方法
调用父类方法
多态
多态
多态指一类事物具有多种形态(继承关系)
序列:列表、元组、字符串
动物:猫、狗。。。
多态性
是指不同功能的函数,可以使用同一个函数名,可以使用同一个函数名调用不同的内容
向不同的对象发送同一条消息,不同的对象在接受时会产生不同的形式为。
函数
- issubclass()
issubclass(cls,class_or_tuple):
1. 如果cls类是class类的子类返回True,相同也返回True,不是则返回False
2. 如果cls是tuple元素的子类则返回True
- isinstance()
isinstance(obj,class_or_tuple):
1. 如果obj是class的实例对象则返回True
2. 如果obj继承了class则返回True
3. 如果obj是tuple中的元素实例则返回True
- hasattr()
hasattr(obj,name,/):判断obj对象中是否有name这个属性---name是str
- getattr()
getattr(object,name[,default]):
1. 从object中获取一个属性值---name
2. 如果name不存在则返回default中的信息
3. 如果default没有定义则抛出异常
- setattr()
setattr(obj,name,value):设置obj中的name属性值为value
- delattr()
delattr(object,name):删除object中name属性
- property()
property(fget=None,fset=None,fdel=None,doc=None):
1. 通过属性设置属性
2. 将属性和另一个属性做关联,修改一个属性,则另一个属性也随之更改
3. fget,fset,fdel分别代表关联属性的get,set,del
4. 方法的返回值用于关联另一个属性
修饰器(修饰符)
作用:可以为已经存在的代码增加额外功能
修饰器:Decorator:
关键字:@
1. 修饰器只能出现在函数定义的前一行,不允许和函数定义在同一行
2. 只能在模块或类中定义,并且不能修饰类,只能是对函数或方法进行修饰
3. 装饰器本身是一个函数,是将被修饰的函数当作参数传递给装饰器,返回的是修饰之后的函数
- 基本定义形式
#基本定义形式
class B:#定义修饰器def A(fun):print("修饰器")return fun #返回一个函数#修饰器修饰方法[@A](https://my.oschina.net/a8856225a)def m1(self):print('运行m1()')
#创建对象并调用方法
b=B()
b.m1()
#结果:修饰器运行m1()
- 利用内嵌函数
#利用内嵌函数
def funA(f):def funB():print("inner function B")funB()return f@funA
def funC():print('function C')funC()
#结果:inner function Bfunction C
- 利用闭包
#利用闭包
def funD(f):def funE():print('inner function E')f()return Nonereturn funE[@funD](https://my.oschina.net/u/3954936)
def funF():print('function F')return None
funF()
#结果:inner function Efunction F
- 利用类
#利用类
class G:def __init__(self,f):self.f=fdef __call__(self):print('class G')return self.f()[@G](https://my.oschina.net/godzilar)
def funH():print('function H')return NonefunH()
#结果:class Gfunction H
- 使用案例
计算程序运行的时间
#计算程序运行的时间
import time
def timelong(f):start=time.clock()print('time start')f()end=time.clock()print('time end')print('程序运行的时间为:%s s'%(end-start))return lambda :None@timelong
def sum1():ret=0for i in range(100):ret +=iprint('计算的结果为:%s'%(ret))sum1()
#结果:time start计算的结果为:4950time end程序运行的时间为:4.758972406575423e-05 s
Python中内置的装饰器
1. classmethond:修饰类方法
2. property
3. staticmethond:静态方法(和函数的使用完全一样)
专题
专题1:Python中的赋值
| 运算 | 解释 |
|---|---|
| a='hehe' | 基本形式 |
| a,b=1,2 | 元组赋值(位置性) |
| [a,b]=[1,2] | 列表赋值(位置性) |
| a,b,c,d='spark' | 序列赋值(通用性) |
| a,b,c=[1,2,3] | 序列赋值(通用性) |
| a,*b='spark' | 扩展的序列解包(Python3独有的) |
| a=b=c=d='spark' | 多目标赋值 |
| a+=1 | 增强赋值:相当于a=a+1 |
- 高级序列赋值
- 高级序列赋值--->赋值嵌套序列
s='spark'
(a,b),c=s[:2],s[2:]
print((a,b),c)#结果:
('s', 'p') ark
- 高级序列赋值--->利用range()函数
a,b,c=range(3)
print(a,b,c)
- 利用切片进行序列的分割
list=[1,2,3,4]
while list:front,list=list[0],list[1:]print(front,list)
#结果如下:
1 [2, 3, 4]
2 [3, 4]
3 [4]
4 []
- Python3中扩展的序列解包
- a,*b a匹配第一个元素元素 b匹配剩余的元素
a,*b=[1,2,3,4]
print(a,b)
#结果:
(1,[2,3,4])
- *a,b b匹配最后一项 a匹配前面的剩余项
*a,b=[1,2,3,4]
print(a,b)
#结果:
([1,2,3],4)
- a,*b,c a匹配第一项 b匹配中间项目 c匹配最后一项
a,*b,c=[1,2,3,4]
print(a,b,c)
#结果:
(1,[2,3],4)
- 序列分割
list=[1,2,3,4]
while list:front,*list=listprint(front,list)
#结果如下:
1 [2, 3, 4]
2 [3, 4]
3 [4]
4 []

