bert笔记
文章目录
- 一、什么是bert
- 二、transformer和bert的区别和联系
- 三、为什么要创造Transformer这个模型
- 四、什么是Transformer
- 五、什么是self-attention
- 六、什么是多头注意力机制
- 七、bert模型的输入是什么
- 八、如何训练bert
- 九、什么是RoBERTa
- 十、BERT在下游任务中的应用方式
- 十一、BERT需要分词吗
- 十二、Albert是啥
- 十三、什么是知识蒸馏
- 十四、Transformer的优缺点
- 十五、transformer为啥要做scale
- 十六、transformer的encoder和decoder的mask有什么区别
- 十七、GPT和BERT有啥区别
- 十八、Transformer相比lstm在长距离依赖上的优势
- 十九、Transformer和RNN的输入有什么不同
- 二十、Transformer、CNN、RNN速度对比如何
- 二十一、Transformer在长距离特征抽取上的关键因素是什么
- 二十二、如果输入的句子长度超过512怎么办
一、什么是bert
BERT是Bidirectional Encoder Representations from Transformers的缩写。
bert其实就是由多层的Transformer Encoder堆叠成的,所谓的Bidirectional其实也就是Transformer中的self-attention机制。
或者也可以说是Self-Attention Layer和Layer Normalization的堆叠而成。
二、transformer和bert的区别和联系
BERT的基础架构是transformer的encoder部分。谷歌发行的bert-base使用的是12层的encoder,bert-large使用的是24层的encoder。
注意是12个encoder堆叠在一起组成了bert,而不是12层的transformer堆叠在一起组成了bert。transformer在原论文中是6个encoder堆叠在一起成了编码端,6个decoder堆叠在一起变成了解码端。
三、为什么要创造Transformer这个模型
Transformer是2017年提出的,源自谷歌那篇论文《Attention is all you need》。2017年的时候,主流的序列模型都是基于复杂的循环神经网络或者是卷积神经网络构造而来的Encoder-Decoder模型,并且就算是当时性能最好的序列模型也都是基于注意力机制下的Encoder-Decoder架构。由于这些传统的Encoder-Decoder架构在建模过程中,下一个时刻的计算过程会依赖于上一个时刻的输出,而这种固有的属性就限制了传统的Encoder-Decoder模型就不能以并行的方式进行计算。
四、什么是Transformer
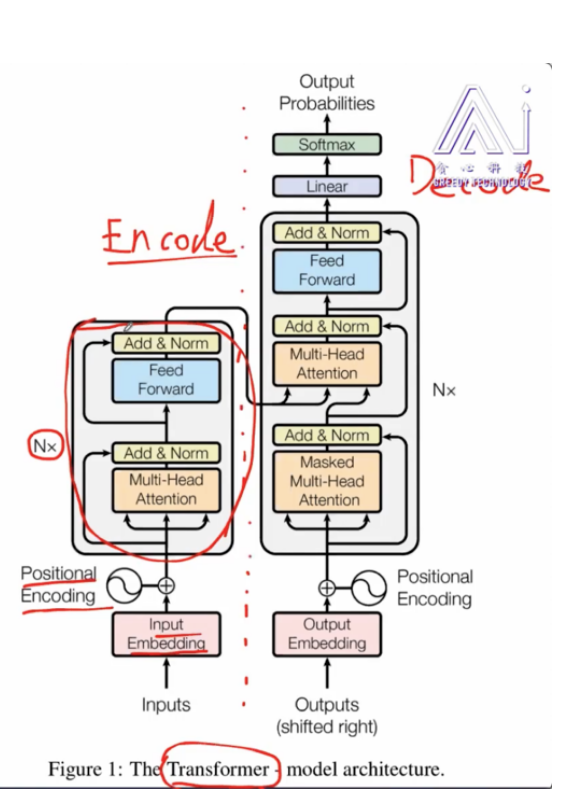
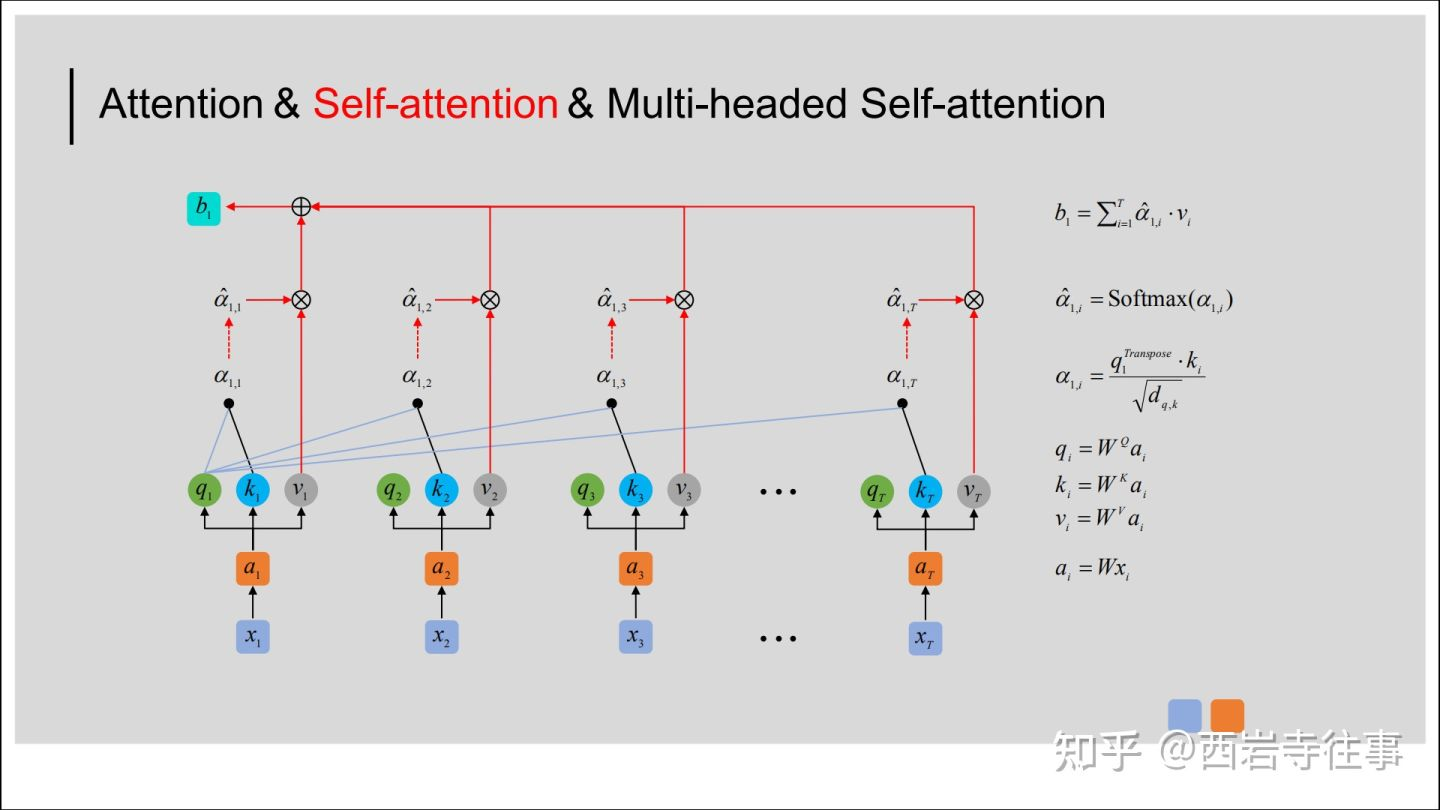
