编译原理:全片知识难点总结
目录
一、概念
二、词法分析
三。自上而下分析语法——LL语法
1)消除左递归
2) 消除回溯、提左因子 、 FIRST集 和 FOLLOW 集
3)预测分析法 与 FIRST集 和 FOLLOW 集的构建。
4)预测分析法中 预测分析表M的构建
四、自下而上的分析语法——算符优先分析法
1)对每个非终结符构建FIRSTVT 集 和LASTVT 集
2)构造算符优先关系表
五、语义分析
1)赋值语句和的简单算数运算表达式的翻译
2)布尔表达式的翻译方法
3)典型控制语句的翻译方法
六、目标代码生成
1)基本块划分
2)寄存器选择——寄存器的待用信息与活跃信息的确定
七、中间代码的优化
(1) 基于DAG图的优化方法
一、概念
1)字母表、字符串、字符串和运算
- 字母表用 Σ 表示,是字符的非空有穷集合,字符是字母表Σ的元素
- 字符串,是字母表Σ中字符组成的有穷序列,其长度用 |<字符串>| 表示。空串用是ε表示, |ε| = 0
- Σ* 指包括空串在内的Σ上所有字符串的集合。称之为字母表的闭包。
- 字符串的方幂: 例如
,指 连续n个a字符
- 对于集合A的正则闭包 +
- 对于集合A的闭包 * ,
文法分类分为0型文法,1型文法,2型文法,3型文法,分别又称为短语文法,上下文有关文法,上下文无关文法,正规文法 。
- 0型文法,短语文法: 每个产生式 α ->β 左部α中至少又一个非终结符
- 1型文法,上下文有关文法: 在0型文法的基础上,还满足 |α| <= |β|
- 2型文法: 每个产生式 A->β ,其中A 是非终结符 , β是终结符和非终结符的闭包。
- 3型文法:每个产生式 A->αB 或 A ->α 的形式,其中A和B 是非终结符,α是终结符
四元式:是 ( op ,arg1,arg2,result) 形式的一个对象,其中op 表示中间代码的操作符,result 表示 运算结果的临时变量。
后缀式、逆波兰式:在抽象语法树中的后续遍历得到的式子。例如a+b(中序)改写成后缀式为ab+
二、词法分析
单词分为关键字、算符、标识符、常数、介符。词法分析的目标是为了将代码分解成对应的单词,并对单词打上些有意义的编码,给后续的语法分析和语义分析使用。
| 单词 | 编码 | 单词 | 编码 | 单词 | 编码 | 单词 | 编码 |
| end | 1 | or | 11 | ( | 21 | := | 31 |
| begin | 2 | program | 12 | ) | 22 | = | 32 |
| bool | 3 | real | 13 | + | 23 | <= | 33 |
| do | 4 | then | 14 | - | 24 | < | 34 |
| else | 5 | true | 15 | * | 25 | <> | 35 |
| end | 6 | var | 16 | / | 26 | > | 36 |
| false | 7 | while | 17 | . | 27 | >= | 37 |
| if | 8 | 标识符 | 18 | , | 28 | ||
| integer | 9 | 整数 | 19 | : | 29 | ||
| not | 10 | 实数 | 20 | ; | 30 |
对代码进行按行读取,判断每个单词是否属于关键字,或者介词、标识符还是标识符等。大致方式
为:按行读取,逐各读取字符并将每个字符假如一个字符缓存变量中,读取的字符如果是空格、换行、或者介词、运算符(对应表格代码是21~37)的话,则缓存变量中是一个完整的单词。对着单词表对单词打上编码,如果不存在则为标识符..
三。自上而下分析语法——LL语法
1)消除左递归
对于类似的产生式 “ A ->Aα | β ”都可以化简成
A -> βA'
A' -> αA' | ε
实际上对于产生式都可以化简成
和
2) 消除回溯、提左因子 、 FIRST集 和 FOLLOW 集
对所有非终结符的A的每个候选是α,定义其终结首符集,FIRST
对所有非终结符的A的每个候选是α,定义其后随符号集,FOLLOW
3)预测分析法 与 FIRST集 和 FOLLOW 集的构建。
统计每个非终结符的 FIRST 和FOLLOW 集 ,并构建预测分析表。
例如:对应文法G[E]:
E → E + T | T
T → T * F | F
F →( E ) | i
现有输入串 i *(i + i) ,判断其语法是否正确?