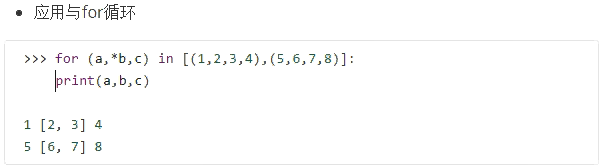
专题2:可迭代对象
字符串、列表、元组、集合、字典
- 容器
容器是一种把多个元素组织在一起的数据结构,容器中的元素可以逐个的迭代获取
特点:可以通过in/not in 成员关系操作符 检测元素是否在容器之内
常见的容器类型:list/str/tuple/set/dict/frozenset



专题3:Python中的推导式
列表推导式
字典推导式
集合推导式推导式可以从一个数据序列构建另一个数据序列
- 列表推导式
推导式--->解析式
1. 格式:变量名=[表达式 for 变量 in 可迭代对象 if 布尔表达式]if可以省略
2. 案例:s=[i for i in range(10)]print(s)#结果为:[0, 1, 2, 3, 4, 5, 6, 7, 8, 9
- 字典推导式
1. 格式变量={键:值 for 变量 in 可迭代对象 if 表达式}2. 案例:d={k:v for k,v in [('one',1),('two',2),('three',3)] if k!='one'}print(d)#结果为:{'two': 2, 'three': 3}
#大小写合并 将字典s转成不区分大小写的新字典输出,避免覆盖key相同时value相加
s={'a':10,'b':20,'A':100,'B':200}
d={k.lower():s[k.lower()]+s[k.upper()]for k in s}
print(d)#结果为:{'a': 110, 'b': 220}
- 集合推导式
1. 格式:变量={表达式 for 变量 in 可迭代对象 if 布尔表达式}
2. 案例:s={i for i in range(10)}print(s)#结果为:{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
注:推导式中表达式可以完全换成函数,该函数只使用一次故可以换成lambda表达式写成匿名函数
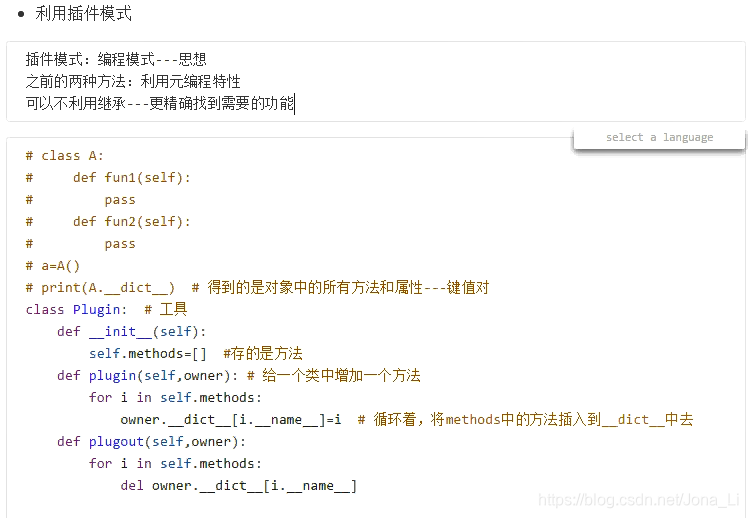
专题4:MinxIn编程
MinxIn是一种开发模式,是将多个类中的功能进行组合的使用方法
1. 利用多继承,不关注继承只关注功能
2. 利用__bases__
3. 利用插件模式



专题5:鸭子类型
1. 在程序设计中,鸭子类型(duck typing)是一种动态类型的风格
2. Python是一门动态类型的语言
3. **在鸭子类型中,关注的不是对象类型本身,而是关注其如何使用**
4. 实际上鸭子类型就是多态性的一种体现
5. 在Python文档中,使用鸭子类型时尽量避免使用isinstance(),type()这样的方法去判断类型,因为这样会限制鸭子类型的使用灵活性所有的控制由程序员控制--->可能会出错专题6:池化
1. 池化有助于减少对象数量和内存的消耗,提高性能
2. 池化是一种预分配机制线程池,请求池、连接池。。。和Java是一样的
专题7:魔法方法
在Python中被两条下划线包围的方法或属性称之为魔法方法,如:__init__()等。
对象的创建和消亡相关
- _init_
1. __init__(self,[...])构造方法---初始化方法初始化实例属性时进行调用本质时覆盖了object中的__init__
2. 有返回值,返回值必须是None
- _new_
1. __new__(cls,[...])创建对象的时候自动的被调用,只调用一次,但是__init__不是第一次被调用的魔法方法,第一次被调用的是__new__cls:class---类new的参数传递给了init
2. 一般不修改new方法

- _del_
1. __del__(self):init--构造方法del---析构方法析构器:垃圾回收器finalizer:当一个对象在消亡时,由编译器自动调用析构函数:destructor 和构造函数相反---当对象脱离作用区域时,则自动调用析构函数del 变量名---删除的是引用---和__del__不一样
算术相关魔法方法




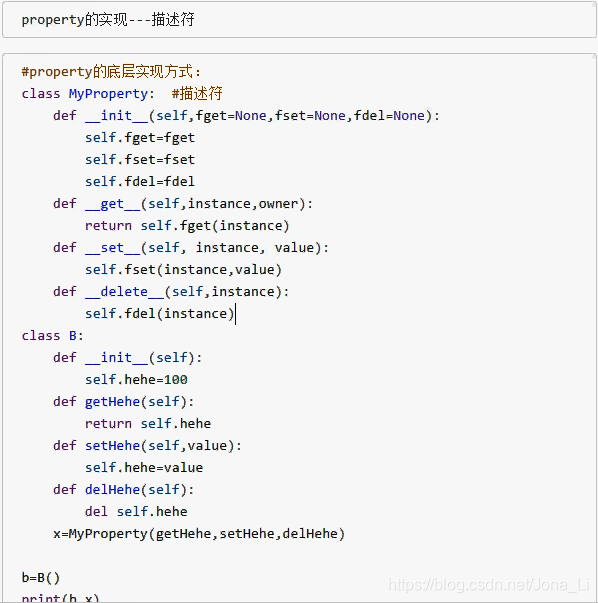
- property的实现--描述符
定制容器
1. 协议:protocols协议和接口很相似:规定了哪些方法必须定义的---指南
2. Python中的协议:一种思想鸭子类型--动车类型风格
3. 容器类型:列表,字典。元组,集合。字符串,不可编集合
- 定制容器的协议
1. 如果定制容器不可变:__len__()__getitem__()
2. 如果定制可变容器__len__()__getitem__()__setitem__()__delitem__()
#编写一个不可变的列表,要求记录列表中每一个元素被访问的次数
class MyList:def __init__(self,*args):self.value=[x for x in args] #用来存储传进来的值#创建字典记录被访问次数--元素1:次数1 元素2:次数2 元素3:次数3self.counts={k:0 for k in self.value}def __len__(self):return len(self.value)def __getitem__(self, item): #item是被访问元素的下标temp=self.value[item]self.counts[temp]+=1return self.counts[temp]m1=MyList(1,2,3,4,5)
m1[0]
m1[0]
m1[1]
print(m1.counts)
迭代器
迭代:每一次重复的过程,每一次迭代的结果作为下一次迭代的初始值
迭代器:存放迭代方法的容器,但凡是实现了__iter__()和__next__()的都是迭代器关于迭代操作:
1. iter():对一个容器调用iter()方法,返回该对象的迭代器
2. next():迭代器调用next()方法,则返回下一个值,如果迭代器没有下一个值,则抛出异常:StopIteration Error包含的魔法方法
1. __iter__()返回一个迭代对象,一般不会进行修改,直接返回当前对象(self)
2. __next__()next()方法底层调用的是__next__()--核心:迭代规则# 综上所述:一个对象实现了__iter__()和__next__()方法之后本身就是一个迭代器
- 练习
斐波那契数列
#斐波那契数列 函数写法
def feibo(n):a=1b=1for i in range(1,n+1):if i<3:print(1,end=' ')else:a,b=b,a+bprint(b,end=' ')
feibo(12)def feibo(n):if n<3:return 1else:return feibo(n-1)+feibo(n-2)
for i in range(1,13):print(feibo(i),end=' ')
