Flink:算子
序言
整理一下flink的任务吧.
我们在搞定了source和sink后.那算子就很重要了.为啥子呢?因为算子就是我们处理source的过程,最后需要sink到指定的存储空间里.cuiyaonan200@163.com
本文基于官网v1.13.2的版本整理
官方网址:概览 | Apache Flink
算子
用户通过算子能将一个或多个 DataStream 转换成新的 DataStream,在应用程序中可以将多个数据转换算子合并成一个复杂的数据流拓扑。
这部分内容将描述 Flink DataStream API 中基本的数据转换API,数据转换后各种数据分区方式,以及算子的链接策略。
其实看了API感觉官网可以在进一步组合api,我觉得算子可以分为3大类(后面在慢慢整理吧cuiyaonan2000@163.com):
- 针对data的算子
- 针对window的算子
- 针对stream的算子
Map
DataStream → DataStream #
Takes one element and produces one element. A map function that doubles the values of the input stream:
遍历流中的对象并返回一个新对象
DataStream dataStream = //...
dataStream.map(new MapFunction() {@Overridepublic Integer map(Integer value) throws Exception {return 2 * value;}
}); FlatMap
DataStream → DataStream #
Takes one element and produces zero, one, or more elements. A flatmap function that splits sentences to words:
根据用例可以看出flatmap就是将原始流中的对象进行切分或者平摊,返回多个对象cuiyaonan2000@163.com
dataStream.flatMap(new FlatMapFunction() {@Overridepublic void flatMap(String value, Collector out)throws Exception {for(String word: value.split(" ")){out.collect(word);}}
}); Filter
DataStream → DataStream #
Evaluates a boolean function for each element and retains those for which the function returns true. A filter that filters out zero values:
dataStream.filter(new FilterFunction() {@Overridepublic boolean filter(Integer value) throws Exception {return value != 0;}
}); KeyBy(很重要可以扩展算子的并行度cuiyaonan2000@163.com)
可以参考The Meaning Of Window And WaterMark On Flink_难得糊涂-CSDN博客 中的窗口创建
DataStream → KeyedStream (此转换返回KeyedStream,其中包括使用被Keys化状态所需的KeyedStream。)
逻辑上将流分区为不相交的分区。具有相同Keys的所有记录都分配给同一分区。在内部,keyBy()是使用散列分区实现的。
dataStream.keyBy(value -> value.getSomeKey());
dataStream.keyBy(value -> value.f0);Reduce
KeyedStream → DataStream
接收根据key分组后的数据,然后进行累计计算并返回.比如value1 与value2 计算的结果value1+value2会与value3进行累计计算cuiyaonan2000@163.com
keyedStream.reduce(new ReduceFunction() {@Overridepublic Integer reduce(Integer value1, Integer value2)throws Exception {return value1 + value2;}
}); Window
KeyedStream → WindowedStream
可以在已经分区的KeyedStream上定义Windows。Windows根据某些特征(例如,在最后5秒内到达的数据)对每个Keys中的数据进行分组计算。这里有个关键的点就是,首先根据keys进行了分流,然后在分流的基础上根据时间进行分组,用于计算cuiyaonan2000@163.com
dataStream.keyBy(value -> value.f0).window(TumblingEventTimeWindows.of(Time.seconds(5))); WindowAll
DataStream → AllWindowedStream
Windows可以在常规DataStream上定义。Windows根据某些特征(例如,在最后5秒内到达的数据)对所有流事件进行分组。
注意:在许多情况下,这是非并行转换。所有记录将收集在windowAll 算子的一个任务中--即算子的并行度为1
dataStream.windowAll(TumblingEventTimeWindows.of(Time.seconds(5)));Window Apply
WindowedStream → DataStream
AllWindowedStream → DataStream
Apply函数的作用是针对 一个窗口内的数据,进行计算,并返回一个结果.比如我们一个窗口是10s,那apply的重载函数就是处理该10s秒内的数据并返回一个结果值,或者返回多个结果值.cuiyaonan2000@163.com
下面是一个手动求和窗口数据元的函数
//注意apply 接收什么,返回什么都都是通过注解来声明.
