强化学习的学习之路(十四)_2021-01-14 :动态规划(DP)、蒙特卡罗(MC)、时间差分(TD)
作为一个新手,写这个强化学习-基础知识专栏是想和大家分享一下自己学习强化学习的学习历程,希望对大家能有所帮助。这个系列后面会不断更新,希望自己在2021年能保证平均每日一更的更新速度,主要是介绍强化学习的基础知识,后面也会更新强化学习的论文阅读专栏。本来是想每一篇多更新一点内容的,后面发现大家上CSDN主要是来提问的,就把很多拆分开来了(而且这样每天任务量也小一点哈哈哈哈偷懒大法)。但是我还是希望知识点能成系统,所以我在目录里面都好按章节系统地写的,而且在github上写成了书籍的形式,如果大家觉得有帮助,希望从头看的话欢迎关注我的github啊,谢谢大家!另外我还会分享深度学习-基础知识专栏以及深度学习-论文阅读专栏,很早以前就和小伙伴们花了很多精力写的,如果有对深度学习感兴趣的小伙伴也欢迎大家关注啊。大家一起互相学习啊!可能会有很多错漏,希望大家批评指正!不要高估一年的努力,也不要低估十年的积累,与君共勉!
动态规划(DP)、蒙特卡罗(MC)、时间差分(TD)
Dynamic Programming(利用贝尔曼方程迭代)

其实把MC、TD都理解成DP的一种近似,只不过降低了计算复杂度以及削弱了对环境模型完备性的假设。
-
动态规划的使用条件:
- 最优化原理:如果问题的最优解所包含的子问题的解也是最优的,就称该问题具有最优子结构,即满足最优化原理。
- 无后效性:即某阶段状态一旦确定,就不受这个状态以后决策的影响。也就是说,某状态以后的过程不会影响以前的状态,只与当前状态有关
- 有重叠子问题:即子问题之间是不独立的,一个子问题在下一阶段决策中可能被多次使用到。(该性质并不是动态规划适用的必要条件,但是如果没有这条性质,动态规划算法同其他算法相比就不具备优势)
-
动态规划的步骤
-
划分阶段:按照问题的时间或空间特征,把问题分为若干个阶段。在划分阶段时,注意划分后的阶段一定要是有序的或者是可排序的,否则问题就无法求解。
-
确定状态和状态变量:将问题发展到各个阶段时所处于的各种客观情况用不同的状态表示出来。当然,状态的选择要满足无后效性。
-
确定决策并写出状态转移方程:因为决策和状态转移有着天然的联系,状态转移就是根据上一阶段的状态和决策来导出本阶段的状态。所以如果确定了决策,状态转移方程也就可写出。但事实上常常是反过来做,根据相邻两个阶段的状态之间的关系来确定决策方法和状态转移方程。
-
寻找边界条件:给出的状态转移方程是一个递推式,需要一个递推的终止条件或边界条件。
一般,只要确定了解决问题的阶段、状态和状态转移决策,就可以写出状态转移方程(包括边界条件)
-
-
动态规划三要素
- 问题的阶段
- 每个阶段的状态
- 从前一个阶段转化到后一个阶段之间的递推关系。
异步的动态规划:Asynchronous Dynamic Programming
在我们之前的算法中,我们每一次的迭代都会完全更新所有的参数,这样对于程序资源需求特别大。这样的做法叫做同步备份(synchronous backups)。异步备份的思想就是通过某种方式,使得每一次迭代不需要更新所有的参数,因为事实上,很多的也不需要被更新。异步备份有以下几种方案
-
In-place 动态规划所做的改进,是直接去掉了原来的副本 v k v_{k} vk, 只保留最新的副本(也就是说,在 一次更新过程中,存在着有些参数用的是 v k , v_{k}, vk, 有些参数用的是 v k + 1 v_{k+1} vk+1 )。具体而言,我们可以这样表示:
对于所有的状态s:
v ( s ) ← max a ∈ A ( R s a + γ ∑ s ′ ∈ S P s s ′ a v ( s ′ ) ) v(s) \leftarrow \max _{a \in A}\left(R_{s}^{a}+\gamma \sum_{s^{\prime} \in S} P_{s s^{\prime}}^{a} v\left(s^{\prime}\right)\right) v(s)←a∈Amax(Rsa+γs′∈S∑Pss′av(s′)) -
加权扫描动态规划:Prioritized Sweeping Dynamic Programming
Prioritized Sweeping 的思想是,根据某种方式,来确定每一个状态现在是否重要,对于重要的状态进行更多的更新,对于不重要的状态更新的次数就比较少。
- 更新顺序:可以使用priority queue 来有效的确定更新次序(按照优先权排队,每次把优先权最高的拿出来更新)
- 权重设计规则:可以使用Bellman error 来确定优先权,这个公式是通过两次的value的差异来作为state的评估标准,如果某个状态上次的value和这次的value相差不大,我们有理由认为他即将达到稳定,则更新他的价值就比较小,反之则比较大。具体公式如下:
max a ∈ A ( R s a + γ ∑ s ′ ∈ S P s s ′ a v ( s ′ ) − v ( s ) ∣ \max _{a \in A}\left(R_{s}^{a}+\gamma \sum_{s^{\prime} \in S} P_{s s^{\prime}}^{a} v\left(s^{\prime}\right)-v(s) \mid\right. a∈Amax(Rsa+γs′∈S∑Pss′av(s′)−v(s)∣
所以说,这个方法需要我们进行反向规划,因为我们需要知道当前状态之前的value是多少
- 实时动态规划:Real-Time Dynamic Programming
实时动态规划的思想是只有Agent现在关注的状态会被更新。与当前无关的状态暂时不被更新。
就比如我们在时间步t进入状态 S t S_{t} St ,进行动作 A t A_{t} At,结果是得到反馈 R t + 1 R_{t+1} Rt+1,那么我们要做的就是,仅仅更新 S t S_{t} St 的value function,公式如下:
v ( S t ) ← max a ∈ A ( R S t a + γ ∑ s ′ ∈ S P S t s ′ a v ( s ′ ) ) v\left(S_{t}\right) \leftarrow \max _{a \in A}\left(R_{S_{t}}^{a}+\gamma \sum_{s^{\prime} \in S} P_{S_{t} s^{\prime}}^{a} v\left(s^{\prime}\right)\right) v(St)←a∈Amax(RSta+γs′∈S∑PSts′av(s′))
- Full-Width Backups and Sample Backups
Full-Width 和 Sample Backups的区别在于更新状态时考虑的后继状态的个数的区别,他和同步DP,异步DP思考的是两个维度的优化方向。
- Full-Width Backups 介绍的是:当我们在考虑更新某一个state 的value function的时候,我们需要遍历这个state的所有可能的action,和每一个action所可能达到的后继state,这个遍历的开销非常大,对于每一次迭代,如果有m个action和n个state,则时间复杂度为 O ( m n 2 ) O\left(m n^{2}\right) O(mn2),也就是说,遍历次数会随着n而指数增长,这在大型的DP问题中,代价是无法接受的,所以提出了sample backups。
- sample backups 的思路是将state-to-state的过程进行采样,也就是说,我们以整个MDP < S , A , R , S ′ >
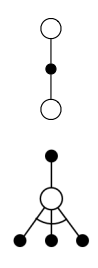
这样做有如下的优点:
- Model-free:一个非常重要的好处就是,由于我们不再需要计算所有的action可到达的状态,就意味着我们不需要使用状态转换概率矩阵,也就是说,我们不再需要提前完全搞明白环境的变化模型,这便是一个model-free的算法!
