线上GO服务出现GC故障,我当时就急了
文章目录
- 前言
- 日志/监控排查
- GC问题是怎么影响系统的
- 一系列的应对手段
- 添加GC trace
- 利用pprof排查
- 内存分配排查
- trace信息排查
- 解决方案
- 结语
- 未解之谜
前言
新公司工作小半年了,线上系统没出过什么大问题,一直很稳定。但凡事总不可能一帆风顺,最近运维的监控群里,时不时的就会报服务健康检查警告
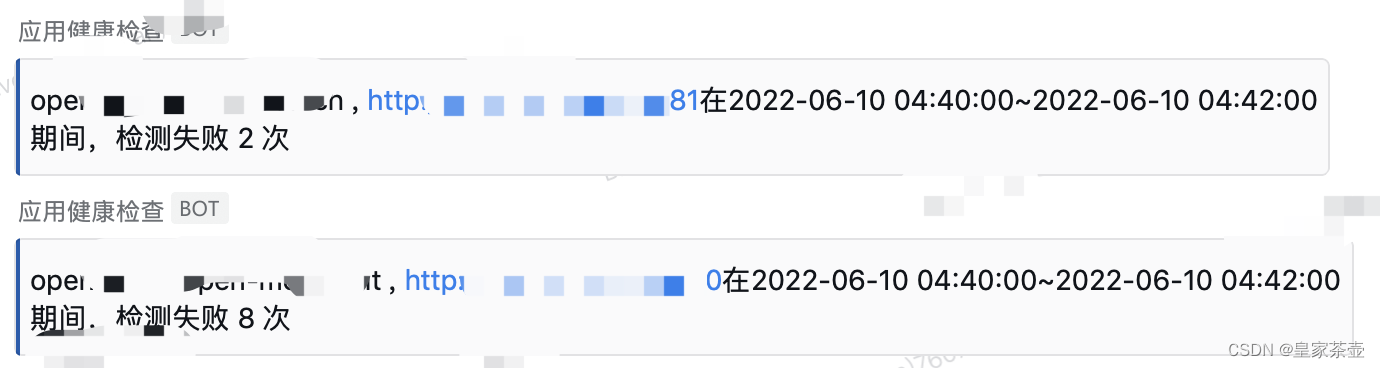
如果一次两次还可以理解为网络波动。但是这段时间,我们小组的几个服务一直在被告警“点名“,上游的同事也在群里反馈请求错误异常增多,这下就有点坐不住了…立马着手开始排查问题。
日志/监控排查
通常上游出现异常,第一反应基本就是查询错误日志,观察系统监控。那么笔者从业务日志上观察并未发现比较异常的点,但是在Grafana指标监控中发现了Go服务中某个实例GC异常升高(下图是是正常时候的状态,有问题的部分没有截上),问题实例的GC时间最高的时候甚至飙到了10s以上!!
GC异常升高的时间点也能够对应上报警时间,那么问题大概率是出现在GC上了。
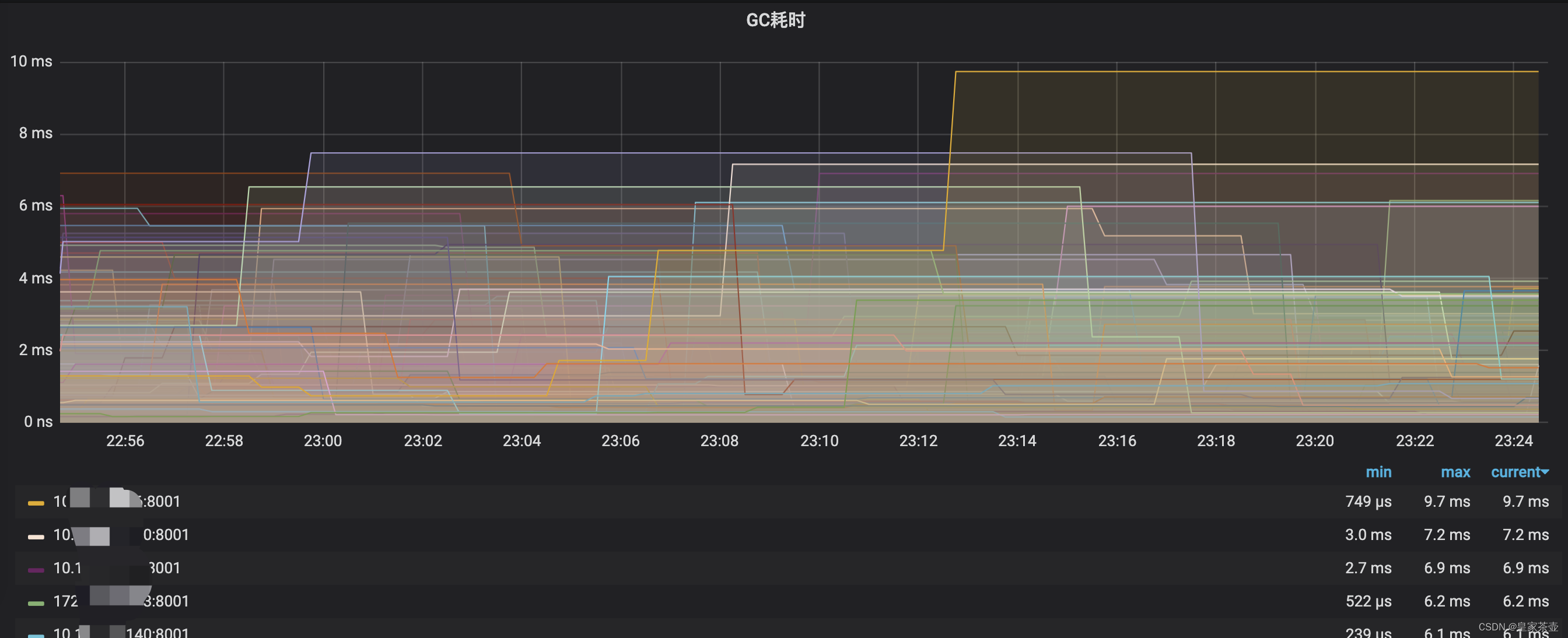
一般来说项目运行很少会出现GC问题,但是一旦出现,那么一般都会让人比较头疼…
GC问题是怎么影响系统的
正常来说,go服务后台的GC策略一般不会影响用户体验,但是Go的GC过程有一个STW(stop the word)的过程,如果这一步卡住了,那么问题就大了,stw顾名思义,整个系统相当于挂起了。这就是上游为什么大周末还在工作群里疯狂@的原因。系统挂起,服务没有了响应,这还了得?
关于go服务的GC工作原理,本文就不详细阐述了,有兴趣的同学可以自行谷歌学习一下。
