SQL语句中ON DUPLICATE KEY UPDATE的使用介绍
一:主键索引,唯一索引和普通索引的关系
主键索引
主键索引是唯一索引的特殊类型。
数据库表通常有一列或列组合,其值用来唯一标识表中的每一行。该列称为表的主键。
在数据库关系图中为表定义一个主键将自动创建主键索引,主键索引是唯一索引的特殊类型。主键索引要求主键中的每个值是唯一的。当在查询中使用主键索引时,它还允许快速访问数据。主键索引不能为空。每个表只能有一个主键
唯一索引:
不允许两行具有相同的索引值。但可以都为NULL,笔者亲试。
如果现有数据中存在重复的键值,则数据库不允许将新创建的唯一索引与表一起保存。当新数据将使表中的键值重复时,数据库也拒绝接受此数据。每个表可以有多个唯一索引
普通索引:
一般的索引结构,可以在条件删选时加快查询效率,索引字段的值可以重复,可以为空值
二:ON DUPLICATE KEY UPDATE使用测试(MYSQL下的Innodb引擎)
上面介绍了索引的知识,是为了介绍这个ON DUPLICATE KEY UPDATE功能做铺垫。
1:ON DUPLICATE KEY UPDATE功能介绍:
有时候由于业务需求,可能需要先去根据某一字段值查询数据库中是否有记录,有则更新,没有则插入。你可能是下面这样写的
if not exists (select node_name from node_status where node_name = target_name)insert into node_status(node_name,ip,...) values('target_name','ip',...)
elseupdate node_status set ip = 'ip',site = 'site',... where node_name = target_name这样写在大多数情况下可以满足我们的需求,但是会有两个问题。
①性能带来开销,尤其是系统比较大的时候。
②在高并发的情况下会出现错误,可能需要利用事务保证安全。
有没有一种优雅的写法来实现有则更新,没有则插入的写法呢?ON DUPLICATE KEY UPDATE提供了这样的一个方式。
2:ON DUPLICATE KEY UPDATE测试样例+总结:
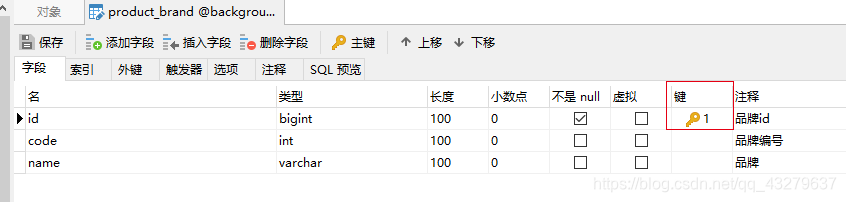
首先我们了解下这个简单的表结构id(主键)、code、name。
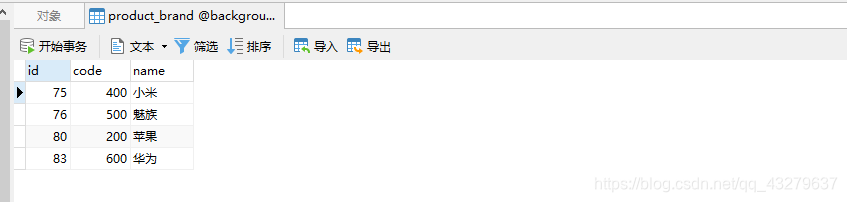
看下表中现有的数据:
执行以下实验进行分析:
实验一:含有ON DUPLICATE KEY UPDATE的INSERT语句中包含主键:
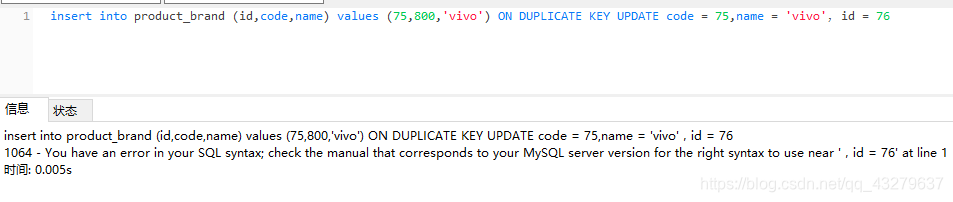
①插入更新都失败,原因是因为把主键id改成了已经存在的id
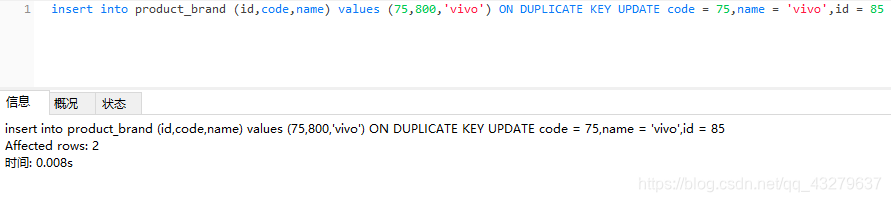
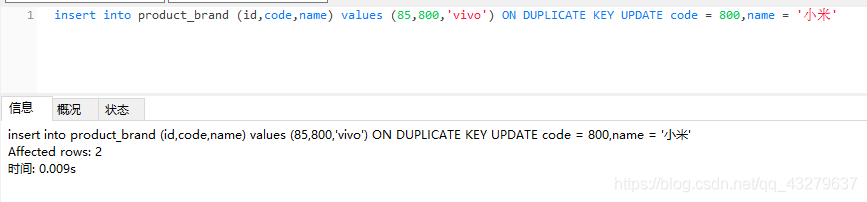
②执行更新操作。这里的数据还是四条。不过第四条的id由75变化为85
③执行更新操作。数据总量是四条
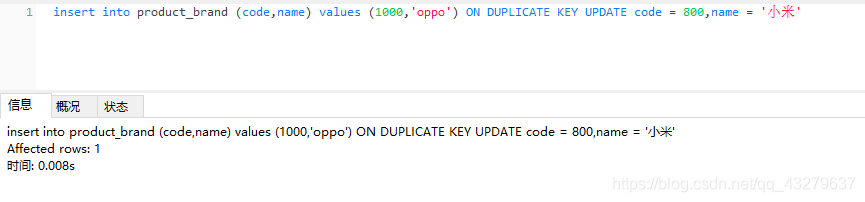
④insert语句中未包含主键,执行插入操作。数据量变为5条
实验二:含有ON DUPLICATE KEY UPDATE的INSERT语句中包含唯一索引:
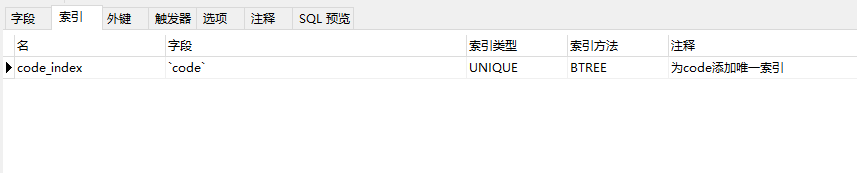
表结构中增加code的唯一索引,表中现有的数据:
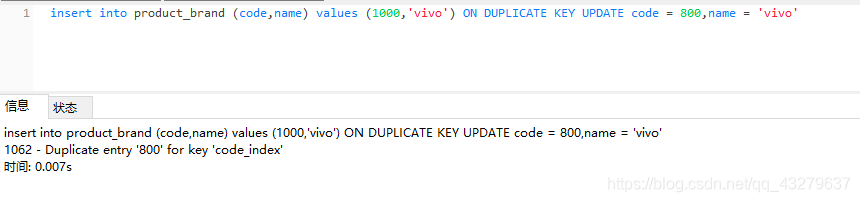
①插入更新都失败,原因是因为把code改成了已经存在的code值
②执行更新操作。这里的数据总量为5条。不过第五条的code由1000变化为1200
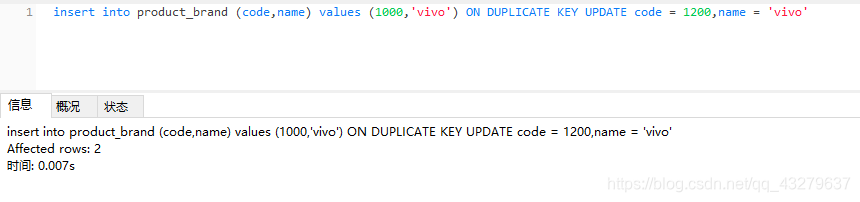
③执行更新操作。数据总量五条,没有变化
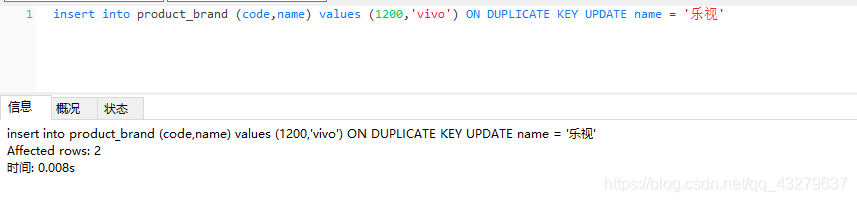
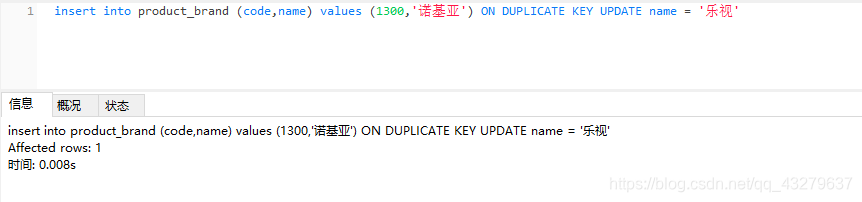
④insert语句中未包含唯一索引,执行插入操作。数据量变为6条
总结:
1:ON DUPLICATE KEY UPDATE需要有在INSERT语句中有存在主键或者唯一索引的列,并且对应的数据已经在表中才会执行更新操作。而且如果要更新的字段是主键或者唯一索引,不能和表中已有的数据重复,否则插入更新都失败。
2:不管是更新还是增加语句都不允许将主键或者唯一索引的对应字段的数据变成表中已经存在的数据。
参考文章:
https://segmentfault.com/a/1190000014306692![]() https://segmentfault.com/a/1190000014306692
https://segmentfault.com/a/1190000014306692
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!