- 假设我们采样的个数为a,那么我们一次迭代的时间复杂度就是 O ( a m n ) O(a m n) O(amn) ,随着state的增加,我们的时间复杂度仅仅是常数增长。一定程度避免了维度灾难。
Monte-Carlo evalution(采样的一种办法)
蒙特卡罗方法是一种基于采样的方法,也就是我们采样得到很多轨迹,然后根据采样得到的结果平均去算V(s)
- MC simulation: we can simply sample a lot of trajectories, compute the actual returns for all the trajectories, then average them
- To evaluate state v ( s ) v(s) v(s)
- Every time-step t t t that state s is visited in an episode,
2. Increment counter N ( s ) ← N ( s ) + 1 N(s) \leftarrow N(s)+1 N(s)←N(s)+1
3. Increment total return S ( s ) ← S ( s ) + G t S(s) \leftarrow S(s)+G_{t} S(s)←S(s)+Gt
4. Value is estimated by mean return v ( s ) = S ( s ) / N ( s ) v(s)=S(s) / N(s) v(s)=S(s)/N(s),这里计算这个均值的时候,我们其实可以用Incremental Mean的方式,也就是新估计←旧估计+步长[目标−旧估计] v ( S t ) ← v ( S t ) + 1 N ( S t ) ( G t − v ( S t ) ) v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\frac{1}{N\left(S_{t}\right)}\left(G_{t}-v\left(S_{t}\right)\right) v(St)←v(St)+N(St)1(Gt−v(St))
