微博热搜榜、热点、帖子、评论爬虫---Scrapy框架、Selenium
提示:主要提供思路和内容参考,不提供完整资料;文章内容有许多瑕疵的地方(由于内容量太大),请理解。如果遇到不了解的地方,可以联系小编,尽个人所能解答。文章内容有错误的地方,希望第一时间能指点出来,小编可以及时完善。
作者:Irain
QQ:2573396010
微信:18802080892
目录
- 1 实现前准备
- 1.1 了解内容
- 1.2 环境搭建
- 1.2.1 第三方库
- 1.2.2 模拟浏览器
- 1.2.3 下载webdriver
- 1.2.4 数据库搭建
- 1.2.5 Scrapy爬虫
- 2 实现步骤
- 2.1 热搜榜网页
- 2.1.1 详细分析热搜榜网页
- 2.1.2 分析热搜榜网页的Ajax内容
- 2.1.3 热点数据表内容
- 2.1.4 热搜榜思维图
- 2.1.5 热搜榜相关代码
- 2.2 热点
- 2.2.1 详细分析热点网页
- 2.2.2 获得热点帖子的Ajax的URL
- 2.2.3 详细分析热点帖子的Ajax内容
- 2.2.4 热点话题
- 2.2.5 热点帖子的Ajax中的导语
- 2.2.6 热点帖子的Ajax中的帖子
- 2.2.7 测试提取帖子内容
- 2.2.8 帖子爬取结束标志
- 2.2.9 热点帖子数据表内容
- 2.2.10 热点帖子思维图
- 2.2.11 热点帖子相关代码
- 2.3 帖子
- 2.3.1 导语页面
- 2.3.2 帖子评论
- 2.3.2.1 详细分析帖子正文网页
- 2.3.2.2 帖子评论页面分析
- 2.3.2.3 两类评论
- 2.3.2.4 查看评论条件
- 2.3.2.5 帖子正文结束标志
- 2.3.2.6 帖子正文思维图
- 2.3.2.7 部分代码展示
- 2.4 互动评论页面
- 2.4.1 详细分析互动评论页面
- 2.4.2 互动评论思维图
- 2.4.3 抽取互动评论部分代码
- 2.5 破反爬虫
- 2.5.1 分析微博登录页面
