MapReduce求最大值
一:背景
求最值是MapReduce的常见算法,应用也很广泛,比如说求出某大型销售网站各个站点销售量最大的商品,人口最多的城市等等,MapReduce求最大值的关键是要实现cleanUp()方法。
二:技术实现
#需求 有两个文件max和max2,现要求合并两个并找出最大值。
#max文件数据如下:
10
29
50
39
88
99
29
100389
10
20
39
90
33
29999
390
900
999
22
实现代码如下:
public class MaxTest {// 定义输入路径private static final String INPUT_PATH = "hdfs://liaozhongmin:9000/max_file/*";// 定义输出路径private static final String OUT_PATH = "hdfs://liaozhongmin:9000/out";public static void main(String[] args) {try {// 创建配置信息Configuration conf = new Configuration();// 创建文件系统FileSystem fileSystem = FileSystem.get(new URI(OUT_PATH), conf);// 如果输出目录存在,我们就删除if (fileSystem.exists(new Path(OUT_PATH))) {fileSystem.delete(new Path(OUT_PATH), true);}// 创建任务Job job = new Job(conf, MaxTest.class.getName());//1.1 设置输入目录和设置输入数据格式化的类FileInputFormat.setInputPaths(job, INPUT_PATH);job.setInputFormatClass(TextInputFormat.class);//1.2 设置自定义Mapper类和设置map函数输出数据的key和value的类型job.setMapperClass(MaxMapper.class);job.setMapOutputKeyClass(LongWritable.class);job.setMapOutputValueClass(NullWritable.class);//1.3 设置分区和reduce数量(reduce的数量,和分区的数量对应,因为分区为一个,所以reduce的数量也是一个)job.setPartitionerClass(HashPartitioner.class);job.setNumReduceTasks(1);//1.4 排序//1.5 归约//2.1 Shuffle把数据从Map端拷贝到Reduce端。//2.2 指定Reducer类和输出key和value的类型job.setReducerClass(MaxReducer.class);job.setOutputKeyClass(LongWritable.class);job.setOutputValueClass(NullWritable.class);//2.3 指定输出的路径和设置输出的格式化类FileOutputFormat.setOutputPath(job, new Path(OUT_PATH));job.setOutputFormatClass(TextOutputFormat.class);// 提交作业 退出System.exit(job.waitForCompletion(true) ? 0 : 1);} catch (Exception e) {e.printStackTrace();}}public static class MaxMapper extends Mapper {// 定义一个Long类型的最小值作为临时变量private Long max = Long.MIN_VALUE;// 定义输出去的valueprivate LongWritable maxValue = new LongWritable();@Overrideprotected void map(LongWritable key, Text value, Mapper.Context context) throws IOException,InterruptedException {// 获取输入的行String line = value.toString();// 抛弃无效记录if (line == null || line.equals("")) {return;}// 把line转换为数值long temp = Long.parseLong(line);// 比较大小if (temp > max) {// 把val赋值给tempMaxmax = temp;}}/*** cleanUp()是指map函数执行完成之后就会调用,刚好满足我们的要求 因为map()函数执行完成之后我们单个任务的的最大值也就产生了*/@Overrideprotected void cleanup(Mapper.Context context) throws IOException, InterruptedException {// 把最后的处理结果写出去maxValue.set(max);context.write(maxValue, NullWritable.get());}}/*** 汇总多个任务产生的最大值,再次比较*/public static class MaxReducer extends Reducer {// 定义一个参考的临时变量private Long max = Long.MIN_VALUE;// 定义输出的keyprivate LongWritable maxValue = new LongWritable();protected void reduce(LongWritable key, Iterable value, Reducer.Context context)throws IOException, InterruptedException {if (key.get() > max) {max = key.get();}}/*** reduce任务完成后写出去*/protected void cleanup(Reducer.Context context) throws IOException, InterruptedException {// 设置最大值maxValue.set(max);context.write(maxValue, NullWritable.get());}}
}
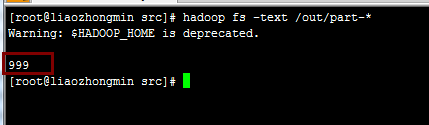
程序运行结果:
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!