By law of large numbers, v ( s ) → v π ( s ) v(s) \rightarrow v^{\pi}(s) v(s)→vπ(s) as N ( s ) → ∞ N(s) \rightarrow \infty N(s)→∞

Tempor-Difference learning
-
TD methods learn directly from episodes of experience
-
TD is model-free: no knowledge of MDP transitions/rewards
-
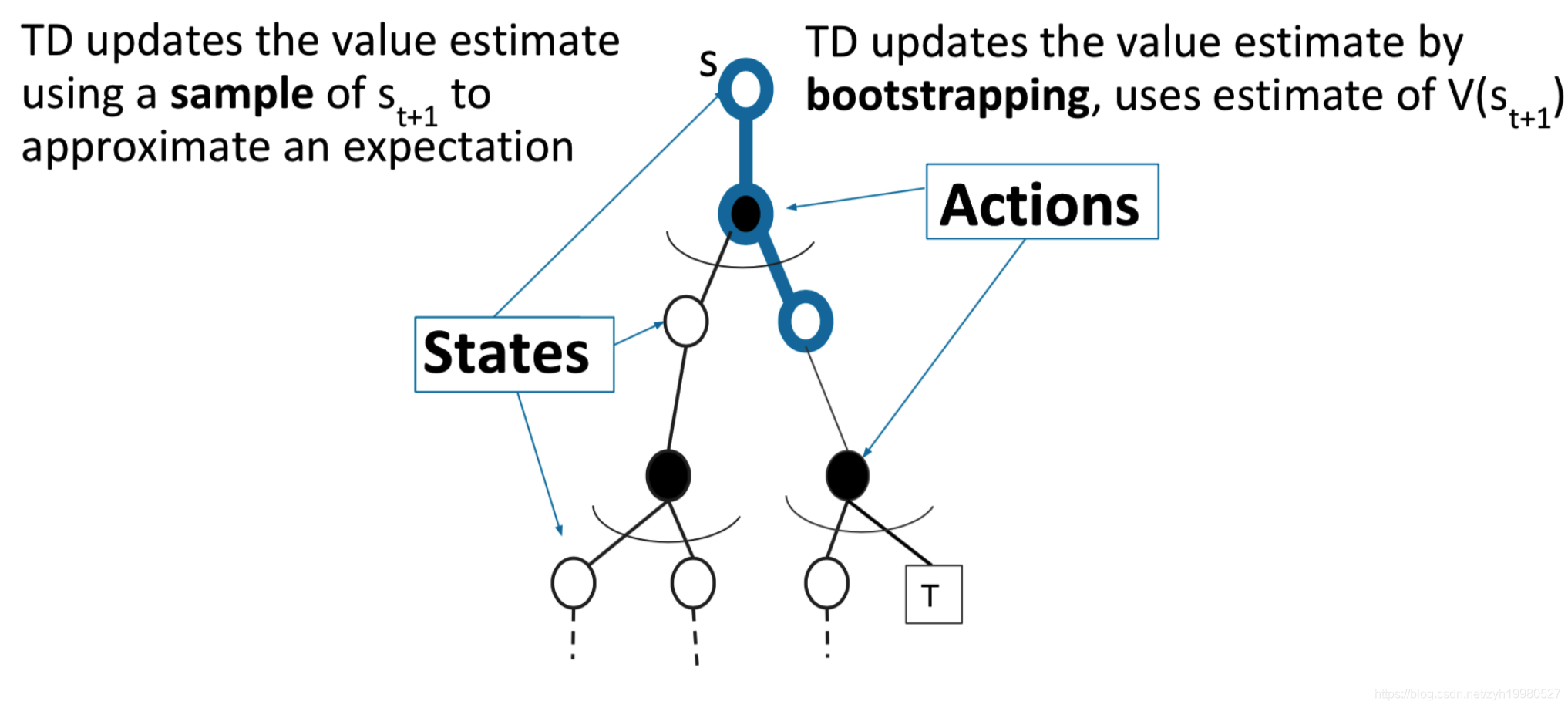
TD learns from incomplete episodes, by bootstrapping
-
Objective: learn v π v_{\pi} vπ online from experience under policy π \pi π Simplest TD algorithm: TD ( 0 ) \operatorname{TD}(0) TD(0) 也就是往前走一步进行估计
U Undate v ( S t ) v\left(S_{t}\right) v(St) toward estimated return R t + 1 + γ v ( S t + 1 ) R_{t+1}+\gamma v\left(S_{t+1}\right) Rt+1+γv(St+1)
v ( S t ) ← v ( S t ) + α ( R t + 1 + γ v ( S t + 1 ) − v ( S t ) ) v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\alpha\left(R_{t+1}+\gamma v\left(S_{t+1}\right)-v\left(S_{t}\right)\right) v(St)←v(St)+α(Rt+1+γv(St+1)−v(St))
R t + 1 + γ v ( S t + 1 ) R_{t+1}+\gamma v\left(S_{t+1}\right) Rt+1+γv(St+1) is called TD target
