Collector和Collectors类(收集器原理分析)
文章目录
- 前言
- 一、Collector接口
- 二、Collectors工具类
- 1,简介
- 2,收集器
- (1)、恒等处理
- (2)、归约处理
- (3)、分组分区
- 3,collectingAndThen
前言
Stream流中的collect方法,收集一个Collector实例,将流中的元素收集成另一种数据结构:
- collect是Stream流的一个 终止方法,会使用传入的收集器(Collector实现对象)对结果执行相关的操作。
- Collector是一个接口,专门作为collect方法的入参,也就是收集器。
- Collectors是生产Collector收集器对象的工具类。
一、Collector接口
Collector接口(收集器)以下5个方法用来生成5个成员变量:
public interface Collector<T, A, R> {//供给型(Supplier)参数,supplier用于生成A类型的结果容器Supplier<A> supplier();//消费型(Consumer)参数,accumulator用于消费元素,也就是归纳元素,这里的T就是元素,它会将流中的元素一个一个与结果容器A发生操作BiConsumer<A, T> accumulator();//方法型(Function)参数,combiner用于两个两个合并并行执行的线程的执行结果,将其合并为一个最终结果ABinaryOperator<A> combiner();//方法型(Function)参数,finisher用于将之前整合完的结果A转换成为RFunction<A, R> finisher();//characteristics表示当前Collector的特征值,这是个不可变SetSet<Characteristics> characteristics();
}
characteristics是一个内部枚举类,包含下面三个值:
public interface Collector<T, A, R> {//内部枚举类enum Characteristics {//多线程并行: 声明此收集器可以多个线程并行处理,允许并行流中进行处理CONCURRENT,//无序: 声明此收集器的汇总归约结果与Stream流元素遍历顺序无关,不受元素处理顺序影响UNORDERED,//无需转换结果: 声明此收集器的finisher方法是一个恒等操作,可以跳过IDENTITY_FINISH}
}
两个of重载方法,用于生成Collector实例,一个包含全部的参数,另一个不包含finisher参数:
public interface Collector<T, A, R> {//四个参数的of方法,生成一个Collector对象,T表示流中的元素,R表示最终结果,也就是容器public static<T, R> Collector<T, R, R> of(Supplier<R> supplier,BiConsumer<R, T> accumulator,BinaryOperator<R> combiner,Characteristics... characteristics) {Objects.requireNonNull(supplier);Objects.requireNonNull(accumulator);Objects.requireNonNull(combiner);Objects.requireNonNull(characteristics);Set<Characteristics> cs = (characteristics.length == 