OPTICS聚类(最清晰解释)
背景
想要理解该算法,你需要先了解:
- DBSCAN算法
OPTICS(用于识别聚类结构的排序点)算法与 DBSCAN 算法有许多相似之处,可视为 DBSCAN 的泛化,将 eps 要求从单个值放宽到一个范围
DBSCAN 和 OPTICS 之间的主要区别在于,OPTICS 算法构建了一个可reachability graph,为每个样本分配一个reachability_距离,和在群集ordering_属性中的一个点; 这两个属性在拟合(fit)模型时分配,并用于确定cluster的成员
如果 OPTICS 在运行的时候把 max_eps 参数设置为默认值 inf,则可以用cluster_optics_dbscan方法对任何给定的eps值在线性时间重复执行 DBSCAN 样式群集提取。将max_eps设置为较低的值将导致较短的运行时间,并可视为每个点在查找其他潜在的可到达点时所采用的最大邻域半径。
这个算法不像其他算法,直接将数据切分成不同的块。它是给出了一个点的可达距离图像,然后从图像上,我们可以对数据进行切分聚类。
必备概念
核心点、噪声点、边缘点的概念请参考DBSCAN。
核心距离:使得 x 成为核心点的最小邻域半径称为 x 的核心距离。
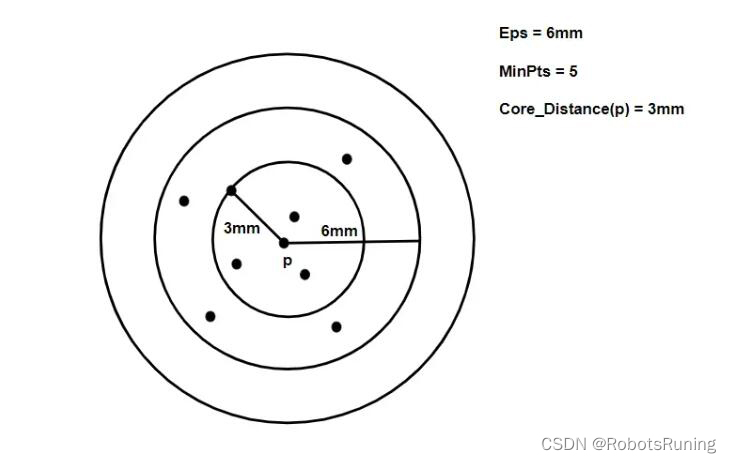
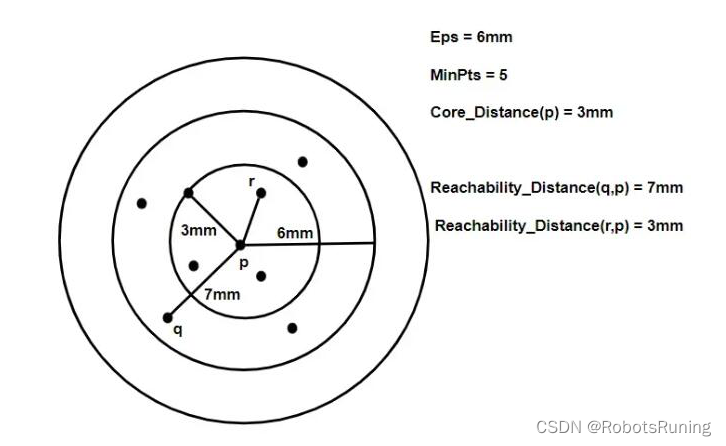
可达距离:假设 q是核心点。那么点 p和点 q 的可达距离定义为:
简而言之,就是p 的核心距离“以及“ p和 q 的实际距离”的最大值。这里DistanceMetric 指任意距离衡量函数。
ε :表示最大半径。
MinPts:描述形成集群所需的点数。
Nε(p):点 p 的邻域。
算法解释
这是主函数:
## OPTICS算法
## DB: 原始数据集
## eps:邻域半径的最大值。即 ε < eps
## MinPts: 形成集群所需的点数。某个点圈地成为老大所需要的最少子民。OPTICS(DB, eps, MinPts)for each point pt of DBpt.reachable_dist = UNDEFINED # 初始化,原始数据集的所有点的可达距离设为UNDEFINEDfor each unprocessed point pt of DB # 遍历原始数据集的每个点 ptNbrs = getNbrs(pt, eps) # 根据eps圈定的范围,确定每个点pt所拥有的子民mark pt as processed # 将目前处理的点pt标记为已处理output pt to the ordered list # 将pt输出到某个有序序列里。这个序列应该是最终的输出序列,此处暂且即为resultif (core_dist(pt, eps, Minpts) != UNDEFINED) # 获取pt的核心距离。假如核心距离UNDEFINED,表示pt为噪声点Seeds = empty priority queue # 初始化优先队列seeds。