Transformer完全摈弃了传统的循环结构,而只通过注意力机制来计算模型输入与输出的隐含表示,而这种注意力机制就是大名鼎鼎的self-attention。self-attention可以描述为将query和一系列的key-value对映射到某个输出的过程,而这个输出的向量就是根据query和key计算得到的权重作用于value上的权重和。用公式表示如下:
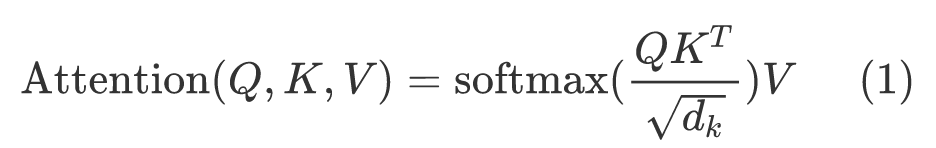 其中,Q、K和V其实就是输入X分别乘以3个不同的矩阵计算而来。而计算得到的Q、K、V,可以理解为这是对于同一个输入进行3次不同的线性变换来表示其不同的3种状态。
其中,Q、K和V其实就是输入X分别乘以3个不同的矩阵计算而来。而计算得到的Q、K、V,可以理解为这是对于同一个输入进行3次不同的线性变换来表示其不同的3种状态。
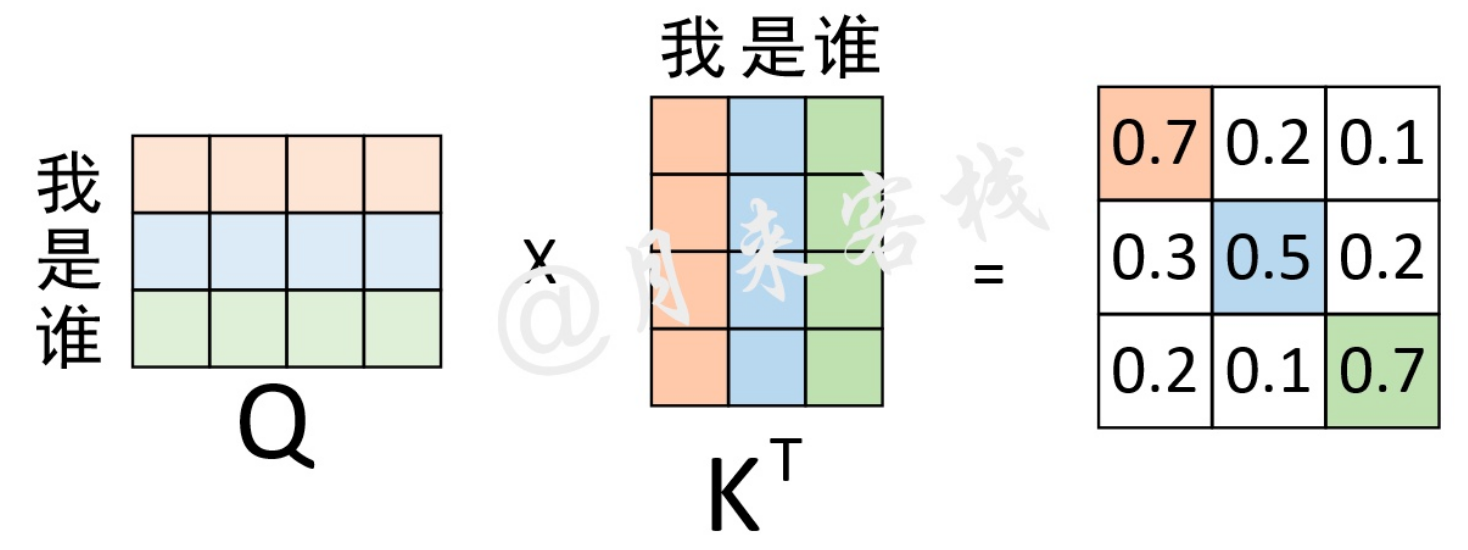 等式右边得到的注意力权重矩阵到底表示什么呢?第1行的0.7表示的就是“我”与”我”的注意力值;0.2表示的就是“我”与”是”的注意力值;0.1表示的就是“我”与”谁”的注意力值。换句话说,在对序列中的”我“进行编码时,应该将0.7的注意力放在”我“上,0.2的注意力放在”是“上,将0.1的注意力放在谁上。
等式右边得到的注意力权重矩阵到底表示什么呢?第1行的0.7表示的就是“我”与”我”的注意力值;0.2表示的就是“我”与”是”的注意力值;0.1表示的就是“我”与”谁”的注意力值。换句话说,在对序列中的”我“进行编码时,应该将0.7的注意力放在”我“上,0.2的注意力放在”是“上,将0.1的注意力放在谁上。