一系列的应对手段
添加GC trace
在项目中执行如下命令
export GODEBUG=gctrace=1
该命令可以将程序运行的trace信息打印出来,其中就有我们比较关心的GC信息
gc 148069 @874092.011s 0%: 0.15+63+0.073 ms clock, 3.7+14/365/923+1.7 ms cpu, 1930->1957->999 MB, 1979 MB goal, 24 P
gc 148070 @874095.521s 0%: 0.13+73+0.009 ms clock, 3.2+140/401/809+0.23 ms cpu, 1948->1985->1009 MB, 1998 MB goal, 24 P
gc 148071 @874098.131s 0%: 0.14+60+0.020 ms clock, 3.4+5.2/328/856+0.49 ms cpu, 1969->1990->1007 MB, 2019 MB goal, 24 P
gc 148072 @874100.934s 0%: 0.12+56+0.028 ms clock, 3.0+8.0/335/861+0.69 ms cpu, 1965->1993->1002 MB, 2015 MB goal, 24 P
gc 148073 @874104.399s 0%: 0.11+55+0.009 ms clock, 2.7+43/315/791+0.22 ms cpu, 1954->1973->991 MB, 2004 MB goal, 24 P
gc 148074 @874107.953s 0%: 0.18+57+0.086 ms clock, 4.4+25/334/814+2.0 ms cpu, 1933->1966->1005 MB, 1983 MB goal, 24 P
简单解释一下打印出来的信息
gc 148069: 这是第148069次gc。
@874092.011s: 这次gc的markTermination阶段完成后,距离runtime启动到现在的时间。
0%:当目前为止,gc的标记工作(包括两次mark阶段的STW和并发标记)所用的CPU时间占总CPU的百分比。
0.15+63+0.073 ms clock:按顺序分成三部分,0.15表示mark阶段的STW时间(单P的);63表示并发标记用的时间(所有P的);0.073表示markTermination阶段的STW时间(单P的)。
3.7+14/365/923+1.7 ms cpu:按顺序分成三部分,3.7表示整个进程在mark阶段STW停顿时间(0.15 * 24);14/365/923分为3部分,14是mutator assists占用的时间,365是dedicated mark workers + fractional mark worker占用的时间,923是idle mark workers占用的时间。这三块时间加起来会接近2.9*8(P的个数);1.7 ms表示整个进程在markTermination阶段STW停顿时间(0.073 * 24)。
1930->1957->999 MB:按顺序分成三部分,1930表示开始mark阶段前的heap_live大小;1957表示开始markTermination阶段前的heap_live大小;999表示被标记对象的大小。
1979 MB goal:表示下一次触发GC的内存占用阀值是1979MB。
24 P:本次gc共有多少个P。