首先先消除左递归,得到新文法如下
E → T E' .....①
E' → + T E' | ε .....②
T → F T' ....③
T' →*FT' |ε ....④
F →( E ) | i .....⑤
因此,有非终结符 E, E',T, T', F.构建FIRST集的过程为
- 自下而上遍历对应的产生式,把产生式右边的首终结符加入到产生式左边的FIRST中因此
FIRST(F) = { ( , i ...} FIRST(T') = { * , ε ...} FIRST(E’) = { + , ε ....}
- 对于 A →B....类似的文法应该把 FIRST(B) 也加入到 FIRST(A)中因此
FIRST(F) = { ( , i } FIRST(T') = { * , ε} FIRST(E‘) = { + , ε}
FIRST(T) ={ ( , i } FIRST (E) ={ ( , i }
构建FOLLOW集的过程为:自上而下遍历对应的产生式形如 S → ABC,
- 把FIRST(C) / {ε}加入到FOLLOW(B)中,如果C是终结符, 那么终结符的FIRST集就是它自身,即FIRST(C) ={ C },
- 把 FOLLOW(S)加入到 FOLLOW(C)中,如果C 可以间接推出 ε ,即ε∈ FIRST(C),那么把 FOLLOW(S)也加入到FOLLOW(B)中,
- 往起始产生式的FOLLOW加入 ‘#’ 起始符。
因此上述文法的
FOLLOW (E) = { # , ) } ....(第3个条件、⑤式匹配第一条件)
FOLLOW(E') = FOLLOW(E) = { # , ) } (①式匹配第4个条件)
FOLLOW(T) =FIRST(E')/{ε} ∪ FOLLOW(E) ={ + ,),# } (②式匹配第一条件,①式匹配第二条件)
同理:
FOLLOW (T' ) = FOLLOW(T) = { + ,),# }
FOLLOW(F) = FIRST(T')/{ε} ∪ FOLLOW(T) ∪ FOLLOW(T')={ * , + ,),#}
4)预测分析法中 预测分析表M的构建
- 遍历每个产生式 A ->α,对每个终结符 a ∈ FIRST(A) , 将 A->α 加入到 M[A,a]中,
- 如果 ε ∈ FIRST(A),则对任何终结符b ∈ FOLLOW(A),将 A->ε 加入到 M[A,B]中
因此,预测分析表如下:
| i | + | * | ( | ) | # | |
| E | E → T E' | E → T E' | ||||
| E' | E' → + T E' | E' →ε | E' →ε | |||
| T | T → F T' | T → F T' | ||||
| T' | T' →ε | T' →*FT' | T' →ε | T' →ε | ||
| F | i | F →( E ) |
语法分析过程:
分析栈的起始状态为 #<起始非终结符> ,如果分析栈的输入串的待匹配字符 和 分析栈顶元素按照预测分析表进行化简,如果栈顶和待匹配字符一致则匹配,如果都不满足则输入串语法错误。
| 步骤 | 分析栈 | 输入串 | 备注 |
| 1 | #E | i *(i + i)# | E → T E' |
| 2 | #E'T | i *(i + i)# | T → F T' |
| 3 | #E'T'F | i *(i + i)# | F →i |
| 4 | #E'T'i | i *(i + i)# | 匹配 |
| 5 | #E'T' | *(i + i)# | T' →*FT' |
| 6 | #E'T'F* | *(i + i)# | 匹配 |
| 7 | #E'T'F | (i + i)# | F →( E ) |
| 8 | #E'T')E( | (i + i)# | 匹配 |
| 9 | #E'T')E | i + i)# | E → T E' |
| 10 | #E'T')E'T | i + i)# | T → F T' |
| 11 | #E'T')E'T'F | i + i)# | F →i |
| 12 | #E'T')E'T'i | i + i)# | 匹配 |
| 13 | #E'T')E'T' | + i)# | T' →ε |
| 14 | #E'T')E' | + i)# | E' → + T E' |
| 15 | #E'T')E'T+ | + i)# | 匹配 |
| 16 | #E'T')E'T | i)# | T → F T' |
| 17 | #E'T')E'T'F | i)# | F →i |
| 18 | #E'T')E'T'i | i)# | 匹配 |
| 19 | #E'T')E'T' | )# | T' →ε |
| 17 | #E'T')E' | )# | E' →ε |
| 18 | #E'T') | )# | 匹配 |
| 16 | #E'T' | # | T' →ε |
| 17 | #E' | # | E' →ε |
| 18 | # | # | 匹配 |
| 19 | 语法正确 |
四、自下而上的分析语法——算符优先分析法
对于一个文法,如果其每个产生式的右部都不含两个相邻的非终结符,形如:S->.....QR....,则为算符文法。
假如G 是一个不含 ε 的算符文法
a =· b : 当且仅当文法G含有 S -> ...ab... 或 S -> ...aQb...
