论文笔记 | 【CVPR2023】Cascaded Local Implicit Transformer for Arbitrary-Scale Super-Resolution
论文笔记 | 【CVPR2023】Cascaded Local Implicit Transformer for Arbitrary-Scale Super-Resolution

CVPR2023任意超分。
来自清华大学Elsa实验室。
由标题可以知道,模型在LIIF基础上改装,引入了局部注意力,最后加入了一个级联机制。
目录
- 论文笔记 | 【CVPR2023】Cascaded Local Implicit Transformer for Arbitrary-Scale Super-Resolution
- 1 Motivation
- 2 Contribution
- 3 Method
- 3.1 Local Coordinate Sampling
- 3.2 Overview of LIT
- 3.3 Cumulative Training Strategy
- 3.4 Cascaded Local Implicit Transformer (CLIT)
- 4 Experiment
- 5 Ablation study
1 Motivation
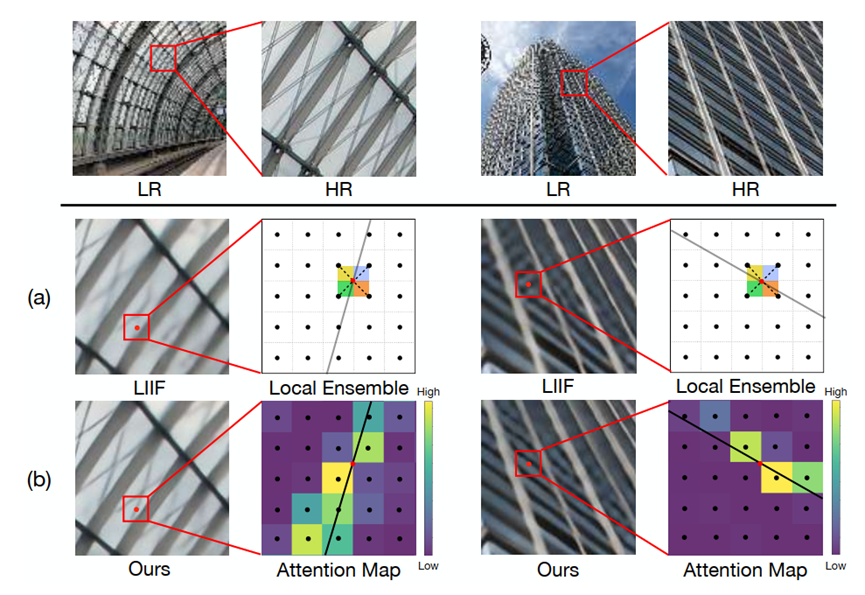
- 1)LIIF的local ensemble只考虑HR像素xq与周围四个最近点的举例,不考虑上下文信息。
文章提出的方案,在某一个范围内生成一个注意力图,其注意力区域与相关点边缘紧密对齐,有效利用上下文信息。 - 2)同时训练大范围不同scale的上采样倍率,为模型带来较大负担。
文章提出累计训练策略,先使用小的scale训练,后用大小scale交替训练进行微调。
2 Contribution
1)在LIIF中引入了局部注意力机制,即LIT(local implicit transformer)。
2)Cumulative training strategy 累计训练策略。