初步观察过后,我们发现进程的STW时间很长,最长的甚至超过数千ms。
利用pprof排查
内存分配排查
我们知道,程序的运行离不开内存,例如创建变量,调用函数,数据计算等等,程序运行过程中需要内存的时候就会去申请内存。内存的申请与管理在GO语言中是自动管理的,不需要开发者过多的干涉。
同市面上大多数带GC回收的语言一样,Go语言所管理的虚拟内存空间一般分为两部分:堆内存和栈内存。一般分配到栈上的内存回随着系统的运行即使获取和释放(代码段和一些不是很大的局部变量都会分配到栈内存上),故而栈内存一般不需要怎么去管,由系统自行分配管理,这部分也不会对GC有很大影响。
而堆内存才是我们重点需要关注的对象,程序的大部分数据都分配在堆内存上,大部分的程序内存占用也都是在堆内存上。
故而我们的第一反应就是看看能不能把运行中内存申请比较多的程序片段找到并列举出来。
对于Go服务来说,官方自带的分析工具pprof正好可以用来干这个事儿。pprof一般的用法是查看CPU耗时火焰图,内存占用图。它的原理是在go服务运行时,每隔一段时间记录程序当前走到的代码行,称之为“采样”。
pprof火焰图(图片源自网络)
幸运的是,目前我们项目的Go 服务中都默认开放了一个调试接口/debug/pprof/profile,通过调用接口,调用后会开启一段时间采样,通过seconds参数调整采样时间,采样越久数据越准确。采样完会导出一个profile文件供分析。
如果项目中没有使用pprof也没关系,因为是官方自带,所以集成起来十分的容易。有兴趣的同学可以自行谷歌一下集成教程。
进入容器,通过git拉取一份项目代码(这一步是必要的,这样pprof才能通过源码获得细粒度的耗时,否则你只能获得方法级别的耗时信息,语句级别的就看不到了, 同时需要注意源码要和你build出来的二进制文件路径一致)。执行下面命令