a <· b : 当且仅当文法G含有 S -> ...aQ... 且 Q ->b... 或 Q ->Rb
a >· b : 当且仅当文法G含有 S -> ...Qb... 且 Q ->...s 或 Q ->....aR
当一个算符文法的任意终结符(a,b) 最多只满足a =· b,a <· b,a >· b 关系之一,则该文法为算符优先文法。也就是说,任意一对终结符,最多只有一种优先关系成立。
例如、对于文法
E' -> #E# .......①
E -> E+T |T ........②
T -> T * F | F ........③
F->P ↑ F | P .........④
P -> (E) | i ...........⑤
用算法优先分析输入串为 ( i+i )*i
1)对每个非终结符构建FIRSTVT 集 和LASTVT 集
FIRSTVT(P) 和 LASTVT (P)表示 非终结符P可推出产生式的第一个终结符和最后一个终结符集合
FIRSTVT (P ) = { a | P => a... 或 P => Qa.... ,a ∈ 终结符, Q∈非终结符}
LASTVT (P ) = { a | P => ....a 或 P =>.....aQ ,a ∈ 终结符, Q∈非终结符}
因此可以自下而上的用下面的规则构造FIRSTVT,
- 若有产生式 P->a. 或 P -> Qa.... ,则 a∈FIRSTVT (P )
- 若有 a∈FIRSTVT (Q) 且有产生式 P-> Q... 则,a∈FIRSTVT (P )
同理,可以自下而上的用下面的规则构造LASTVT,
- 若有产生式 P->....a 或 P ->.....aQ ,则 a∈LASTVT (P )
- 若有 a∈LASTVT (Q) 且有产生式 P-> ....Q 则,a∈LASTVT(P )
FIRSTVT (P) = { (,i } LASTVT(P') ={ ),i}
FIRSTVT (F) = {↑,(, i} LASTVT(F) = {↑, ),i}
FIRSTVT (T) = {*,↑,(, i} LASTVT (T) = {*,↑,), i}
FIRSTVT (E) = {+,*,↑,(, i} LASTVT (E) = {+,*,↑,), i}
FIRSTCT (E') = {#} LASTVT (E') = {#}
2)构造算符优先关系表
形如有产生式 ....aP.....,那么对任何 b ∈ FIRSTVT(P) ,都有 a <· b
形如有产生式 ....Pb.....,那么对任何 a ∈ LASTVT(P) ,都有 a >· b
遍历每个产生式因此算符优先关系表如下
| + | * | ↑ | i | ( | ) | # | |
| + | >· | <· | <· | <· | <· | >· | >· |
| * | >· | >· | <· | <· | <· | >· | >· |
| ↑ | >· | >· | <· | <· | <· | >· | >· |
| i | >· | >· | >· | >· | >· | ||
| ( | <· | <· | <· | <· | <· | =· | |
| ) | >· | >· | >· | >· | >· | ||
| # | <· | <· | <· | <· | <· | =· |