3)级联框架LIT,即CLIT,以处理大scale的上采样。
3 Method
3.1 Local Coordinate Sampling
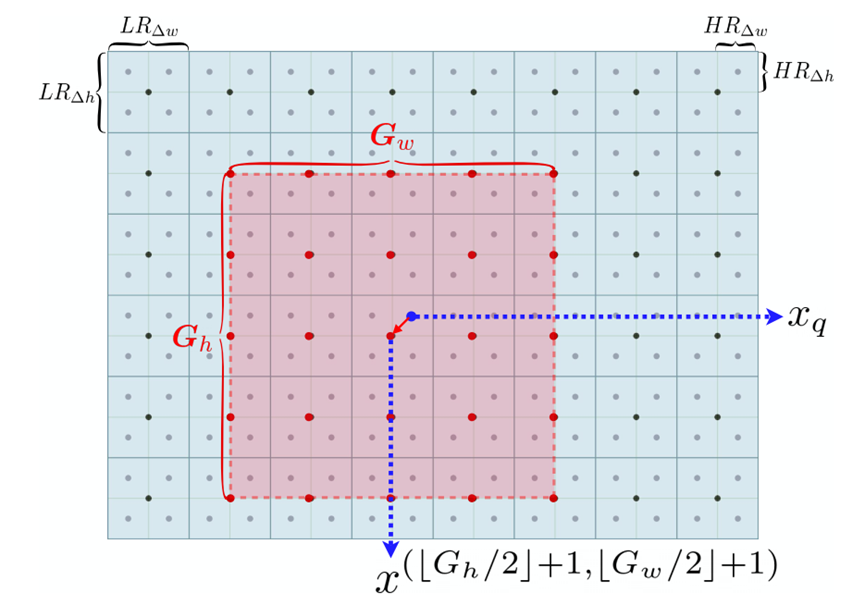
改变一下讲述顺序,先看文章的图3,涉及到如何由HR坐标定位到LR坐标,并且定位到文中图2中使用的特征。
这个代码是在LIIF的基础上改装的,因此它的坐标建立和LIIF一样,把(-1,1)区域分成HW个方格,方格中心坐标作为对应像素的坐标,坐标归一化到(-1,1)。
对于一个待查询的HR坐标xq,可以找到离他最近的一个LR坐标x,以它为中心确立Gh*Gw的一个区域。这个区域就是稍后进行注意力计算的区域。在这个区域里,我们需要额外准备一些变量,以供计算。
HR坐标xq可以确立离他最近的一个LR坐标x,以它为中心确立Gh*Gw的一个区域。
区域共有GhGw个LR像素坐标,对应的可以取到GhGw个11C的LR特征。
另外,xq周围的四个最近的LR特征,可以通过坐标插值出xq处的11C特征。
这就是需要做的准备。
3.2 Overview of LIT
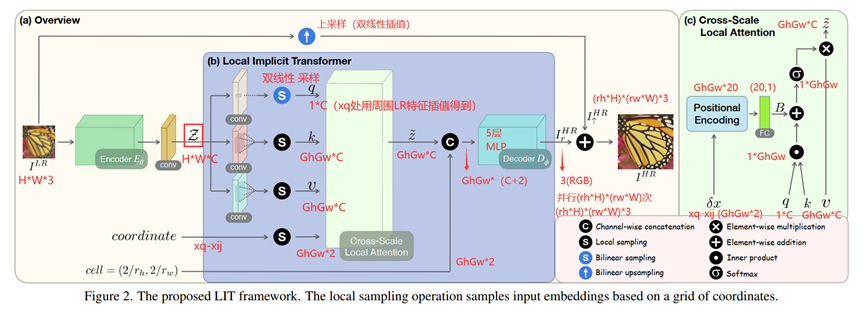
图是这个,经过了维度的标注。
总的来说,是把3通道的HW3图像,经过特征提取网络和一层卷积,然后通过LIT模块得到HR图像的残差,与原来的LR图像经过双线性上采样的结果进行叠加,得到最终的高分图像。
详细说。
HW3的LR图像,经过特征提取网络(EDSR、RCAN或者SwinIR之类都可以)和一个conv层,得到HWC的特征,此为Z。
接下来,对于一个需要查询的HR像素,其坐标为xq而言,通过一次LIT模块,就可以得到xq处像素的RGB值;并行地让(rhH)(rw*W)个HR像素坐标经过LIT模块,就可以重建出一张任意尺度HR图像。
以xq为例。
Z通过三个不同的独立的卷积,再经过不同的采样处理,分别得到qkv矩阵。
其中,q矩阵是:对于HR坐标xq而言,可以找到离xq最近的四个LR坐标,对应到四个11C的LR特征(从Z中采样),用这四个特征双线性插值,得到q矩阵。