δ t = R t + 1 + γ v ( S t + 1 ) − v ( S t ) \delta_{t}=R_{t+1}+\gamma v\left(S_{t+1}\right)-v\left(S_{t}\right) δt=Rt+1+γv(St+1)−v(St) is called the TD error
Comparison: Incremental Monte-Carlo
v ( S t ) ← v ( S t ) + α ( G i , t − v ( S t ) ) v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\alpha\left(G_{i, t}-v\left(S_{t}\right)\right) v(St)←v(St)+α(Gi,t−v(St))
n-step TD
n-step TD像是控制n的大小在TD(0)和MC中找一个平衡
n = 1 ( T D ) G t ( 1 ) = R t + 1 + γ v ( S t + 1 ) n = 2 G t ( 2 ) = R t + 1 + γ R t + 2 + γ 2 v ( S t + 2 ) ⋮ n = ∞ ( M C ) G t ∞ = R t + 1 + γ R t + 2 + … + γ T − t − 1 R T \begin{array}{ll}n=1(T D) & G_{t}^{(1)}=R_{t+1}+\gamma v\left(S_{t+1}\right) \\ n=2 & G_{t}^{(2)}=R_{t+1}+\gamma R_{t+2}+\gamma^{2} v\left(S_{t+2}\right) \\ & \vdots \\ n=\infty(M C) & G_{t}^{\infty}=R_{t+1}+\gamma R_{t+2}+\ldots+\gamma^{T-t-1} R_{T}\end{array} n=1(TD)n=2n=∞(MC)Gt(1)=Rt+1+γv(St+1)Gt(2)=Rt+1+γRt+2+γ2v(St+2)⋮Gt∞=Rt+1+γRt+2+…+γT−t−1RT
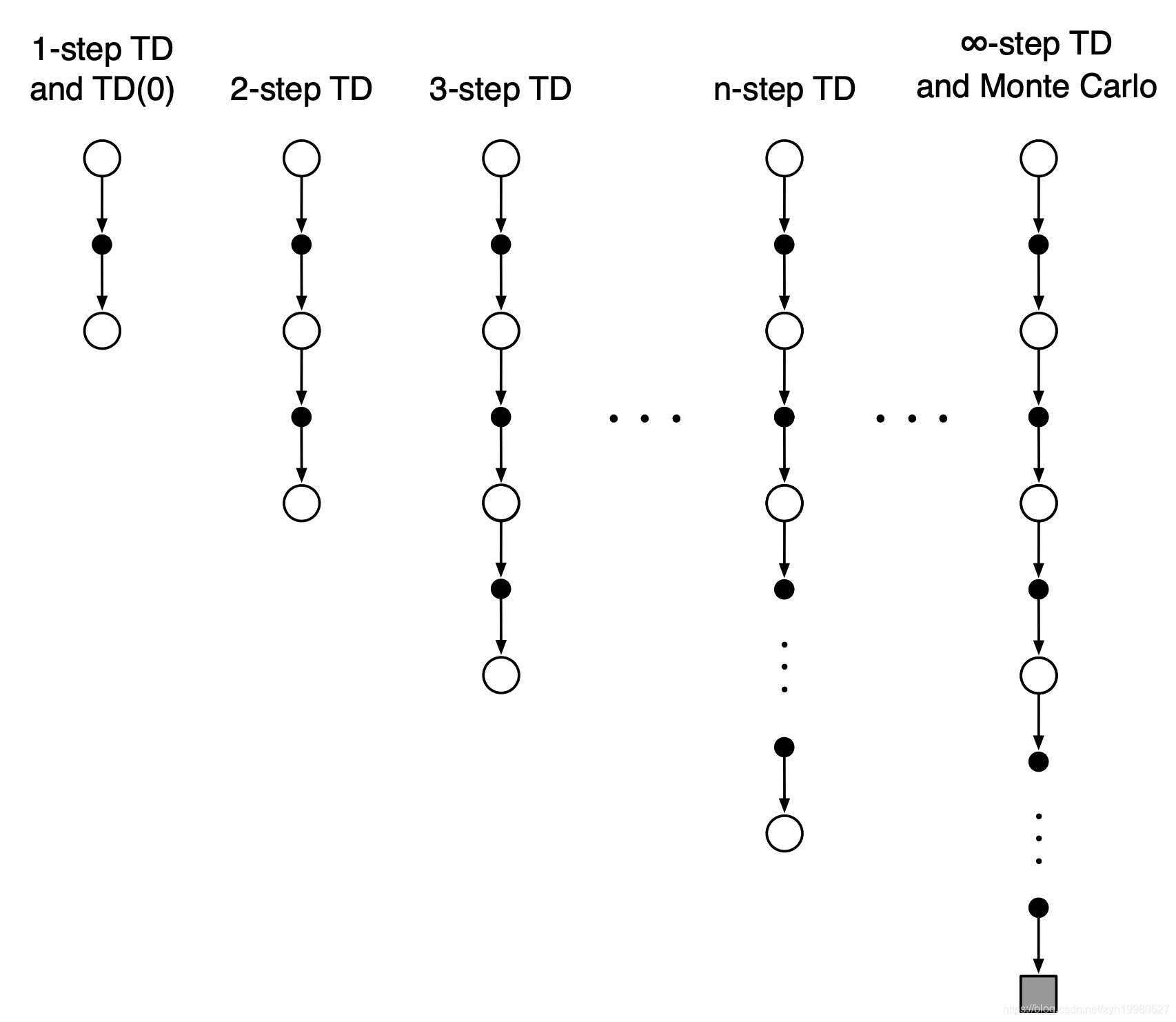
