pycharm安装scrapy失败_Scrapy ——环境搭配与一个简单的例子

在我刚接触爬虫的时候就已经听过Scrapy大名了,据说是一个很厉害的爬虫框架,不过那个时候沉迷于Java爬虫。现在终于要来揭开它神秘的面纱了,来一起学习一下吧
欢迎关注公众号:老白和他的爬虫
1.环境搭配
使用Scrapy的话,我建议使用Anaconda+pycharm的环境配置,首先Anaconda为我们继承好了很多的第三方库非常方便实用,pycharm是一个非常好用的python IDE,如果你不太清楚这两者的配置的话,那么请出门右拐,去这里配置一下环境——Anaconda+pycharm配置,还有如果你是python小白的话,什么环境都没有配,你可能更需要Anaconda,直接安装Anaconda不用自己配环境了。
通过这一步,先使用pycharm建立一个简单的项目,随便你起什么名字,例如我自己起的名字是MyTest,再在这个项目下面新建一个Test1.py的文件
第一次打开pycharm,我们可以在左下角打开控制台和终端的窗口

我们可以在终端输入各种命令非常方便
2.简单例子
把环境配好了之后尝试一个简单的例子,在你新建的Test1.py文件里copy这段代码,还有记得在这步之前去Anaconda里面安装Scrapy,如果你不知道怎么在Anaconda里面安装第三方库的话,那么,出门右拐,Anaconda+pycharm配置
import scrapyclass mingyanSpider(scrapy.Spider):name ="quotes"start_urls =['http://lab.scrapyd.cn/',]def parse(self, response):for quote in response.css('div.quote'):yield{'内容': quote.css('span.text::text').extract_first(),'作者': quote.xpath('span/small/text()').extract_first(),}next_page = response.css('li.next a::attr("href")').extract_first()if next_page isnotNone:yield scrapy.Request(next_page,self.parse)
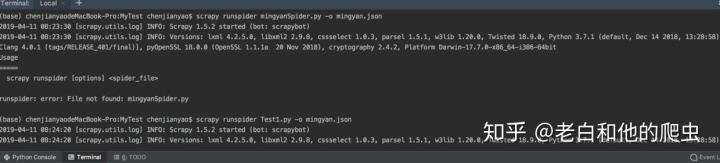
然后我们在终端里输入这段命令
scrapy runspider Test1.py -o mingyan.json
运行成功后看一下你的终端是不是有这样的数据
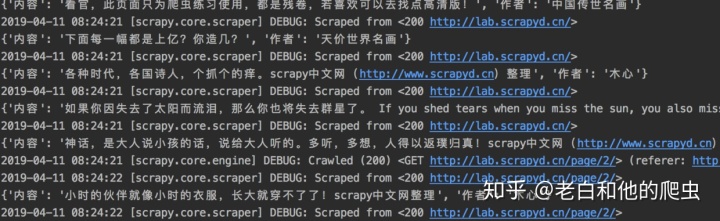
并且你的当前文件夹下面会生成一个mingyan.json文件,虽然里面的文件是unicode编码,但是稍加调整就可以显示正常

好了,能成功运行这个例子你就已经迈出了第一步,主要是把环境搭好,后面好方便写更高级的代码
最后,关注一波吧

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!