当分析栈顶元素与输入缓冲区的第一个字符作优先对比,如果是<· 则将缓冲区的第一个字符移进分析栈中即push分析栈,如果是>·则进行规约,即pop分析栈。如果是=·那么缓冲区的第一个字符和分析栈顶同时移除
| 步骤 | 分析栈 | 输入缓冲区 | 备注 |
| 1 | # | ( i+i )*i# | #<·(,移进 |
| 2 | #( | i+i )*i# | (<·i,移进 |
| 3 | #(i | +i )*i# | i>·+,规约 |
| 4 | #( | +i )*i# | (<·+移进 |
| 5 | #(+ | i )*i# | +<·i,移进 |
| 6 | #(+i | )*i# | i>·),规约 |
| 7 | #(+ | )*i# | +>·),规约 |
| 8 | #( | )*i# | ( =· ) ,同时移出 |
| 9 | # | *i# | #<·*,移进 |
| 10 | #* | i# | *<·i,移进 |
| 11 | #*i | # | i>· #,规约 |
| 12 | #* | # | *>· #,规约 |
| 13 | # | # | # =·# ,同时移出 |
| 语法正确 |
五、语义分析
语义分析的主要目的是为了在语法分析中规约、匹配、接受等时执行相应的动作指令,最终生成一组四元式,四元式可以为接下来的中间代码生成中解析。
对于算符文法语法语义分析的流程图大致如下

在文法翻译可以粗略地分为:声明语句的翻译、赋值语句的翻译、简单算数运算表达式的翻译,布尔表达式的翻译、控制语句的翻译。其中声明语句的翻译涉及符号表相关动作,非本文重点。
动作函数及属性说明如下:
- Entry(id) :在符号表中标识符id的位置
- S.code : 语句S对应的后缀式代码序列
- E.place : 与非终结符E相联系的临时变量地址
- E.true : 当E的表达式为真时,控制流转向的语句编号(四元式编号)
- E.false : 当E的表达式为假时,控制流转向的语句编号(四元式编号)
- Gen(op,arg1,arg2,result) : 创建四元式,属性result默认值为空。
- nextquad:下一个生成的四元式编号,即比当前最大的四元式编号多1。执行一次Gen,nextquad就加1,
- E.quad:E对应的四元式编号,
- S.next : S对应的代填转移链,通常在S规约后,回填S.next集合中对应的跳转四元式
- Merg(P1,P2), 把四元式链表P1 和链P2,并返回新链的链首指针
- Backpatch (p,t) :把t回填到四元式链表P中每一个节点(四元式)中的result项。
- Newtemp() : 生成一个临时变量
注:产生式S统一计为语句;E计为表达式,L计为语句块 , A 为赋值语句,M为语句块的起始四元式编号,N语句块的结束四元式编号
1)赋值语句和的简单算数运算表达式的翻译
| 产生式 | 语义动作 |
| A->id := E | {Gen(":=" , E.place, "_" , Entry(id)) } |
| E -> E1 + E2 | {E.place = Newtemp() ; GEN("+",E1.place,E2.place,E.place) } |
| E -> E1 * E2 | {E.place = Newtemp() ; GEN("*",E1.place,E2.place,E.place) } |
| E -> -E1 | {E.place = Newtemp() ; GEN("minus",E1.place,"_",E.place) } |