Thus the n-step return is defined as
G t n = R t + 1 + γ R t + 2 + … + γ n − 1 R t + n + γ n v ( S t + n ) G_{t}^{n}=R_{t+1}+\gamma R_{t+2}+\ldots+\gamma^{n-1} R_{t+n}+\gamma^{n} v\left(S_{t+n}\right) Gtn=Rt+1+γRt+2+…+γn−1Rt+n+γnv(St+n)
n-step T D : v ( S t ) ← v ( S t ) + α ( G t n − v ( S t ) ) \mathrm{TD}: v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\alpha\left(G_{t}^{n}-v\left(S_{t}\right)\right) TD:v(St)←v(St)+α(Gtn−v(St))
MC、DP以及TD算法的对比
Dynamic Programming ( D P ) (\mathrm{DP}) (DP) computes v i v_{i} vi by bootstrapping the rest of the expected return by the value estimate v i − 1 v_{i-1} vi−1
Iteration on Bellman expectation backup:
v i ( s ) ← ∑ a ∈ A π ( a ∣ s ) ( R ( s , a ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s , a ) v i − 1 ( s ′ ) ) v_{i}(s) \leftarrow \sum_{a \in \mathcal{A}} \pi(a \mid s)\left(R(s, a)+\gamma \sum_{s^{\prime} \in \mathcal{S}} P\left(s^{\prime} \mid s, a\right) v_{i-1}\left(s^{\prime}\right)\right) vi(s)←a∈A∑π(a∣s)(R(s,a)+γs′∈S∑P(s′∣s,a)vi−1(s′))
