时序图 分支_BOOM微架构学习(1)——取指单元与分支预测

之前在RISC-V的“Demo”级项目——Rocket-chip一文中曾经简介过BOOM处理器的流水线,这次我们开始一个系列,深入学习一下BOOM的微架构,这样对于乱序执行的超标量处理器会有一个较为深入的认识。
本系列计划按照流水线的前后顺序,第一篇讲前端的取指和分支预测,第二篇讲译码和寄存器重命名,第三篇介绍ROB和指令的发射,第四篇介绍指令的执行和Bypass机制,第五篇讲BOOM的访存和存储系统, 最后从使用的角度来讲一下BOOM中的Chisel Parameter配置方式。
本文是BOOM系列的第一篇,先从取指单元以及BOOM的分支预测器入手。
BOOM的取指单元
在介绍取指单元之前先回顾两个概念方便下文讨论:一个叫前端(Front-end),指流水线中的取指和分支预测部分,这一部分将指令从I-Cache中取出;另一个叫后端(Back-end),指流水线中从派发到写回阶段的这一部分,也就是指令的执行阶段。
BOOM的前端如下图所示,它包括取指和分支预测在内共划分为5个周期(从F0到F4)。当后端发现分支预测错误,或者分支预测器预测需要改变取指的位置,就会给前端发一个请求,前端就会从新的PC开始取指令。
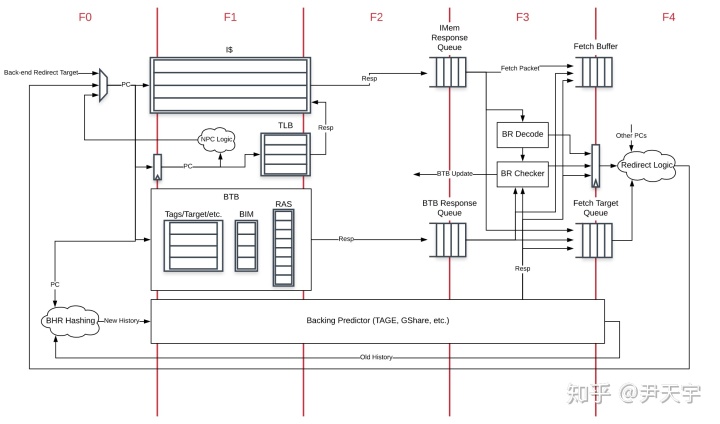
BOOM并不是每次从I-Cache中取一条指令,而是一次从指令缓存中取出一个Fetch Packet的指令(就像是批发一样,一次批发一包指令进来)。之后对这些指令进行快速译码(为分支预测提供信息),并写到Fetch Buffer(Fetch Buffer是一个将前后端解耦的指令队列)中供后端使用;同时将给后端用的PC和分支预测信息则写到Fetch Target Queue中(Fetch Target Queue保存着从I-Cache取得的指令的地址以及地址对应的分支预测信息;当指令被提交后,ROB会从Fetch Target Queue中取出该指令的相应信息;当取指单元重定向时Fetch Target Queue会被更新)。
另外,BOOM必须要考虑RVC指令,RVC指令是RISC-V标准中规定的16位压缩指令,目的在于减少程序代码空间大小。取RVC指令给处理器带来了很大的挑战,主要在于加入了16位指令以后,原有的32位指令不再是要求4字节对齐的了,这样一来有的指令是从半字节位置开始,找到一条指令的起始位置就变得困难;而且译码的复杂度也增加了(操作数的位置不再固定为指令低7位);每次PC的自增也不再是简单的PC+4。