- 2.5.2 简单验证
- 2.5.3 无法破解(小编无能为力)
- 2.6 退出账号
- 3 设计数据表
- 3.1 设计数据表思维图
- 3.2 创建表的部分代码
- 3.3 MySQL-Front中的数据表
- 3.4 数据表的内容
- 4 应用扩展
- 4.1 热点词云、情感分析
- 4.2 热点主题分类
- 5 参考链接
- 6 完整流程图
- 7 总结、建议和期望
- 8 设计、实现和过程完整思维图
1 实现前准备
1.1 了解内容
Ajax内容了解链接
1.2 环境搭建
1.2.1 第三方库
pip install scrapy -i https://pypi.douban.com/simple/
pip install selenium -i https://pypi.douban.com/simple/
pip install pymysql -i https://pypi.douban.com/simple/
pip install requests -i https://pypi.douban.com/simple/
pip install lxml -i https://pypi.douban.com/simple/
1.2.2 模拟浏览器
1.2.3 下载webdriver
下载webdriver链接

1.2.4 数据库搭建
Mysql 5.5.36下载
Mysql-Front下载
数据库搭建链接
1.2.5 Scrapy爬虫
创建Scrapy爬虫
在DOC窗口创建scrapy项目和爬虫
设置配置
scrapy爬虫项目设置settings.py参数
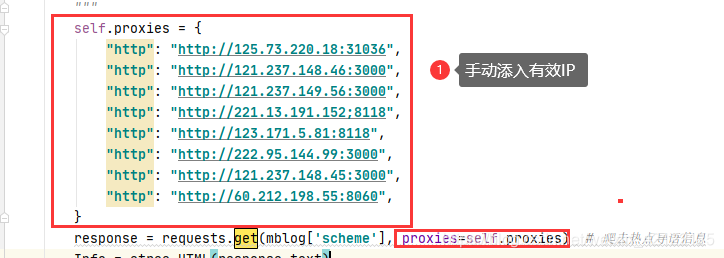
代理IP、user-agent
中间件、请求头代理、IP代理
2 实现步骤
分析微博网页(热搜榜、热点、热点帖子、帖子互动评论)
2.1 热搜榜网页
2.1.1 详细分析热搜榜网页
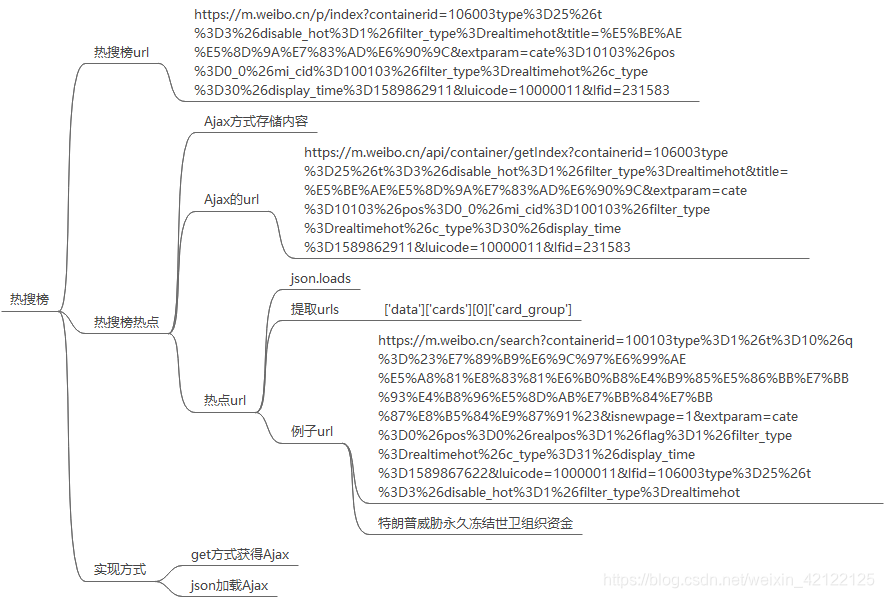