k和v矩阵则是通过卷积后,由xq确定最近的一个LR坐标,以这个坐标点为中心,确立一个含有GhGw个LR点的区域,这GhGw个LR点可以采样到GhGwC维度的特征,则为k和v矩阵。
注意力将在这个矩阵,也就是图3的红色区域内,进行计算。
注意这里的k和v是不同的。因为k和v是由Z经过2个独立的卷积各自得到的,学习到的内容可能有异,这时候即使用同样的LR坐标采样,采样得到的特征也不同,即kv不同。
下面是图中的另一个输入,coordinate,其实是 (c) 中的δx。
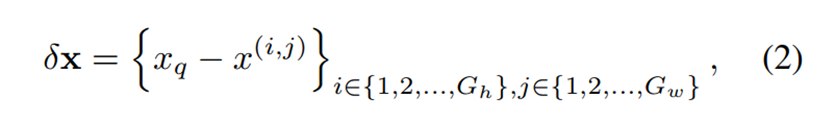
δx是用xq减掉Gh×Gw区域,每一个LR坐标得到的。i,j主要是用来对LR坐标点编号。
至此,把δx,qkv,输入跨尺度局部注意力模块,计算注意力。得到一个GhGw*C的输出结果。(CSLAB模块稍后讲)
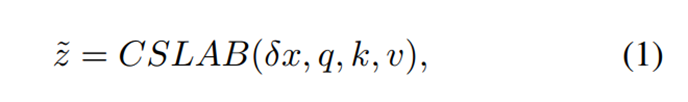
得到结果后,在通道维度上concat图中的cell。
(这里文中虽然说:c是指图3中HR像素的高和宽,但2/rh,2/rw ≠ HRΔh,HRΔw。
这与图2中标注的c=2/rh,2/rw有出入。略看代码,觉得代码最终使用的应该是图2中的2/rh,2/rw,不是很确定,如有错误欢迎指正)

把concat得到的结果,送入decoder D中。D本质是一个5层的MLP,输出维度是3,即xq处的RGB值。让这个LIT模块并行地对(rhH)(rw*W)个HR像素坐标计算,就得到一张任意尺度HR图像(的残差),叠加上原图双线性上采样的结果,得到最终的重建结果。
CSLAB模块。
主要做的是通过qkv,对特征进行注意力的计算,用attention map对特征进行加权和调整。
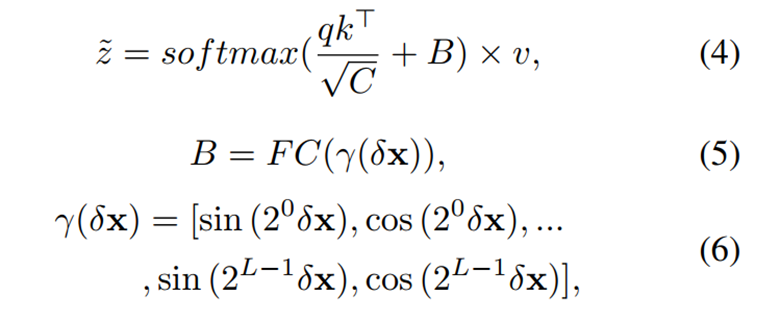
流程如下:
δx通过position encoding(实际上是类似傅里叶级数的一个函数,把2维向量映射到20维),经过一个MLP,把20维映射到1维,得到一个位置bias,B。
