关于使用正则表达式解析网页内容
关于使用正则表达式解析网页内容
正则表达式用于对字符串进行操作,事先定义好特定的规则,利用这个规则对字符串进行过滤。对网页内容解析时,可以将源代码变为字符串,利用正则表达式进行匹配。
常见的正则字符和含义
| 模式 | 描述 | 模式 | 描述 |
|---|---|---|---|
| . | 匹配任意字符,除了换行符 | \s | 匹配空白字符串 |
| * | 匹配前一个字符0次或多次 | \S | 匹配任何非空白字符串 |
| + | 匹配前一个字符1次或多次 | \d | 匹配数字,等价于 [0-9] |
| ? | 匹配前一个字符0次或1次 | \D | 匹配任何非数字,等价于 [^0-9] |
| ^ | 匹配字符串开头 | \w | 匹配字母数字,等价于[A-Za-z0-9] |
| $ | 匹配字符串末尾 | \W | 匹配非字母数字,等价于[^A-Za-z0-9] |
| () | 匹配括号内的表达式,也表示一个组 | [] | 用来表示一组字符 |
正则表达式的三种方法
re.match方法
功能:从字符串起始位置匹配一个模式,若不能匹配则返回none
语法:re.match(pattern,string,flags=0),其中pattern是正则表达式,string为要匹配的字符串,flags用来控制正则表达式的匹配方式,如是否区分大小写、多行匹配等。
举例:
import re
m = re.match('www','www.baidu.com')
print("匹配结果: ",m)
print("匹配起点与终点: ",m.span())
print("匹配起点: ",m.start())
print("匹配终点: ",m.end())
得到的结果为:

re.search方法
功能:扫描整个字符串并返回第一个成功的匹配
语法:与re.match类似
举例:
import re
m1 = re.search('cat','A cat is a cat')
print("匹配结果: ",m1)
print("匹配的起点与终点: ",m1.span())
print("匹配起点: ",m1.start())
print("匹配终点: ",m1.end())
得到的结果为:

与match方法不同的是,match方法只能从字符串起始位置开始匹配,search用起来则更加灵活。
re.findall方法
功能:找到所有满足条件的匹配
举例:
import re
m_match = re.match('[0-9]+','12345 is the first number, 23456 is the second')
m_search = re.search('[0-9]+','12345 is the first number, 23456 is the second')
m_findall = re.findall('[0-9]+','12345 is the first number, 23456 is the second')
print(m_match.group())
print(m_search.group())
print(m_findall)
得到的结果为:
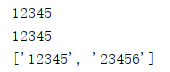
用正则表达式解析网页内容不是很难,关键在于找到合适的匹配规则。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!