# 分配内存采样
/usr/local/go/bin/go tool pprof 'http://localhost:8000/debug/pprof/allocs'
此时pprof会进行采样读取,之后我们会进入pprof的命令行界面。通过使用top 20命令,我们可以看到分配内存最多的前20个方法
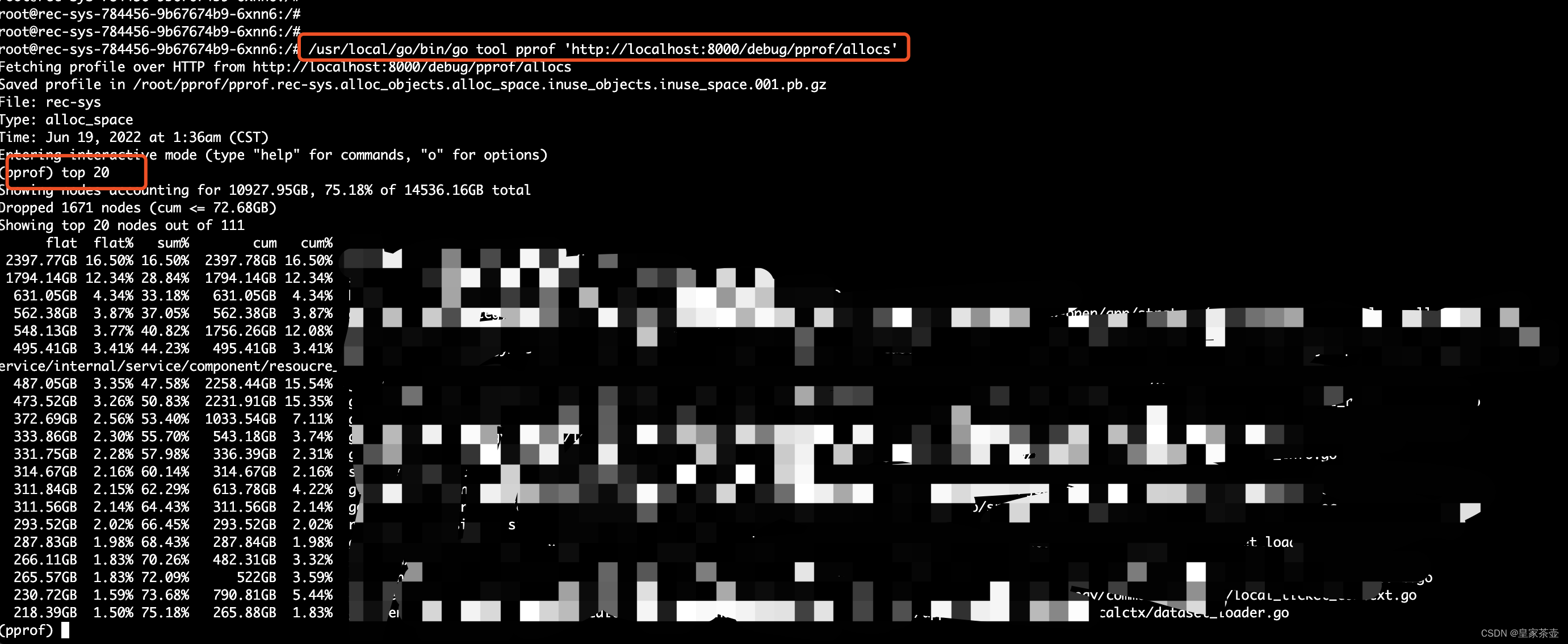
我们使用list [方法名]的命令进一步查看方法内部的内存分配明细。

到了这一步,我们基本上可以把内存申请最多的代码片段都一一找到了。下一步,就是开始优化。这里笔者把优化点直接列出来,这些优化点也是平时写Go代码时需要注意的点,千万不要一不小心就写出了容易造成隐患的代码,为以后排查埋下伏笔 : (
trace信息排查
pprof支持排查方式很多,除了内存分配,我们还可以采样程序运行的trace信息,拉取采样文件进行解析。
# 刚才是/debug/pprof/allocs, 现在我们抓取trace信息
curl -o /tmp/trace.data 'http://127.0.0.1:8000/debug/pprof/trace?seconds=60'
这会生成一份trace数据文件,我们把文件拉到本地,运行
go tool trace trace.data
这会在本地启动一个trace服务,用于展示采样数据。
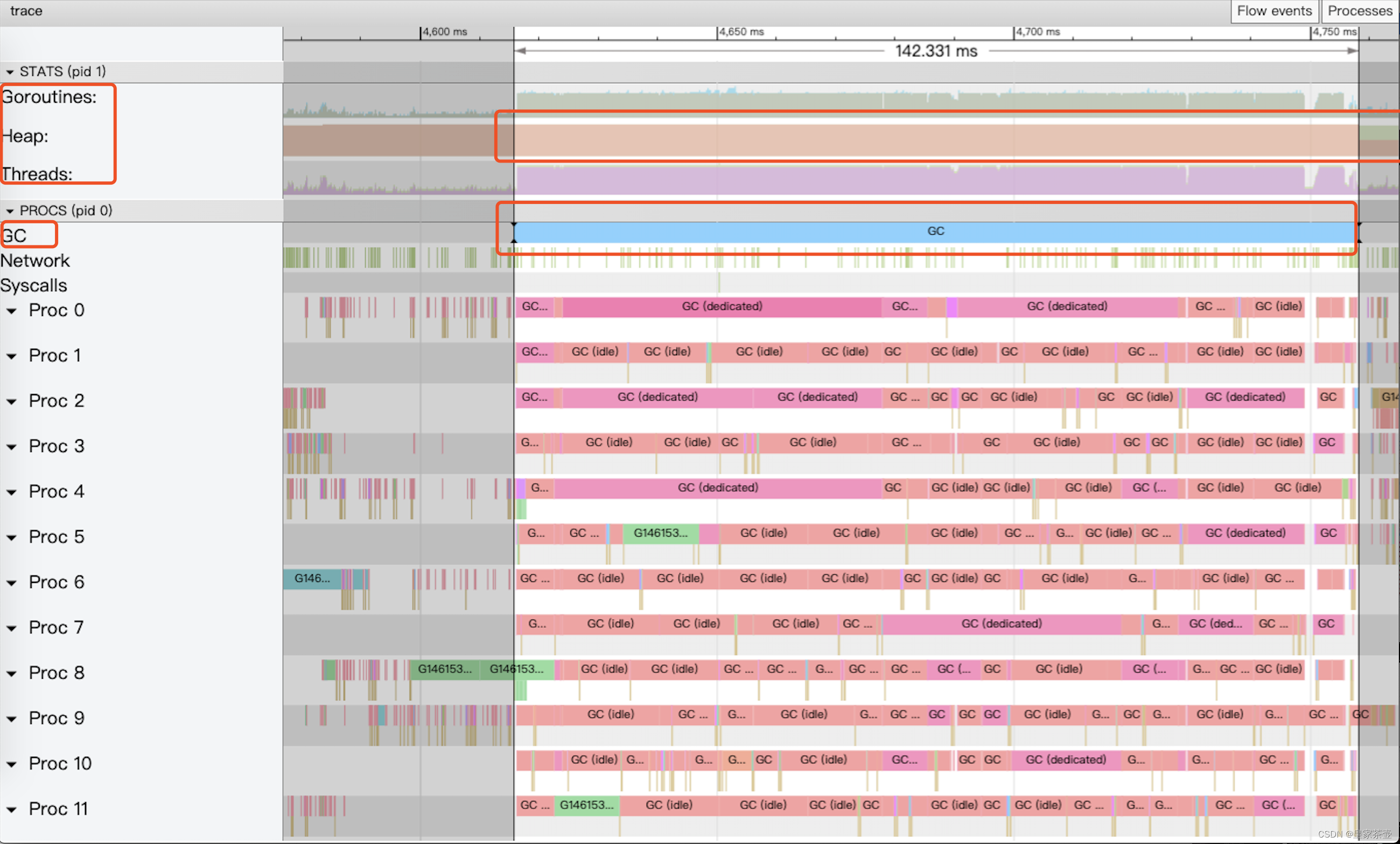
右侧的proc对应gctrace中P的数量,这张图展示了程序的运行轨迹。目前我们只关心GC(注意画红圈)的部分,想对GC trace有一个详细了解的话,可以看看这篇文章,本篇专注于解决问题~~