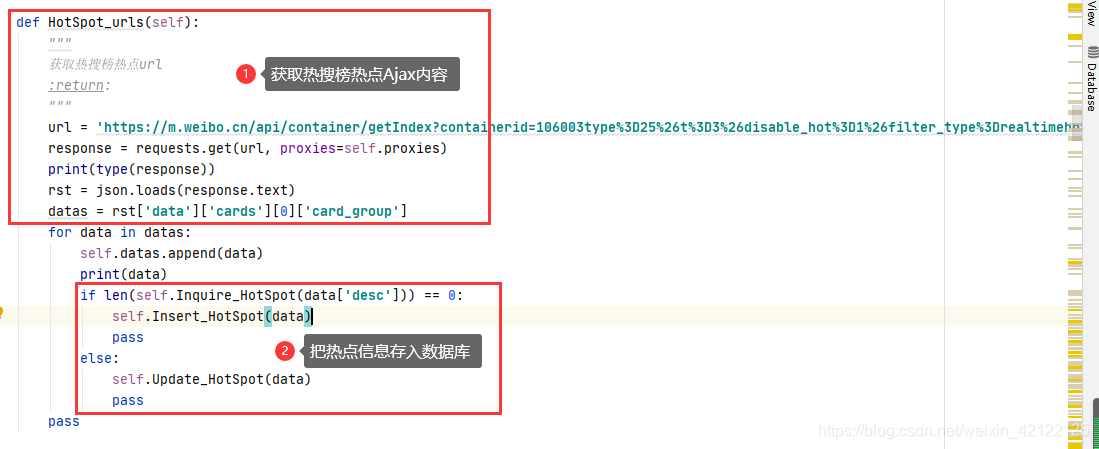
热搜榜榜单的热点数据都是通过Ajax动态加载的。浏览器访问热搜榜网页,所有热点全部加载出来,不需要进行下一步操作。访问热搜榜网页不需要登陆微博。在开发者调试工具(在浏览器中按下F12)中进过多次访问、分析,热搜榜Ajax的url是不变的。这里用get访问方式,直接获取热搜榜Ajax内容。
热搜榜链接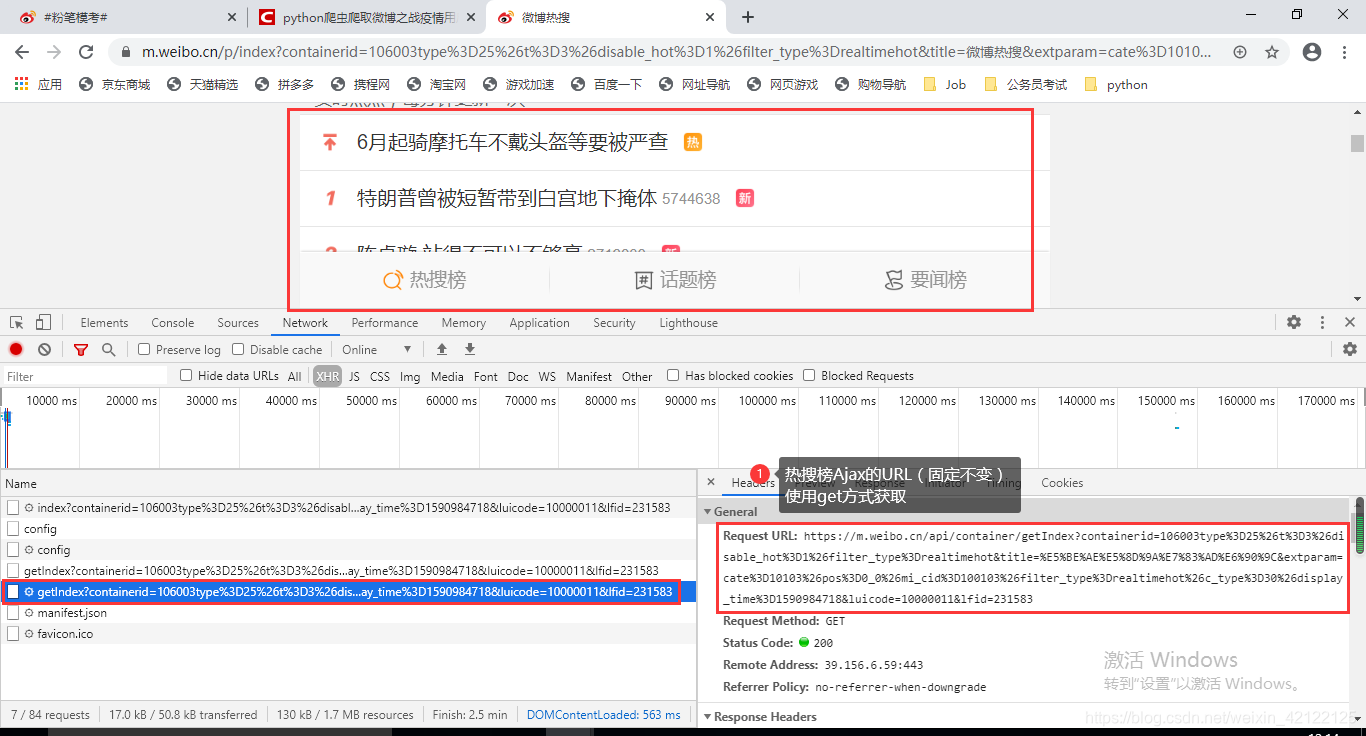
2.1.2 分析热搜榜网页的Ajax内容
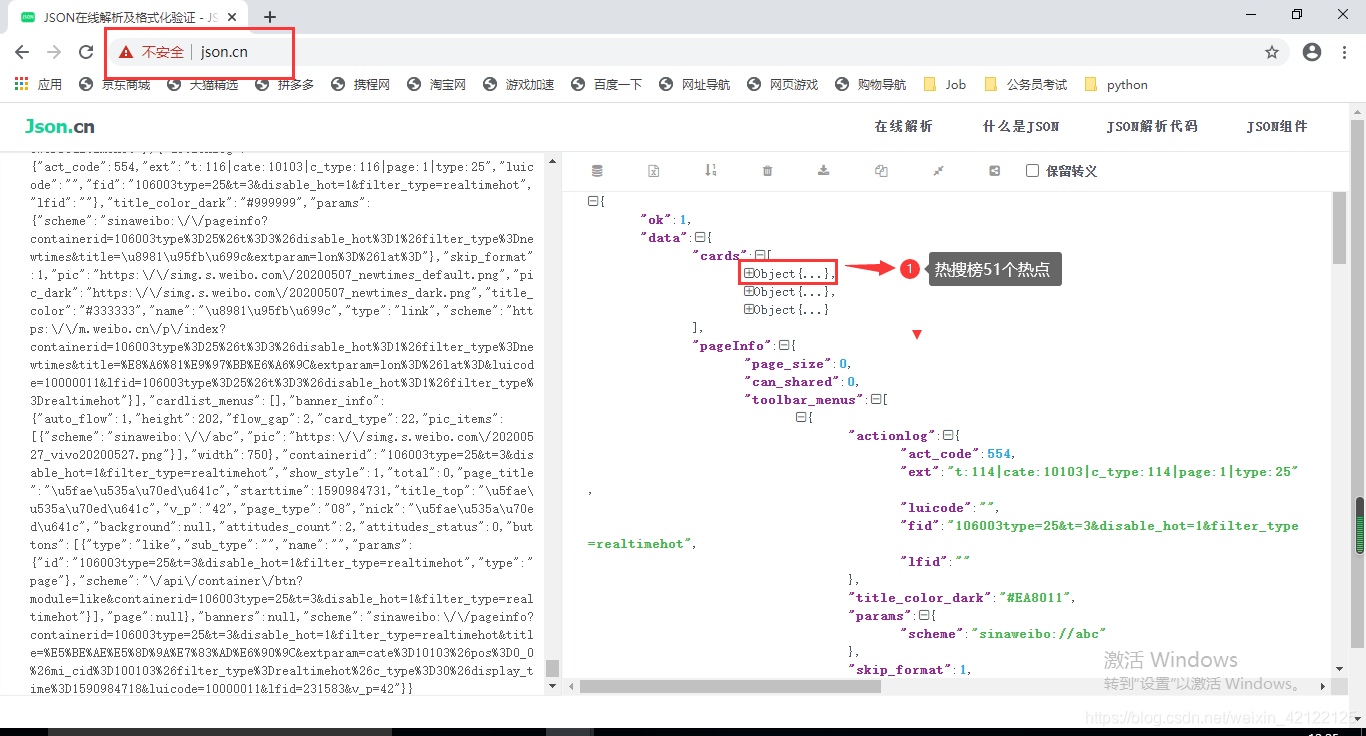
详细分析Ajax内容:把Ajax内容在json.cn网页分析,发现热搜榜热点在json中存储的规律。使用json加载获取的Ajax中的热点内容(主题、链接、热度)。
http://json.cn/
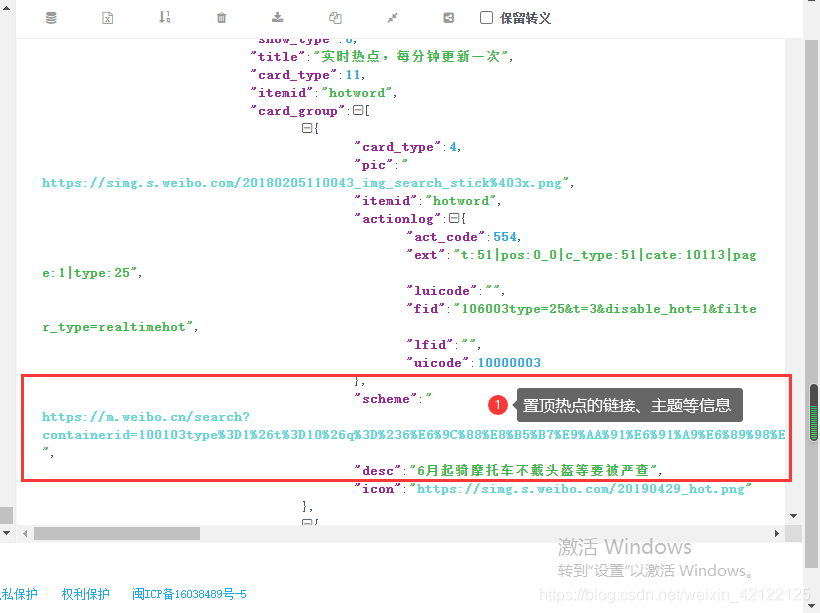
2.1.3 热点数据表内容
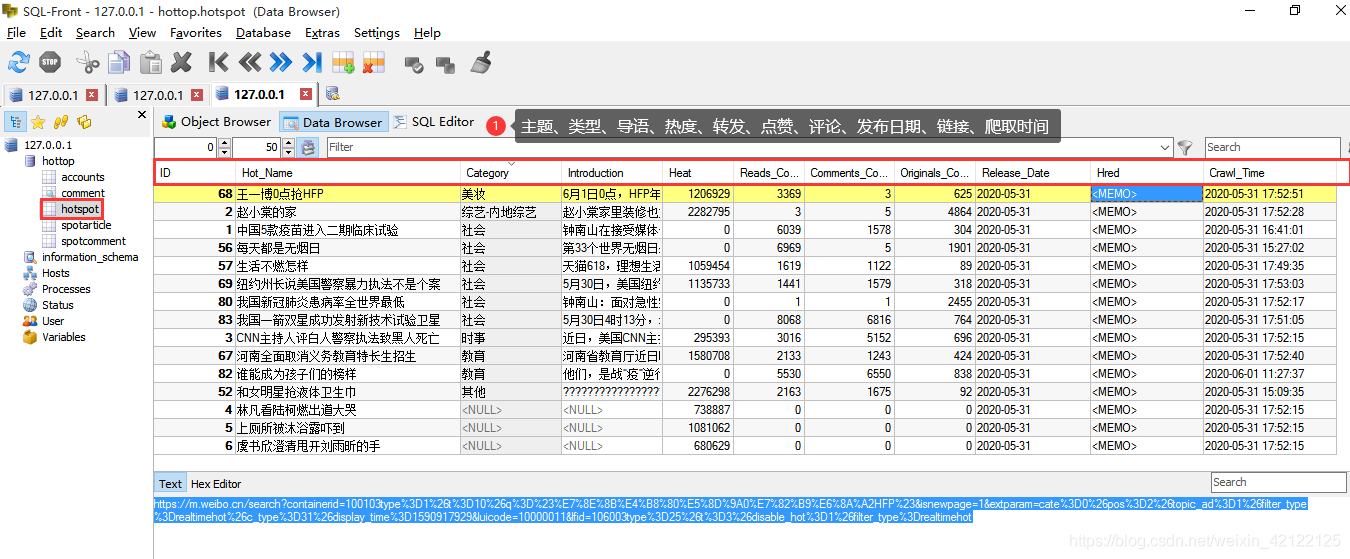
2.1.4 热搜榜思维图
2.1.5 热搜榜相关代码
2.2 热点
2.2.1 详细分析热点网页
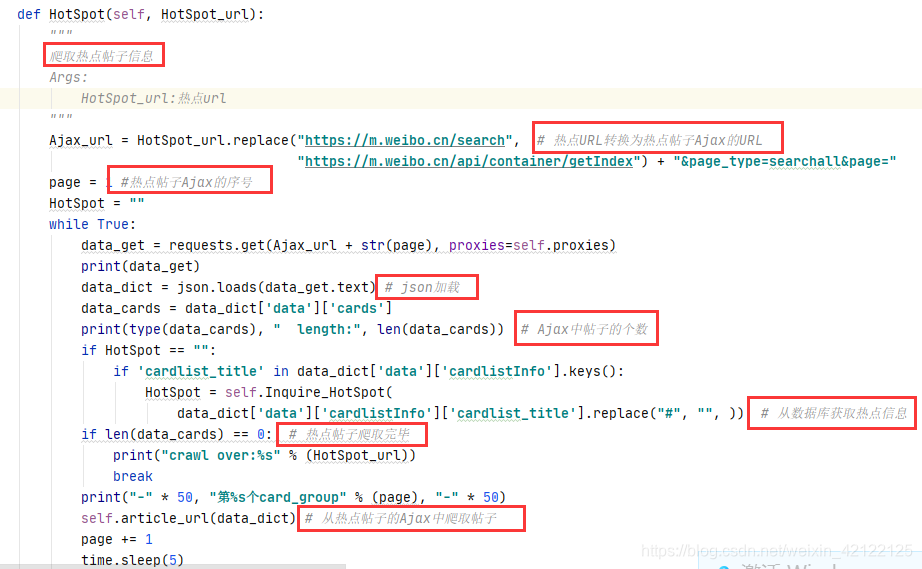
与热搜榜网页分析方式和内容很像。热点网页的帖子都是通过Ajax动态加载的。浏览器访问热点网页,加载部分帖子, 通过滑动滚动条置底端,更新动态Ajax内容。也是不需要登陆微博。在开发者调试工具(在浏览器中按下F12)中进过多次访问、分析,发现热点帖子Ajax的url与热点URL相关联,可以相互转换。每个Ajax 的URL以页数page区别开来。访问方式仍然是get,循环获取热点帖子的Ajax内容,结束标志是没有帖子。没有反爬虫,容易爬取。

2.2.2 获得热点帖子的Ajax的URL
修改热点链接,获取热点帖子的Ajax的URL。在python IDLE下,测试把热点URL转换为Ajax的URL。