#---------------------------------------------------------------------------------------
# 利用迭代器中包含的魔法方法实现
class Fibo:#写一个初始方法,给两个初始值def __init__(self):self.a,self.b=0,1#实现__iter__() and __next__()def __iter__(self):return selfdef __next__(self):#核心---决定迭代规则self.a,self.b=self.b,self.a+self.breturn self.afibo=Fibo()
for i in fibo:if i > 100:breakelse:print(i,end=' ')
- 总结


模块
1. 模块的概念:将代码量较大的程序分割成多个组织,彼此独立,且能相互调用的代码片段,这些文件称之为模块。
2. 模块在物理形式上以.py结尾的代码文件(源文件)
3. Python允许导入其他模块以实现代码重用,从而实现了将独立的代码文件组织成更大的程序系统
import 语句
想使用 Python 源文件,只需在另一个源文件里执行 import 语句,语法如下:
import module1[, module2[,... moduleN]
当解释器遇到 import 语句,如果模块在当前的搜索路径就会被导入。
搜索路径是一个解释器会先进行搜索的所有目录的列表。如想要导入模块 support,需要把命令放在脚本的顶端:
import sys #引入模块print('命令行参数如下:')
for i in sys.argv:print(i)
print('\n\nPython 路径为:', sys.path, '\n')
这种导入方式只能导入模块级别,不能导入函数级别
from … import 语句
Python 的 from 语句让你从模块中导入一个指定的部分到当前命名空间中,语法如下:
from modname import name1[, name2[, ... nameN]]
from 包名+模块名 as 别名
例如,要导入模块 fibo 的 fib 函数,使用如下语句:
>>> from fibo import fib, fib2
>>> fib(500)
1 1 2 3 5 8 13 21 34 55 89 144 233 377
这个声明不会把整个fibo模块导入到当前的命名空间中,它只会将fibo里的fib函数引入进来。
from … import * 语句
把一个模块的所有内容全都导入到当前的命名空间也是可行的,只需使用如下声明:
from modname import *
from 包名+模块名 as 别名
这提供了一个简单的方法来导入一个模块中的所有项目。然而这种声明不该被过多地使用。
__name__属性
一个模块被另一个程序第一次引入时,其主程序将运行。如果我们想在模块被引入时,模块中的某一程序块不执行,我们可以用__name__属性来使该程序块仅在该模块自身运行时执行。
1. if __name__ == '__main__'主要用于代码的测试,如果以脚本的形式运行,则if中的语句会执行
2. __name__是模块对象的属性如果以脚本的形式运行,则__name__属性的值为__main__如果以模块的形式运行,则__name__属性的值为模块的权限定名
#!/usr/bin/python3
# Filename: using_name.pyif __name__ == '__main__':print('程序自身在运行')
else:print('我来自另一模块')
运行输出如下:
$ python using_name.py
程序自身在运行
$ python
>>> import using_name
我来自另一模块
>>>
说明: 每个模块都有一个__name__属性,当其值是'main'时,表明该模块自身在运行,否则是被引入。
说明:name 与 main 底下是双下划线, _ _ 是这样去掉中间的那个空格。
搜索路径
import sys
sys.path1. Python中的所有路径都在sys.pyth中标准库模块:python安装目录下的lib下第三方模块:一般来自社区的模块---site-packages自定义模块:自己编辑的模块
2. 如果模块真实存在,但是无法直接import,可以手动append到sys.path中
时间和日期
Python 程序能用很多方式处理日期和时间,转换日期格式是一个常见的功能。
Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。
时间间隔是以秒为单位的浮点小数。
每个时间戳都以自从1970年1月1日午夜(历元)经过了多长时间来表示。
Python 的 time 模块下有很多函数可以转换常见日期格式。如函数time.time()用于获取当前时间戳,
import time; # 引入time模块ticks = time.time()
print ("当前时间戳为:", ticks)#结果为:当前时间戳为: 1554082392.113664
获取当前时间
从返回浮点数的时间戳方式向时间元组转换,只要将浮点数传递给如localtime之类的函数。
import timelocaltime = time.localtime(time.time())
print ("本地时间为 :", localtime)
# 获取到时间元组
#运行结果为:本地时间为 : time.struct_time(tm_year=2019, tm_mon=4, tm_mday=1, tm_hour=9, tm_min=35, tm_sec=29, tm_wday=0, tm_yday=91, tm_isdst=0)
获取格式化时间
你可以根据需求选取各种格式,但是最简单的获取可读的时间模式的函数是asctime():
import timelocaltime = time.asctime( time.localtime(time.time()) )
print ("本地时间为 :", localtime)#运行结果为:本地时间为 : Mon Apr 1 09:37:48 2019
格式化日期
我们可以使用 time 模块的 strftime 方法来格式化日期,:
time.strftime(format[, t])
import time# 格式化成2019-03-20 11:45:39形式
print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))# 格式化成Sat Mar 28 22:24:24 2019形式
print (time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()))# 将格式字符串转换为时间戳
a = "Sat Mar 28 22:24:24 2019"
print (time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y")))