0)? Collectors.CH_ID: Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH, characteristics));return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, cs);}// //四个参数的of方法,生成一个Collector对象,T表示流中的元素,R表示最终结果,finisher用于将中间结果A转换成Rpublic static<T, A, R> Collector<T, A, R> of(Supplier<A> supplier,BiConsumer<A, T> accumulator,BinaryOperator<A> combiner,Function<A, R> finisher,Characteristics... characteristics) {Objects.requireNonNull(supplier);Objects.requireNonNull(accumulator);Objects.requireNonNull(combiner);Objects.requireNonNull(finisher);Objects.requireNonNull(characteristics);Set<Characteristics> cs = Collectors.CH_NOID;if (characteristics.length > 0) {cs = EnumSet.noneOf(Characteristics.class);Collections.addAll(cs, characteristics);cs = Collections.unmodifiableSet(cs);}return new Collectors.CollectorImpl<>(supplier, accumulator, combiner, finisher, cs);}}
这里拿大神文章的一个图来看,可以清晰的看明白处理流程及Collector这5个参数的作用,分串行和并行两种情况,如下:
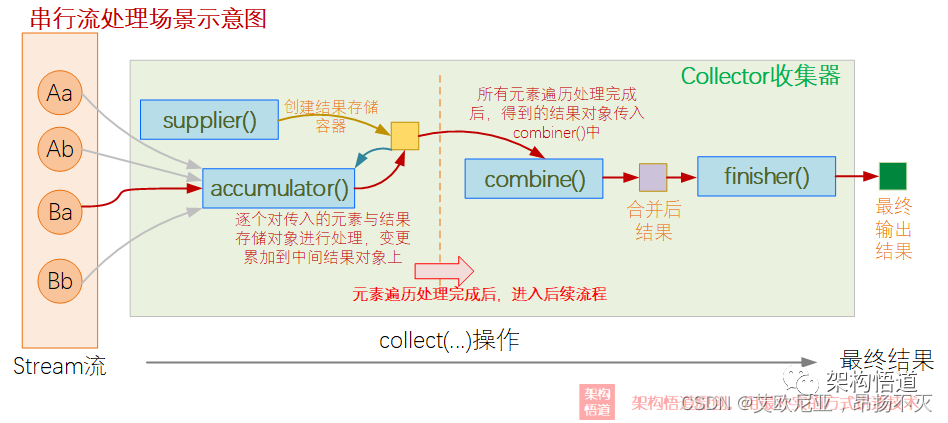
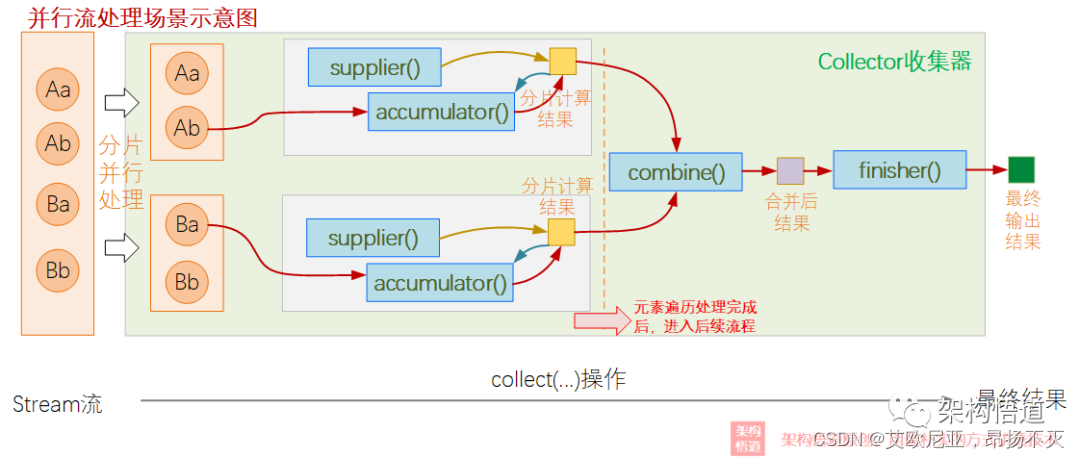
原文连接:https://cloud.tencent.com/developer/article/2066869
二、Collectors工具类
1,简介
Collectors是一个工具类,是JDK预实现Collector的工具类,它内部提供了多种收集器的生成策略,我们可以直接拿来使用,非常方便。
2,收集器
根据操作类型,可以将收集器分成下面三个类:
- 恒等处理: 该类操作元素本身没有变化
- toList()
- toSet()
- toCollection(Supplier
collectionFactory) - toMap
- 归约处理: 该类操作将流中的元素进行处理,最后得到一个最终结果
- counting()
- summingInt(ToIntFunction mapper)
- maxBy(Comparator comparator)
- minBy(Comparator comparator)
- joining()
- 分组分区: 按照某个维度将stream流中的元素进行分组
- groupingBy(Function classifier)
- partitioningBy(Predicate predicate)
(1)、恒等处理
Stream中的元素经过Collector收集器处理前后完全不变,拿toList()来看,该收集器只是将结果取出,放到List集合中,本质没有对元素本身有任何修改。
来看Collectors中的toList方法,如下:
public static <T> Collector<T, ?, List<T>> toList() {return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,(left, right) -> { left.addAll(right); return left; },CH_ID);}