这样,一条指令从指令缓存中取出来,到写入Fetch Buffer之前,要经历如下的过程: 1. Fetch Packet的大小为fetchWidth*16位,在F2周期每次从I-Cache中取出一个Fetch Packet大小的指令存放到IMem Response Queue中, 2. 在F3周期中维护取指“状态”,包括上一个Fetch Packet的最后16位(有可能上一个Fetch Packet的最后16位和本Fetch Packet的前16位共同组成一条指令)、PC等,用于解决RVC指令的若干问题。F3中还包括了预译码单元,用于确定每条指令的起始位置。 3. 在存到Fetch Buffer前将无效指令去掉
BOOM的分支预测
接下来我们来讨论BOOM的分支预测机制。 BOOM使用了两级分支预测,第一级是快速而简单的Next-Line Predictor(NLP),第二级是慢速而复杂的Backing Predictor(BPD)。
Next-Line Predictor(NLP)
总的来说BOOM的NLP是由一个全相连的Branch Target Buffer(BTB)、一个双峰表(BIM)以及一个返回地址栈(RAS)组成的快速而“相对”准确的预测器。它可以根据当前PC在一个周期内(通过组合逻辑)完成预测,在大多数情况下BOOM使用NLP可以快速作出分支预测的决定。
NLP的预测
NLP中的BTB如下图所示。和一般简单的处理器不同的是,NLP的预测不是基于某条指令进行分支预测的判断,而是根据一整个Fetch Packet进行判断。 每次预测时,NLP首先将Fetch PC(即当前Fetch Packet的开头的地址)和BTB中的PC tags进行匹配, 如果发现有匹配上的项,BTB和RAS一起判断该Fetch Packet中是否包含分支、跳转或者返回指令,以及具体是哪条指令发生了跳转(记录在BTB的bidx字段中)。
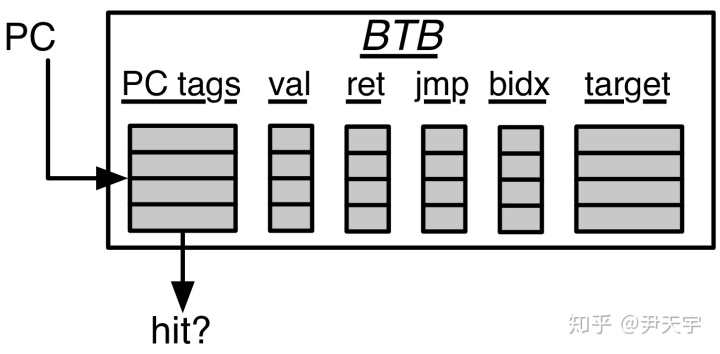
当确定某条指令为分支指令时,NLP会查询BIM表来决策跳转还是不跳转;当确定某条指令为返回指令时,NLP会查询RAS来确定下一次取指的Fetch PC。
NLP的更新
当前端发生重定向、后端发出了跳转请求(一般意味着分支预测错误)或者BPD做出了分支预测时,BTB会更新或创建新的表项。
当前端的预先译码发现某指令为“Call”指令时(RISC-V并没有专门定义的Call指令,BOOM通过JAL和JALR指令的目标寄存器为x1判定该指令为调用指令),会将它的PC和它的目标PC压入RAS中;当发现某条指令为返回指令时,将该项从RAS中弹出。
Backing Predictor(BPD)
介绍完了简单的NLP(实际上确实很简单,很短的篇幅就把NLP的工作过程讲清楚了),接下来本段要讲的第二级分支预测器BPD就比较复杂了。
正常情况下NLP在预测正确的情况下,后端可以不间断地执行指令。 但NLP在具有简单快速的优点的同时也带来了很多缺点:比如面积和功耗较大、BTB的存储空间有限,只能存储几十个分支、BIM的机制太过简单,无法应对复杂的跳转情况。