q和k矩阵,q(1C)与k中的每一个1C(共有GhGw个)进行内积运算,得到1GhGw,每一个都叠加上bias,通过sigmoid函数激活,与原来的v(GhGwC)特征相乘,得到注意力加权后的结果。
3.3 Cumulative Training Strategy
一句话概括:先训练小scale一阵子,然后大小scale交替训练,性能比较高。
以前的做法有:只训练小scale、大小scale交替训练,效果都不如本文使用的这种。
(这篇文章个人感觉故事讲的很好哇)
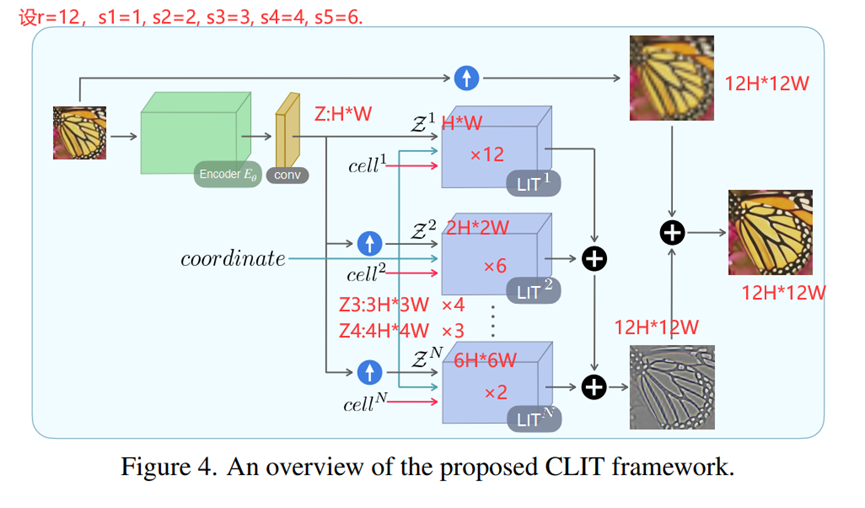
3.4 Cascaded Local Implicit Transformer (CLIT)
级联LIT。
(这里其实我不太确定,看了部分代码,但是有些云里雾里。本人代码基础还要加强啊……)
Motivation是大尺度的上采样难以一步到位。所以把它拆成几个乘法因子,每个因子各自做固定output尺寸,但是input维度和scale不同的任意超分RGB值查询,得到的output尺寸相同。这些output其实都是对于原图学习到的一个残差,再与上采样的原图相加即可。
这样讲有点抽象,举个我理解的例子。
假设要上采样r=12倍,12有很多个因子,应该不需要列举全,只需要列举其中的一部分。这里为了讲清楚就全列了,如下图,12的因子可以是1,2,3,4,6,12。但12就没意义了,于是不加进去。
S1=1的部分,Z1就是原尺寸HW,做×12的超分,得到12H2W的结果;
S2=2的部分,Z2是原尺寸的2倍,2H2W,做×6的超分,得到12H2W的结果;
S3=3的部分,Z3是原尺寸的3倍,3H3W,做×4的超分,得到12H2W的结果;
S4=4的部分,Z4是原尺寸的4倍,4H4W,做×3的超分,得到12H2W的结果;
S5=6的部分,Z5是原尺寸的6倍,6H6W,做×2的超分,得到12H2W的结果;
因为LIT模块的实质是,执行一次,对一个HR坐标xq执行RGB值查询,所以×n的超分,不过是并行地对LIT模块执行nH*nW次,对LIT中的参数进行调整而已,个人认为这个想法是合理的。