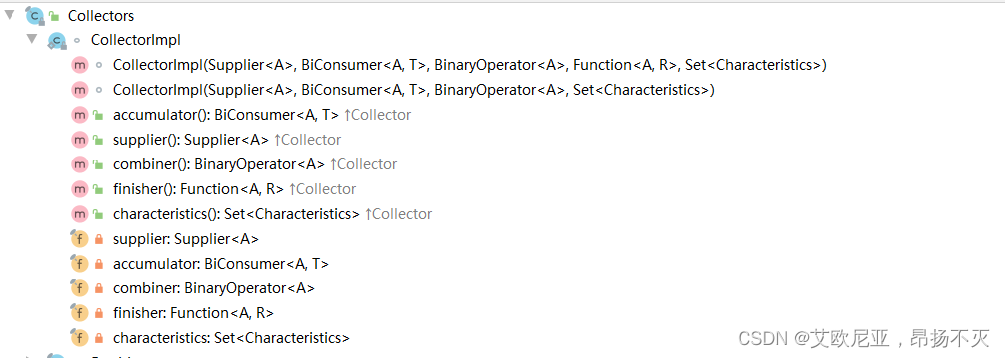
来看上面的toList方法,该方法返回了一个Collector的实现类CollectorImpl,CollectorImpl是该工具类中的一个收集器的实现类:
suppllier为结果容器,这里就是new出来的ArrayList集合对象,A为List
accumulator为list::add,即将流中的元素T与容器A进行操作,这里的操作就是将元素添加到容器中;
combiner为(left, right) -> { left.addAll(right); return left; },也就是合并操作,将一个结果right添加到一个结果left中,针对并行操作有效;
finisher这里没用到这个参数;
characteristics为IDENTITY_FINISH,即无需转换结果。
演示:
@Testpublic void test1(){String[] arr = new String[]{"a","bb","ccc","d"};//toCollection 接收一个Supplier类型参数,用作自定义的容器 toCollection(Supplier collectionFactory) ArrayList<String> collect = Arrays.stream(arr).collect(Collectors.toCollection(ArrayList::new));System.out.println(collect); //[a, bb, ccc, d]//toListList<String> list = Arrays.stream(arr).collect(Collectors.toList());System.out.println(list); //[a, bb, ccc, d]//toSetSet<Integer> set = Arrays.stream(arr).map(String::length).collect(Collectors.toSet());System.out.println(set); //[1, 2, 3]//toMap, 保证key唯一,否则报错Map<String, Integer> map = Arrays.stream(arr).collect(Collectors.toMap(Function.identity(), String::length));System.out.println(map); //{bb=2, a=1, ccc=3, d=1}//toMap, key重复,自定义策略,(o,o1)->o1:原来值为o,现在值为o1,取o1,即新值覆盖Map<Integer, String> map1 = Arrays.stream(arr).collect(Collectors.toMap(String::length, Function.identity(),(o,o1)->o1));System.out.println(map1); //{1=d, 2=bb, 3=ccc}}
(2)、归约处理
Stream流中的元素经过收集器处理后变成一个结果,比如累加,计算等等。。。
先来看归约方法,同Stream流中的三个重载的归约方法,Collectors中也提供了同样的三个reducing方法,如下:
public void test2(){Integer[] arr = {1,2,3};//一个参数Optional<Integer> collect = Arrays.stream(arr).collect(Collectors.reducing(Integer::sum));System.out.println(collect.get()); //6//两个参数,有初始值Integer collect1 = Arrays.stream(arr).collect(Collectors.reducing(10, Integer::sum));System.out.println(collect1); //16//三个参数,包含合并方法 非并行 10+1+2+3 区别于Stream中的三个参数的方法,这里第二个参数是Function类型,非BiFunctionInteger collect2 = Arrays.stream(arr).collect(Collectors.reducing(10, (x) -> x, (x, y) -> x + y));System.out.println(collect2); //16}
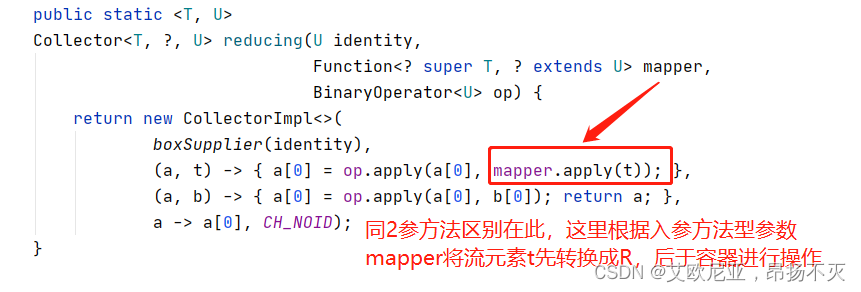
拿一个参数的reducing源码来看,底层逻辑也是收集器的实现

两个参数的归约方法:

这里可以看到两个参数的归约方法和一个参数的方法容器使用不同,对于一个参数来说,为什么不能直接使用数组作为容器呢,还要单独new一个新的内部类?对于两参方法,提供了初始值,可直接将初始值作为开始元素存入数组第一个索引位,后面直接拿该元素位的值与流元素T发生操作,但是对于一参无初始化值,如果也同二参这样拿数组第一个元素位记录,那么初始化时数组第一个元素位并不能准确的赋值,如果是null,后面accept方法可能报错,如果默认0,如果求累计积则结果也不符合预期。而内部类这个对象通过present能将流中的第一个t赋值到value,后续只需拿value同t进行消费方法的操作即可。
三个参数的归约方法:
maxBy、minBy、counting底层用的也是reducing,用法如下:
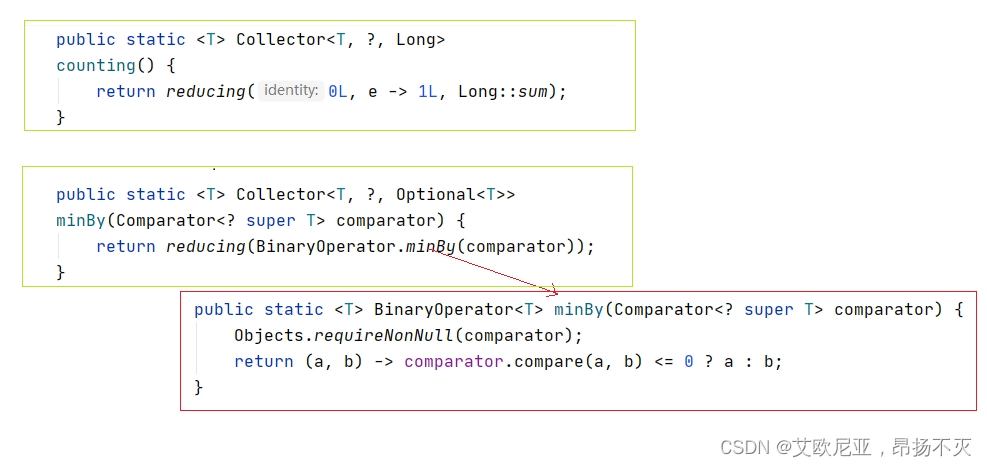
@Testpublic void test9(){List<String> list = Arrays.asList("3", "7", "1", "3");//计数Long collect = list.stream().collect(Collectors.counting());System.out.println(collect); //4//最值Optional<String> max = list.stream().collect(Collectors.maxBy(String::compareTo));System.out.println(max.get()); //7Optional<String> min = list.stream().collect(Collectors.minBy(String::compareTo));System.out.println(min.get()); //1//平均数Double avg = list.stream().collect(Collectors.averagingInt(Integer::parseInt));System.out.println(avg); //3.5 --> (14 / 4 )//summingIntInteger collect1 = list.stream().collect(Collectors.summingInt(String::length));System.out.println(collect); //4}
再来看summingInt方法,入参为一个将T转换为Int输出的方法型对象。其实现同理也是返回了收集器实现对象,初始容器为一个长度为1的数组,拿该数组中仅有的一个元素(a[0])与目标元素依次求和,合并方法为a[0]+b[0];finisher这里将中间结果R(a数组对象)转换成了A(int类型)输出。
public static <T> Collector<T, ?, Integer> summingInt(ToIntFunction<? super T> mapper) {return new CollectorImpl<>(() -> new int[1],(a, t) -> { a[0] += mapper.applyAsInt(t); },(a, b) -> { a[0] += b[0]; return a; },a -> a[0], CH_NOID);}