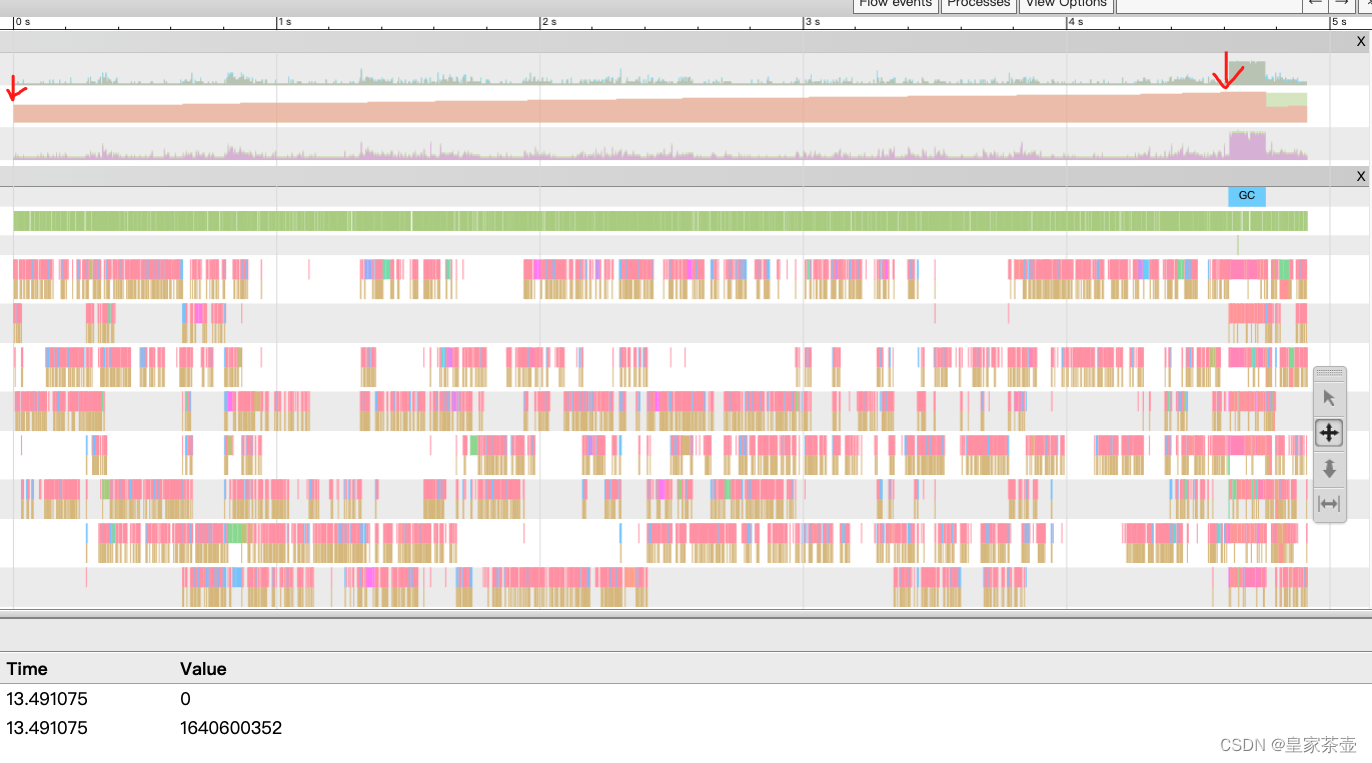
箭头所在位置是程序heap内存,可以看到heap到达阈值(第二个箭头处),发生了GC(蓝色横柱部分),GC完成后,heap内存下降了一半。(很合理,但是也说明这段采样没有抓到问题部分)

这玩意儿采样有一定的运气成本在里面,不多采几遍不一定能采样到STW异常的代码片段。多次采样之后,我们发现了一段包含较长STW的采样信息。随即针对STW期间其他P还处于运行中的代码进行了进一步排查。
解决方案
-
Map,Slice初始化设置长度
我们通常会使用make方法来初始化slice和Map,如果不设置长度并且添加的元素很多的话,可能会造成slice或者map频繁的扩容和申请内存。所以一般初始化之前我们都要对长度进行预估并一次性分配好容量大小。 -
大对象复制/未使用指针
在项目启动阶段,我们会预加载商品数据到系统内存当中,每一个商品的信息十分复杂(商品信息,各类打分信息,关联关系等),这样一个商品的结构体是很大的。而加载好之后,我们一般也就是用来查询,不会去做修改。原来我们再获取商品信息时,返回是一个完整的结构体而非指针,这就导致了很多无意义的内存拷贝,会对GC造成不小的负担。实际上在排查过程中,这种大结构体复制导致的内存分配过多是非常明显的(至少top3),改成返回指针之后,情况立马好转了许多。
另外多一句嘴,如果数据结构体很小,或者干脆就是一些基本数据,int,string之类的话,就没必要使用指针了,直接使用原数据反而会获得更好的性能。
-
IO阻塞 readAll
项目启动前会加载商品数据,这些数据是通过读取商品数据文件获得。我们再检查内存分配的过程中,发现内存分配很大的一个方法是io.ReadAll