这里使用的训练策略是在3.3的累计训练策略的基础上得到的。
具体说,就是先用累计训练策略,训练一个LIT1(第一个分支);
然后用LIT1的参数初始化LIT2,用累计训练策略(其实这里已经是用大小scale交替训练了),对LIT2的参数进行微调;
接着用LIT2的参数初始化LIT3,用累计训练策略对LIT3的参数进行微调;
以此类推,直到最后一个LITN也被纳入进系统,得到CLIT,即级联LIT。
(这部分的方法是我读了原文,加上自己的一些脑补和自我说服得到的,如有误,欢迎纠正讨论!!!)
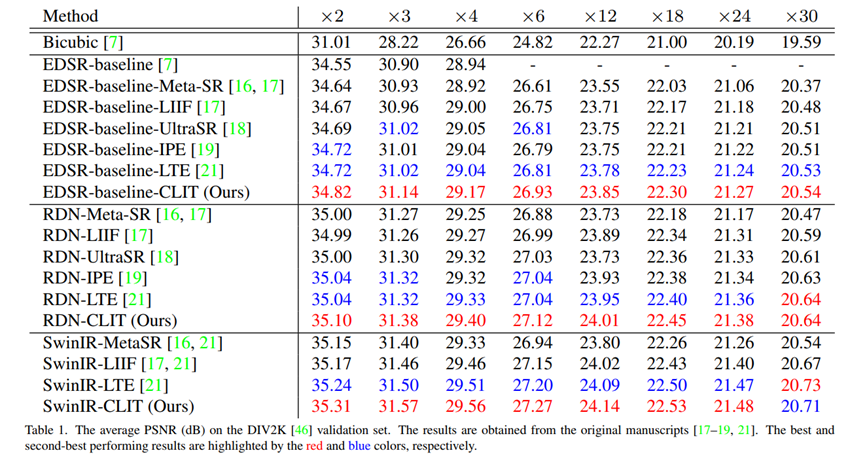
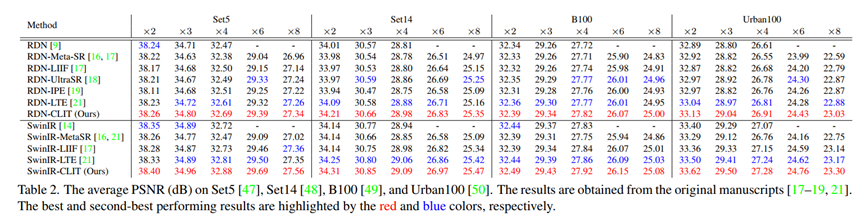
4 Experiment
5 Ablation study
Table3:
Cross-scale local attention block(CSLAB)
Cell size
+e:local emsemble(其实这个实验,证明local emsemle虽然简单粗暴,但是还是有用的。比如这里虽然已经用了注意力,但是再加上local emsemble这一步,性能又有提升)
Table4: grid sizes(GhGw,计算注意力的区域的尺寸),最后选了77
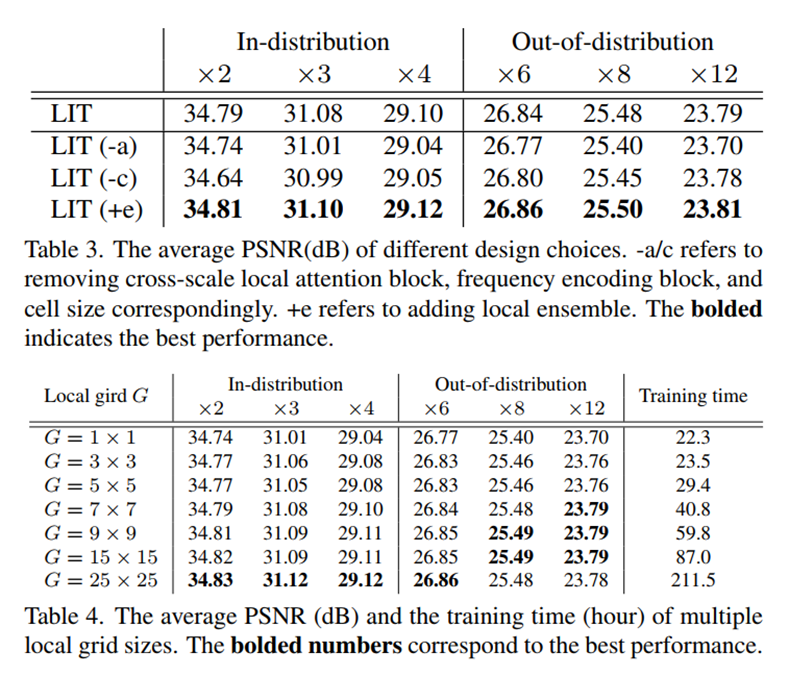
Table5: 训练策略。
第一列是随机1-4内采样scale;第二列是范围扩大到1-12;
第三列是在1-4和4-12之间切换采样尺度,交替训练;
第四列是本文采取的训练策略;现在1-4尺度训练LIT,然后在1-4和4-12之间切换scale,进行微调。
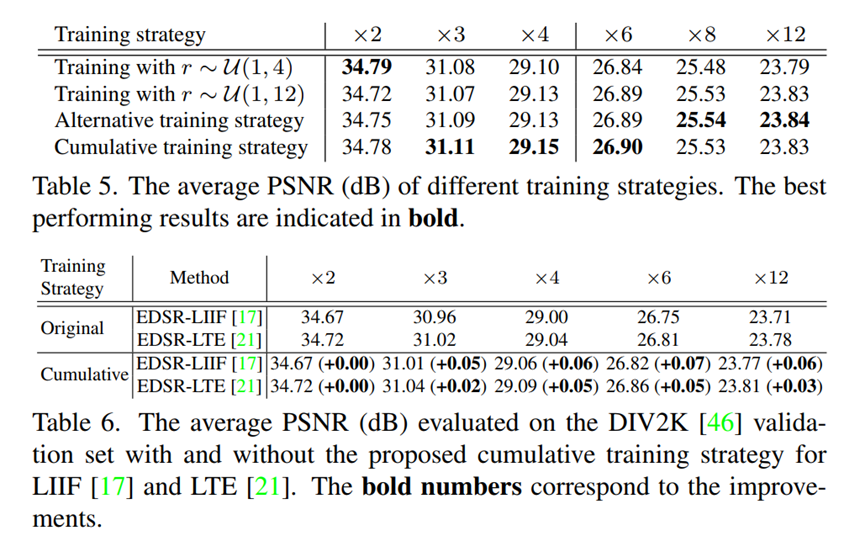
Table6: 验证训练策略的作用。
在LIIF和LTE上验证了累计训练策略的作用。在大尺度上有一定的提升。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!