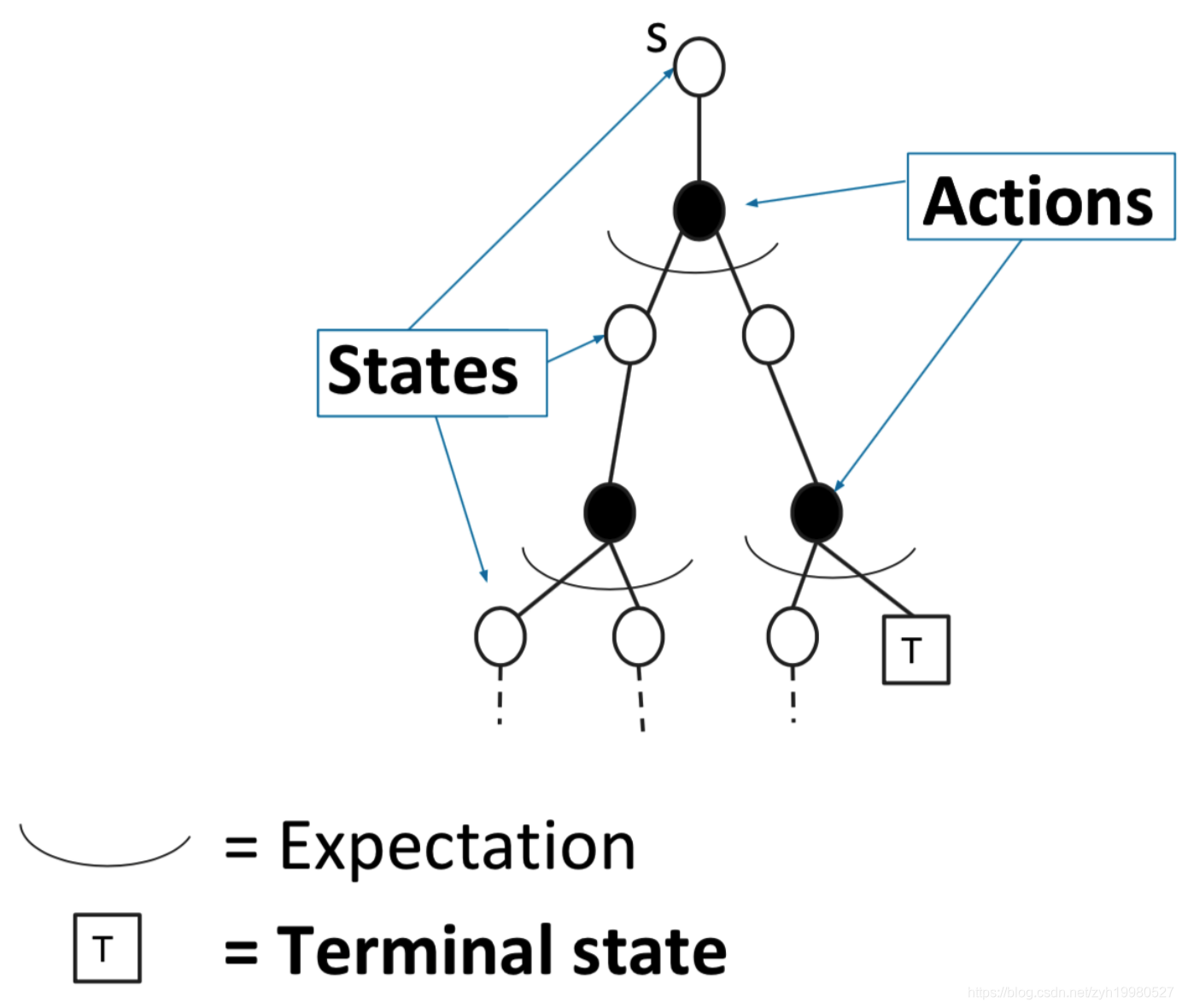
M C \mathrm{MC} MC updates the empirical mean return with one sampled episode
v ( S t ) ← v ( S t ) + α ( G i , t − v ( S t ) ) v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\alpha\left(G_{i, t}-v\left(S_{t}\right)\right) v(St)←v(St)+α(Gi,t−v(St))
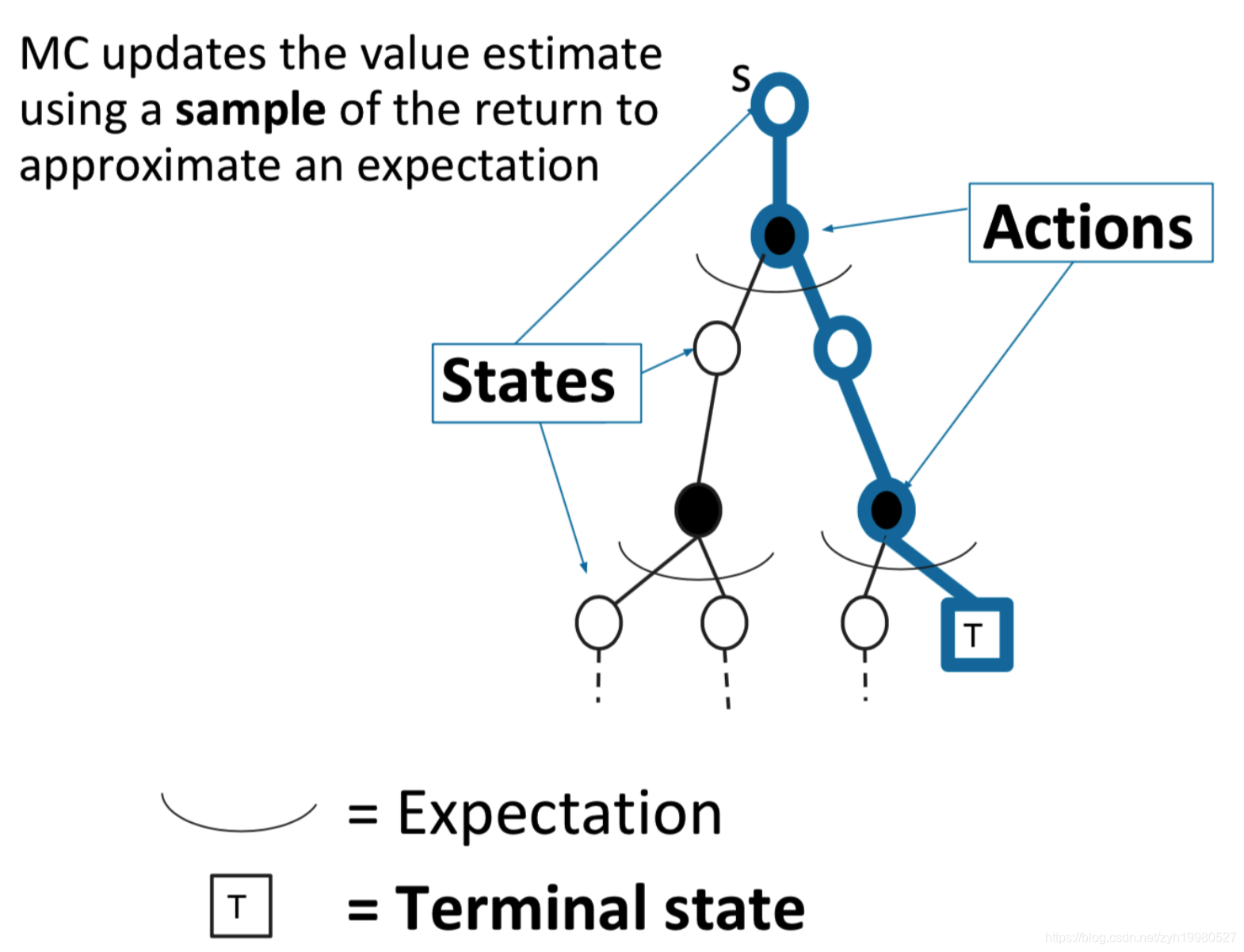
MC相比于DP的优点
- M C \mathrm{M} \mathrm{C} MC works when the environment is unknown
- Working with sample episodes has a huge advantage, even when one has complete knowledge of the environment’s dynamics, for example, transition probability is complex to compute
- Cost of estimating a single state’s value is independent of the total number of states. So you can sample episodes starting from the states of interest then average returns
TD相比于MC的优点
1、TD不需要等到epsilon结束后才学习(Incomplete sequences)
-
TD can learn online after every step
M C \mathrm{MC} MC must wait until end of episode before return is known -