很显然,经过一番定位,发现使用到这个方法的就是读取商品文件。可以看到,项目读取文件采用的是一次性读取,通常情况下,这不会产生问题。但经过调研,我们发现这样的读取也有引发GC问题的隐患(在上文提到的trace信息查看STW较长部分,也看到了读取文件的代码身影)。详情可以参考这个Issue:runtime: ioutil.ReadFile when reading big files may cause long STW pauses最终的修改方案也很简单,改为流式读取就好了。
-
k8s容器下process设置不当
由于项目是运行在k8s容器当中,众所周知,Go底层通过调度器GMP实现轻量级协程(如果对GMP调度过程感兴趣,可以看看这篇文章),其中P(process)通常会和机器的CPU核数设置成一样。但是运行在k8s下的Go项目,会把P设置成和机器总核数一致,而不是我们分配给容器的核数,首先这会导致频繁调度,其次这也会引发GC问题。 这篇文章对这个现象解释的很少,可以一看,本文就不再赘述。解决方案比较简单,项目中使用Uber的库
automaxprocs就可以解决P设置与分配核数不一致的问题。
结语
一顿猛如虎的操作之后,程序整体的GC时间下降了80%,这下终于能睡个好觉了~❤️
然而…
未解之谜
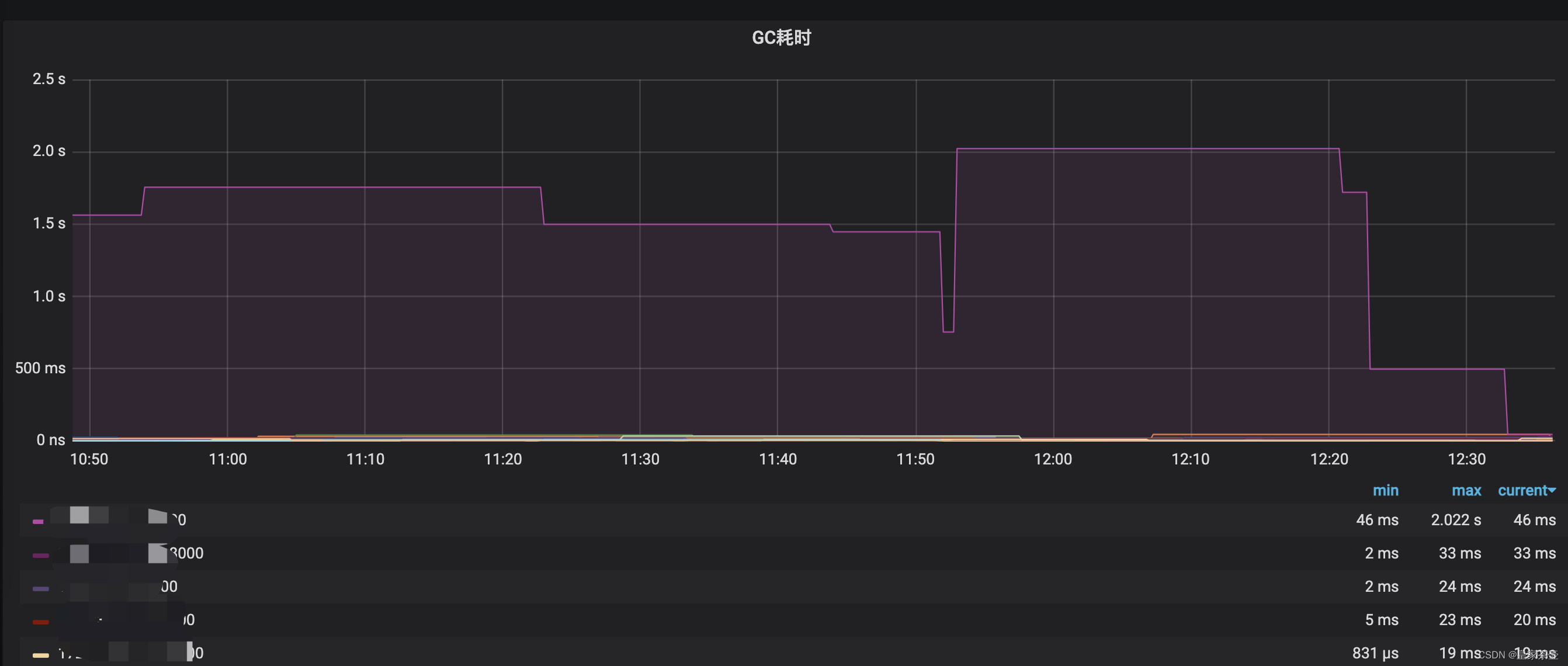
虽然进行了优化,但我们也加上了对GC耗时的报警监控。如上图,我们发现个别k8s容器的GC时间仍然会到达秒级以上?对于这个问题笔者至今仍然没有特别好的解决方案。同事猜测可能是物理机混合部署,其他程序抢占资源导致项目GC时间异常上升。
小伙伴们怎么认为呢?

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!