| E-> ( E1 ) | E.place =E1.place |
| E -> id | E.place = Entry(id) |
2)布尔表达式的翻译方法
注:rel_op为布尔运算符
| 产生式 | 语义动作 |
| E -> E1 or ME2 | {backpatch(E1.false, M.quad) ; E.true := merge(E1.true , E2.true); E.false := E2.false} |
| E -> E1 and ME2 | {backpatch(E1.true, M.quad) ; E.true := E2.true ; E.false := merge(E1.false,E2.false)} |
| E -> not E1 | E.true := E1.false ; E.false := E1.true ; |
| E-> ( E1 ) | E.true :=E1.true ; E.false :=E.1false |
| E-> id rel_op id | {E.true :=nextquad ; E.false := nextquad+1 ; Gen( "j Gen("j" ,"_" ,"_",0); } |
| E -> id | {E.true :=nexquad ; E.false := nexquad+1 ; Gen( "jnz" , id1.place , "_" ,0 ); Gen("j" ,"_" ,"_",0); } |
| M ->ε | M.xq =nextquad |
例如:布尔表达式 “ a
因为对于自下而上的语法分析中,语义动作是在产生式规约的时候发生的,所以语义执行顺序是按照逆波兰式顺序执行的
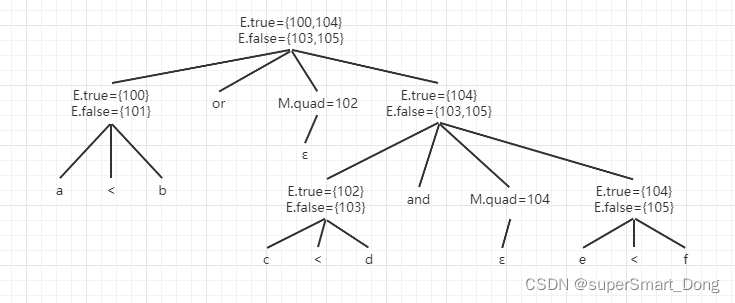
首先发生规约的是 E -> a
100 :("j<" , a,b,0)
101: (j,_,_0)
接下来发生规约的是M ->ε ,此时nextquad下一个四元式编号是102,再接下来发生规约是E ->c < d
102 :("j<" , c,d,0)
103: (j,_,_0)
接下来发生规约的是M ->ε ,此时nextquad下一个四元式编号是104,再接下来发生规约是E ->e < f
104 :("j<" , e,f,0)
105: (j,_,_0)
接下来发生规约的是 E -> E1 and ME2 ,见上表对应的语义动作是把 M.quad回填到E1.true控制流四元式的跳转值。即backpatch(102, 104),修改编号102的四元式成 102 :("j<" , c,d,104)
接下来发生规约的是 E -> E1 or ME2 ,见上表对应的语义动作是把 M.quad回填到E1.false控制流四元式的跳转值。即backpatch(101, 102),修改编号101的四元式成 101: (j,_,_102)
因此 此布尔表达式得到的最终序列是:
100 :("j<" , a,b,0)
101: (j,_,_102)
102 :("j<" , c,d,104)
103: (j,_,_0)
104 :("j<" , e,f,0)
105: (j,_,_0)
上述四元式的含义是
100:如果 a
101:直接跳转到102号四元式
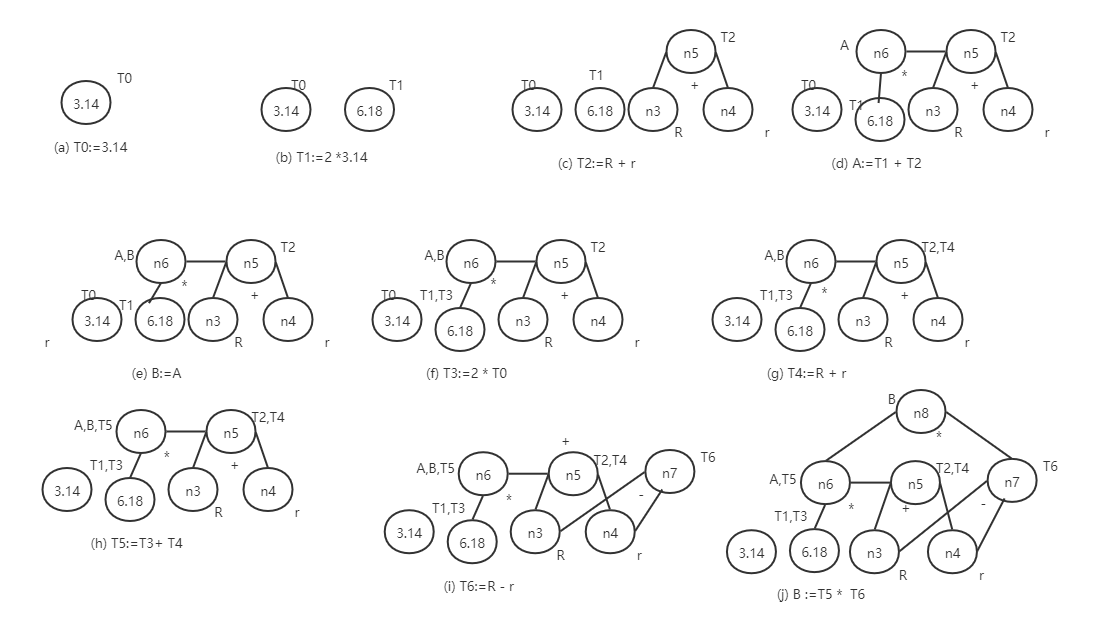