//比如下面的Tuple2 指明了窗口期内的对象内容
//Collector指明了返回的类型
//cuiyaonan2000@163.com
windowedStream.apply(new WindowFunction, Integer, Tuple, Window>() {public void apply (Tuple tuple,Window window,Iterable> values,Collector out) throws Exception {int sum = 0;for (value t: values) {sum += t.f1;}out.collect (new Integer(sum));}
});// applying an AllWindowFunction on non-keyed window stream
allWindowedStream.apply (new AllWindowFunction, Integer, Window>() {public void apply (Window window,Iterable> values,Collector out) throws Exception {int sum = 0;for (value t: values) {sum += t.f1;}out.collect (new Integer(sum));}
}); WindowReduce
WindowedStream → DataStream
对窗口应用 reduce function 并返回 reduce 后的值。---即窗口内的值
windowedStream.reduce (new ReduceFunction>() {public Tuple2 reduce(Tuple2 value1, Tuple2 value2) throws Exception {return new Tuple2(value1.f0, value1.f1 + value2.f1);}
}); Union
DataStream* → DataStream
两个或多个数据流的联合,创建包含来自所有流的所有数据元的新流。注意:如果将数据流与自身联合,则会在结果流中获取两次数据元
dataStream.union(otherStream1, otherStream2, ...);Window Join
DataStream,DataStream → DataStream
根据指定的 key 和窗口 join 两个数据流。
dataStream.join(otherStream).where().equalTo().window(TumblingEventTimeWindows.of(Time.seconds(3))).apply (new JoinFunction () {...}); Interval Join
KeyedStream,KeyedStream → DataStream
在给定的时间间隔内使用公共Keys关联两个被Key化的数据流的两个数据元e1和e2,以便e1.timestamp + lowerBound <= e2.timestamp <= e1.timestamp + upperBound
// this will join the two streams so that
// key1 == key2 && leftTs - 2 < rightTs < leftTs + 2
keyedStream.intervalJoin(otherKeyedStream).between(Time.milliseconds(-2), Time.milliseconds(2)) // lower and upper bound.upperBoundExclusive(true) // optional.lowerBoundExclusive(true) // optional.process(new IntervalJoinFunction() {...});Window CoGroup
DataStream,DataStream → DataStream
根据指定的 key 和窗口将两个数据流组合在一起。
dataStream.coGroup(otherStream).where(0).equalTo(1).window(TumblingEventTimeWindows.of(Time.seconds(3))).apply (new CoGroupFunction () {...});Connect
DataStream,DataStream → ConnectedStream
“连接”两个保存其类型的数据流。连接允许两个流之间的共享状态
DataStream someStream = //...
DataStream otherStream = //...ConnectedStreams connectedStreams = someStream.connect(otherStream); CoMap, CoFlatMap
ConnectedStream → DataStream
类似于在连接的数据流上进行 map 和 flatMap。
connectedStreams.map(new CoMapFunction() {@Overridepublic Boolean map1(Integer value) {return true;}@Overridepublic Boolean map2(String value) {return false;}
});
connectedStreams.flatMap(new CoFlatMapFunction() {@Overridepublic void flatMap1(Integer value, Collector out) {out.collect(value.toString());}@Overridepublic void flatMap2(String value, Collector out) {for (String word: value.split(" ")) {out.collect(word);}}
}); Iterate
DataStream → IterativeStream → ConnectedStream
通过将一个算子的输出重定向到某个之前的算子来在流中创建“反馈”循环。这对于定义持续更新模型的算法特别有用。下面的代码从一个流开始,并不断地应用迭代自身。大于 0 的元素被发送回反馈通道,其余元素被转发到下游。
IterativeStream iteration = initialStream.iterate();
DataStream iterationBody = iteration.map (/*do something*/);
DataStream feedback = iterationBody.filter(new FilterFunction(){@Overridepublic boolean filter(Long value) throws Exception {return value > 0;}
});
iteration.closeWith(feedback);
DataStream output = iterationBody.filter(new FilterFunction(){@Overridepublic boolean filter(Long value) throws Exception {return value <= 0;}
}); 物理分区
Flink 也提供以下方法让用户根据需要在数据转换完成后对数据分区进行更细粒度的配置。
这里的分区设置指的是算子和算子之间的信息传递的规则,因为有的算子并发度为2,有的算子的并发度为4 ,那他们之间的信息传递规则如何设置的问题cuiyaonan2000@163.com
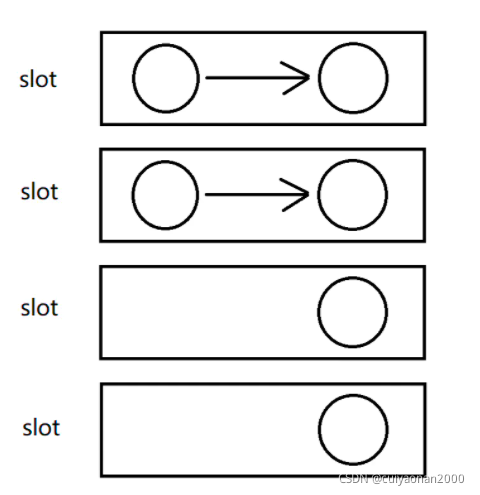
forward (默认)
上游算子某个并发直接将数据发给同一个slot中的下游算子的并发,
适用于
- 上下游算子并发度一致
-
数据没有倾斜
rebalance
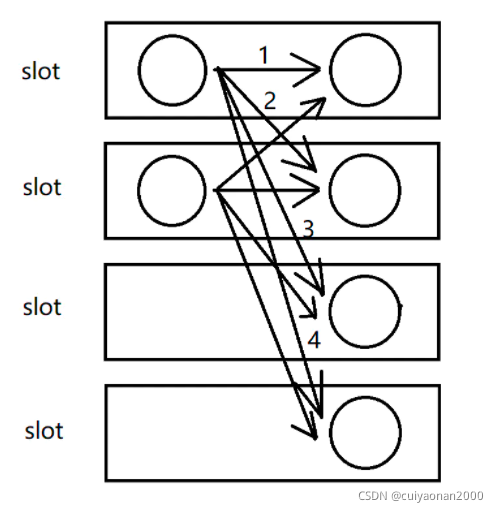
按照round-robin的方式,决定上游算子的某个并发的数据发往下游的哪个并发。该方法可以保证从上游算子到下游算子的数据是绝对均匀发送的。但是不同并发之间的数据交互存在网络传输开销。
适用于(下游所有的算子内的子任务会均匀的收到上游算子的子任务发送的信息,)
- 上下游算子并发度不一致
- 存在数据倾斜
Custom Partitioning
DataStream → DataStream
使用用户定义的 Partitioner 为每个元素选择目标任务。
即自定义分区,自定义分区需要实现Partitioner接口
dataStream.partitionCustom(partitioner, "someKey");
dataStream.partitionCustom(partitioner, 0);
Random Partitioning
DataStream → DataStream
Partitions elements randomly according to a uniform distribution.