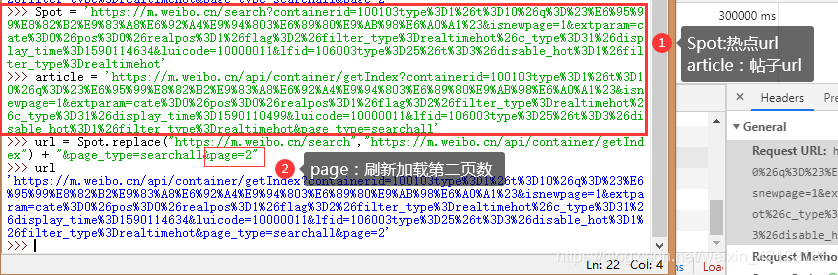
2.2.3 详细分析热点帖子的Ajax内容
把Ajax内容在json.cn网页分析,发现热搜榜热点在json中存储的规律。
http://json.cn/
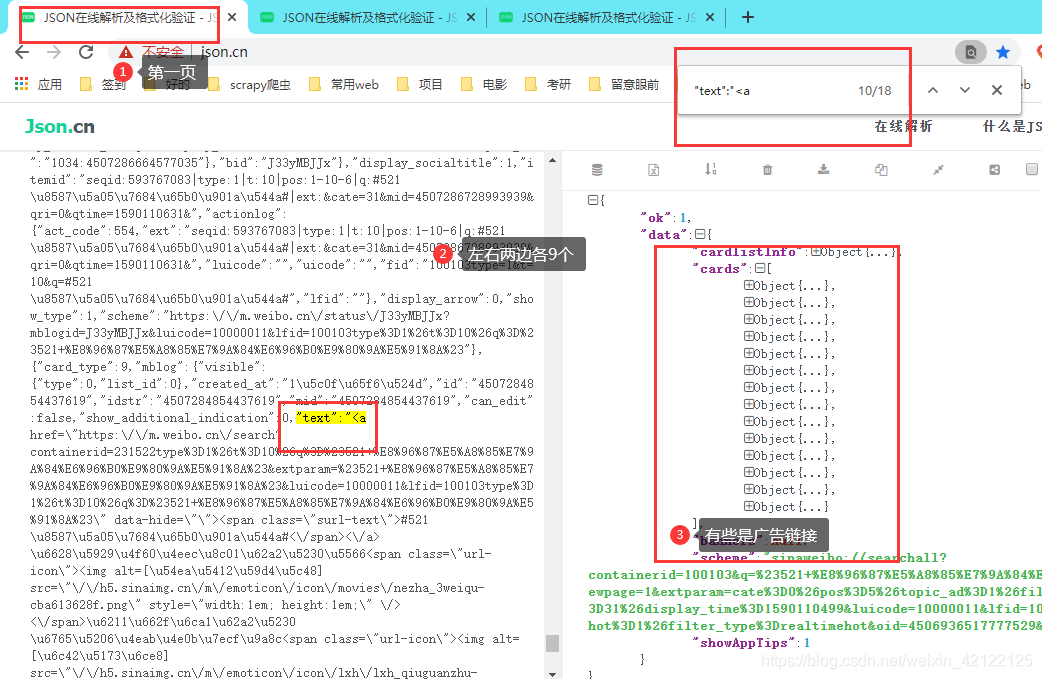
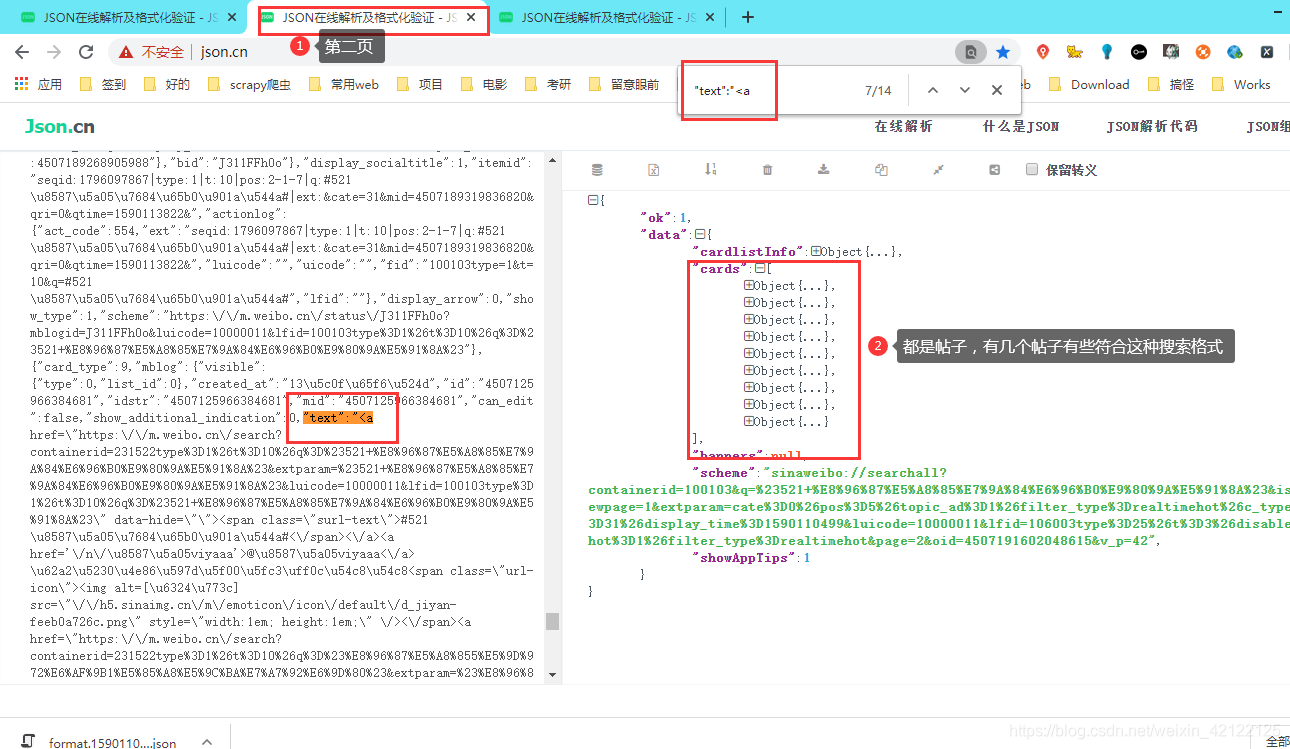
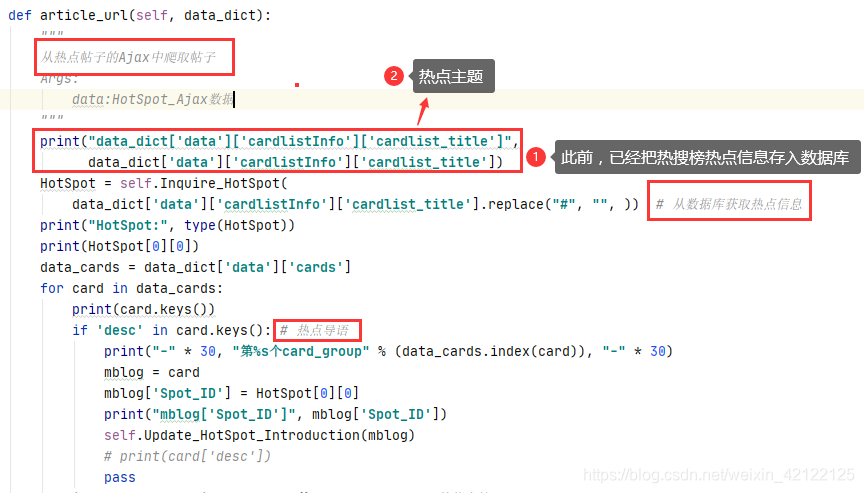
2.2.4 热点话题

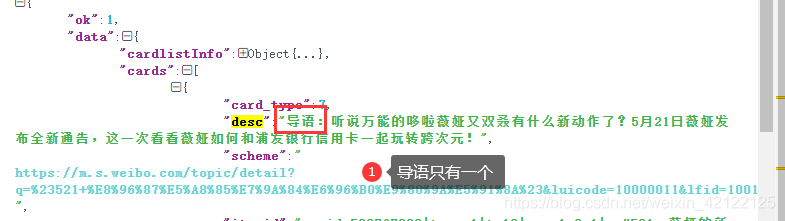
2.2.5 热点帖子的Ajax中的导语
不是所有的热点都有导语,社会事件一般才有导语。
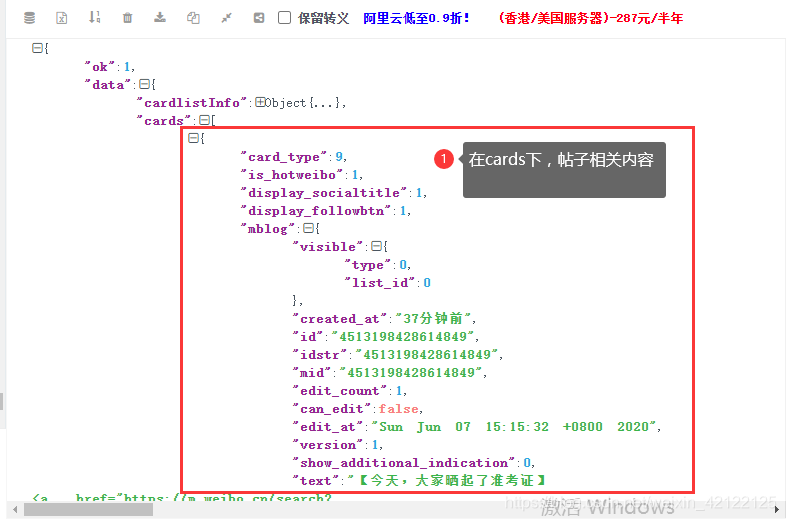
2.2.6 热点帖子的Ajax中的帖子
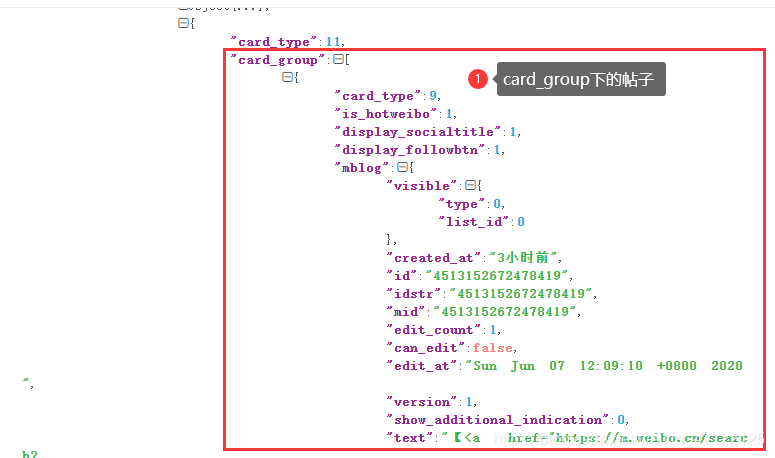
分别在cards和card_group下的帖子
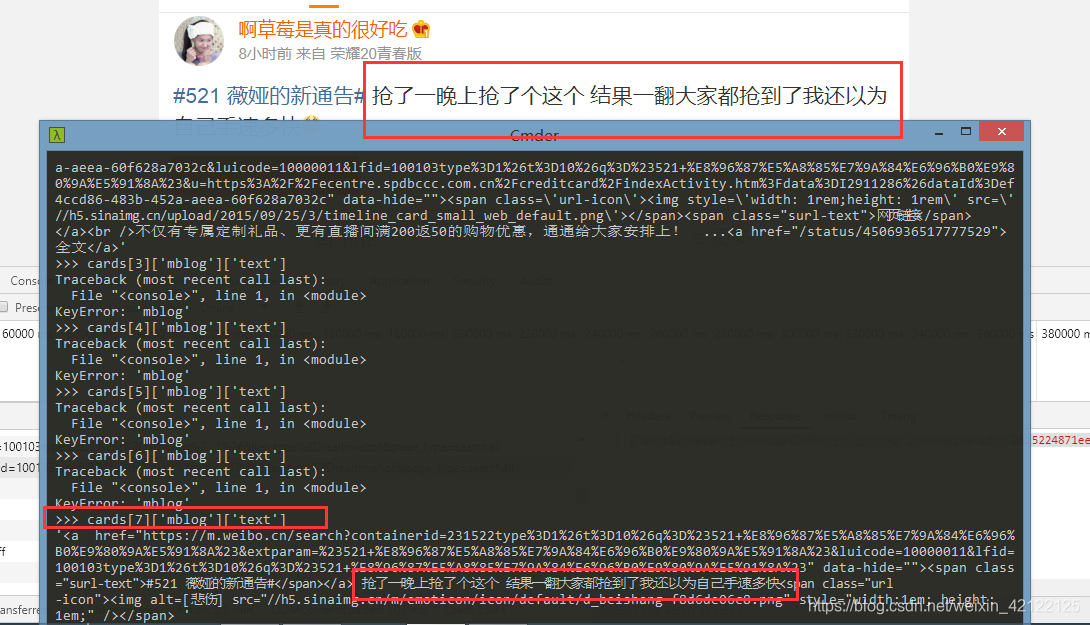
2.2.7 测试提取帖子内容
在DOS使用Scrapy Shell命令,获得热点帖子的Ajax,提取某个帖子的内容。
2.2.8 帖子爬取结束标志

2.2.9 热点帖子数据表内容
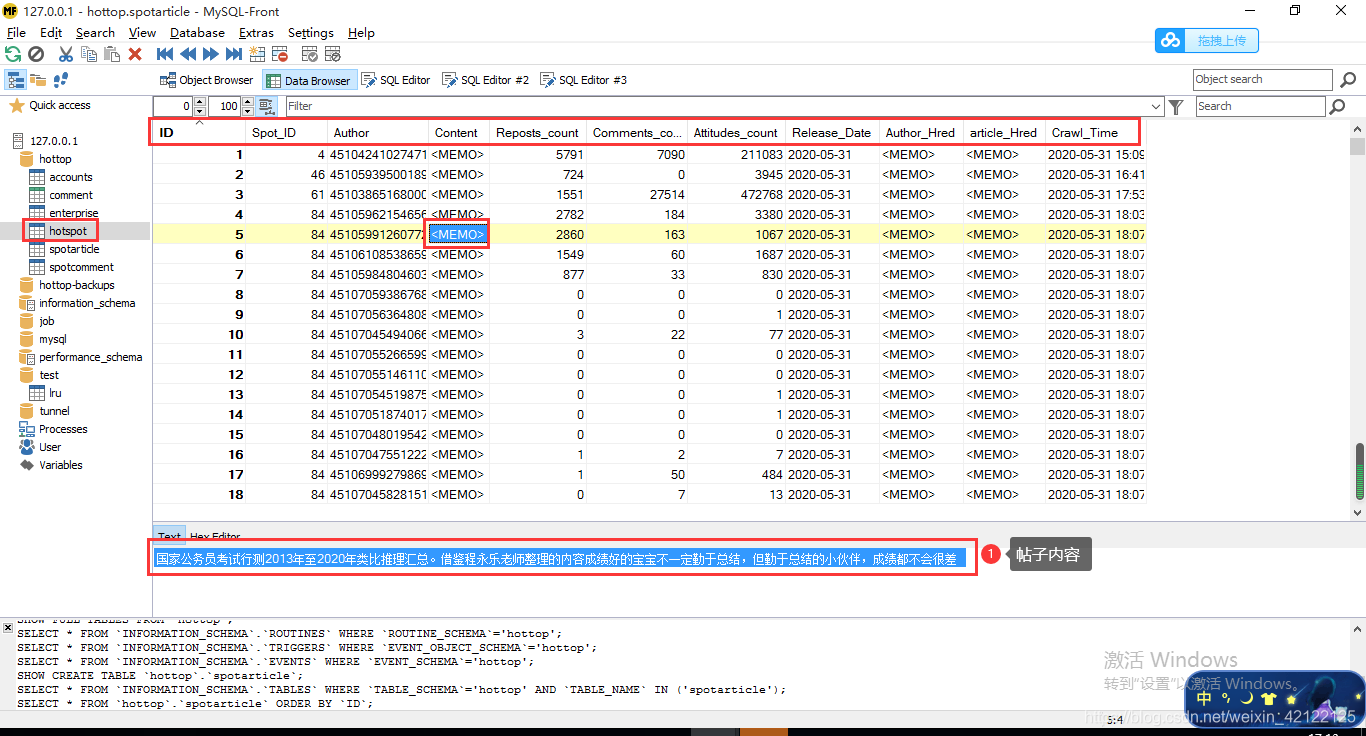
2.2.10 热点帖子思维图
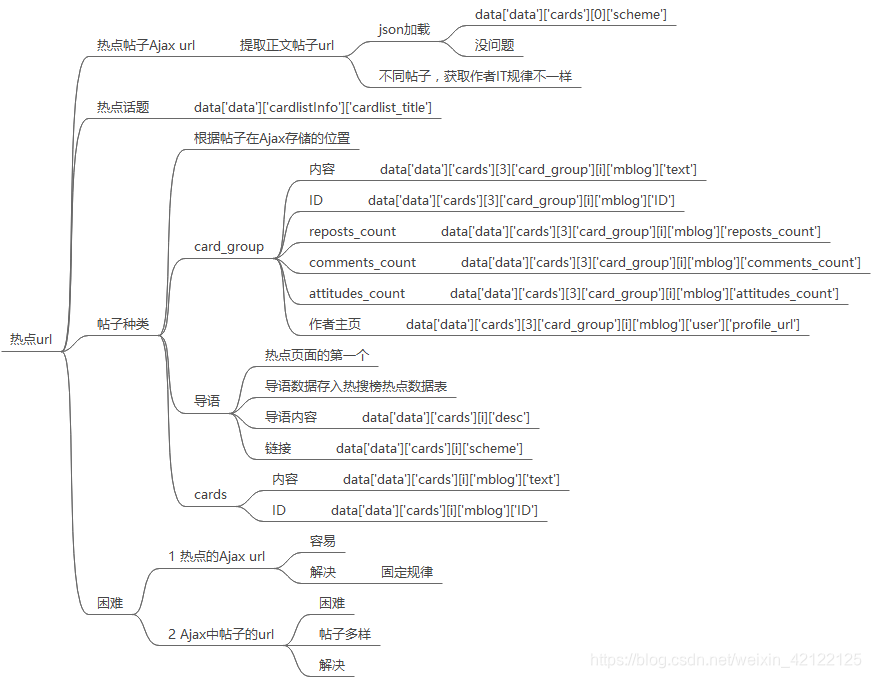
2.2.11 热点帖子相关代码
用get获取热点帖子Ajax的代码。使用json加载Ajax中的热点帖子内容,提取帖子内容、作者ID等信息。
从热点帖子Ajax中提取热点页面帖子的相关代码
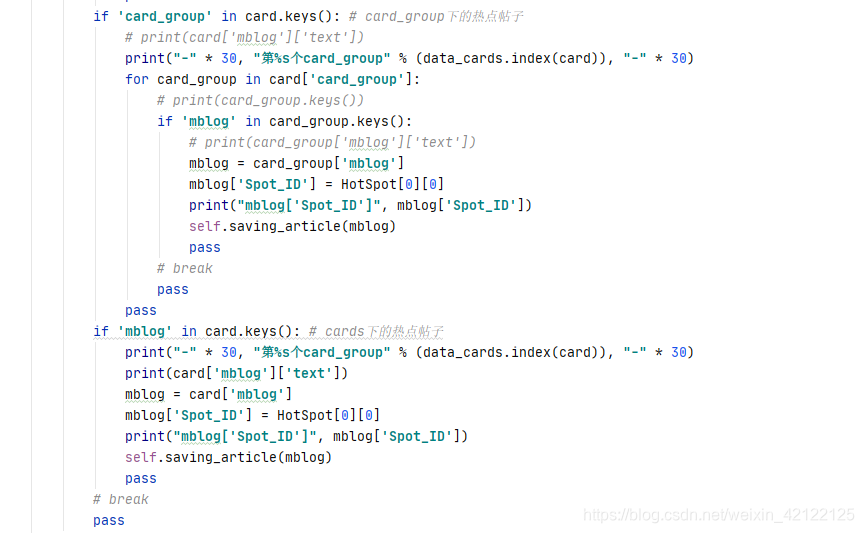
2.3 帖子
2.3.1 导语页面