为了解决这些问题BOOM提供了BPD,它的目标是利用很小的面积来作出相当高准确率的判断;BPD只能判断某条分支指令(无条件跳转指令不在BPD的职责范围之内,它们由NLP和后端共同负责处理)是否需要跳转,而无法给出哪些指令是分支指令以及它们跳转的目标是什么(这些信息可以从BTB中获得,也可以从F3周期的预先译码模块中获得)。 当BPD作出预测时,它会给出一个比特序列,该序列的长度与配置的Fetch Width相同,即对Fetch Packet中的每条指令给出“跳转”或“不跳转”的决策(当然只有分支指令对应的比特位才是有意义的),在F3周期会对Fetch Packet中的指令进行预先译码,解出每条指令的分支目标地址,并结合BPD给出的比特序列决定是否对前端进行重定向。
从本文开头的BOOM前端时序图中可以看出,BPD的作用是横跨整个取指过程的,与访问Cache和NLP的预测并行, 这样就为BPD争取到了三个时钟周期的时间,这样BPD可以将庞大的历史记录存放在SRAM中,而不必须像BTB一样使用寄存器存储,节约了很大的面积。
讲完了BPD在前端的大致作用,接下来我们开始剖析BPD的若干细节。
全局历史寄存器(GHR)
BPD采用了基于全局历史的分支预测设计,它使用全局历史寄存器(Global History Registor, GHR)来预测本条指令是否需要跳转。 GHR中记录了之前N条分支指令的结果。在对某条分支指令进行预测时,GHR根据之前N条分支指令的跳转结果来作出决策,这就意味着GHR必须跟着每条分支指令即时进行更新。而对于BOOM来说,指令只有过了Commit阶段,才能真正“确定”被执行了,此时更新到GHR中才能保证绝对不会出错。 但这对于BOOM来说太晚了,可能同时有多条指令在BOOM的流水线中运行着,也就意味着BPD对于某条分支指令的预测时根据多条指令以前的历史信息进行的判断,准确度是不够的。
因此在BOOM中GHR采用的是推测式更新法,当某条分支指令被预测后,就会更新在GHR中。当后端发现某条分支指令预测错误时,就需要重置并更新正确的GHR,因此对于流水线中正在执行的每条分支指令,均保留了它当时的GHR快照,以便后面需要时进行恢复。
分支预测抽象类
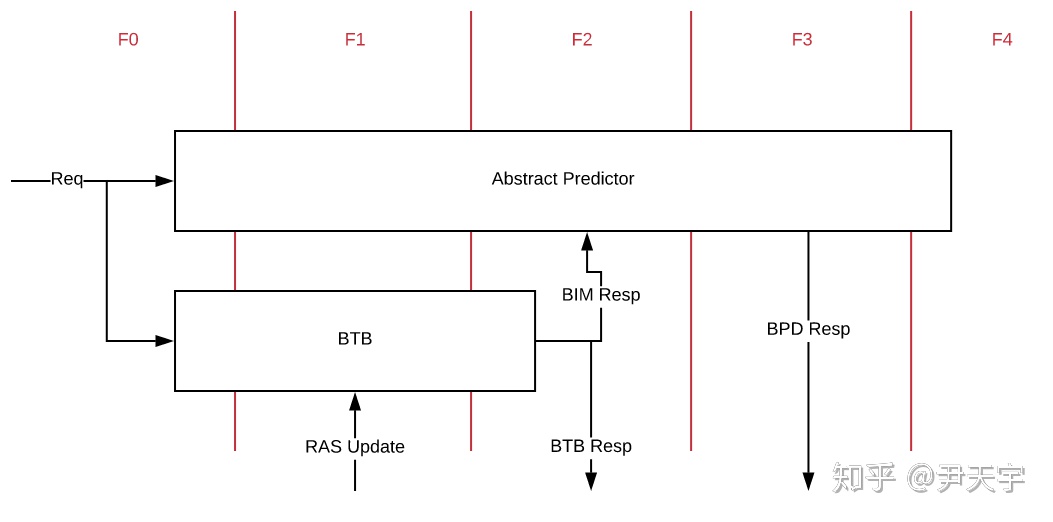
BOOM定义了一个分支预测抽象类BranchPredictor,实现这个类即可为BOOM实现一种新的基于全局历史的分支预测方案。 BranchPredictor为BPD的实现提供了接口以及GHR的控制逻辑,实现类不需要再去处理上文中提到的有关GHR的更新、快照维护等事情,而专注于分支预测的逻辑即可。分支预测抽象类的接口逻辑结构如下图所示。
2-bit计数器表
BPD中专门设计了一个2-bit计数器表(Two-bit Counter Table,简称2BCT)供各种分支预测器使用。 在此先复习一下2-bit计数器的知识,0b11代表“强烈跳转”,而0b00代表“强烈不跳转”;因此,高位代表“是否跳转”,简称P位,而低位代表“强度”,简称H位。