同理averagingInt底层实现同样如此,区别是使用数组第二个索引位记录个数,依次累加:
public static <T> Collector<T, ?, Double> averagingInt(ToIntFunction<? super T> mapper) {return new CollectorImpl<>(() -> new long[2],(a, t) -> { a[0] += mapper.applyAsInt(t); a[1]++; },(a, b) -> { a[0] += b[0]; a[1] += b[1]; return a; },a -> (a[1] == 0) ? 0.0d : (double) a[0] / a[1], CH_NOID);}
joining底层收集器如下:
public static Collector<CharSequence, ?, String> joining() {return new CollectorImpl<CharSequence, StringBuilder, String>(StringBuilder::new, StringBuilder::append,(r1, r2) -> { r1.append(r2); return r1; },StringBuilder::toString, CH_NOID);}
(3)、分组分区
分组:
先来看groupingBy的源码,该方法需要两个关键参数:
- 一个是分组函数,用来判断如何分组,即key的取值;
- 一个是值收集器,也就是用来存放分组后的value值的容器。
我们先看一个参数的groupingBy,如下:

这里分组函数为形参中自定义的方法型参数,值收集器为toList()方法返回的收集器对象,在往下看,调用了两个参数的groupingBy方法:

这里调用了三个参数的groupingBy方法,mapFactory为生产结果容器的供给型参数。详细分组源码过程如下图所示:

@Testpublic void test3(){List<String> list = Arrays.asList("aa", "b", "ac", "bdd", "ae", "aff", "bg");//字符长度分组Map<Integer, List<String>> map = list.stream().collect(Collectors.groupingBy(String::length));System.out.println(map);//{1=[b], 2=[aa, ac, ae, bg], 3=[bdd, aff]}
}
来看这个例子,根据String长度分组来举例,具体的执行流程如下图所示:
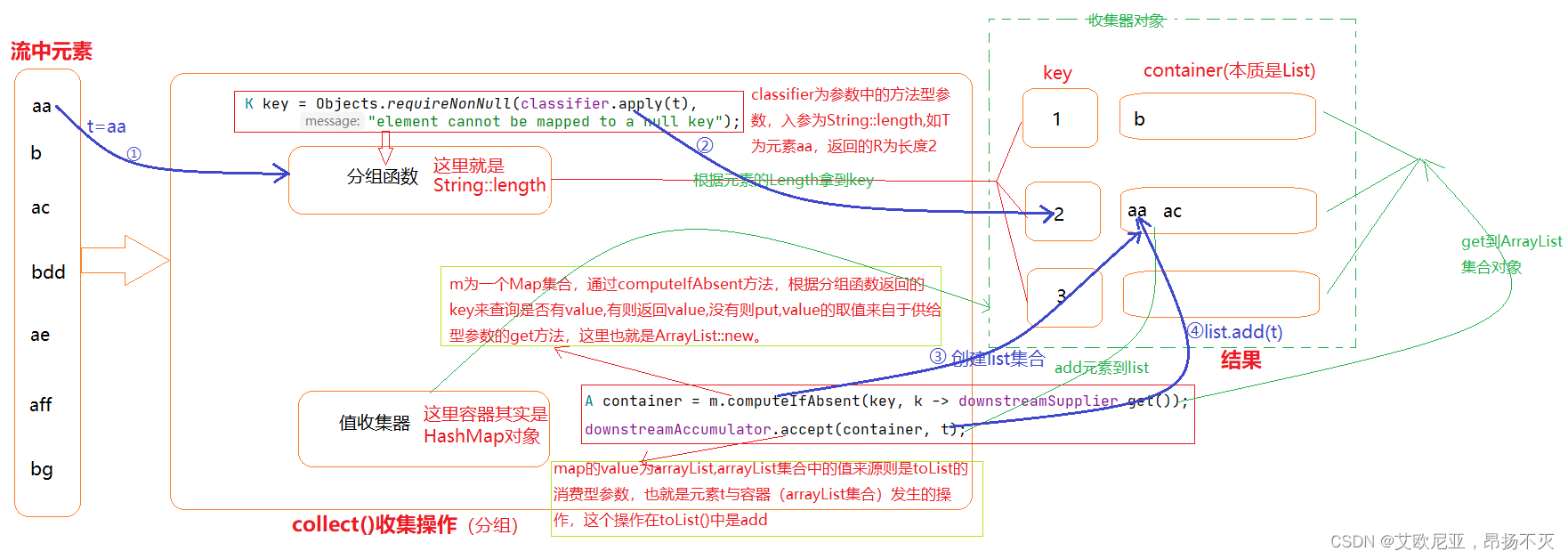
叠加嵌套
上面的值收集器默认使用的是toList()方法返回的收集器实现对象,来看下面的一个例子:
//两个分组条件:先根据字符首字母分组,然后根据字符长度分组Map<Character, Map<Integer, List<String>>> collect = list.stream().collect(Collectors.groupingBy(s -> s.charAt(0), Collectors.groupingBy(String::length)));System.out.println(collect); //{a={2=[aa, ac, ae], 3=[aff]}, b={1=[b], 2=[bg], 3=[bdd]}}