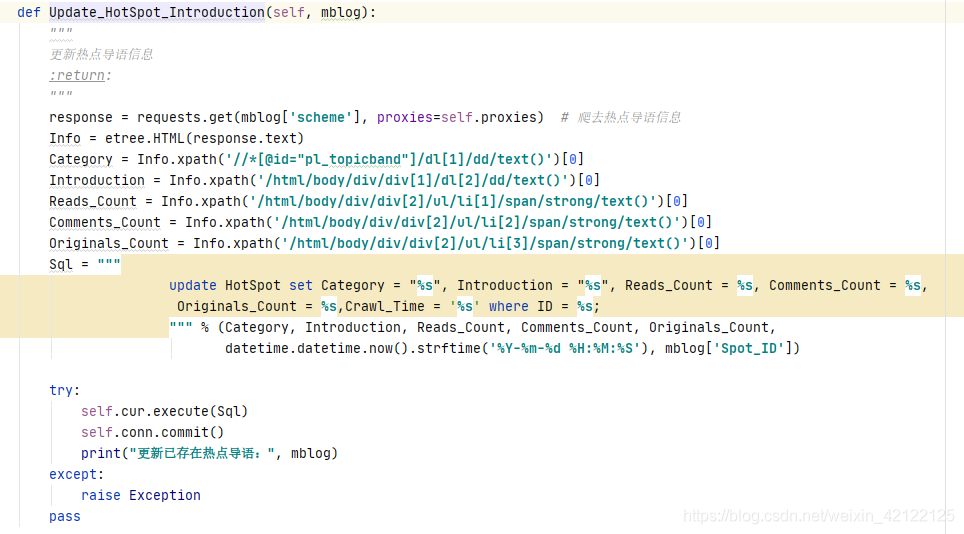
从热点帖子Ajax中获取导语的内容和链接。使用get方式,访问导语链接,进入导语页面,获取相关信息(分类、阅读、讨论、原创次数)。在热搜榜热点数据表更新热点的导语等信息。不是所有的热点都有导语,社会事件一般才有导语页面。
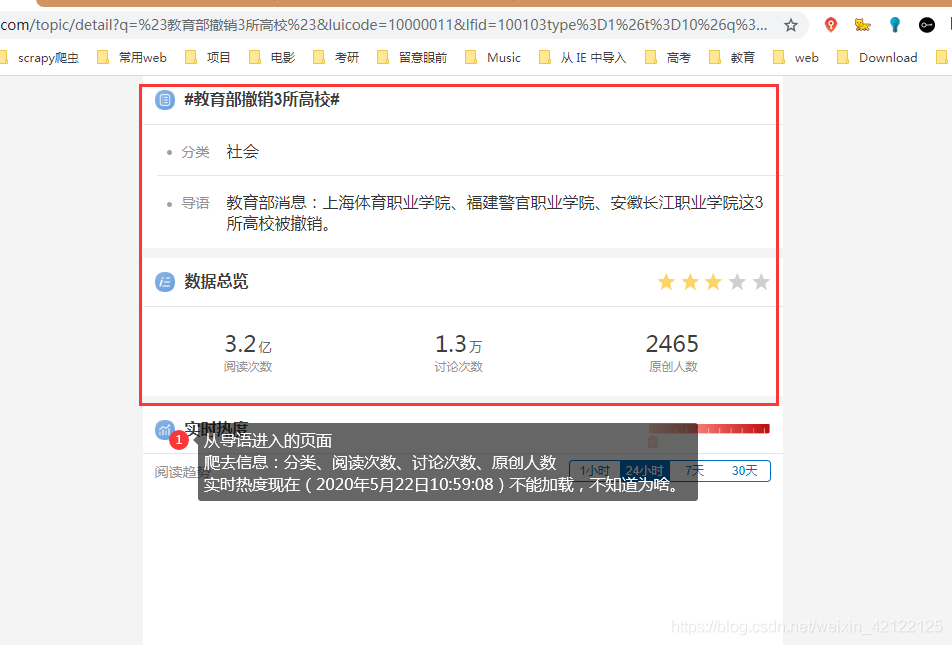
2.3.2 帖子评论
2.3.2.1 详细分析帖子正文网页
与热点帖子网页分析方式和内容很像。帖子正文的评论都是通过Ajax动态加载的。在开发者调试工具(在浏览器中按下F12)中进过多次访问、分析,帖子正文页面的url只跟作者的ID有关,作者ID在爬取热点帖子(第二步骤)中获得。
帖子链接:https://m.weibo.cn/detail + 帖子作者ID
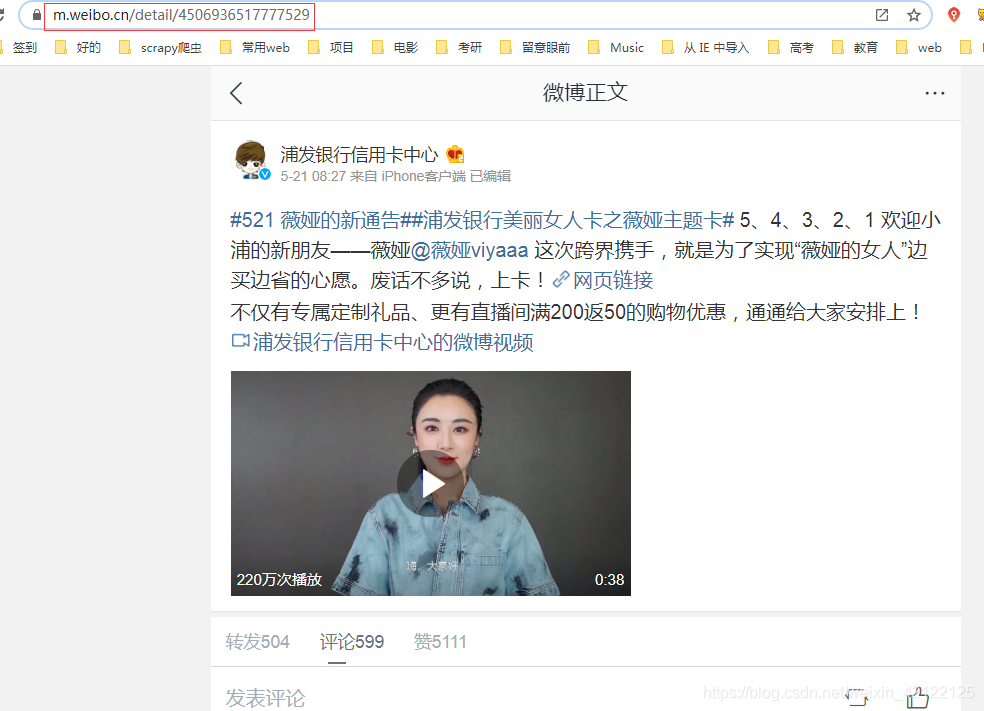
2.3.2.2 帖子评论页面分析
https://m.weibo.cn/detail/4513513248445166
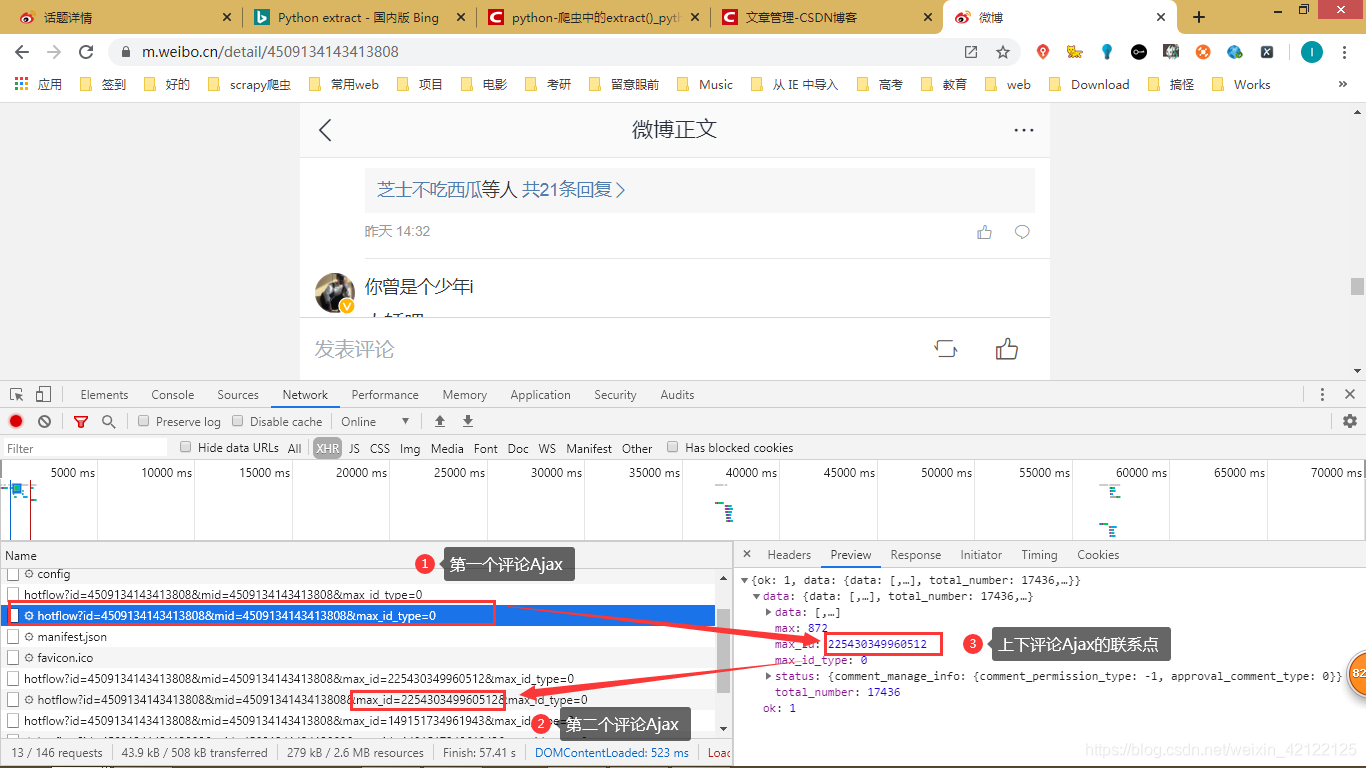
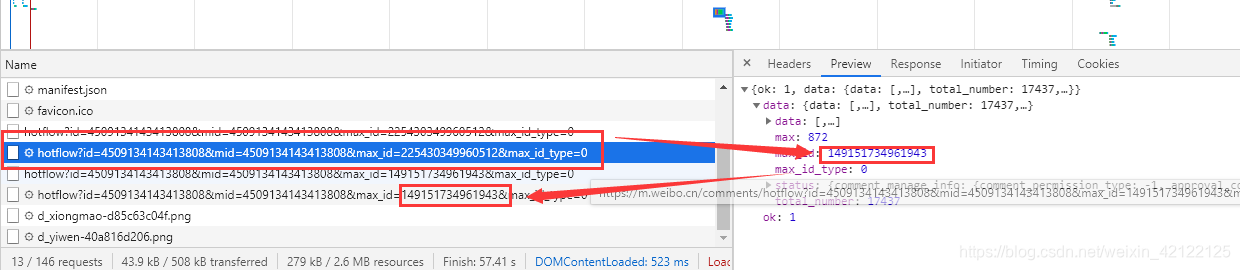
2.3.2.3 两类评论
评论分成两类:互动评论和非互动评论。如果是非互动评论,则直接提取,全部存入到一个字符串中。
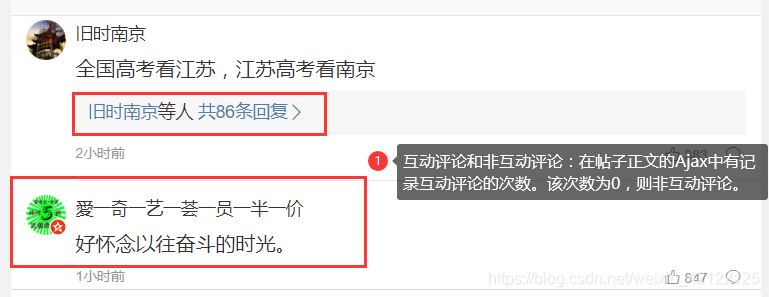
Ajax中评论者的ID,内容,互动评论次数等。

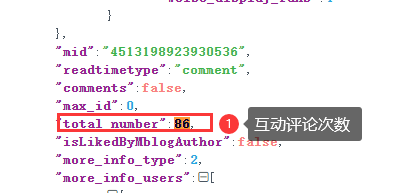
2.3.2.4 查看评论条件
访问Ajax需要登录身份,所以,用模拟浏览器访问Ajax,不在帖子正文页面中爬取评论,更加方便,不用下拉滚动条。而且,这样也容易通过互动评论次数,分辨出评论类型。
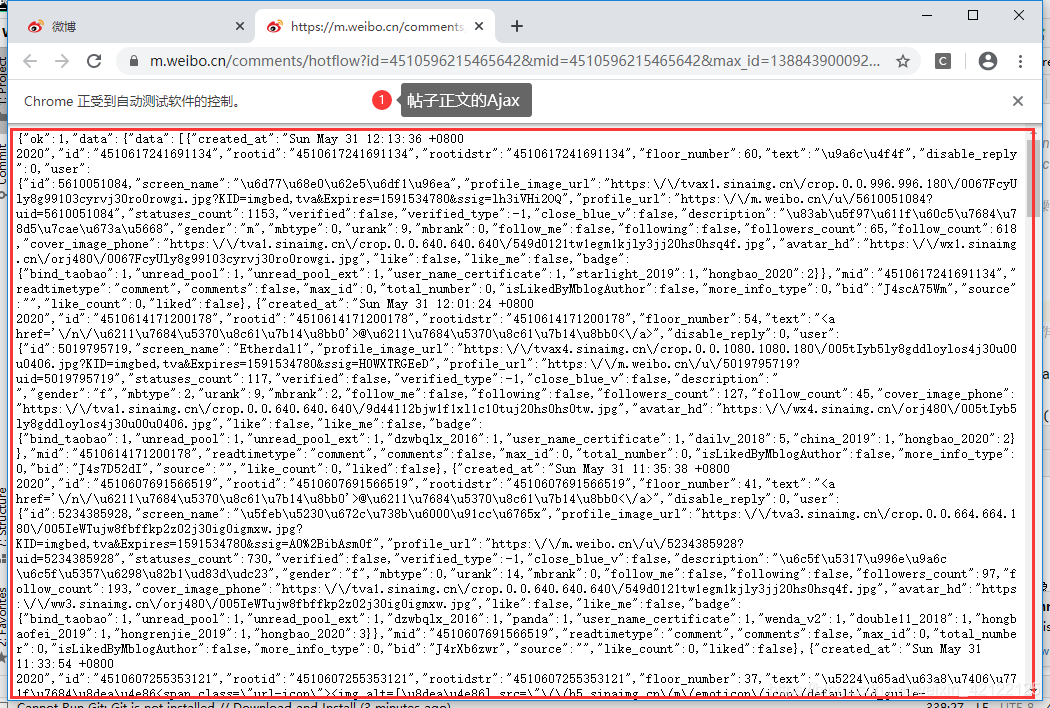
2.3.2.5 帖子正文结束标志