同理看第3行,在对序列中”谁“进行编码时,应该将0.2的注意力放在”我“上,将0.1的注意力放在”是“上,将0.7的注意力放在”谁“上。从这一过程可以看出,通过这个权重矩阵模型就能轻松的知道在编码对应位置上的向量时,应该以何种方式将注意力集中到不同的位置上。
我们发现模型在对当前位置的信息进行编码时,会过度的将注意力集中于自身的位置(这也符合我们常识)而可能忽略了其它位置。因此,一种解决方案就是采用多头注意力机制(MultiHeadAttention)。
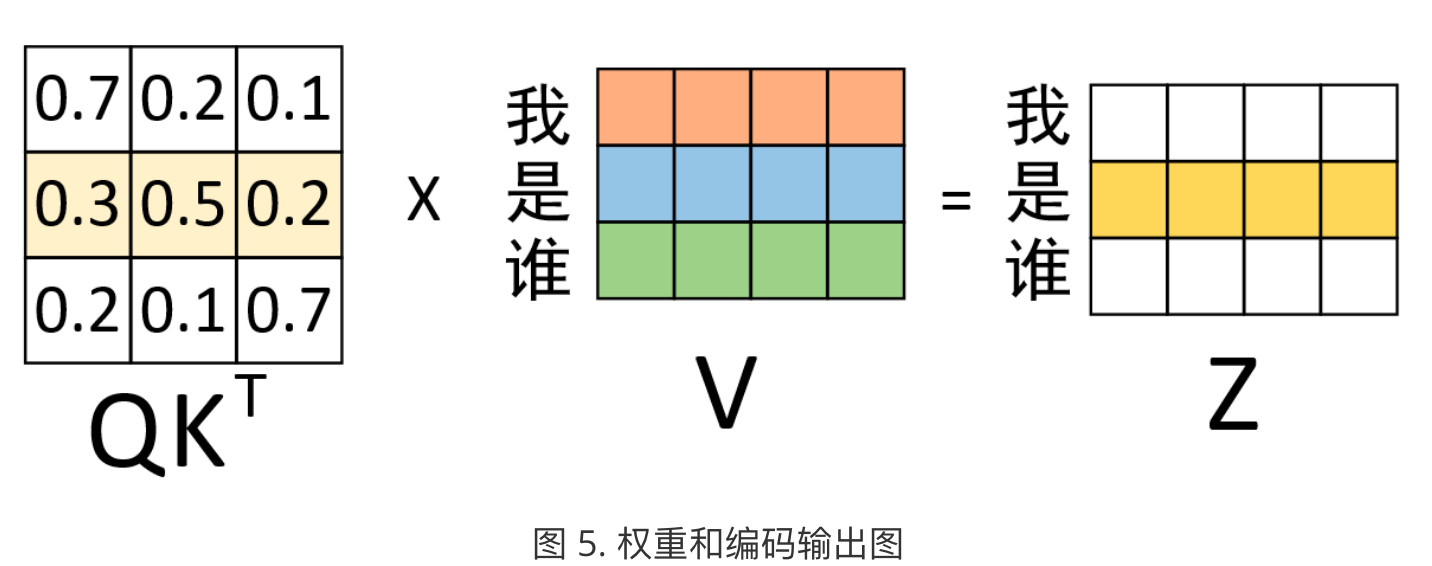 具体再观察上面的第二行:
具体再观察上面的第二行:
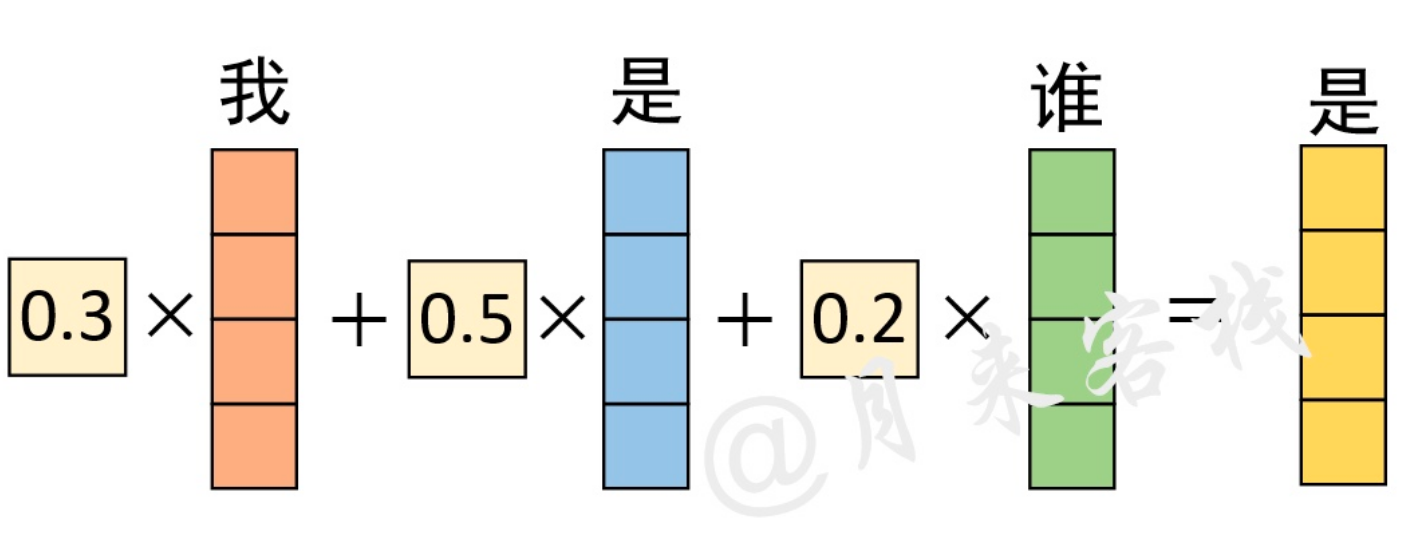 对于最终输出”是“的编码向量来说,它其实就是原始”我 是 谁“3个向量的加权和,而这也就体现了在对”是“进行编码时注意力权重分配的全过程。
对于最终输出”是“的编码向量来说,它其实就是原始”我 是 谁“3个向量的加权和,而这也就体现了在对”是“进行编码时注意力权重分配的全过程。
五、什么是self-attention
self-attention可以学习序列中不同位置之间的依赖关系,即在处理每个位置的信息时,模型会考虑序列中其他所有位置上的信息,这种机制使得 Transformer 模型能够有效地处理长距离依赖关系。
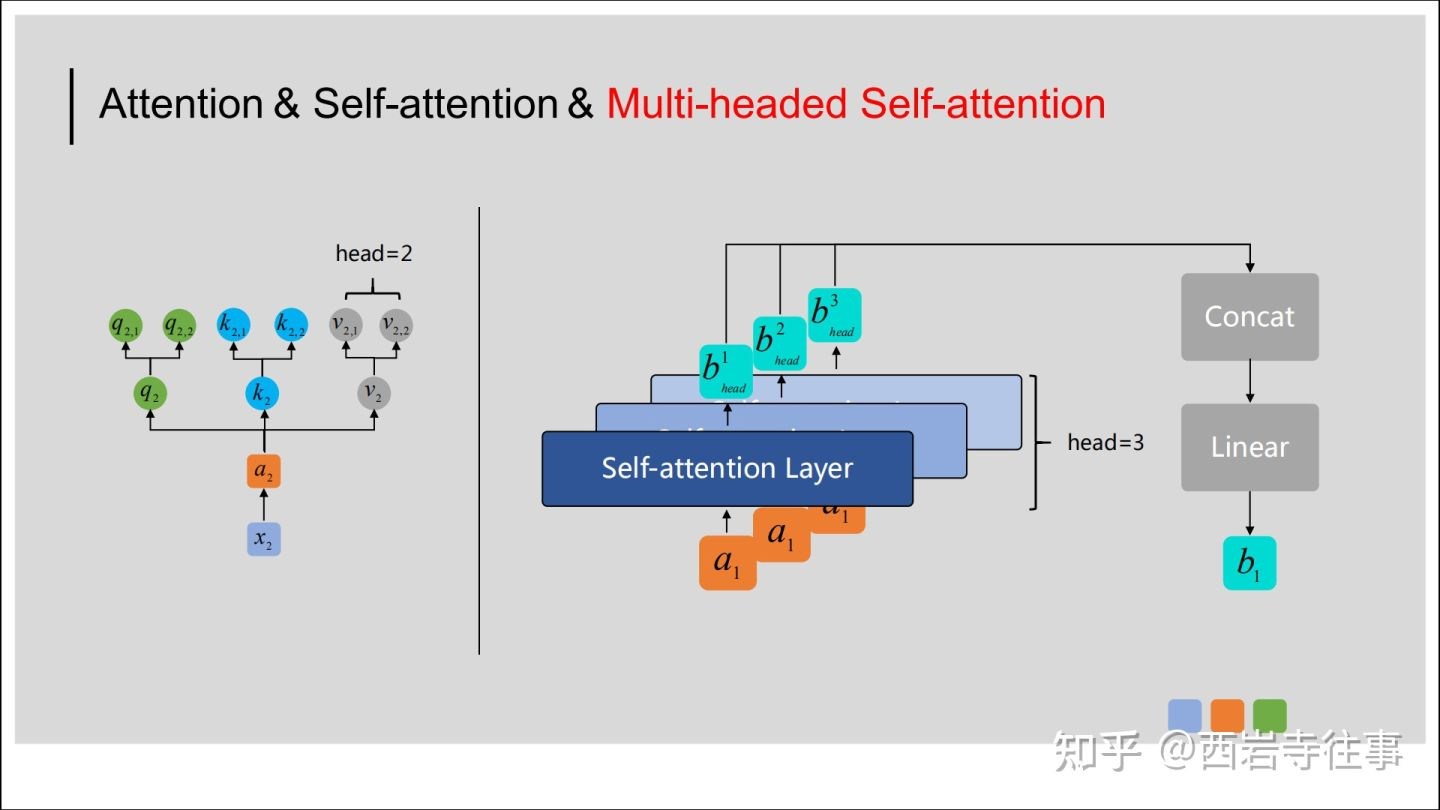
六、什么是多头注意力机制