TD can learn from incomplete sequences
M C \mathrm{M} \mathrm{C} MC can only learn from complete sequences -
TD works in continuing (non-terminating) environments
M C \mathrm{MC} MC only works for episodic (terminating) environment
2、TD在马尔科夫的环境中更有效(因为用了bootstraping)
- TD exploits Markov property, more efficient in Markov environments
M C \mathrm{MC} MC does not exploit Markov property, more effective in non-Markov environments
3、Lower variance
4、Online
-
总结:
-
- 由于MC的高方差,无偏差的特性,MC有以下几个特点:
- MC有更好的收敛性质。MC总能够很好的拟合函数(MC能够更容易接近真实的价值函数);
- 对初始化数据不敏感(因为他的标注是真实的,所以最后总会调整到正确的轨道上);
- 收敛速度比较慢
- 由于TD算法的有偏差,低方差的特性,TD有以下几个特点:
- TD通常速度比较快(因为数据的方差比较小,而我们一般认为收敛的准则是:当数据的波动比较小,则认为他收敛了);
- 但是对初始化数据比较敏感(如果有一个不好的初始化值,那么他虽然可以很快收敛,但不是收敛到正确的解);
是否有Bootstrapping和Sampling
- Bootstrapping:update involves an estimate
- MC does not bootstrap
- DP bootstraps
- TD bootstraps
- Sampling:update samples an expectation
- MC samples
- DP does not sample