这里根据两个条件分组,先根据首字母分组,然后再根据字符长度分组,类比于上面根据String长度来分组的流程图,我们可以想到的是,基本执行流程相同,不同的是对于收集器,这里使用的并不是toList()方法默认的ArrayList的结果容器,这里第一次分组使用的分组函数是首字母,如a ->{aa,ac,ae,af} ,值收集器使用的是根据字符长度来分组返回的收集器,也就是这部分结果{aa,ac,ae,af}调用收集器的消费对象方法(长度分组)与收集器的容器对象(Map)发生操作,结果为:2=[aa, ac, ae], 3=[aff],将这部分的收集器对象当做第一次分组的值收集器对象放入,最终值就是:{a= {2=[aa, ac, ae], 3=[aff]} }。
分区:
按照指定条件将 stream 划分为 true 和 false 两个 map,先来看partitioningBy一个参数的源码:

这里看到类似于分组,依旧是默认使用的收集器是toList()

内部类Partition如下:
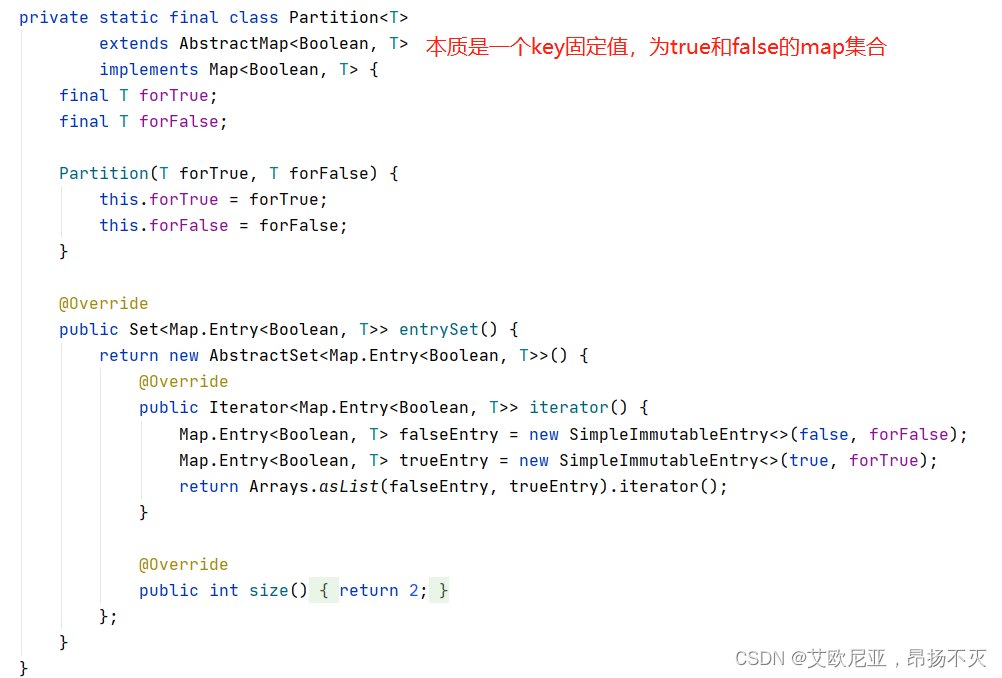
实例演示:
@Testpublic void test10(){List<String> list = Arrays.asList("aa", "b", "ac", "bdd", "ae", "aff", "bg");Map<Boolean, List<String>> collect1 = list.stream().collect(Collectors.partitioningBy(s -> s.length() > 2));System.out.println(collect1); //{false=[aa, b, ac, ae, bg], true=[bdd, aff]}}
3,collectingAndThen
包裹另一个收集器,对其结果进行二次加工转换,源码如下:

例如:
String[] arr = new String[]{"a","bb","ccc","d"};//toListList<String> list = Arrays.stream(arr).collect(Collectors.toList());System.out.println(list); //[a, bb, ccc, d]//collectingAndThen包裹,finisher为List::size,也就是本来输出的R为数组,现在将R为参数,通过入参的finisher.apply将其长度输出。Integer collect1 = Arrays.stream(arr).collect(Collectors.collectingAndThen(Collectors.toList(), List::size));System.out.println(collect1); //4
//两个参数归约方法,本身的finisher将初始值 数组a -> a[0]Integer collect1 = Arrays.stream(arr).collect(Collectors.reducing(10, Integer::sum));System.out.println(collect1); //16//collectingAndThen包裹后,也就是将原本的int型16转为String类型String collect3 = Arrays.stream(arr).collect(Collectors.collectingAndThen(Collectors.reducing(10, Integer::sum), x -> x + ""));System.out.println(collect3);
参考文章
https://www.bbsmax.com/A/lk5amVPa51/
https://cloud.tencent.com/developer/article/2066869
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!