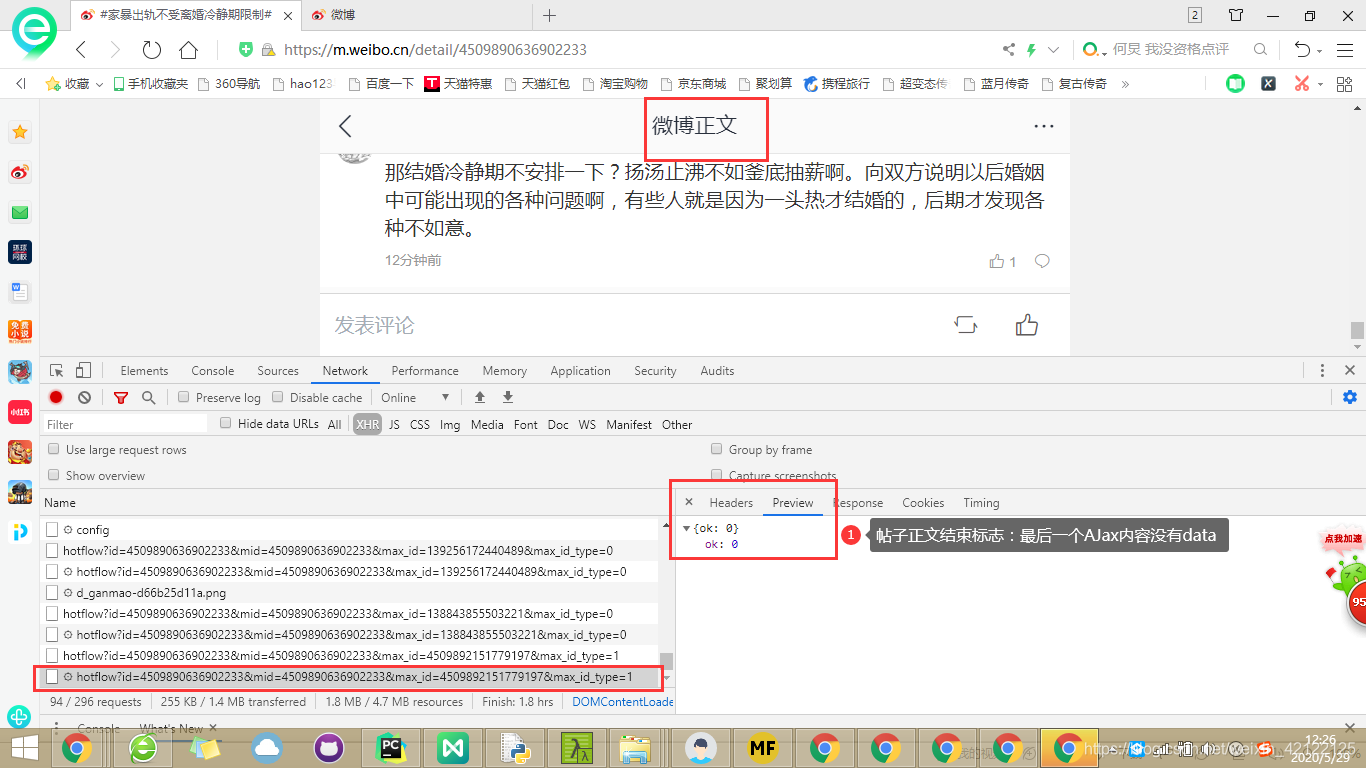
2.3.2.6 帖子正文思维图
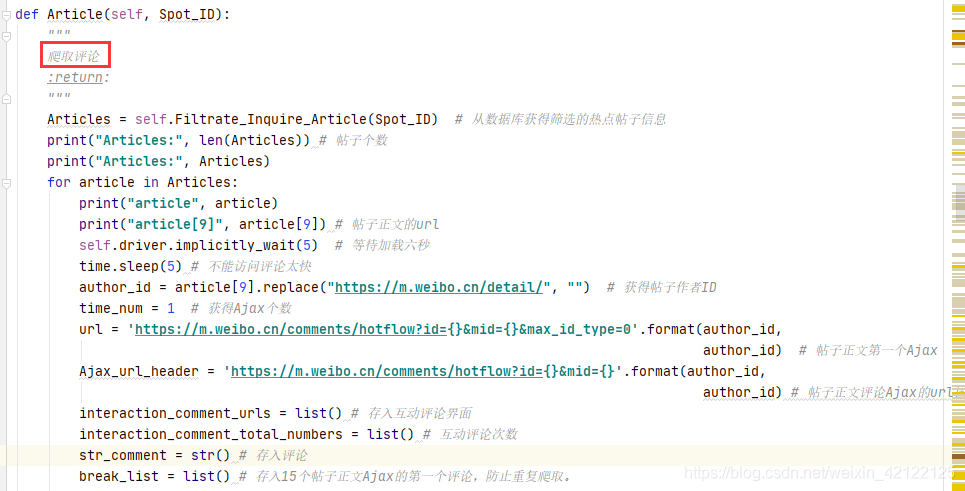
2.3.2.7 部分代码展示
2.4 互动评论页面
2.4.1 详细分析互动评论页面
https://m.weibo.cn/detail/4513513248445166?cid=4513515199698214
帖子链接:https://m.weibo.cn/detail + 帖子作者ID + cid= + 首次互动评论者ID。在上一步(热点帖子页面的Ajax中获取了所有互动评论的首发者ID)中,把帖子正文页的URL与互动评论的首发者ID连接起来,得到互动评论页面的URL。
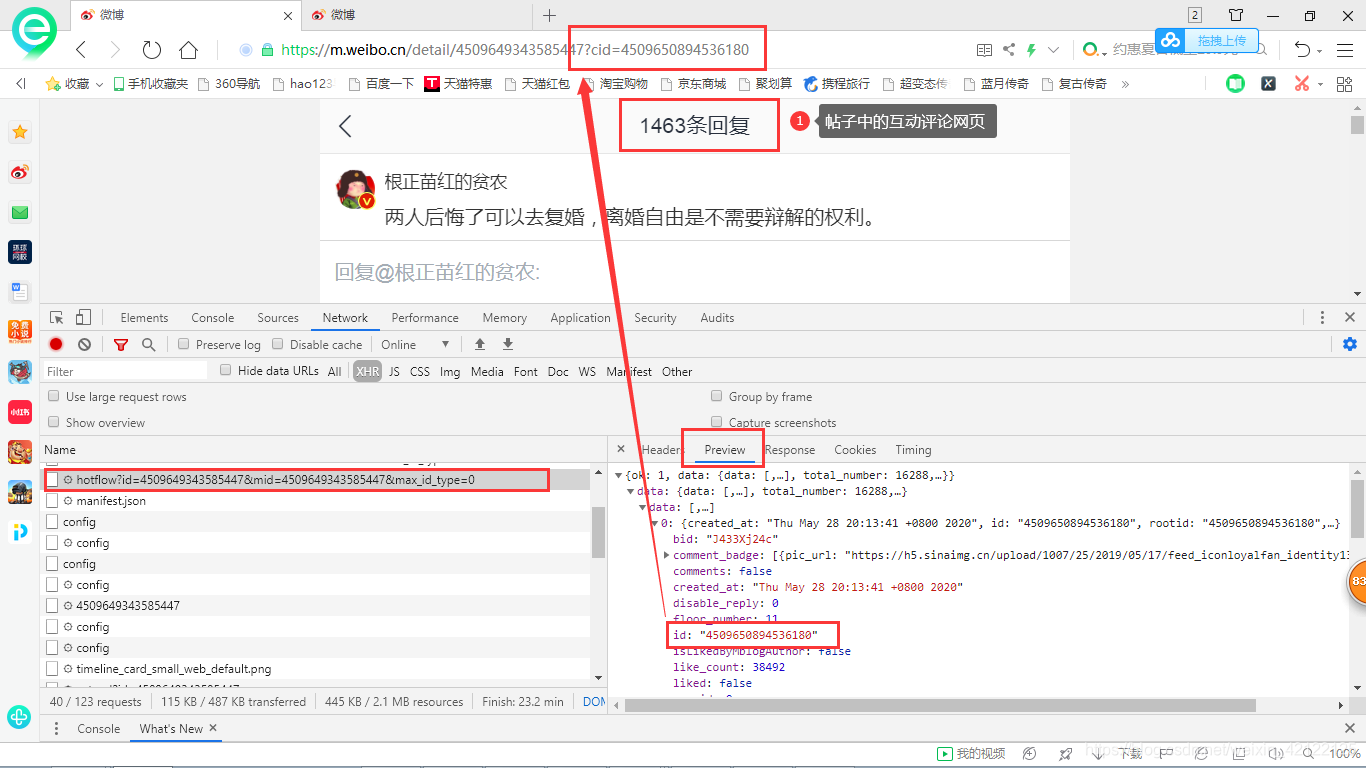
进入该页面后,互动评论的Ajax每次最多有20条评论。模拟浏览器下拉滚动条的次数 = 所有互动评论次数/20。页面加载所有互动评论后,获得网页代码,抽取互动评论。
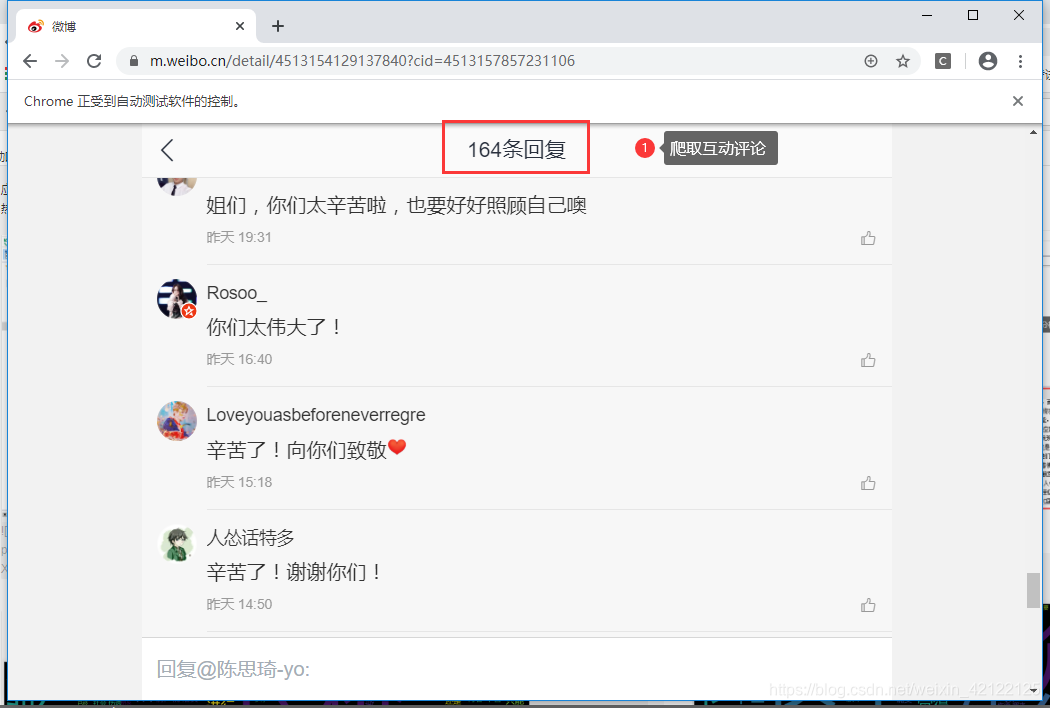
https://m.weibo.cn/detail/4513130259258563?cid=4513131202918552
2.4.2 互动评论思维图

2.4.3 抽取互动评论部分代码
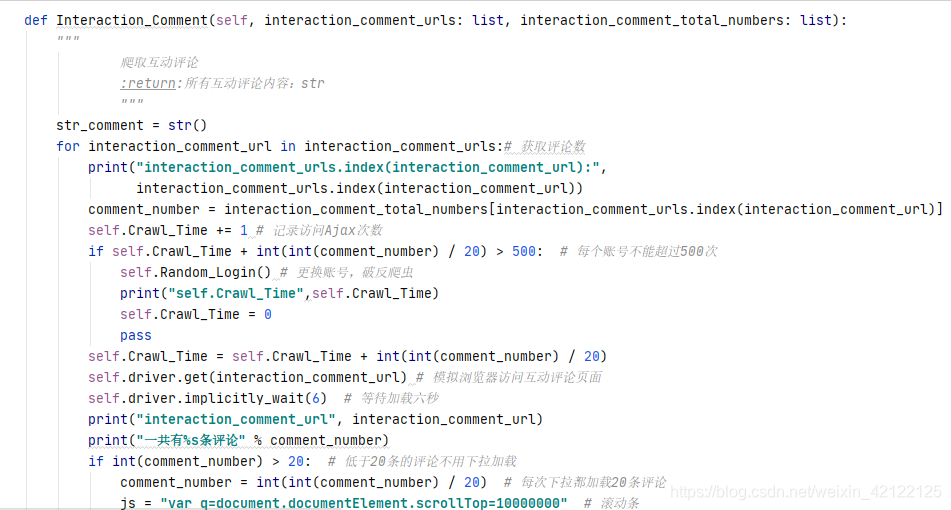
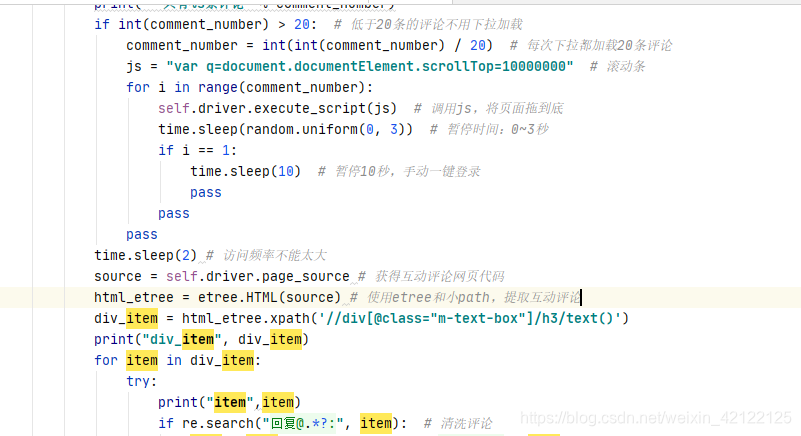

2.5 破反爬虫
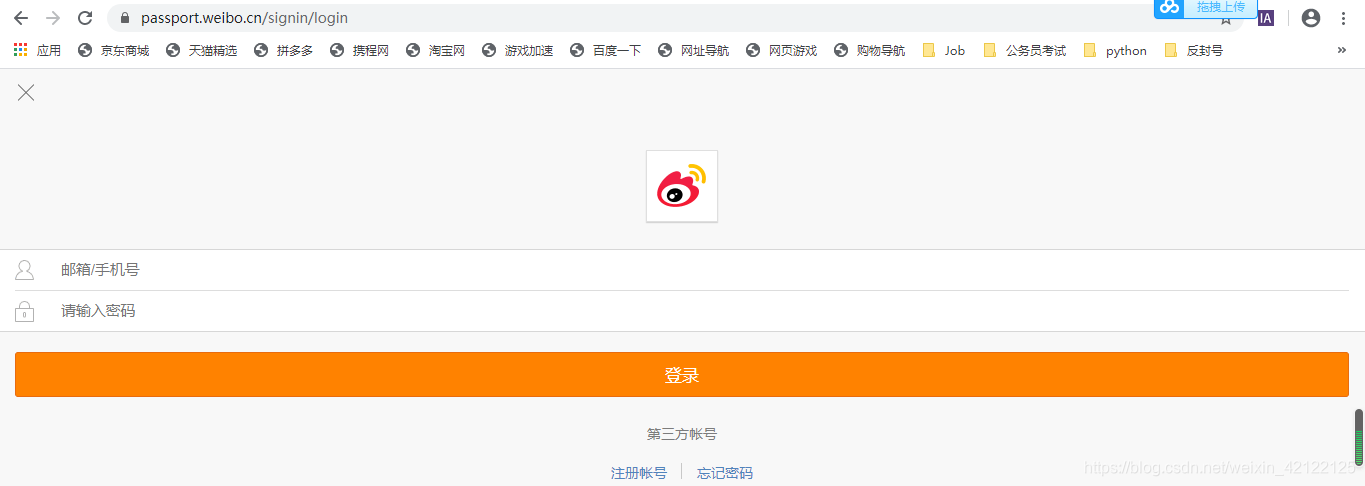
2.5.1 分析微博登录页面
观看评论,都要登陆微博。所以,考虑使用Selenium模拟浏览器爬取评论。总是用同一个账号访问微博服务器,很容易被封号。可以去第三平台(百度、知乎搜索)购买微博小号,价格不贵。有2元以内,一个账号。
微博登录链接:https://passport.weibo.cn/signin/login