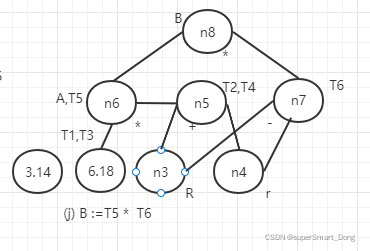
102:如果 c ........ {backpatch(E.true, M.quad) ; S.next := merge(E1.false , S1.next); } {backpatch(E.true, M1.quad) ; backpatch(E.false, M2.quad) ; S.next:= merge(S1.next,N.next,S2.next)} {backpatch(S.next, M1.quad) ; backpatch(E.true, M2.quad) ; S.next:=E.false; Gen(" j ",_ , _ M1.quad)} S.next = L.next S.next 初始化 backpatch(L1.next, M.quad) ; L.next =S.next N.next =nextquad ; Gen(" j ", _ ,_ ,0) 例如:程序语句 的四元式序列?设序列起始值为100 :还是画语法树并自下而上按照逆波兰式顺序规约填写控制流 总结一下: 因此:得到下述四元式,用T来表示临时变量 100: ("j>" ,a,0,102) 101: (" j " ,_,_,0) 102:(" j<" ,x,0,104); 103: (" j " ,_,_,0) 104:(" +" ,x,1,T1) 105:(":=",T1,_,x ) 106:(" j>" ,a,0,110) 107:(" j " ,_,_,108) 108:(" j<",b,0,110) 109:(" j ",_,_113) 110:(" - ",a,1,T2) 111:(":=",T2,_,x) 112: (" j ",_,_,100) 113:( " - " ,b,1,T3) 114:(" :=",T3,_ ,b) 115"(" j ",_,_,100) 0: 程序结束 目标代码生成的任务是为了把四元式序列转化成对应的代码。而这个转化后的代码通常是汇编语言。在上例中的的伪Pascal文法下的代码片段,其每一个四元式都有对应的含义。例如四元式102:(" j<" ,x,0,104) 对应的意义是当 x<0 时跳转到104号四元式。对应的汇编代码是: CMP x,0 JE <代码块标签名称> 类似的 指令码 意义 条件 JZ, JE 结果为0或相等则转 Z=1,(A) = (B) JNZ, JNE 结果不为0或不相等则转 Z=0,(A)≠(B) JNL, JGE 大于等于转(不小于) (S∨O)=0,(A)≥(B) JL, JNGE 小于转(不大于等于) (S∨O)=1,(A)<(B) JG, JNLE 大于转(不小于等于) (S∨O∨Z)=0,(A)>(B) JMP 那么 <代码块标签名称> 该怎么确定呢? 代码块标签名称通常是自定义的,通常是当作 goto语句的跳转代码位置。而四元式的基本块相当于程序语言的语句块,就是一堆顺序执行的语句序列。而基本块入口的确定满足以下条件的其中一个就行: 最后,相邻两个基本块入口之间的四元式构成一个基本块(其中包含前者入口,不包含后者入口)。跳转语句的跳转位置也就是基本块的名字。 