所谓的多头注意力机制其实就是将原始的输入序列进行多组的自注意力处理过程;然后再将每一组自注意力的结果拼接起来进行一次线性变换得到最终的输出结果。
在Multi-headed Self-attention中,我们会将这里得到的![[公式]](https://img-blog.csdnimg.cn/905f142265f94dbca8155d5f111df250.png)
进行拼接(向量首尾相连),然后通过线性转换(即不含非线性激活层的单层全连接神经网络)得到![[公式]](https://img-blog.csdnimg.cn/18968e2f0dd446a28c52b963f221843c.png)
。
七、bert模型的输入是什么
将Token、Segment、Position三个Embedding相加(并进行标准化)便得到了最终的bert模型的输入向量。
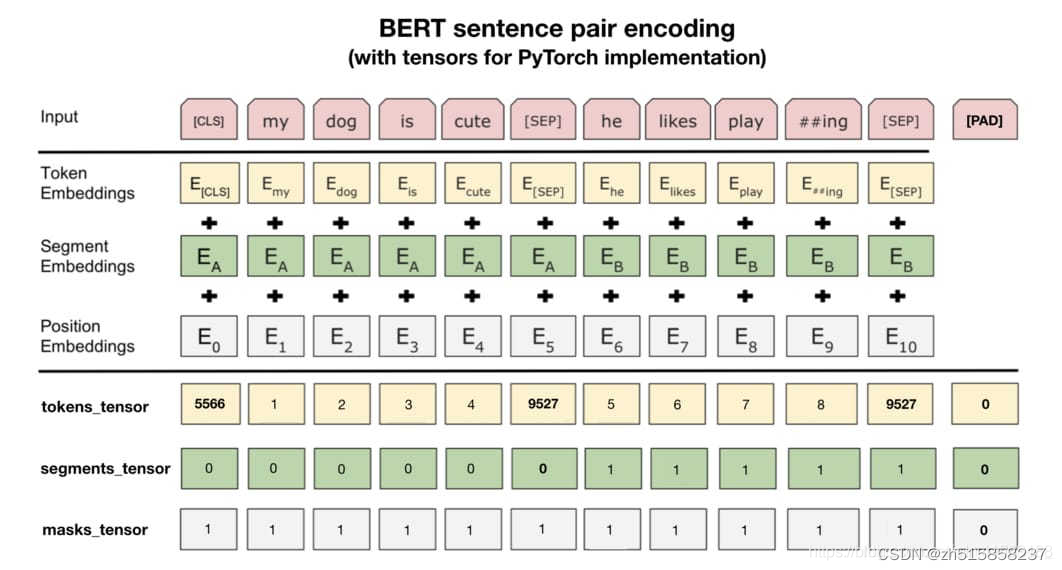
大多数地方只展示了上图中第二条分隔线之上 的内容,而实际在 PyTorch 中使用 BERT 时,第二条分隔线之下的内容才是最重要的。我们需要将文本转化为3种 id tensors:
| tensors | 含义 |
|---|---|
| tokens_tensor | 对应上文的 input_ids,存储每个 token 的索引值,用 tokenizer 转化文本获得。所有任务都需要有这个输入 |
| segments_tensor | 对应上文的 token_type_ids,用来识别句子界限。如果是单句子分类任务,默认为全0,可以不用设置该参数;如果是文本蕴含关系等句对任务,则第一个句子对应的位置全0,句子间分隔符 [SEP] 处置为0,第二个句子对应位置全1,句尾分隔符 [SEP] 处置为1, [PAD] 处全置0 |