python中时间日期格式化符号
1. %y 两位数的年份表示(00-99)
2. %Y 四位数的年份表示(000-9999)
3. %m 月份(01-12)
4. %d 月内中的一天(0-31)
5. %H 24小时制小时数(0-23)
6. %I 12小时制小时数(01-12)
7. %M 分钟数(00=59)
8. %S 秒(00-59)
9. %a 本地简化星期名称
10. %A 本地完整星期名称
11. %b 本地简化的月份名称
12. %B 本地完整的月份名称
13. %c 本地相应的日期表示和时间表示
14. %j 年内的一天(001-366)
15. %p 本地A.M.或P.M.的等价符
16. %U 一年中的星期数(00-53)星期天为星期的开始
17. %w 星期(0-6),星期天为星期的开始
18. %W 一年中的星期数(00-53)星期一为星期的开始
19. %x 本地相应的日期表示
20. %X 本地相应的时间表示
21. %Z 当前时区的名称
22. %% %号本身
获取某月日历
Calendar模块有很广泛的方法用来处理年历和月历,例如打印某月的月历:
import calendarcal = calendar.month(2019, 4)
print ("以下输出2019年4月份的日历:")
print (cal)#输出结果为:
以下输出2019年4月份的日历:April 2019
Mo Tu We Th Fr Sa Su1 2 3 4 5 6 78 9 10 11 12 13 14
15 16 17 18 19 20 21
22 23 24 25 26 27 28
29 30
Time模块的内置函数
Time 模块包含了以下内置函数,既有时间处理的,也有转换时间格式的:
| 序号 | 函数及描述 | 实例 |
|---|---|---|
| 1 | time.altzone 返回格林威治西部的夏令时地区的偏移秒数。如果该地区在格林威治东部会返回负值(如西欧,包括英国)。对夏令时启用地区才能使用。 | 以下实例展示了 altzone()函数的使用方法:>>> import time >>> print ("time.altzone %d " % time.altzone) time.altzone -28800 |
| 2 | time.asctime([tupletime]) 接受时间元组并返回一个可读的形式为"Tue Dec 11 18:07:14 2008"(2008年12月11日 周二18时07分14秒)的24个字符的字符串。 | 以下实例展示了 asctime()函数的使用方法:>>> import time >>> t = time.localtime() >>> print ("time.asctime(t): %s " % time.asctime(t)) time.asctime(t): Thu Apr 7 10:36:20 2016 |
| 3 | time.clock() 用以浮点数计算的秒数返回当前的CPU时间。用来衡量不同程序的耗时,比time.time()更有用。 | 实例由于该方法依赖操作系统,在 Python 3.3 以后不被推荐,而在 3.8 版本中被移除,需使用下列两个函数替代。time.perf_counter() # 返回系统运行时间 time.process_time() # 返回进程运行时间 |
| 4 | time.ctime([secs]) 作用相当于asctime(localtime(secs)),未给参数相当于asctime() | 以下实例展示了 ctime()函数的使用方法:>>> import time >>> print ("time.ctime() : %s" % time.ctime()) time.ctime() : Thu Apr 7 10:51:58 2016 |
| 5 | time.gmtime([secs]) 接收时间戳(1970纪元后经过的浮点秒数)并返回格林威治天文时间下的时间元组t。注:t.tm_isdst始终为0 | 以下实例展示了 gmtime()函数的使用方法:>>> import time >>> print ("gmtime :", time.gmtime(1455508609.34375)) gmtime : time.struct_time(tm_year=2016, tm_mon=2, tm_mday=15, tm_hour=3, tm_min=56, tm_sec=49, tm_wday=0, tm_yday=46, tm_isdst=0) |
| 6 | time.localtime([secs] 接收时间戳(1970纪元后经过的浮点秒数)并返回当地时间下的时间元组t(t.tm_isdst可取0或1,取决于当地当时是不是夏令时)。 | 以下实例展示了 localtime()函数的使用方法:>>> import time >>> print ("localtime(): ", time.localtime(1455508609.34375)) localtime(): time.struct_time(tm_year=2016, tm_mon=2, tm_mday=15, tm_hour=11, tm_min=56, tm_sec=49, tm_wday=0, tm_yday=46, tm_isdst=0) |
| 7 | time.mktime(tupletime) 接受时间元组并返回时间戳(1970纪元后经过的浮点秒数)。 | 实例 |
| 8 | time.sleep(secs) 推迟调用线程的运行,secs指秒数。 | 以下实例展示了 sleep()函数的使用方法:#!/usr/bin/python3 import time print ("Start : %s" % time.ctime()) time.sleep( 5 ) print ("End : %s" % time.ctime()) |
| 9 | time.strftime(fmt[,tupletime]) 接收以时间元组,并返回以可读字符串表示的当地时间,格式由fmt决定。 | 以下实例展示了 strftime()函数的使用方法:>>> import time >>> print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) 2016-04-07 11:18:05 |
| 10 | time.strptime(str,fmt='%a %b %d %H:%M:%S %Y') 根据fmt的格式把一个时间字符串解析为时间元组。 | 以下实例展示了 strptime()函数的使用方法:>>> import time >>> struct_time = time.strptime("30 Nov 00", "%d %b %y") >>> print ("返回元组: ", struct_time) 返回元组: time.struct_time(tm_year=2000, tm_mon=11, tm_mday=30, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=335, tm_isdst=-1) |