按照均匀分布的随机数,决定上游算子的某个并发的数据发往下游的哪个并发。该方法与rebalance类似,但是会增加随机数生成的开销。并且因为是随机的,最后结果未必是百分百均匀的,但是概率上是均匀分布的。但是不同并发之间的数据交互存在网络传输开销。
dataStream.shuffle();
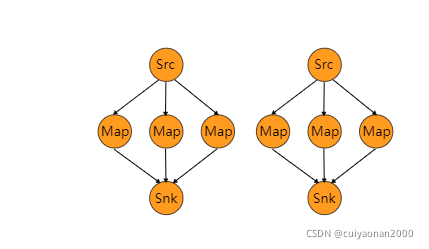
Rescaling
DataStream → DataStream
Rescaling:重新调节
DataStream.rescale()
如果上游操作有2个并发,而下游操作有4个并发,那么上游的1个并发结果分配给力下游的2个并发操作,另外的1个并发结果则分配给了下游的另外2个并发操作。
另一方面,下游有2个并发操作而上游有4个并发操作,那么上游的其中2个操作的结果分配给了下游的一个并发操作,而另外2个并发操作的结果则分配给了另外1个并发操作
Rescaling与Rebalancing的区别为 Rescaling会分个组,而Rebalancing不会分组,而是雨露均沾的传递数据给下一个算子的子任务
由上可以了解Rescaling是重新分配计算资源,然每个计算资源的任务数一样,而不是去修改分区cuiyaonan2000@163.com
dataStream.rescale();
Broadcasting
DataStream → DataStream
Broadcasts elements to every partition.
元素会分发给所有的分区,即重复消费.
dataStream.broadcast();算子链和资源组
将两个算子链接在一起能使得它们在同一个线程中执行,从而提升性能。Flink 默认会将能链接的算子尽可能地进行链接(例如, 两个 map 转换操作)。此外, Flink 还提供了对链接更细粒度控制的 API 以满足更多需求:
如果想对整个作业禁用算子链,可以调用 StreamExecutionEnvironment.disableOperatorChaining()。下列方法还提供了更细粒度的控制。
需要注 意的是, 这些方法只能在 DataStream 转换操作后才能被调用,因为它们只对前一次数据转换生效。例如,可以 someStream.map(...).startNewChain() 这样调用,而不能 someStream.startNewChain()这样。----即只能将两个算子放在一个线程中.
一个资源组对应着 Flink 中的一个 slot 槽,更多细节请看slots 槽。 你可以根据需要手动地将各个算子隔离到不同的 slot 中。
Start New Chain
基于当前算子创建一个新的算子链。
后面两个 map 将被链接起来,而 filter 和第一个 map 不会链接在一起。
someStream.filter(...).map(...).startNewChain().map(...);
Disable Chaining
禁止和 map 算子链接在一起。
someStream.map(...).disableChaining();
Set Slot Sharing Group
为某个算子设置 slot 共享组。
Flink 会将同一个 slot 共享组的算子放在同一个 slot 中,而将不在同一 slot 共享组的算子保留在其它 slot 中。这可用于隔离 slot (这里可以控制算子独占一个slot还是可以共享在同一个slot中cuiyaonan2000@163.com)。
如果所有输入算子都属于同一个 slot 共享组,那么 slot 共享组从将继承输入算子所在的 slot。slot 共享组的默认名称是 “default”,可以调用 slotSharingGroup(“default”) 来显式地将算子放入该组。
someStream.filter(...).slotSharingGroup("name");算子的注释
Flink里的算子和作业节点会有一个名字和一个描述。名字和描述。名字和描述都是用来介绍一个算子或者节点是在做什么操作,但是他们会被用在不同地方。
名字会用在用户界面、线程名、日志、指标等场景。节点的名字会根据节点中算子的名字来构建。 名字需要尽可能的简洁,避免对外部系统产生大的压力。
someStream.filter(...).setName("filter").setDescription("x in (1, 2, 3, 4) and y > 1");
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!