爬虫总结——(2)页面信息解析
很多时候,我们爬取了一整张页面后,我们只会截取一部分的内容。比如我可能只要页面某个栏目的图片,或者只要文章的开头。通过看网页的html内容,我们可以发现,其实其结构属于层层包含,而我们所需要的通常在,某个class或者div的目录下。因此我们就可以使用正则表达式,bs4或者xpath。
先来看一下正则。正则涉及到正则表达式。
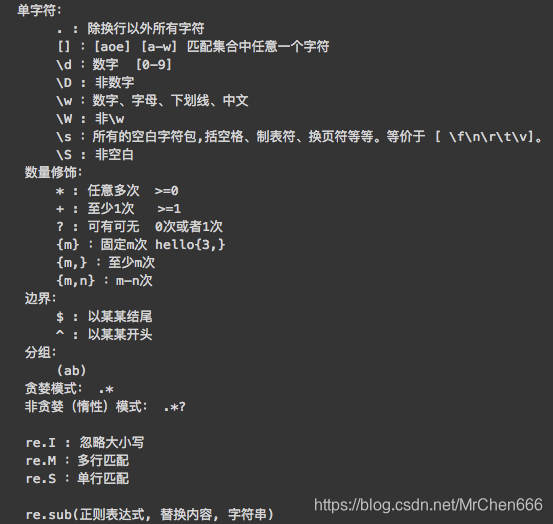
大家可以来练习一下正则。
#提取pythonkey = "javapythonc++php"print( re.findall('python' , key)[0] )key = "hello world "
#这里的(.*)表示多个字符:hello worldprint( re.findall('(.*)'
, key)[0] )string = '我喜欢身高为170的女生'#这里\d表示数字,后面的+表示取至少一次print( re.findall('\d+' , string )[0] )
下面给一个页面中某个链接所在的位置,用正则表达式可以把链接提取出来
''' '''ex = '.*?#这是使用正则的方法newsList = re.findall(ex , response , re.S)
接下来就是beautifulsoup了,要使用beautifulsoup,先把html的text文件转化为beautifulsoup文件,然后再进行搜索。beautifulsoup将html中的标签按树的结构来存储,因此具有层次结构。
使用流程: - 导包:from bs4 import BeautifulSoup- 使用方式:可以将一个html文档,转化为BeautifulSoup对象,然后通过对象的方法或者属性去查找指定的节 点内容(1)转化本地文件:- soup = BeautifulSoup(open('本地文件'), 'lxml')(2)转化网络文件:- soup = BeautifulSoup('字符串类型或者字节类型', 'lxml')(3)打印soup对象显示内容为html文件中的内容
基础巩固:(1)根据标签名查找- soup.a 只能找到第一个符合要求的标签(2)获取属性- soup.a.attrs 获取a所有的属性和属性值,返回一个字典- soup.a.attrs['href'] 获取href属性- soup.a['href'] 也可简写为这种形式(3)获取内容- soup.a.string- soup.a.text- soup.a.get_text()【注意】如果标签还有标签,那么string获取到的结果为None,而其它两个,可以获取文本内容(4)find:找到第一个符合要求的标签- soup.find('a') 找到第一个符合要求的- soup.find('a', title="xxx")- soup.find('a', alt="xxx")- soup.find('a', class_="xxx")- soup.find('a', id="xxx")(5)find_all:找到所有符合要求的标签- soup.find_all('a')- soup.find_all(['a','b']) 找到所有的a和b标签- soup.find_all('a', limit=2) 限制前两个(6)根据选择器选择指定的内容select:soup.select('#feng')- 常见的选择器:标签选择器(a)、类选择器(.)、id选择器(#)、层级选择器- 层级选择器:div .dudu #lala .meme .xixi 下面好多级div > p > a > .lala 只能是下面一级【注意】select选择器返回永远是列表,需要通过下标提取指定的对象
最后说一下xpath,其实原理大致跟beautifulsoup类似,就是语法不太相同。使用时同样想转化为xpath文件,然后再根据层级关系来查找。
属性定位:#找到class属性值为song的div标签//div[@class="song"]
层级&索引定位:#找到class属性值为tang的div的直系子标签ul下的第二个子标签li下的直系子标签a//div[@class="tang"]/ul/li[2]/a
逻辑运算:#找到href属性值为空且class属性值为du的a标签//a[@href="" and @class="du"]
模糊匹配://div[contains(@class, "ng")]//div[starts-with(@class, "ta")]
取文本:# /表示获取某个标签下的文本内容# //表示获取某个标签下的文本内容和所有子标签下的文本内容//div[@class="song"]/p[1]/text()//div[@class="tang"]//text()
取属性://div[@class="tang"]//li[2]/a/@href
解析逻辑:当我们要解析的东西分布在不同层级,可以采用或逻辑运算符来处理#解析到热门城市和所有城市对应的a标签#//div[@class="bottom"]/ul/li/a 热门城市a标签#//div[@class="bottom"]/ul/div[2]/li/a 全部城市的a标签#通过或运算符,来得到热门和全部城市的a标签a_list = tree.xpath('//div[@class="bottom"]/ul/li/a | //div[@class="bottom"]/ul/div[2]/li/a')
这里举个例子,爬取新闻的标题和文章
import requests
from bs4 import BeautifulSoup
import json
if __name__ == '__main__':res = requests.get('http://world.chinadaily.com.cn/5bd55927a3101a87ca8ff618').textua = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0'}html = BeautifulSoup(res)for i in html.select('.left-liebiao .busBox3 h3 > a'):res1 = requests.get('https:'+i.attrs['href'],headers=ua).texthtml1 = BeautifulSoup(res1)item = {}try:item['title'] = html1.select('.dabiaoti')[0].textitem['body'] = ''for i in html1.select('#Content > p'):item['body'] += i.textexcept Exception:continuejs = json.dumps(item,ensure_ascii=False)with open('out.json','a+',encoding='utf-8') as file:file.write(js+'\n')print(js)
看一个xpath解析图片的例子(图片解析一般先找到图片的url,而一般图片的url是不完整的,因此拼接好后request完整的url,并把图片(注意是二进制文件)爬取,然后进行存储(存储时可以用文件夹装载,创立文件夹要导入os包),而写文件注意是 ‘wb’ 操作。)
#使用xpath解析美人图片import requests
from lxml import etree
import osif __name__ == '__main__':url = 'http://pic.netbian.com/4kmeinv/'headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.55'}response = requests.get(url= url , headers= headers)#由于直接解析得到的中文会出现乱码,因此要预先编码#response.encoding = 'utf-8'page_text = response.texttree = etree.HTML(page_text)li_list = tree.xpath('//div[@class="slist"]/ul/li')#使用os来创建文件夹if not os.path.exists('./picLibs'):os.mkdir('./picLibs')for li in li_list:img_src = 'http://pic.netbian.com' + li.xpath('./a/img/@src')[0]img_name = li.xpath('./a/img/@alt')[0] + '.jpg'#通用处理中文乱码方法img_name = img_name.encode('iso-8859-1').decode('gbk')img_path = 'picLibs/' + img_name#请求图片并存储img_data = requests.get(url= img_src , headers= headers).contentwith open(img_path , 'wb') as fp:fp.write(img_data)print(img_name + '下载成功!!!')
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!