在BOOM中,为了节约面积将2BCT存入SRAM中,对2-bit计数器进行了调整:如果当前状态为0b10,而此次输入为“没有跳转”,则状态直接转移到0b00;如果当前状态为0b01,而此次输入为“跳转”,则状态直接转移到0b11。调整后的时序转移图如下。
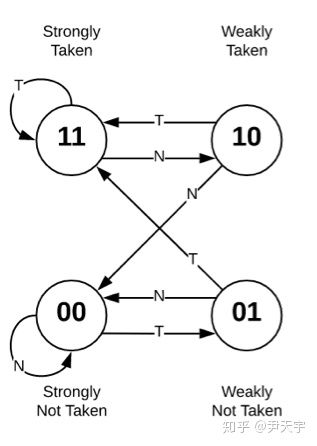
经过这样的调整以后,P位和H位可以在硬件上分开进行设计: 对于P位来说,每次预测时读取从而进行是否跳转的判断,而每次判断错误时则进行取反写入;对于H位来说,在预测错误时进行读取,而每次分支指令执行后进行写入(写入分支结果)。
通过这种设计BOOM将P位和H位分别存储于两个1端口SRAM中。
GShare预测器
本文最后介绍BOOM实现的两种分支预测器,分别是本节将要介绍的GShare预测器以及下一节中的TAGE预测器。
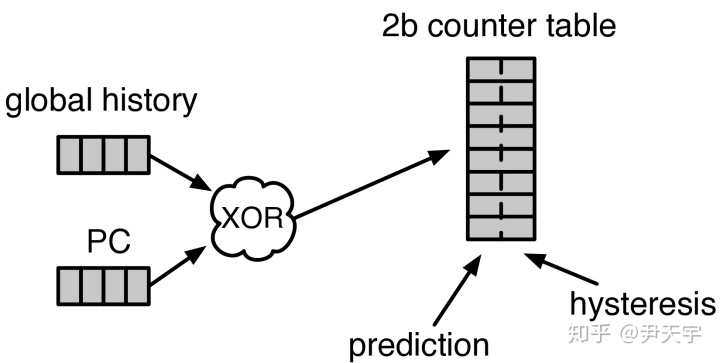
GShare分支预测器实现比较简单,下图为其逻辑框图。它将GHR与指令的PC做异或后,作为2BCT的索引进行查询和更新。
TAGE预测器
TAGE(TAgged GEometric)是一种新型的高度可配置的分支预测算法,它既能快速学习短期历史,也能学习长期历史(可以学习超过1000条分支历史记录)。
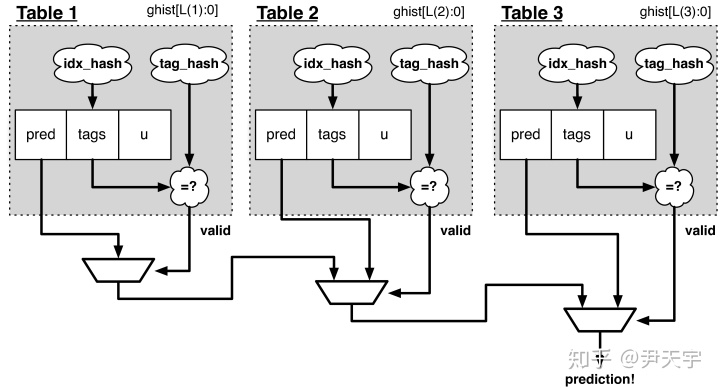
TAGE由一组预测表构成,每张表包括了一个预测计数器、一个有用度计数器以及一个tag。预测计数器用于提供预测,有用度计数器记录着在过去的正确预测中该表项的重要程度,tag用于进行匹配。
TAGE的每一张表都拥有不同长度的历史记录(基本上可以理解为上文中的GHR),每张表的历史记录和要预测的指令PC进行异或得到index hash和tag hash。在每张表中先通过index hash进行索引再通过tag hash进行匹配,根据该表项做出预测。在所有作出预测的表中,选择历史记录最长的表作为最终的预测结果。
有关TAGE的更多细节(可以另写一篇文章)读者可自行搜索学习,本文限于篇幅不再详述。
本文小结
本文作为BOOM微架构学习系列第一篇,介绍了BOOM的取指模块及其分支预测器的设计。在分支预测器部分,介绍了BOOM的两级分支预测:NLP和BPD。其中BPD是基于全局历史的复杂分支预测设计,可以实现多种分支预测算法。本文介绍了Gshare和TAGE两种预测器,当然BOOM也还支持其他的预测器,读者可以自行查阅相关资料。
参考资料
[1] https://docs.boom-core.org/
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!