2.5.2 简单验证
最简单的验证方式是点击验证按钮,即可完成验证。
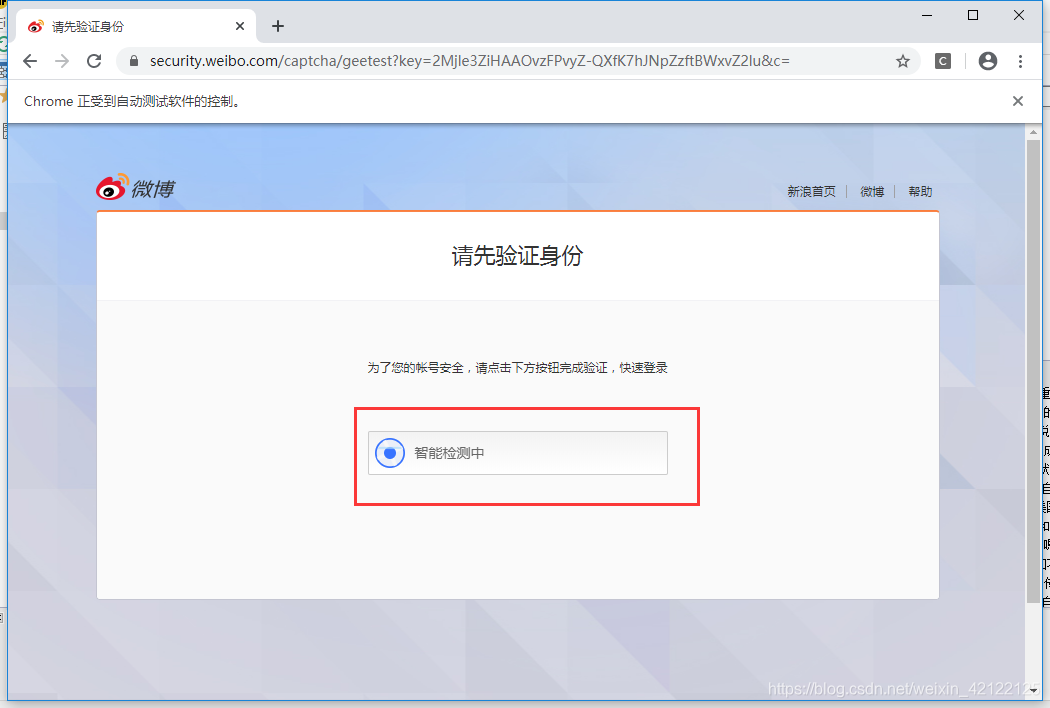
登录代码:输入账号、密码,点击确认和验证。
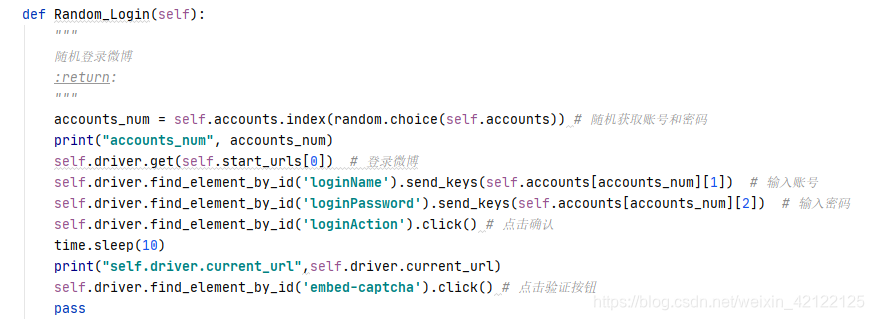
2.5.3 无法破解(小编无能为力)
高难度的验证方式:只能手动操作。点击验证按钮后,可能还有恶心的验证操作,如下面图。
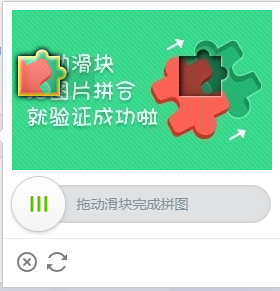
拉条验证可能可以解决:通过图像识别,识别出凹槽的位置,然后模拟浏览器操控鼠标拖拉滚动条,完成验证。下面的字体验证恶心,肉眼很难识别。用机器识别,需要费多大的代价。

2.6 退出账号
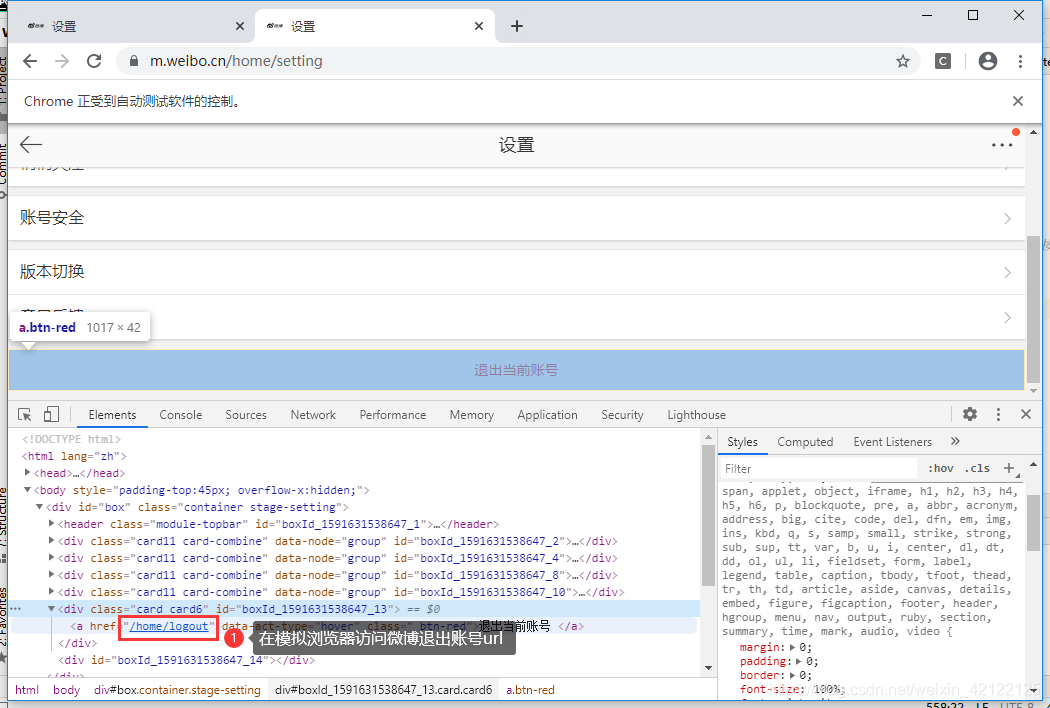
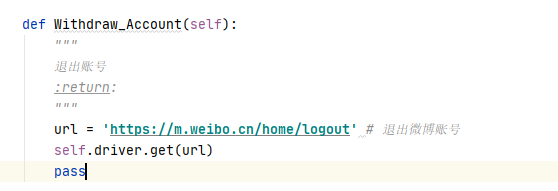
退出账号的正常操作:进入微博个人设置页面,点击退出账号。用模拟浏览器直接访问退出账号的url,即退出当前账号。
https://m.weibo.cn/home/logout
3 设计数据表
3.1 设计数据表思维图
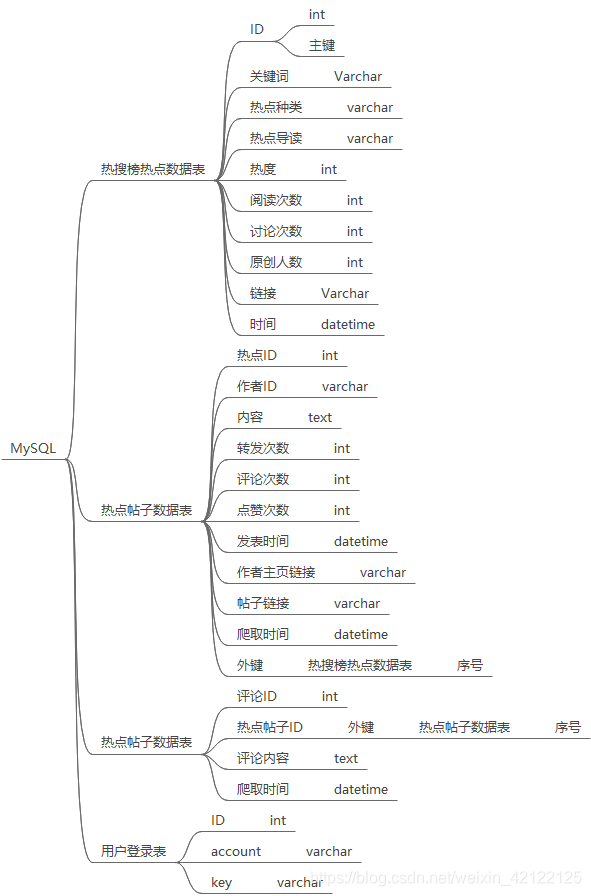
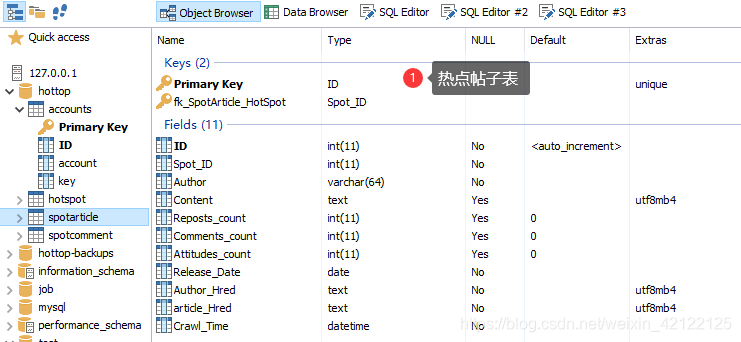
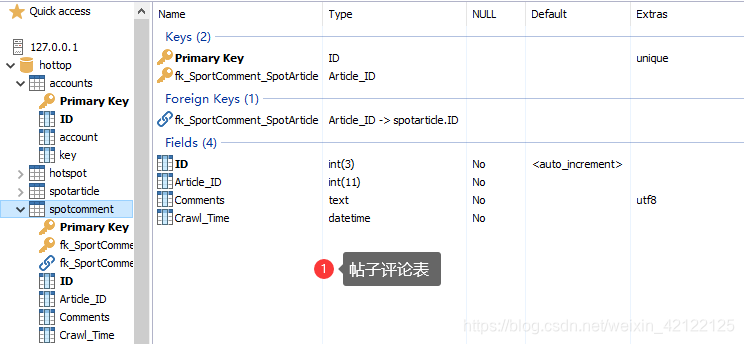
四张数据包、用户账号表、热搜榜表、热点帖子表、帖子评论表。思维图大致解释清楚每张数据表的内容。
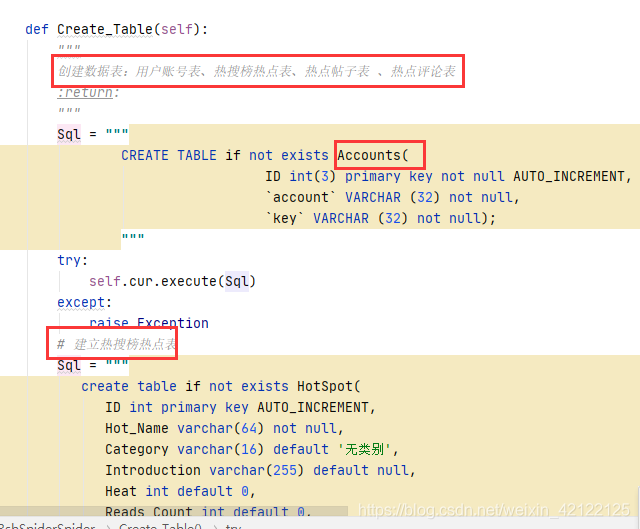
3.2 创建表的部分代码
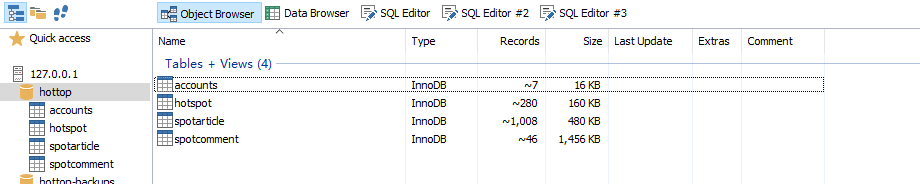
3.3 MySQL-Front中的数据表

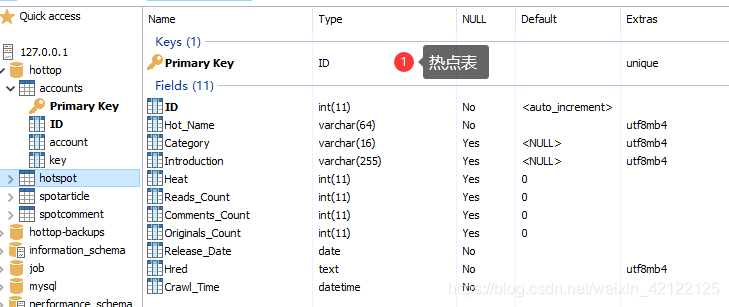
