强化学习RL 05: Alpha Go、Alpha Zero
目录
1. Alpha Go
1.1 Behavior Cloning
1.2 reinforcement learning of policy network
1.3 Alpha Zero
1.4 Monte-Carlo Tree Search
参考
1. Alpha Go
- alphaGo actually uses a 19*19*48 tensor to store other information.
- number of possible sequence of actions is
- training in 3 steps:
- initialize policy network using behavior cloning.
- train the policy network using policy gradient.
- after training the policy network, use it to train a value network.
- Execution (actually play Go games)
- Do Monte Carlo Tree Search (MCTS) using the policy and value networks.
1.1 Behavior Cloning
Behavior cloning is imitation learning rather than reinforcement learning.
problem:会对未见过的操作懵逼,然后break down。
1.2 reinforcement learning of policy network

1.3 Alpha Zero
- AlphaGo Zero does not use human experience. (no behavior cloning)
1.4 Monte-Carlo Tree Search
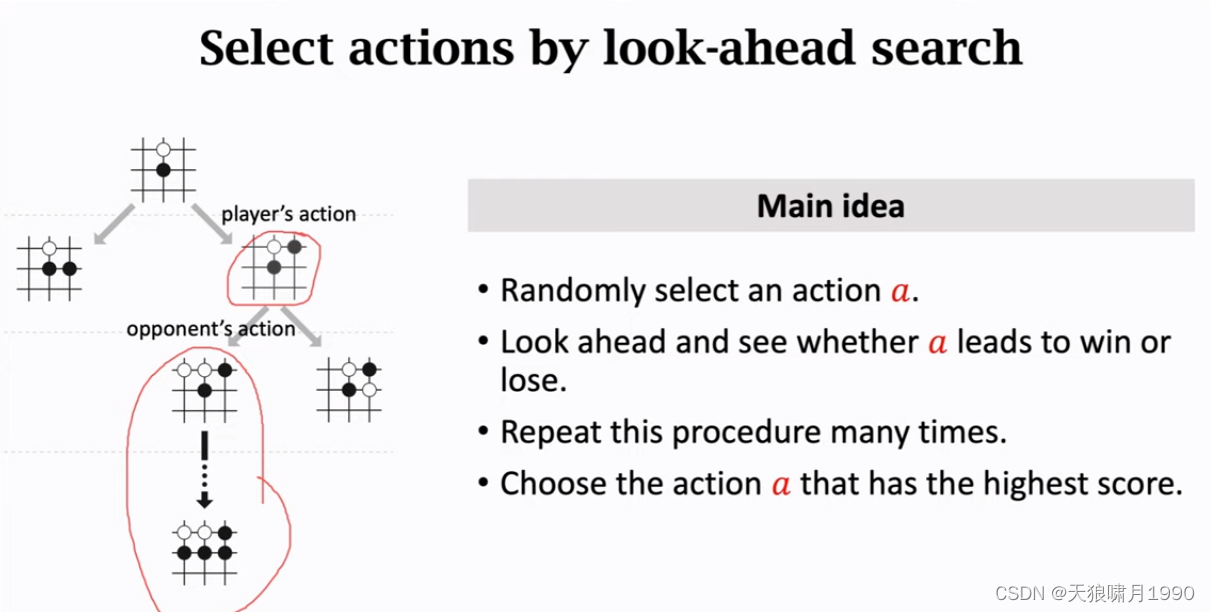
- step 1: Selection
- step 2: Expansion
- step 3: Evaluation
- step 4: Backup
参考
1. 王树森~强化学习 Reinforcement Learning
2. https://www.cnblogs.com/pinard/category/1254674.html
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!