对于上例的四元式序列划分的基本块如下: 因此:102:(" j<" ,x,0,104) 要跳转的104四元式对应的的基本块GOTOBLOCK5因此对应的目标代码是: 除了比较跳转的四元式外,:还有四则运算和赋值语句 赋值语句对应的是: MOV 变量名 ,<寄存器名称> , 而四则运算对应的代码则为 每个寄存器只能存一个值,因此如何选择寄存器是目标代码生成的一个重点 在同一个基本块中,如果中间代码(四元式) i 对 A 定值,中间代码 j 引用了 A 值,且从 i 到 j 之间没有 A 的其他定值,则 j 是代码 i 中变量 A 的待用信息 ,且 A在 i 处是活跃的。 通俗来讲,就是存在寄存器里的值还需要被后续代码 j 引用到,那么就 j 使用的寄存器就应该是 A ,且 i 到 j 之间的代码不能使用寄存器A。 即 代码 j 待使用 A 的值 ,A的值是来源于代码 i。 对于变量待用信息的计算: (1)开始时,把基本块中各个变量在符号表中的待用信息域初始化为“非待用”,根据基本块出口之后是否活跃(变量生命周期是否结束)来初始化活跃信息域 "活跃" 或 "非活跃"。 (2)由后向前遍历从基本块出口至基本块入口中的每一行中间代码形如 ( op , B , C, A) 或 ( := , B ,_, A)形式的依次执行以下步骤: 例如:某一个基本块的中间代码序列如下,假设基本块结束后W时活跃变量,假设由R1,R2,R3寄存器,写出目标代码; ① T := A +B ② U := A - C ③ V := T + U ④ W := V + U 由④遍历到①代码得到待用信息与活跃信息表 非待用 非活跃 非待用 非活跃 非待用 活跃 非待用 非活跃 非待用 活跃 非待用 非活跃 非待用 非活跃 非待用 活跃 非待用 非活跃 非待用 活跃 所以当代码执行到 ①时,存放值B的寄存器使用完了可以直接释放,存放A值的寄存器要等代码②执行完,才可以释放,存放值T的寄存器要等代码③执行完才变成"非待用"后可以释放。 同理类推....得到目标代码 最后:五-3 示例中得到的目标代码为 中间代码的优化有三个原则:等价原则,有效原则,合算原则。即优化后的效果必须要和原来一致,不会增加无效代码,并且对性能有提高的。每个对于不可达代码,可以画流图来确认哪些基本块是永远没机会执行的,对于这些不可达的基本块可以直接从代码中删除。对于算数计算的优化可以用有向无环图(DAG)进行代码优化。原理大致是,每一个节点代表一个值可以被一个或多个变量引用。然后重写语句。 例如、给定某个基本块代码如下: 常量是叶子节点,计算符是内部节点 最后得到的DAG图是 确认哪个是基本块退出后的活跃变量,(假设是 B),以活跃变量为根节点,删除非活跃变量的引用,但是每个内部节点要保留至少一个引用,叶子节点保留值就行。 假设基本块退出后的只有一个活跃变量,优化后的中间代码可以为: T2 := R - r T6 := R + r A := 6.18 * T2 B := A * T6 3)典型控制语句的翻译方法
产生式 语义动作 S -> if E then MS1 S -> if E then M1 S1 N else M2 S2 E -> while M1 E do M2 S1 S-> Begin L end S -> A L -> L1 ; MS L -> S L.next =S.next M ->ε M.quad =nextquad N->ε while a > 0 and x < 0 do begin x := x +1 ;if a > 0 or b <0 then a := a-1 else b := b -1end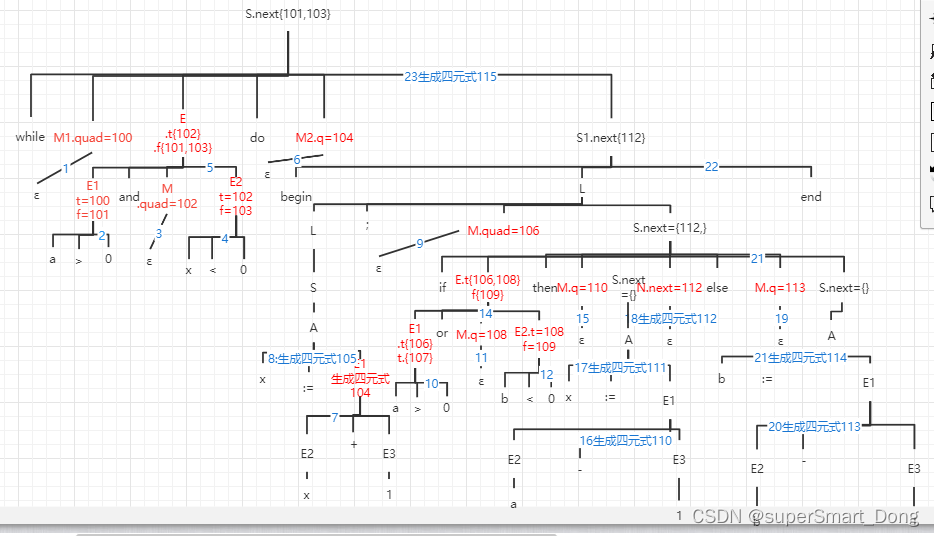
六、目标代码生成
无条件转移 1)基本块划分