- TD samples
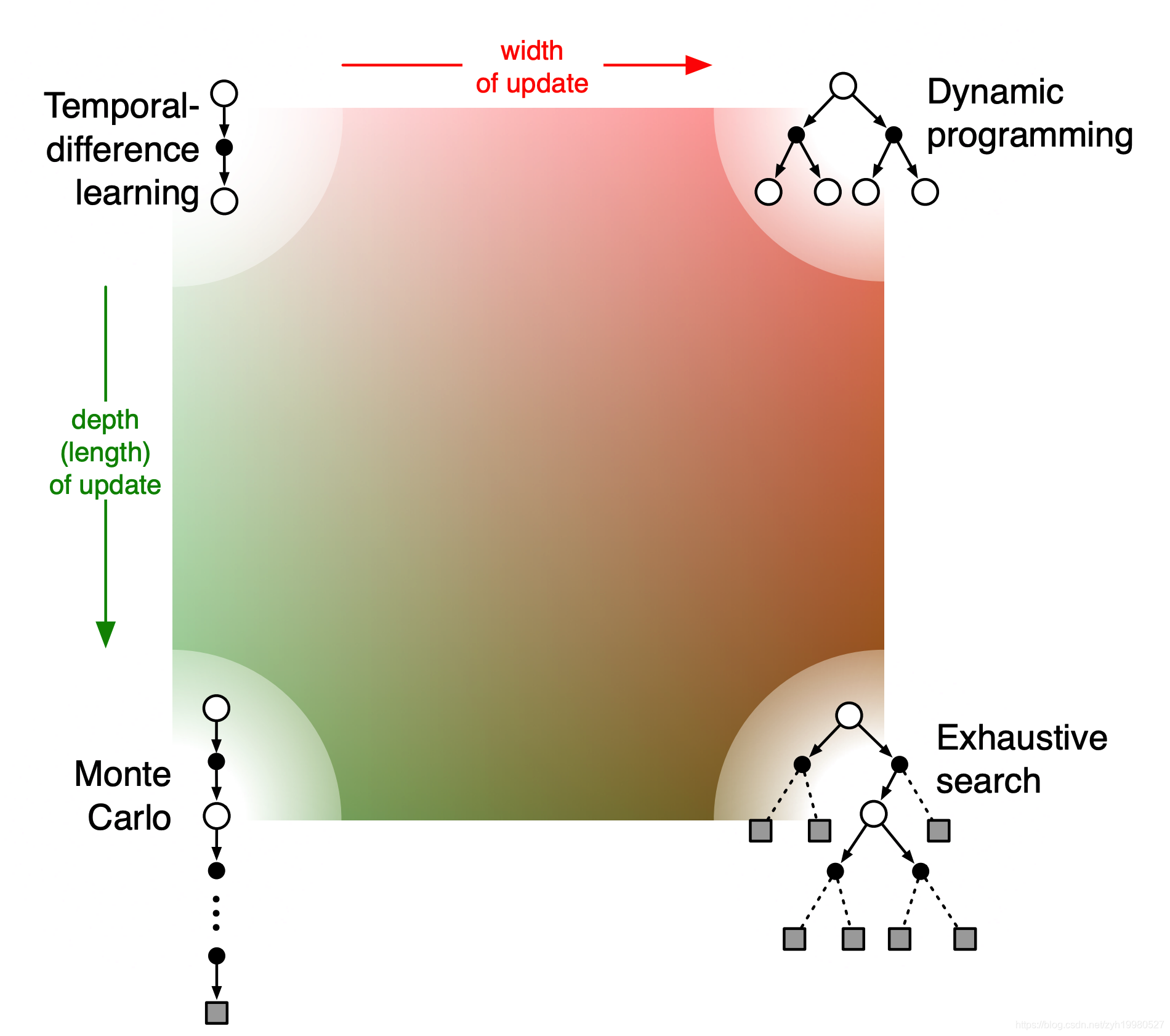
画图理解
DP: v ( S t ) ← E π [ R t + 1 + γ v ( S t + 1 ) ] v\left(S_{t}\right) \leftarrow \mathbb{E}_{\pi}\left[R_{t+1}+\gamma v\left(S_{t+1}\right)\right] v(St)←Eπ[Rt+1+γv(St+1)]
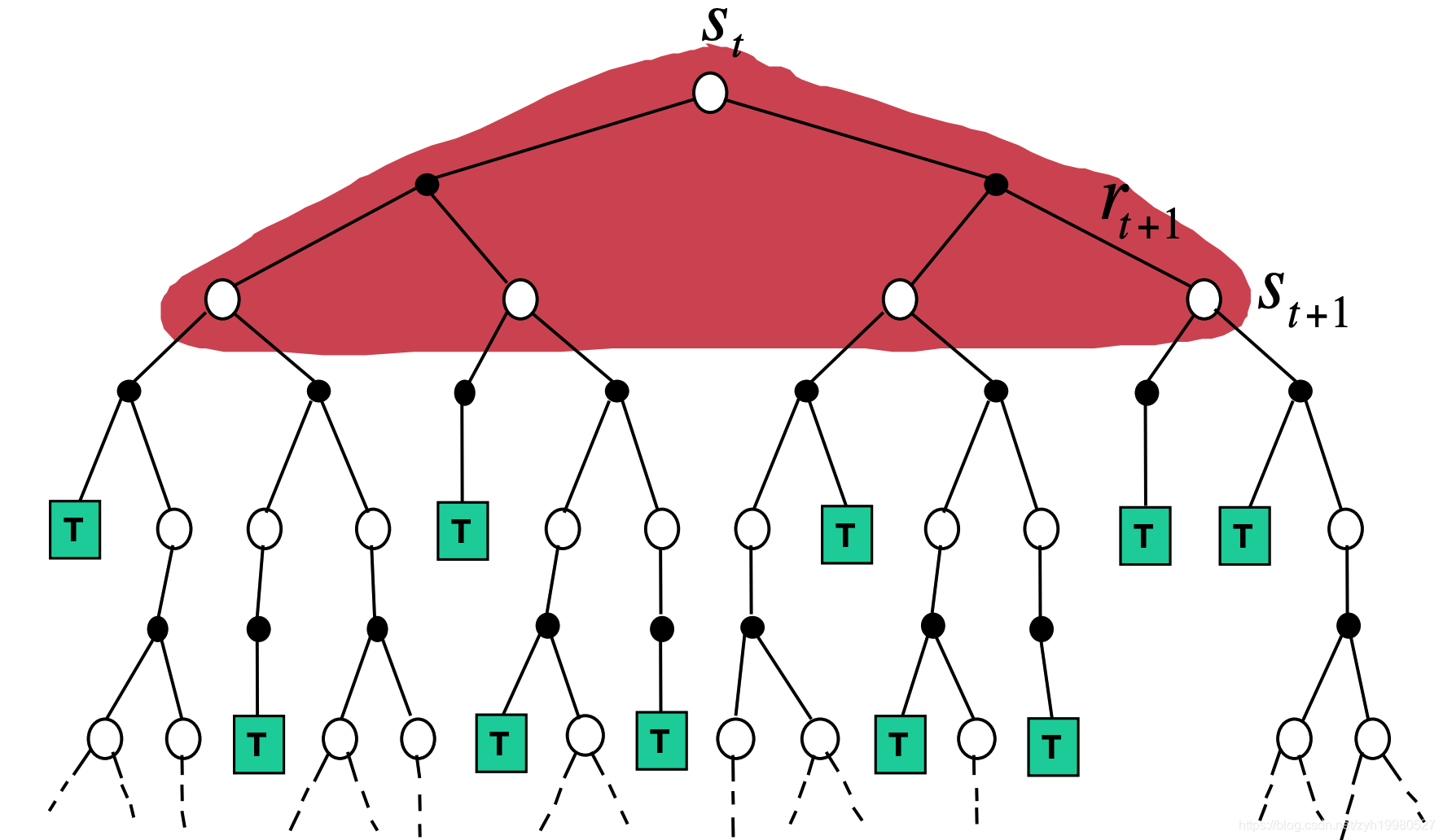
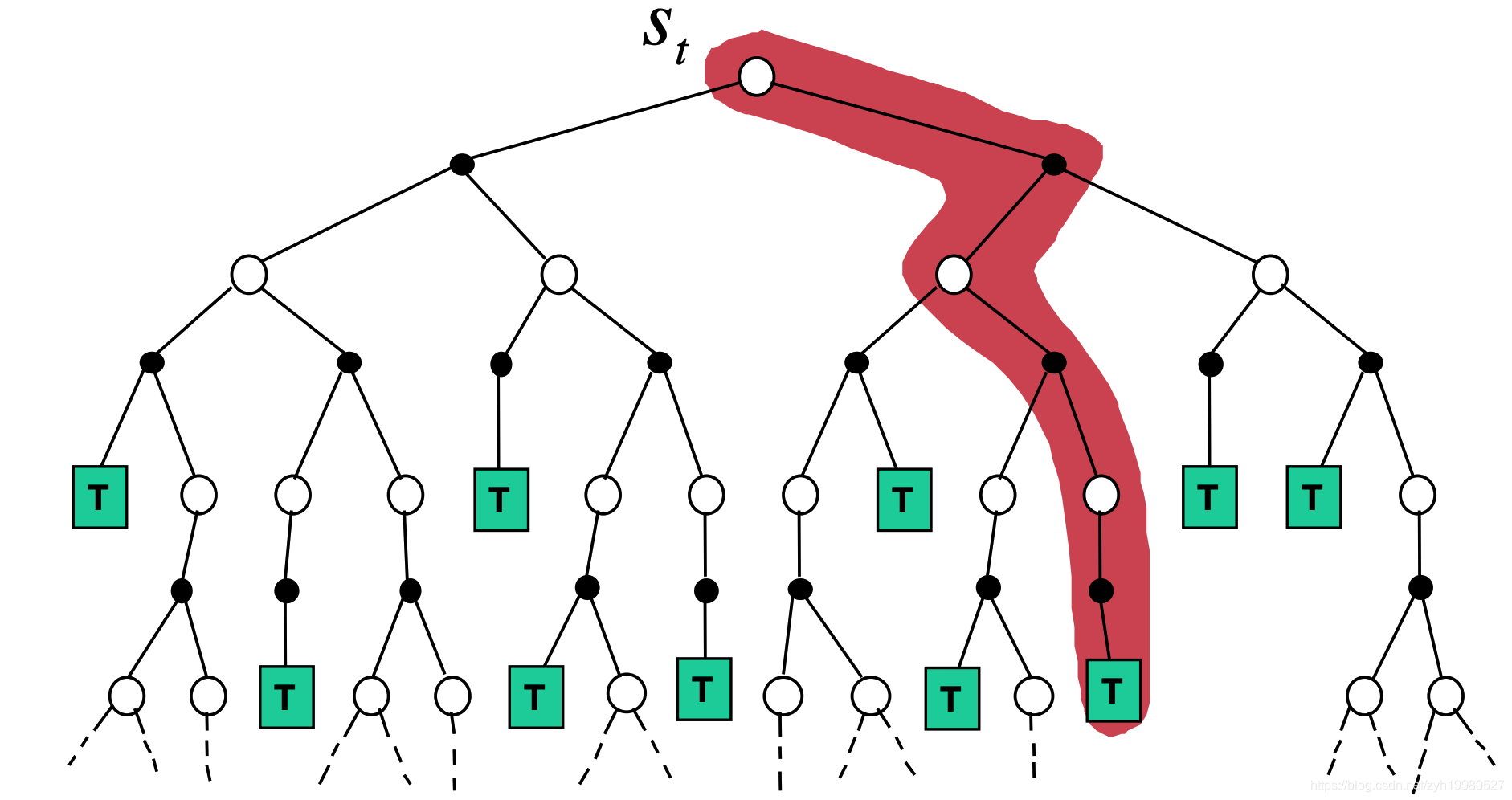
MC: v ( S t ) ← v ( S t ) + α ( G t − v ( S t ) ) v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\alpha\left(G_{t}-v\left(S_{t}\right)\right) v(St)←v(St)+α(Gt−v(St))
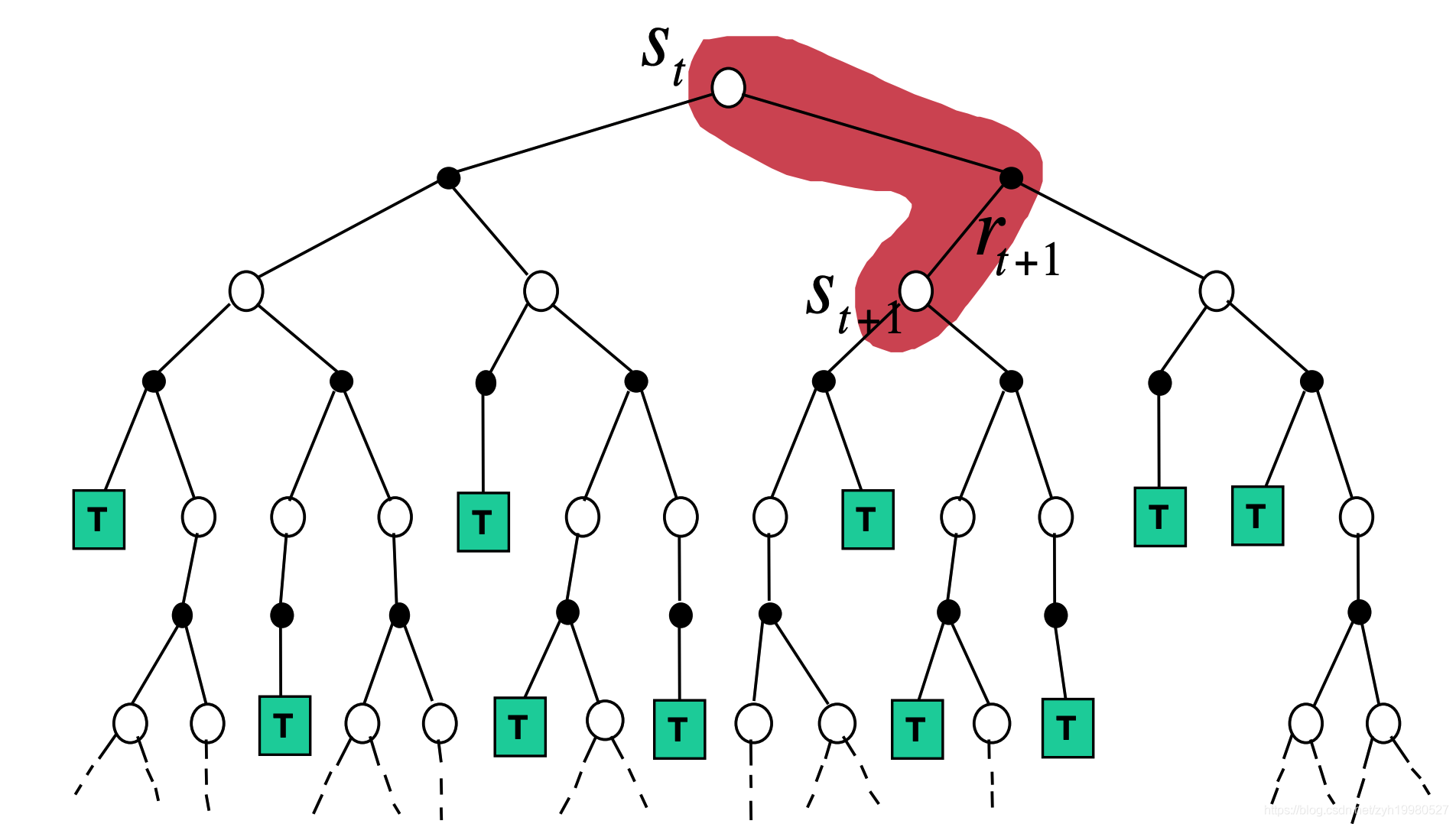
TD(0): T D ( 0 ) : v ( S t ) ← v ( S t ) + α ( R t + 1 + γ v ( s t + 1 ) − v ( S t ) ) T D(0): v\left(S_{t}\right) \leftarrow v\left(S_{t}\right)+\alpha\left(R_{t+1}+\gamma v\left(s_{t+1}\right)-v\left(S_{t}\right)\right) TD(0):v(St)←v(St)+α(Rt+1+γv(st+1)−v(St))
上一篇:强化学习的学习之路(十三)_2021-01-13:Policy Iteration和Value Iteration及其Python实现
下一篇:强化学习的学习之路(十五)_2021-01-15: Sarsa和Q-learning及其Python实现
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!