| 11 | time.time( ) 返回当前时间的时间戳(1970纪元后经过的浮点秒数)。 | 以下实例展示了 time()函数的使用方法:>>> import time >>> print(time.time()) 1459999336.1963577 |
| 12 | time.tzset() 根据环境变量TZ重新初始化时间相关设置。 | 实例 |
| 13 | time.perf_counter() 返回计时器的精准时间(系统的运行时间),包含整个系统的睡眠时间。由于返回值的基准点是未定义的,所以,只有连续调用的结果之间的差才是有效的。 | 实例 |
| 14 | time.process_time() 返回当前进程执行 CPU 的时间总和,不包含睡眠时间。由于返回值的基准点是未定义的,所以,只有连续调用的结果之间的差才是有效的。 |
Time模块包含了以下2个非常重要的属性:
| 序号 | 属性及描述 |
|---|---|
| 1 | time.timezone 属性time.timezone是当地时区(未启动夏令时)距离格林威治的偏移秒数(>0,美洲;<=0大部分欧洲,亚洲,非洲)。 |
| 2 | time.tzname 属性time.tzname包含一对根据情况的不同而不同的字符串,分别是带夏令时的本地时区名称,和不带的。 |
日历(Calendar)模块
此模块的函数都是日历相关的,例如打印某月的字符月历。
星期一是默认的每周第一天,星期天是默认的最后一天。更改设置需调用calendar.setfirstweekday()函数。模块包含了以下内置函数:
| 序号 | 函数及描述 |
|---|---|
| 1 | calendar.calendar(year,w=2,l=1,c=6) 返回一个多行字符串格式的year年年历,3个月一行,间隔距离为c。 每日宽度间隔为w字符。每行长度为21* W+18+2* C。l是每星期行数。 |
| 2 | calendar.firstweekday( ) 返回当前每周起始日期的设置。默认情况下,首次载入caendar模块时返回0,即星期一。 |
| 3 | calendar.isleap(year) 是闰年返回 True,否则为 false。>>> import calendar >>> print(calendar.isleap(2000)) True >>> print(calendar.isleap(1900)) False |
| 4 | calendar.leapdays(y1,y2) 返回在Y1,Y2两年之间的闰年总数。 |
| 5 | calendar.month(year,month,w=2,l=1) 返回一个多行字符串格式的year年month月日历,两行标题,一周一行。每日宽度间隔为w字符。每行的长度为7* w+6。l是每星期的行数。 |
| 6 | calendar.monthcalendar(year,month) 返回一个整数的单层嵌套列表。每个子列表装载代表一个星期的整数。Year年month月外的日期都设为0;范围内的日子都由该月第几日表示,从1开始。 |
| 7 | calendar.monthrange(year,month) 返回两个整数。第一个是该月的星期几,第二个是该月有几天。星期几是从0(星期一)到 6(星期日)。>>> import calendar >>> calendar.monthrange(2014, 11) (5, 30)(5, 30)解释:5 表示 2014 年 11 月份的第一天是周六,30 表示 2014 年 11 月份总共有 30 天。 |
| 8 | calendar.prcal(year,w=2,l=1,c=6) 相当于 print calendar.calendar(year,w,l,c). |
| 9 | calendar.prmonth(year,month,w=2,l=1) 相当于 print calendar.calendar(year,w,l,c)。 |
| 10 | calendar.setfirstweekday(weekday) 设置每周的起始日期码。0(星期一)到6(星期日)。 |
| 11 | calendar.timegm(tupletime) 和time.gmtime相反:接受一个时间元组形式,返回该时刻的时间戳(1970纪元后经过的浮点秒数)。 |
| 12 | calendar.weekday(year,month,day) 返回给定日期的日期码。0(星期一)到6(星期日)。月份为 1(一月) 到 12(12月)。 |
其他相关模块和函数
在Python中,其他处理日期和时间的模块还有:
- time 模块
- datetime模块
**案例1:**perf_counter 进度条实例
import timescale = 50 print("执行开始".center(scale//2,"-")) # .center() 控制输出的样式,宽度为 25//2,即 22,汉字居中,两侧填充 -start = time.perf_counter() # 调用一次 perf_counter(),从计算机系统里随机选一个时间点A,计算其距离当前时间点B1有多少秒。当第二次调用该函数时,默认从第一次调用的时间点A算起,距离当前时间点B2有多少秒。两个函数取差,即实现从时间点B1到B2的计时功能。
for i in range(scale+1): a = '*' * i # i 个长度的 * 符号b = '.' * (scale-i) # scale-i) 个长度的 . 符号。符号 * 和 . 总长度为50 c = (i/scale)*100 # 显示当前进度,百分之多少dur = time.perf_counter() - start # 计时,计算进度条走到某一百分比的用时print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c,a,b,dur),end='') # \r用来在每次输出完成后,将光标移至行首,这样保证进度条始终在同一行输出,即在一行不断刷新的效果;{:^3.0f},输出格式为居中,占3位,小数点后0位,浮点型数,对应输出的数为c;{},对应输出的数为a;{},对应输出的数为b;{:.2f},输出有两位小数的浮点数,对应输出的数为dur;end='',用来保证不换行,不加这句默认换行。time.sleep(0.1) # 在输出下一个百分之几的进度前,停止0.1秒
print("\n"+"执行结果".center(scale//2,'-'))#执行结果为:
-----------执行开始----------
24 %[************->......................................]1.24s
import time
