XML 1 笔记分享
XML 1
1.理解XML的概念和优势
XML:
- eXtendsible 可扩展的 未来我们在XML中写什么都可以
- Markup标记 标记
- Language语言
java.xxx
doubbox
HTML:Hyper超级 Text文本 Markup标记 Language语言
优势介绍:
最初诞生的作用:用于数据传输,数据传输格式
后来:被广泛应用于某些系统的配置文件和小型程序的数据存储
2.会编写格式良好的XML文档
2.1文档的组成
扩展名:.xml
XML文档由两部分组成:
-
文档头(声明)
-
文档内容(主体)
<students><student name="雷锋" age="23">student><student name="七条" age="1">student> students>
2.2文档的标签语法
-
声明 每个XML文档都有,它必须在第一行,用来声明XML的文档信息
version和encoding是两个属性 分别表示XML版本、文档编码格式
-
<元素名/标签名/节点名 属性1="属性值" 属性2="属性值" >元素内容双标签语法: 前面的标签称为开放标签 后面的标签称为结束标签/闭合标签
-
<元素名/>单标签/自闭合语法
2.3XML编写注意事项
-
XML中的标签必须注意有开有闭, 或者
-
XML中的标签必须注意正确嵌套和同级缩进。(为了阅读更加方便)
-
XML中的标签名注意遵循小驼峰语法或者下划线连接法,避免出现
-、.、:不能出现空格。 -
XML中的属性要求小写,同样属性值中不允许出现特殊符号:
<、&、"它们有特殊含义。 -
XML中注意区分大小写,和是两个标签不是同一个。
3.了解XML中特殊字符的处理方式
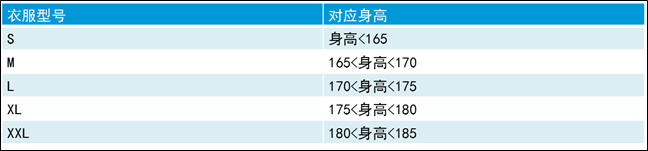
<clothesSize><size><type>Stype><height>身高<165height>size><size><type>Mtype><height>height>size>
clothesSize>
< less than < 小于
> greater than > 大于
& &
" 双引号
' 单引号
当你需要使用大量的特殊符号时 可以直接使用CDATA来帮助你消除特殊含义
4.了解解析器和DOM树节点构造
Java如何操作XML文件?
- 使用IO流,内容识别起来非常繁琐,API过于原生,操作步骤也繁琐。
- 基于IO流产生了一些封装的基础,专门用于XML解析。API相较简单且解析更强。
常见的解析方式:
- DOM解析(W3C)
- 基于XML树结构来进行解析
- 比较消耗资源
- SAX解析
- 基于事件的解析
- 资源消耗小
- DOM4J(DOM for Java)
- 基于DOM和SAX的优点构成,开源的
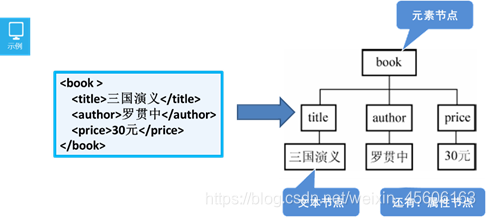
DOM解析:XML树结构是什么意思?
DOM是Document Object Model(文档对象模型)的意思,它的解析方式要求解析器把整个XML 文档装裁到内存(我们俗称DOM树),并解析成一个Document对象。
DOM中的术语
- 节点(Node):在DOM树结构中,每一个组成都可以称之为节点
- 元素 Element
- 属性 Attribute
- 标签内容 Text
- 注释 Comment
- ……
5.会使用DOM操作XML数据
5.1查看
// 1.创建解析器工厂对象
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
// 2.解析工厂对象创建解析器对象
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
// 3.解析器对象解析指定的XML 将其转换为Document对象
Document document = documentBuilder.parse(new File("src\\cn\\kgc\\work\\user.xml"));
// 4.使用Document对象进行文档内容操控
// getElementsByTagName(String tagName) 根据标签名获取元素节点列表
NodeList userNodeList = document.getElementsByTagName("user");
// 遍历节点列表
for (int i = 0; i < userNodeList.getLength(); i++) {// 根据索引获取指定的节点对象Node userNode = userNodeList.item(i);// 为了获取元素专有信息强转 获取节点中的每个属性Element userEle = (Element)userNode;// getAttribute(String name)根据属性名获取属性值String userId = userEle.getAttribute("userId");String username = userEle.getAttribute("username");String password = userEle.getAttribute("password");String email = userEle.getAttribute("email");System.out.println("userId:"+userId+" username:"+username+" password:"+password+" email:"+email+"\n");
}
5.2增加
// 1.创建解析工厂对象
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
// 2.利用解析工厂对象创建解析器对象
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
// 3.利用解析器对象指定的XML 将其转换为Document对象
Document document = documentBuilder.parse(new File("src\\cn\\kgc\\work\\user.xml"));// 创建一个user标签
Element userEle = document.createElement("user");
// 给user添加属性
userEle.setAttribute("userId", "4");
userEle.setAttribute("username", "cxk");
userEle.setAttribute("password", "cxknmsl");
userEle.setAttribute("email", "cxk@126.com");
// 获取根节点
Node usersNode = document.getElementsByTagName("users").item(0);
// 将user标签 指定为users的一个子节点
Node usersChild = usersNode.appendChild(userEle);
5.3保存
将内存中的数据 输出到 XML中
// 1.创建TransformerFactory工厂对象
TransformerFactory transformerFactory = TransformerFactory.newInstance();
// 2.工厂对象创建Transformer(转换器)对象
Transformer transformer = transformerFactory.newTransformer();
// 3.指定数据源
DOMSource domSource = new DOMSource(document);
// 4.指定输出的目的地
StreamResult streamResult = new StreamResult(new File("src\\cn\\kgc\\work\\user.xml"));
// 5.指定输出模式
transformer.setOutputProperty("encoding", "UTF-8");
// 6.转换器执行转换
transformer.transform(domSource, streamResult);
amResult streamResult = new StreamResult(new File("src\\cn\\kgc\\work\\user.xml"));
// 5.指定输出模式
transformer.setOutputProperty("encoding", "UTF-8");
// 6.转换器执行转换
transformer.transform(domSource, streamResult);
注:笔记思路来自查老师!!
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!