redis实战-缓存穿透、缓存击穿、缓存雪崩
缓存穿透、击穿、雪崩
- 一:故事背景
- 二:业务场景
- 2.1 业务场景
- 2.2代码实现
- 三:缓存穿透
- 3.1 什么是缓存穿透
- 3.2 解决方案
- 3.2.1 缓存空值
- 3.2.2 数据预热
- 3.2.3 数据库优化查询
- 四:缓存击穿
- 4.1什么是缓存击穿
- 4.2解决方案
- 4.2.1 加锁防止并发访问数据库。
- 五:缓存雪崩
- 5.1 什么是缓存雪崩
- 5.2解决方案
- 5.2.1 设置合适的缓存过期时间
- 5.2.2 引入多级缓存
- 5.2.3 限流和熔断
- 六:总结&提升
- 6.1 总结
- 6.2 提升
- 6.3 后记
一:故事背景
使用Redis进行缓存,我们就必须要知道使用Redis可能会出现的问题,只有这样,我们再能更好规避,更好的使用Redis,为我们服务。
今天我们就来讲讲Redis的经典问题,Redis缓存的穿透、击穿、雪崩。
二:业务场景
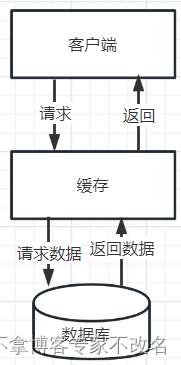
2.1 业务场景
我们假设一个简单的业务场景,有一个在线商城系统
- 用户可以根据商品ID查询商品信息。系统使用Redis作为缓存,将商品信息存储在缓存中,键的格式为"product:{productId}",值为商品的详细信息。
- 当用户请求查询商品信息时,首先尝试从Redis缓存中获取,如果缓存中不存在,则从数据库中查询,并将查询结果存储到缓存中。
2.2代码实现
@Service
public class ProductService {@Autowiredprivate RedisTemplate<String, Product> redisTemplate;public Product getProductInfo(String productId) {// 尝试从缓存中获取商品信息Product product = redisTemplate.opsForValue().get("product:" + productId);if (product == null) {// 如果缓存中不存在,则从数据库查询product = queryProductInfoFromDatabase(productId);if (product == null) {// 如果查询结果为空,将空值存储到缓存中,并设置较短的过期时间redisTemplate.opsForValue().set("product:" + productId, null, 300, TimeUnit.SECONDS);} else {// 将查询结果存储到缓存中redisTemplate.opsForValue().set("product:" + productId, product);}}return product;}private Product queryProductInfoFromDatabase(String productId) {// 从数据库查询商品信息// ...}
}上述代码给出了,我们所述业务场景的实现。接下来我们就结合这个场景分别解释,缓存穿透、缓存击穿、缓存雪崩。
三:缓存穿透
3.1 什么是缓存穿透
缓存穿透指的是在缓存中无法找到需要的数据,导致每次请求都需要访问底层数据存储,从而引发数据库负载过大的情况。通常发生在恶意请求或者查询不存在的数据时。
3.2 解决方案
3.2.1 缓存空值
在缓存中存储空值,并且设置一个较短的过期时间,防止频繁的查询请求,直接访问数据库。上面的代码里也编写了此部分代码
if (product == null) {// 如果查询结果为空,将空值存储到缓存中,并设置较短的过期时间redisTemplate.opsForValue().set("product:" + productId, null, 300, TimeUnit.SECONDS);}
3.2.2 数据预热
在系统启动时,可以将热门或者常用的数据预先加载到缓存中,从而避免冷启动时大量的缓存穿透请求。比如可以使用定时任务进数据预热。
// 在系统启动时加载热门数据到缓存中
@PostConstruct
public void initCache() {// 查询热门数据List<Product> hotProducts = queryHotProductsFromDatabase();// 将热门数据放入缓存for (Product product : hotProducts) {redisTemplate.opsForValue().set("product:" + product.getId(), product, 5, TimeUnit.MINUTES);}
}
3.2.3 数据库优化查询
可以通过对数据库的查询进行优化,例如使用索引、缓存数据库查询结果等方式,从而减少数据库查询的耗时,降低数据库负载,减少缓存穿透的发生。
这个方法并未解决穿透问题,只是从数据库层面降低了缓存穿透带来的问题。
四:缓存击穿
4.1什么是缓存击穿
缓存击穿指的是一个原本存在于缓存中的数据过期或者被删除,而此时恰好有大量的请求同时访问这个数据,导致这些请求都无法从缓存中获取数据,而需要访问底层数据存储,从而引发数据库负载过大的情况。
4.2解决方案
4.2.1 加锁防止并发访问数据库。
在缓存失效时,通过加锁来保证只有一个请求可以访问数据库,其他请求等待并共享查询结果。分布式锁可以看我的这篇博客redis分布式锁
五:缓存雪崩
5.1 什么是缓存雪崩
缓存雪崩指的是在缓存中大量的数据同时过期或失效,导致多个请求同时访问底层数据存储,从而引发数据库负载过大的情况。
5.2解决方案
5.2.1 设置合适的缓存过期时间
合理设置缓存的过期时间,避免大量缓存在同一时间内失效,从而降低缓存雪崩的风险。可以通过设置不同的过期时间,将缓存的过期时间分散开来,避免同时失效。
if (product != null) {// 将查询结果存储到缓存中,并设置随机的过期时间,范围为 1~5 分钟int expireTime = new Random().nextInt(5) + 1;redisTemplate.opsForValue().set("product:" + productId, product, expireTime, TimeUnit.MINUTES);}
5.2.2 引入多级缓存
通过在缓存系统中引入多层级的缓存,例如一级缓存(内存缓存)和二级缓存(分布式缓存如Redis),可以在一级缓存失效时,从二级缓存获取数据,并在二级缓存中更新一级缓存,从而减少直接请求后端系统的次数。
5.2.3 限流和熔断
在缓存失效时,可以考虑限流和熔断策略,防止大量请求涌入后端系统,可以通过设置请求的并发数限制、请求频率限制等方式控制请求的流量,保护后端系统的稳定性。
六:总结&提升
6.1 总结
- 缓存穿透、缓存击穿和缓存雪崩是常见的缓存使用问题,可能导致系统性能下降甚至系统崩溃。
- 使用合适的缓存策略,如设置合理的缓存过期时间、使用分布式缓存等,可以有效避免这些问题的发生。
6.2 提升
- 在使用Spring Boot和Redis进行缓存时,可以通过合理地配置缓存的过期时间、使用缓存的自动刷新功能、合理设计缓存的Key和Value结构等方式来避免这些问题的发生,从而提高系统的性能和稳定性。
6.3 后记
通过此篇文章相信你对Redis的缓存穿透、击穿、雪崩、有了一定的了解,还在等什么,赶紧实践起来吧。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!