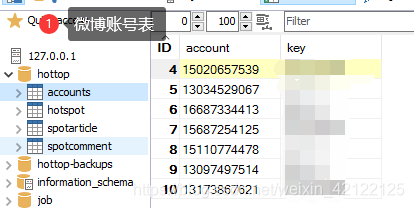
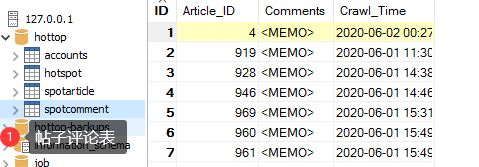
3.4 数据表的内容


4 应用扩展
4.1 热点词云、情感分析

4.2 热点主题分类
5 参考链接
https://www.cnblogs.com/bk9527/p/10504883.html
https://blog.csdn.net/ayouleyang/article/details/104306270
https://blog.csdn.net/Eastmount/article/details/104995419
6 完整流程图
流程图绘画不佳(没有清楚、完整地表达出来):流程图链接
7 总结、建议和期望
总结:项目的出发点很重要,除了锻炼自己,还有随时以高精炼地了解社会热点;为以后词云、情感分析、主题分类的学习提供了充足、优质的来源;在更好方面,做成运营(爬虫模块负责采集优质数据,数据处理模块(词云、情感分析、主题分类、数据分析等)、宣传模块(公众号、小程序、Web、邮箱等渠道))。在这三个模块有序合作,每天自动化、不断推送当日社会情况。
缺陷:前期完成了重要的分析与设计,后期编写代码时,时不时地适当地构思和修改设计框架,加大了难度;爬虫的验证模块没有做到完全自动化,这个难度较大;整体爬取效率低,耗时间;需要强化爬虫伪装性。
建议:(强烈)把大部分时间放在分析需求与设计思路方面,这方面做得越好,代码编写过程就越轻松。如果在分析与设计中,出现了大错误,造成的结果很严重。大面积修改以前的代码是很难避免的;重新分析和设计;重新编写代码。
期望:完善IP代理池(爬取免费IP代理网站)、User-Agent代理池(考虑使用第三方库)、强化爬虫伪装性、爬取效率、完全自动化爬虫、尽量使用Scrapy架构优化。
8 设计、实现和过程完整思维图

发布:2020年6月9日
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!