对每个核心点,建一个新的优先队列update(Nbrs, pt, Seeds, eps, Minpts) # 更新优先队列seeds。该队列结果为pt的邻域内的子民按照可达性距离排序。for each next q in Seeds # 由于优先队列内seeds内的点也可能是核心点,抽取出来处理Nbrs' = getNbrs(q, eps) # 和上面一样,抽取领域,标记,输出到有序序列resultmark q as processedoutput q to the ordered listif (core_dist(q, eps, Minpts) != UNDEFINED) # 假如是核心点update(Nbrs', q, Seeds, eps, Minpts) # 同样进行update处理。此时seeds队列的点进一步增加下面是update函数:
## 函数整体功能:根据p的邻域N,更新优先队列seeds。该优先队列以点的可达距离属性排序function update(N, p, Seeds, eps, MinPts) iscoredist = core-distance(p, eps, MinPts) # 获取p的核心距离for each o in N # 遍历p的邻域内的所有子民,以o表示if o is not processed then # 如果该点未被处理new-reach-dist = max(coredist, dist(p,o)) # 根据核心距离,获取p到o的可达距离if o.reachability-distance == UNDEFINED then # 如果o的可达距离未定义,即o还没放入seeds队列o.reachability-distance = new-reach-dist # 更新o的可达距离(o的属性之一)Seeds.insert(o, new-reach-dist) # 将o放入seeds,处理完毕else # 假如o已经处理过了(o可能也是其他老大邻域内的子民)if new-reach-dist < o.reachability-distance then # 如果目前的老大p比以前的老大,离o的距离更近,那么p拥有o的管辖权o.reachability-distance = new-reach-dist # o的可达距离属性指定为p到o的可达距离Seeds.move-up(o, new-reach-dist) # 更新o在优先队列的位置最后算法将获得这样的结果:
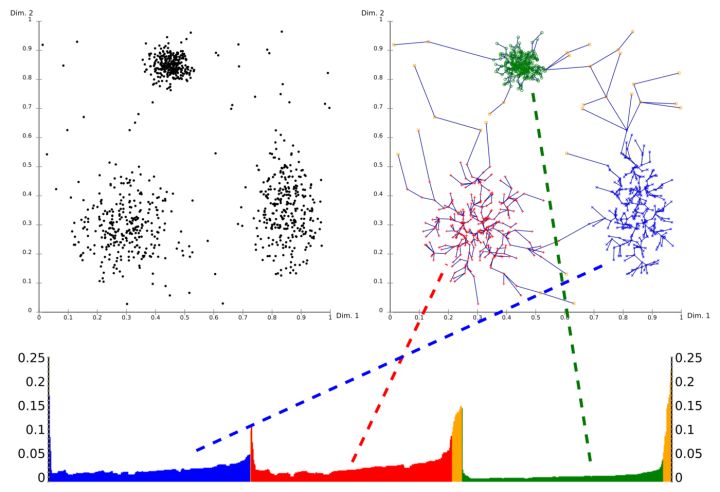
这是一个2D图,x轴是OPTICS算法处理点的先后顺序,y轴是点的最小可达性距离。
由于一个cluster内的点越密集,每个点与它的邻居之间的可达距离就越小,因此对应图例中的谷底。谷底越深,表示该cluster点的密度越高。
之后要提取聚类,可以通过在y轴上选定阈值即可。假如分类严格写,阈值就低些;反之则高一些,这类似于在DBSCAN中进行 ε 和minPts的选定。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!