《Python数据分析与应用》第6章 使用sklearn构建模型 实训部分
《Python数据分析与应用》第6章 使用sklearn构建模型 实训部分((源于大学课程python数据分析))
实训1 使用sklearn处理wine和wine_quality数据集
1.使用pandas库分别读取wine数据集



2.将wine数据集和wine_quality数据集的数据和标签拆分开
拆分wine数据集

和wine_quality数据集

3.将wine,wine_quality数据集划分为训练集和测试集


4.标准化wine数据集和wine_quality数据集


5.对wine数据集和wine_quality数据集进行PCA降维


实训2 构建基于wine数据集的K-Means聚类模型
1.构建聚类数目为3的K-Means模型

2.对比真实标签和聚类标签求取FMI

3.在聚类数目为2-10类时,确定最优聚类数目

结果表明最优聚类数目为3类
4.求取模型的轮廓系数,绘制轮廓系数折线图,确定最优聚类数目

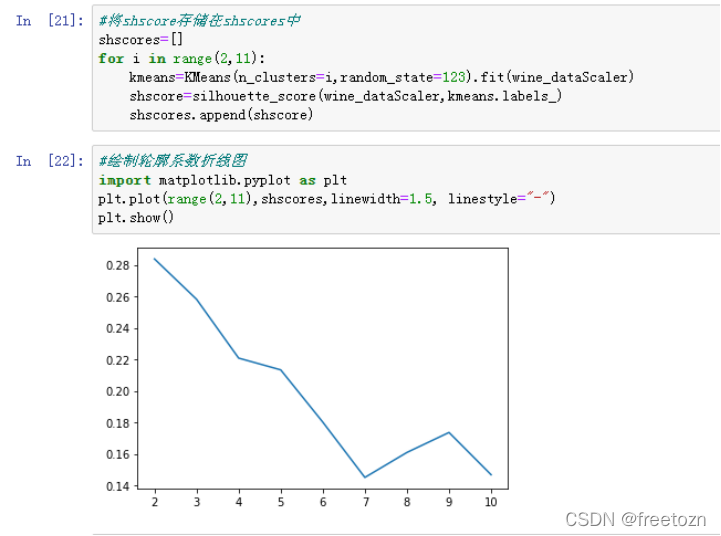
由上图所示,k=7时,畸变程度最大,所以最优聚类数目为7
5.求取Calinski—Harabasz指数,确定最优聚类数目

如上显示k=2时,数值较大,因此最优聚类数目为2
实训3 构建基于wine数据集的SVM分类模型
1.读取wine数据集,区分标签和数据

2.将wine数据集划分为训练集和测试集

3.使用离差标准化方法标准化wine数据集

4.构建SVM模型,并预测测试集结果


5.打印出分类报告,评价分类模型性能

准确率和Cohen’s Kappa系数一定程度是接近1,该分类模型性能较好
实训4 构建基于wine_quality数据集的回归模型

1.根据wine_quality数据集处理的结果,构建线性回归模型

2.根据wine_quality数据集处理的结果,构建梯度提升回归模型

3.结合真实评分和预测评分,计算均方误差、中值绝对误差、可解释方差


4.根据得分,判定模型的性能优劣
由于上可知,平均绝对误差、均方误差、中值绝对误差,梯度提升回归模型均比线性模型更接近0,可解释方差值、回归R方值梯度,提升回归模型均比线性模型更接近1,因此梯度提升回归模型优于线性回归模型
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!