import calendar"""时间元组(年、月、日、时、分、秒、一周的第几日、一年的第几日、夏令时)一周的第几日: 0-6一年的第几日: 1-366夏令时: -1, 0, 1
""""""python中时间日期格式化符号:------------------------------------%y 两位数的年份表示(00-99)%Y 四位数的年份表示(000-9999)%m 月份(01-12)%d 月内中的一天(0-31)%H 24小时制小时数(0-23)%I 12小时制小时数(01-12)%M 分钟数(00=59)%S 秒(00-59)%a 本地简化星期名称%A 本地完整星期名称%b 本地简化的月份名称%B 本地完整的月份名称%c 本地相应的日期表示和时间表示%j 年内的一天(001-366)%p 本地A.M.或P.M.的等价符%U 一年中的星期数(00-53)星期天为星期的开始%w 星期(0-6),星期天为星期的开始%W 一年中的星期数(00-53)星期一为星期的开始%x 本地相应的日期表示%X 本地相应的时间表示%Z 当前时区的名称 # 乱码%% %号本身
"""# (1)当前时间戳
# 1538271871.226226
time.time()# (2)时间戳 → 时间元组,默认为当前时间
# time.struct_time(tm_year=2018, tm_mon=9, tm_mday=3, tm_hour=9, tm_min=4, tm_sec=1, tm_wday=6, tm_yday=246, tm_isdst=0)
time.localtime()
time.localtime(1538271871.226226)# (3)时间戳 → 可视化时间
# time.ctime(时间戳),默认为当前时间
time.ctime(1538271871.226226)# (4)时间元组 → 时间戳
# 1538271871
time.mktime((2018, 9, 30, 9, 44, 31, 6, 273, 0))# (5)时间元组 → 可视化时间
# time.asctime(时间元组),默认为当前时间
time.asctime()
time.asctime((2018, 9, 30, 9, 44, 31, 6, 273, 0))
time.asctime(time.localtime(1538271871.226226))# (6)时间元组 → 可视化时间(定制)
# time.strftime(要转换成的格式,时间元组)
time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())# (7)可视化时间(定制) → 时间元祖
# time.strptime(时间字符串,时间格式)
print(time.strptime('2018-9-30 11:32:23', '%Y-%m-%d %H:%M:%S'))# (8)浮点数秒数,用于衡量不同程序的耗时,前后两次调用的时间差
time.clock()
Python的标准库
派派社区:https://pypi.python.org/pypi1. 查看Python中的模块help('modeles')
- 执行环境
1. 模块带入到其他文件中,也可以导入到其他模块---模块的调用---链式调用模块可以用其他语言写---Java/c
2. 模块可以包含:类,全局变量,函数1其他内容尽量不要书写---(while,for,if else,input,if...),写到函数中原因:模块再被导入时会自动执行一次
3. 模块的文件类型:py pyc pyopy:源文件pyc:字节码文件---通过pvmpyo:优化编译后的程序---硬件
文件
- 打开文件
open()函数
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)参数说明:1. file: 必需,文件路径(相对或者绝对路径)。
2. mode: 可选,文件打开模式
3. buffering: 设置缓冲;---0:关闭缓冲区/1:打开缓冲区/大于1设置缓冲区大小为该值/负数:缓冲区交由系统管理
4. encoding: 一般使用utf8
5. errors: 报错级别
6. newline: 区分换行符
7. closefd: 传入的file参数类型
8. opener:
mode 参数有:
| 模式 | 描述 |
|---|---|
| t | 文本模式 (默认)。 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| b | 二进制模式。 |
| + | 打开一个文件进行更新(可读可写)。 |
| U | 通用换行模式(不推荐)。 |
| r | 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 |
| rb | 以二进制格式打开一个文件用于只读。文件指针将会放在文件的开头。这是默认模式。一般用于非文本文件如图片等。 |
| r+ | 打开一个文件用于读写。文件指针将会放在文件的开头。 |
| rb+ | 以二进制格式打开一个文件用于读写。文件指针将会放在文件的开头。一般用于非文本文件如图片等。 |
| w | 打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb | 以二进制格式打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| w+ | 打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。 |
| wb+ | 以二进制格式打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。一般用于非文本文件如图片等。 |
| a | 打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| ab | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。 |
| a+ | 打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。 |
| ab+ | 以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。如果该文件不存在,创建新文件用于读写。 |
默认为文本模式,如果要以二进制模式打开,加上 b 。
file 对象
file 对象使用 open 函数来创建
- file对象扽属性
1. closed2. mode3. name4. softspace
- file对象的方法
| 序号 | 方法及描述 |
|---|---|
| 1 | file.close()关闭文件。关闭后文件不能再进行读写操作。 |
| 2 | file.flush()刷新文件内部缓冲,直接把内部缓冲区的数据立刻写入文件, 而不是被动的等待输出缓冲区写入。 |
