我和Tensorflow的美丽邂逅——一起来训练Y=Weights*X+bias吧
我最近发现,结合一些实际的小程序,小项目来学习Tensorflow效率比较高,那么今天我就和大家一起来建立一个最简单的神经网络来预测一个线性分布的数据,然后在程序中一些函数我会再发博文详细学习它们
情景:假设我们的训练数据集满足关系:y = 0.1*x + 0.3
- 第一步:先导入我们需要的库
import tensroflow as tf
import numpy as np- 第二步:得到我们的数据集
x_data = np.random.rand(100).astype(np.float32)
y_data = 0.1*x_data + 0.3- 第三步:定义权重,偏置以及我们的预测值y
Weights = tf.Variable(tf.random_uniform([1],-1.0,1.0)) #random_uniform是一个用于生成在指定区间内均匀分布的数据的函数
"""
tf,random_uniform()用于生成指定大小的,比如说[1]就是一个数在给定区间内的均匀分布的数值
如果是[2,2]就是生成一个2x2的矩阵,矩阵中的所有数字都是在给定的区间内均匀分布
"""
bias = tf.Variable(tf.zeros[1]) #偏置先设置为0
y = Weight * x_data + bias- 第四步:定义损失值
何谓损失值,就是衡量我们预测的值和真实值差距的一种方式
下面列出三种常用的损失函数
-
1. 0-1损失函数
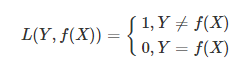
-
2. 绝对值损失函数
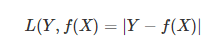
-
3. 均方误差损失函数
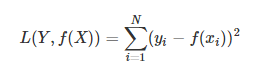
下面我们使用的是第三种损失函数:
loss = tf.reduce_mean(tf.square(y - y_data)) #损失函数使用的是均方误差损失函数,reduce_mean()是取均值,tf.square()是求平方- 第五步:优化
optimizer = tf.train.GradientDescentOptimizer(0.5) #采用梯度下降,学习率为0.5
train = optimizer.minimize(loss)- 第六步:变量初始化
我们在tensorflow中定义了变量之后,一定要有一个初始化的过程
init - tf.initialize_all_variables()- 第七步:创建Session,开始训练
with tf.Session() as sess:sess.run(init)for step in range(201):sess.run(train)if step % 20 == 0:print(step, sess.run(Weights), sess.run(bias))下面是完整代码:
import tensroflow as tf
import numpy as npx_data = np.random.rand(100).astype(np.float32)
y_data = 0.1*x_data + 0.3Weights = tf.Variable(tf.random_uniform([1],-1.0,1.0))
bias = tf.Variable(tf.zeros[1]) #偏置先设置为0
y = Weight * x_data + biasloss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)init - tf.initialize_all_variables()with tf.Session() as sess:sess.run(init)for step in range(201):sess.run(train)if step % 20 == 0:print(step, sess.run(Weights), sess.run(bias))我们让它每隔20次训练就打印一次Weights和bias的值,我们来看看它们的变化情况:
0 [-0.03887308] [0.5013835]
20 [0.056104] [0.3227819]
40 [0.08995082] [0.3052155]
60 [0.09769945] [0.30119398]
80 [0.09947332] [0.30027336]
100 [0.09987942] [0.3000626]
120 [0.0999724] [0.30001435]
140 [0.0999937] [0.3000033]
160 [0.09999855] [0.30000076]
180 [0.09999967] [0.3000002]
200 [0.0999999] [0.30000007]
我们可以看到,在第200次训练之后,我们的Weights值已经很接近0.1,bias的值也很接近0.3了
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!