django-DRF学习记录
Django && Django rest framework(DRF)
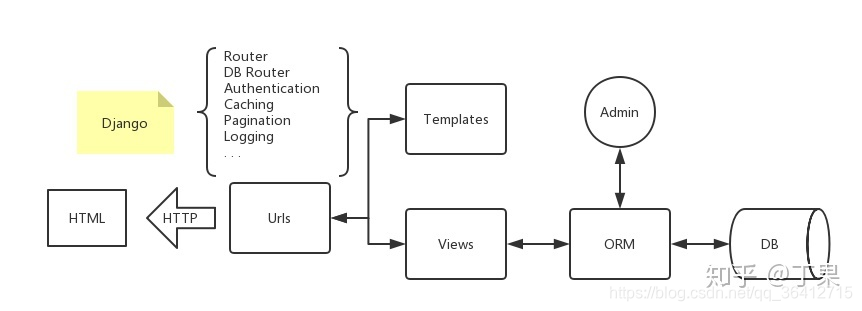
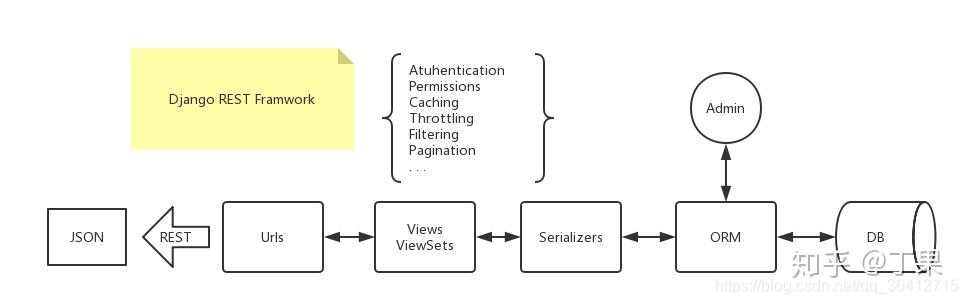
最少的语言描述Django?
将数据库的东西通过ORM的映射取出来,通过view文件,按照template文件排出的模板渲染成HTML。当用户请求相应的url时,返回相应的结果。
最少语言描述DRF?
将数据库的东西通过ORM的映射取出来,通过view和serializers文件绑定REST接口,当前端请求时,返回序列化好的json。
最少语言描述DRF在Django的基础上做了什么?
DRF是Django的超集,去掉了模板的部分,提供了一个REST的接口,同时也提供了满足该接口的代码工作流。同时,在REST的规范下,升级了权限和分页等功能,增加了限流和过滤搜索等功能。
1.安装环境
pip install django
pip install djangorestframework
2.创建项目
django-admin startproject api_drf
cd api_drf
python manage.py startapp api
3.设置
#settings.py
INSTALLED_APPS = (...'rest_framework',
)DATABASES = {'default': {'ENGINE': 'django.db.backends.mysql', # 数据库引擎'NAME': 'lcpapi', # 数据库名称'HOST': '127.0.0.1', # 数据库地址,本机 ip 地址 127.0.0.1'PORT': 3306, # 端口'USER': 'root', # 数据库用户名'PASSWORD': '123456', # 数据库密码}
}
#__init__.py
import pymysql
pymysql.version_info = (1, 4, 13, "final", 0)
pymysql.install_as_MySQLdb()
4.app的models.py
表模型,一个类对应一个数据表
from django.db import models
type_choice = ((0, 'INTEL'),(1, 'AMD')
)
multiply_choice=((0, 1.0),(1, 1.1),(2, 1.2),
)
duration_choice=((0,1),(1,2)
)
class CPU(models.Model):'''模型字段'''partnumber = models.CharField(max_length=128, verbose_name='partnumber', unique=True)featurecode = models.CharField(max_length=32, null=False, verbose_name='featurecode')name = models.CharField(max_length=128, verbose_name='name')idle = models.FloatField(null=False, verbose_name='idle')idle_rate = models.FloatField(null=False, verbose_name='idle_rate')max = models.FloatField(null=False, verbose_name='max')max_rate = models.FloatField(null=False, verbose_name='max_rate')max_efficiency = models.FloatField(null=False, verbose_name='max_efficiency')type = models.IntegerField(choices=type_choice, verbose_name='type')multiply = models.IntegerField(choices=multiply_choice, verbose_name='multiply', blank=False)term_duration = models.IntegerField(choices=duration_choice, verbose_name='term_duration', blank=False)class Meta:db_table = "cpulist"verbose_name = "cpulist"verbose_name_plural = verbose_name
5.app的Serializers
- 在你的app中新建一个serializers.py文件,对models.py中的类新建一个序列化的类
- 在类中写要序列化的字段
作用:
- 序列化,序列化器会把模型对象转换成字典,经过response以后变成json字符串
- 反序列化,把客户端发送过来的数据,经过request以后变成字典,序列化器可以把字典转成模型
- 反序列化,完成数据校验功能
from rest_framework.serializers import ModelSerializerfrom api import models