| 3 | file.fileno()返回一个整型的文件描述符(file descriptor FD 整型), 可以用在如os模块的read方法等一些底层操作上。 |
| 4 | file.isatty()如果文件连接到一个终端设备返回 True,否则返回 False。 |
| 5 | file.next()返回文件下一行。 |
| 6 | [file.read(size])从文件读取指定的字节数,如果未给定或为负则读取所有。 |
| 7 | [file.readline(size])读取整行,包括 "\n" 字符。 |
| 8 | [file.readlines(sizeint])读取所有行并返回列表,若给定sizeint>0,返回总和大约为sizeint字节的行, 实际读取值可能比 sizeint 较大, 因为需要填充缓冲区。 |
| 9 | [file.seek(offset, whence])设置文件当前位置 |
| 10 | file.tell()返回文件当前位置。 |
| 11 | [file.truncate(size])从文件的首行首字符开始截断,截断文件为 size 个字符,无 size 表示从当前位置截断;截断之后后面的所有字符被删除,其中 Widnows 系统下的换行代表2个字符大小。 |
| 12 | file.write(str)将字符串写入文件,返回的是写入的字符长度。 |
| 13 | file.writelines(sequence)向文件写入一个序列字符串列表,如果需要换行则要自己加入每行的换行符。 |
错误和异常
异常处理--捕获异常
while True:try:x = int(input("Please enter a number: "))breakexcept ValueError:print("Oops! That was no valid number. Try again ")
try语句按照如下方式工作;
- 首先,执行try子句(在关键字try和关键字except之间的语句)
- 如果没有异常发生,忽略except子句,try子句执行后结束。
- 如果在执行try子句的过程中发生了异常,那么try子句余下的部分将被忽略。如果异常的类型和 except 之后的名称相符,那么对应的except子句将被执行。最后执行 try 语句之后的代码。
- 如果一个异常没有与任何的except匹配,那么这个异常将会传递给上层的try中。
一个 try 语句可能包含多个except子句,分别来处理不同的特定的异常。最多只有一个分支会被执行。
处理程序将只针对对应的try子句中的异常进行处理,而不是其他的 try 的处理程序中的异常。
一个except子句可以同时处理多个异常,这些异常将被放在一个括号里成为一个元组,例如:
except (RuntimeError, TypeError, NameError): pass
最后一个except子句可以忽略异常的名称,它将被当作通配符使用。你可以使用这种方法打印一个错误信息,然后再次把异常抛出。
import systry:f = open('myfile.txt')s = f.readline()i = int(s.strip())
except OSError as err:print("OS error: {0}".format(err))
except ValueError:print("Could not convert data to an integer.")
except:print("Unexpected error:", sys.exc_info()[0])raise
try except 语句还有一个可选的else子句,如果使用这个子句,那么必须放在所有的except子句之后。这个子句将在try子句没有发生任何异常的时候执行。例如:
for arg in sys.argv[1:]:try:f = open(arg, 'r')except IOError:print('cannot open', arg)else:print(arg, 'has', len(f.readlines()), 'lines')f.close()
使用 else 子句比把所有的语句都放在 try 子句里面要好,这样可以避免一些意想不到的、而except又没有捕获的异常。
异常处理并不仅仅处理那些直接发生在try子句中的异常,而且还能处理子句中调用的函数(甚至间接调用的函数)里抛出的异常。例如:
>>>def this_fails():x = 1/0>>> try:this_fails()except ZeroDivisionError as err:print('Handling run-time error:', err)Handling run-time error: int division or modulo by zero
异常处理--抛出异常
Python 使用 raise 语句抛出一个指定的异常,raise 唯一的一个参数指定了要被抛出的异常。它必须是一个异常的实例或者是异常的类(也就是 Exception 的子类)。如果你只想知道这是否抛出了一个异常,并不想去处理它,那么一个简单的 raise 语句就可以再次把它抛出。
>>>try:raise NameError('HiThere')except NameError:print('An exception flew by!')raiseAn exception flew by!
Traceback (most recent call last):File "", line 2, in ?
NameError: HiThere
- 自定义异常
可以通过创建一个新的异常类来拥有自己的异常。异常类继承自 Exception 类,可以直接继承,或者间接继承,例如:
>>>class MyError(Exception):def __init__(self, value):self.value = valuedef __str__(self):return repr(self.value)>>> try:raise MyError(2*2)except MyError as e:print('My exception occurred, value:', e.value)My exception occurred, value: 4
>>> raise MyError('oops!')
Traceback (most recent call last):File "", line 1, in ?
__main__.MyError: 'oops!''''
在这个例子中,类 Exception 默认的 __init__() 被覆盖。
当创建一个模块有可能抛出多种不同的异常时,一种通常的做法是为这个包建立一个基础异常类,然后基于这个基础类为不同的错误情况创建不同的子类:
'''
定义清理行为
try:result = x / y
except ZeroDivisionError:print("division by zero!")