---------GOTOBLOCK1------------
100:("j>" ,a,0,102)
---------GOTOBLOCK2------------
101:(" j " ,_,_,0)
---------GOTOBLOCK3------------
102:(" j<" ,x,0,104)
---------GOTOBLOCK4------------
103:(" j " ,_,_,0)
---------GOTOBLOCK5------------
104:(" +" ,x,1,T1)
105:(":=",T1,_,x )
106:(" j>" ,a,0,110)
---------GOTOBLOCK6------------
107:(" j " ,_,_,108)
---------GOTOBLOCK7------------
108:(" j<",b,0,110)
---------GOTOBLOCK8------------
109:(" j ",_,_113)
---------GOTOBLOCK9------------
110:(" - ",a,1,T2)
111:(":=",T2,_,x)
112:(" j ",_,_,100)
---------GOTOBLOCK10------------
113:( " - " ,b,1,T3)
114:(" :=",T3,_ ,b)
115"(" j ",_,_,100)
---------END--------------------CMP x,0
JE GOTOBLOCK52)寄存器选择——寄存器的待用信息与活跃信息的确定
序号 中间代码 T A B C U V W ④ W := V + U ③ V := T + U 4,活跃 4,活跃 ② U := A - C 3,活跃 3,活跃 4,活跃 ① T := A +B 3,活跃 2,活跃 2,活跃 3,活跃 4,活跃 MOV R1 , A
MOV R2 , B
ADD R2 , R1 --B值以后用不到了R2释放,R2用来存T
MOV R3 , C
SUB R1 , R3 -- C以后用不到了R3释放 ,A值以后用不到了R1释放,R1用来存U
ADD R2 , R3 -- T值以后用不到了R2释放,R2用来存 V
ADD R1 , R2 -- U值以后用不到了R1释放,V值以后用不到了R2释放,R1用来存W
CODEBLOCK1:CMP a , 0JG CODEBLOCK3
CODEBLOCK2:JMP CODEEND
CODEBLOCK3:CMP x , 0 JL CODEBLOCK5
CODEBLOCK4:JMP CODEEND
CODEBLOCK5:MOL AX , xADD AX , 1MOV x ,AXCMP a , 0 JG CODEBLOCK9
CODEBLOCK6:JMP CODEBLOCK8
CODEBLOCK7:CMP b,0JL CODEBLOCK9
CODEBLOCK8:JMP CODEBLOCK10:
CODEBLOCK9:MOL AX , aSUB AX , 1MOV x ,AXJMP CODEBLOCK1
CODEBLOCK10:MOL AX , bSUB AX , 1MOV b ,AXJMP CODEBLOCK1
CODEEND:
七、中间代码的优化
(1) 基于DAG图的优化方法
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!