from api.models import CPUclass CPUSerializer(ModelSerializer):class Meta:model = CPU# fields = ['id', 'partnumber', 'featurecode', 'name',# 'idle', 'idle_rate', 'max','max_rate','max_efficiency',# 'type','multiply','term_duration'# ]fields = '__all__'extra_kwargs = {"id": {"read_only": True}}def create(self, validated_data): # 调用Serializer必须重写create方法res = models.CPU.objects.create(**validated_data)return res
6.app的views.py
使用序列化器操作models.py中定义的数据表,返回序列化好的json。
get/post/put/patch/delete
from rest_framework.response import Response
from rest_framework.views import APIView
from api import models
from api.serializers import CPUSerializerclass CPU(APIView):response = {'code':100, 'msg':'查询成功'}def get(self,request):cpus = models.CPU.objects.all()# 注instance用于接受序列化的对象,many表示是queryset对象,如果是多条,就是many=True,如果是单个对象,就不写cpus_serializer = CPUSerializer(instance=cpus, many=True)return Response(cpus_serializer.data) #cpus_serializer.data就是序列化后的字典def get_by_id(self, request, id):res = models.CPU.objects.all().filter(id=id).first()ser = CPUSerializer(instance=res)return Response(ser.data)def post(self,request):res = request.data # post提交的是数据都在这里,是一个字典ser = CPUSerializer(data=res) # 这里针对数据往哪个表存识别不了,所以在序列化类里需要重写create方法# 校验字段if ser.is_valid():ser.save() # 调用save保存到数据库return Response(ser.data)else:return Response(ser.errors) # 如果校验不通过返回错误信息
7.urls.py
视图views和路由的映射
from django.contrib import admin
from django.urls import path, re_path
from api import viewsurlpatterns = [path('admin/', admin.site.urls),path('cpus/', views.CPU.as_view()),re_path(r'cpu/(?P\d+)' ,views.CPU.as_view()),
]
8.启动
python manage.py makemigrations #记录下models.py的变更记录
python manage.py migrate #变更记录同步到数据库
python manage.py runserver #启动server
Django model中的class Meta
Django model中的class Meta详解
- app_label:指定这个模型类是哪个应用程序
- db_table:指定自定义数据库表名
- db_tablespace:指定这个模型对应的数据库表放在哪个数据库表空间
- ordering:告诉Django模型对象返回的记录结果集是按照哪个字段排序的
ordering=['order_date']
# 按订单升序排列
ordering=['-order_date']
# 按订单降序排列,-表示降序
ordering=['?order_date']
# 随机排序,?表示随机
ordering = ['-pub_date', 'author']
# 对 pub_date 降序,然后对 author 升序
- unique_together:通过两个字段保持唯一性
unique_together = (("first_name", "last_name"),)
- verbose_name:给模型类起一个可读的名字
verbose_name = "pizza"
- verbose_name_plural:指定模型的复数形式是什么
verbose_name_plural = "pizzas"
Django 序列化器中的class Meta
- model = 需要用到的序列化模型类
- fields = (‘需要序列化的字段’)
- 如果多个视图需要数据大致相同可以通过extra_kwargs = {‘声明那些字段参与序列化,那些不参与序列化’}
ModelSerializer和Serializer的区别
- Serializer:进行序列化基本的类;
- ModelSerializer:继承于Serializer,内部实现了通用的序列化逻辑,其中包含了与Model字段对应的字段,可以快速对Model进行序列化。
ModelSerializer 类相比 Serializer 类添加了以下功能:
- 它会基于 model 自动创建一些字段
- 它会自动生成一些验证,比如 unique_together 验证
- 它包含简单的默认的 create() 和 update()
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!