else:print("result is", result)
finally: #无论如何都要执行的代码块print("executing finally clause")如果一个异常在 try 子句里(或者在 except 和 else 子句里)被抛出,而又没有任何的 except 把它截住,那么这个异常会在 finally 子句执行后再次被抛出。
>>>def divide(x, y):try:result = x / yexcept ZeroDivisionError:print("division by zero!")else:print("result is", result)finally:print("executing finally clause")
预定义的清理行为
一些对象定义了标准的清理行为,无论系统是否成功的使用了它,一旦不需要它了,那么这个标准的清理行为就会执行。
这面这个例子展示了尝试打开一个文件,然后把内容打印到屏幕上:
for line in open("myfile.txt"):print(line, end="")
以上这段代码的问题是,当执行完毕后,文件会保持打开状态,并没有被关闭。
关键词 with 语句就可以保证诸如文件之类的对象在使用完之后一定会正确的执行他的清理方法:
with open("myfile.txt") as f:for line in f:print(line, end="")
以上这段代码执行完毕后,就算在处理过程中出问题了,文件 f 总是会关闭。
多线程
- 进程
1. 计算机的核心是CPU,承担计算任务
2. 操作系统是计算机的管理者,负责任务的调度、资源的分配和管理以及整个计算机硬件。
3. 应用程序是具有某种功能的程序,程序试运行在操作系统中的。
4. 进程是一个具有独立功能的程序,在一个数据集合上的一个独立的单位,是应用程序运行的载体。
5. 进程是一种模糊的概念,没有标准的定义进程包括:程序:程序用于描述进程要完成的功能,是控制进程执行的指令集。数据集合:程序在执行时所需要的数据和工作区。进程的控制块:包含进程的描述信息和控制信息,是进程的唯一标识。 进程的特点
1. 动态性:动态产生动态消亡。
2. 并发性:宏观并行微观串行。
3. 独立性:进程与进程之间互不影响。
4. 结构性:进程=程序+数据集合+进程控制块
- 线程
1. 线程也是一种抽象的概念,是轻量级的进程
2. 进程中可以包含线程线程包括:线程ID指令指针寄存器堆栈
线程的特点:
1. 线程是程序执行的最小单位,是CPU调度和分配的最小单位。---内存空间
2. 进程是操作系统分配资源的最小单位。---时间片
3. 一个进程有多个线程组成,线程是进程的不同执行路线
4. 进程和进程之间是相互独立的,但是一个进程下的多个线程之间共享进程的空间以及进程的一些资源。
5. 不同进程间的线程独立不可见。
6. 线程的调度和切换要比进程的调度和切换快的多。
- 单线程和多线程
1. 单线程:一个进程只有一个线程,程序所有的资源供一个线程使用。
2. 多线程:在一个进程中有多个线程,多个线程之间并发(宏观并行微观串行)执行,相互抢占资源。
- Python的多线程模块threading
1. Thread类:threading.Thread(self,group=None,target=None,name=None,args=(),kwargs={})Thread是threading模块中最重要的类,可以创建线程参数说明:group:预留的参数用于扩展target:可调用的对象(函数对象)name:线程的名字,线程默认的名字:Thread-N;比如第一个线程Thread-1;第二个线程Thread-2args/kwargs:分别表示target的参数和关键字参数创建线程的的方式
继承Thread类,覆盖run()方法
#自定义类继承Thread
import threading#创建线程任务类--继承Thread
class MyThread1(threading.Thread):def __init__(self,names,count):super().__init__()self.names=namesself.count=count#覆盖run()方法def run(self):for i in range(self.count):print('****************%s******************' % (self.names))class MyThread2(threading.Thread):def __init__(self, names, count):super().__init__()self.names = namesself.count = count# 覆盖run()方法def run(self):for i in range(self.count):print('================%s=================='%(self.names))if __name__ == '__main__':#创建线程对象t1=MyThread1('A',100)t2=MyThread2('B',100)#启动线程t1.start()t2.start()
threading.Thread()
#threading.Thread()的方式创建线程
import threading#创建线程任务
def task1(names,count):for i in range(count):print('****************%s******************'%(names))def task2(names,coun):for i in range(coun):print('================%s=================='%(names))if __name__ == '__main__':#创建线程对象t1= threading.Thread(target=task1,args=('A',100)) #给threading下的Thread类传递构造参数t2= threading.Thread(target=task2,args=('B',100)) #给threading下的Thread类传递构造参数# 开启线程t1.start()t2.start()
- threading.Thread类的其他方法
1. getName():获取线程的名字
2. setName():设置线程的名字
3. ident:获取线程标识符应该放在启动之后---一般是一个非零的整数如果放在启动之前---None
4. is_alive():判断线程是否是激活状态
5. join([timeout]):调用Thread.join()线程会阻塞---当前线程(主线程),直到被join()的线程执行完毕timeout:设置超时时间如果发生了当前线程阻塞,等等timeout秒,如果时间到,则不在阻塞
6. setDaemon():线程守护--守护线程--精灵线程
线程的状态
和Java一样 分为五个状态,初始状态、就绪状态、运行状态、死亡状态、阻塞状态
GIL全局锁

线程同步
import threading,timelock=threading.Lock() #定义锁class MyList:def __init__(self):self.l=['A','B','','','','']self.index=2def addList(self,value):lock.acquire() #添加锁标记self.l[self.index]=valuetime.sleep(0.0001)self.index+=1lock.release() #释放锁标记def getList(self):return self.ldef addTask(myList,value):myList.addList(value)if __name__=='__main__':m=MyList()#m.addList('C')#m.addList('D')t1=threading.Thread(target=addTask,args=(m,'C'))t2=threading.Thread(target=addTask,args=(m,'D'))t1.start()t2.start()t1.join()t2.join()print(m.getList())
- 死锁
1. 死锁:一个线程中有且只有一次机会使用acquire()给线程加锁,如果出现多个,则线程进入到死锁状态,无法使用
2. 解决方案:只是用一次锁;或者使用RLock类获得锁对象,该锁可被多次调用。
Python的风格
PEP8
Python的语句和语法
- 注释
#:可以从任意一行开始注释,主要用于python的文档
- 续行
\:单一语句跨行
''':闭合操作符,单一语句跨多行,用于内置文档,实现多行注释,可以用于字符串进行使用
- 代码块(代码组)
1. 缩进相同的一组语句构成一个代码块
2. 代码块中可以嵌套其他代码块
3. python使用缩进来进行分割---同一个代码块中的代码必须严格的进行左对齐。
- 同一行书写多个语句
;:使用分号隔开,例如:print(100);print(200);print(300);print(400);
强烈建议不这样书写
- 模块
1. 每个python脚本文件都可以当作一个模块(模块名--脚本名--文件名)
2. 模块里的代码可以是一段直接执行的脚本,也可以是一些类似库函数的代码从而可以有别的模块执行导入import
3. 模块在被导入时会执行一次,模块中尽量只包含类、函数、全局变量,直接执行的代码尽量避免import在导入模块时,会自动编译--生成模块对象,方便其他的模块调用
转载于:https://my.oschina.net/u/3991887/blog/3065040
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!