| mask_tensor | 对应上文的 attention_mask,用来界定注意力机制范围。1表示让 BERT 关注该位置,0代表是 [PAD] 不用关注。即 [PAD]处为0,其余位置为1 |
最上面的Input表示原始的输入序列,其中第一个字符”[CLS]“是一个特殊的分类标志,如果下游任务是做文本分类的话,那么在BERT的输出结果中可以只取"[CLS]“对应的向量进行分类即可;而其中的”[SEP]"字符则是用来作为将两句话分开的标志。Segment Embedding层则同样是用来区分两句话所在的不同位置,对于每句话来说其内部各自的位置都是一样的,当然如果原始输入就只有一句话,那么Segment Embedding层中对应的每个Token的位置向量都是一样的。最后,Positional Embedding则是用来标识句子中每个Token各自所在的位置,使得模型能够捕捉到文本”有序“这一特性。
token_embedding:就是对所有的input的词汇进行向量化表示。
segment_embedding:因为我们处理的是两个句子,所以我们需要对两个句子进行区分。在第一个句子我们全部用0来表示,后面的句子我们全部用1表示,以此代表两个句子
position_embeddings:代表的是bert的输入部分,与transformer的输入部分有一个很大的不同点,在transformer中,用的是正余弦函数,在bert使用的是随机初始化,然后让模型自己去学习。比如说第一个位置定位0 第二个位置定位1 直到511。让模型自己学习embedding的向量是什么样子的。
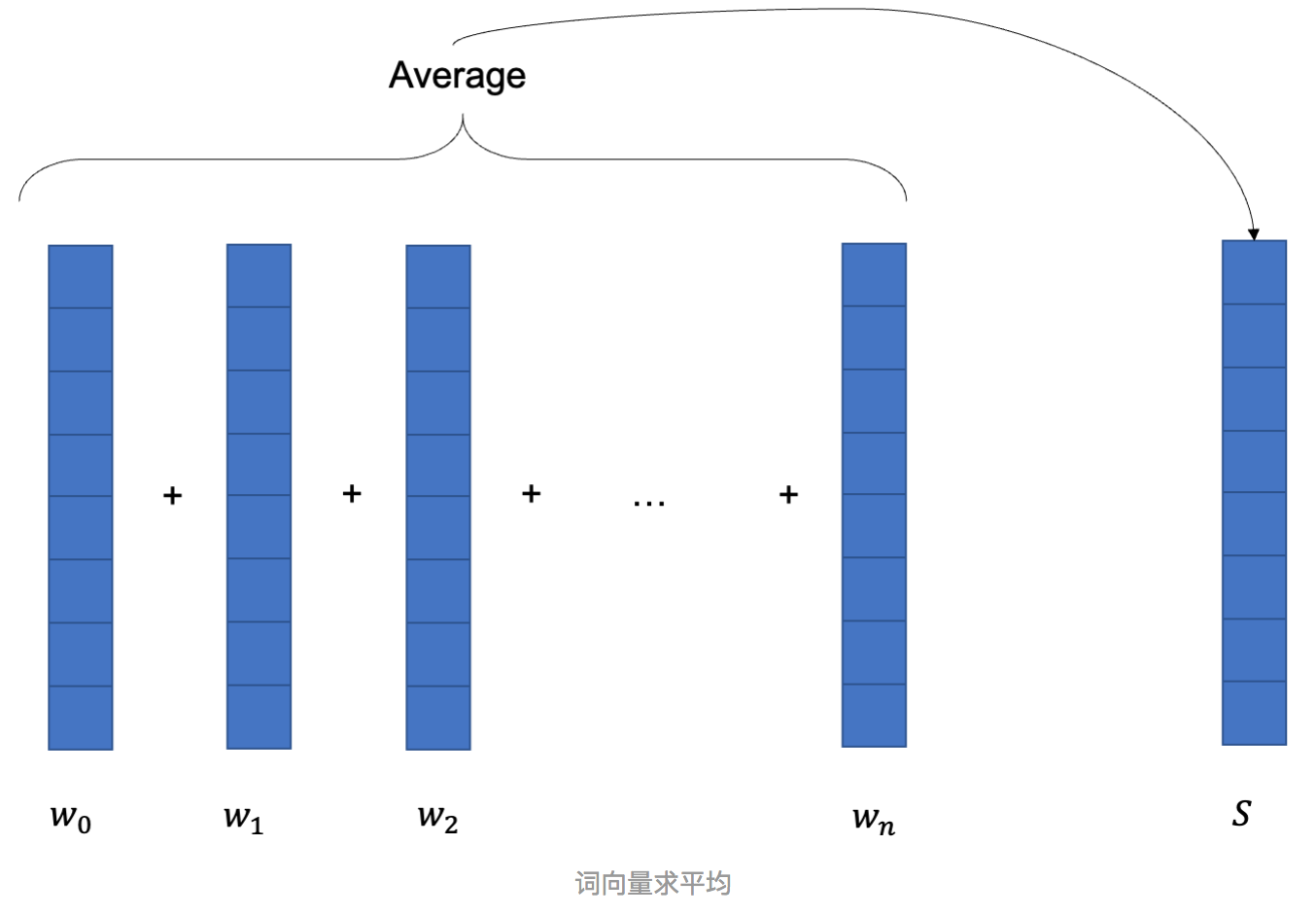
对于BERT-base,这将是一个包含768维的向量,那么一个句子在输入到bert中时将会被编码为一个矩阵:512x768。而sbert在得到句子向量时,使用的mean方法,就类似下图:
八、如何训练bert
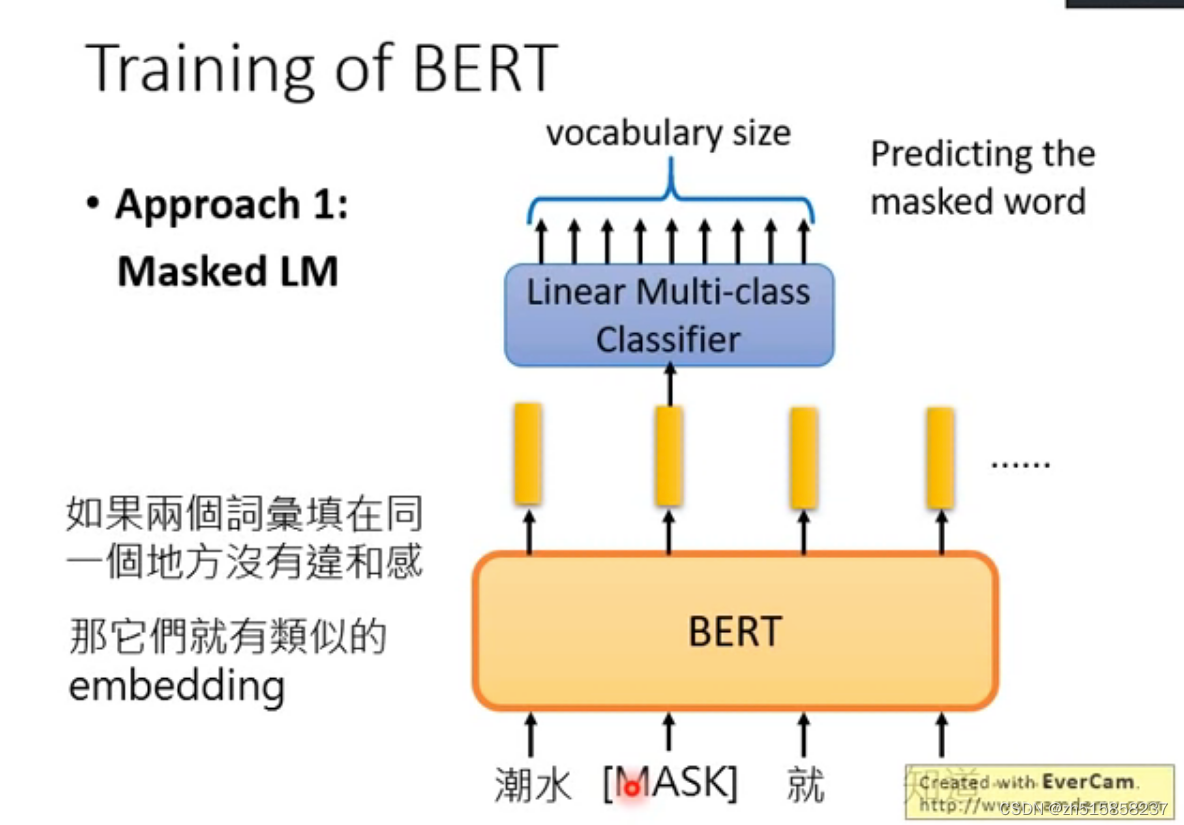
BERT在训练过程中使用了基于掩盖的语言模型(Masked Language Model, MLM),即随机掩盖掉输入序列中的Token(即用"[MASK]"替换掉原有的Token),然后在BERT的输出结果中取对应掩盖位置上的向量进行真实值预测,如下图所示:
除此之外,在训练BERT的过程中作者还加入了下句预测任务(Next Sentence Prediction, NSP),即同时输入两句话到模型中,然后预测第2句话是不是第1句话的下一句话。
BERT中的Positional Embedding对于每个时刻的位置并不是采用公式计算出来的,其原理也是类似普通的词嵌入一样为每一个位置初始化了一个向量,然后随着网络一起训练。
其实真正让BERT表现出色的就是上面基于MLM和NSP这两种任务的预训练过程,使得训练得到的模型具有强大的表征能力。
具体用图可以表示为:
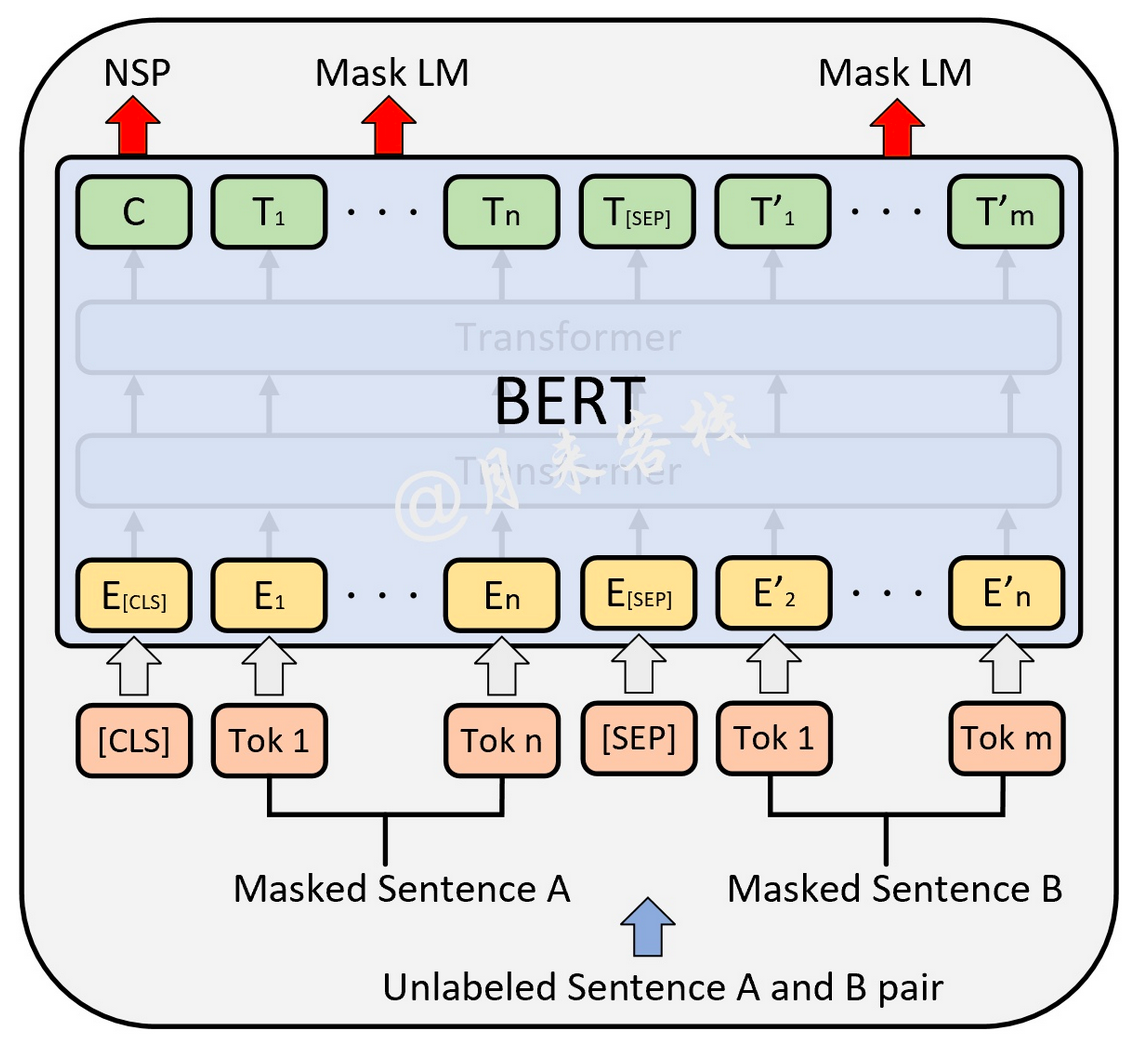 MLM和NSP这两个任务在BERT预训练时的输入输出示意图如上,其中最上层输出的C在预训练时用于NSP中的分类任务;其它位置上的T(在Sentence A或B对应位置是[MASK])则用于预测被掩盖的Token。
MLM和NSP这两个任务在BERT预训练时的输入输出示意图如上,其中最上层输出的C在预训练时用于NSP中的分类任务;其它位置上的T(在Sentence A或B对应位置是[MASK])则用于预测被掩盖的Token。
MLM的细节如下
BERT在训练时随机mask部分token,然后只预测那些被屏蔽的token。MLM学习的是单词与单词之间的关系。但是MLM存在两个问题:
- pre-train阶段与fine-tune阶段不匹配,因为在fine-tune期间不会有[mask] token;
- 每个batch只预测15%的token,因此需要训练更多的训练步骤才能收敛;
因此:
- 防止模型过度关注特定位置或masked token,模型随机遮掩15%的单词;
- mask token并不总被[mask]取代,在针对特定任务fine-tune时不需要进行[mask]标注;
具体做法:
- 随机选择15%的token;
- 选中的token并不总是被[mask] 取代,其中的80%的单词被[mask]取代;
- 其余10%的单词被其他随机单词取代;
- 剩余的10%的单词保持不变;
NSP的细节如下
下句预测(Next Sentence Prediction),该任务是一个二分类任务,预测第二句sentence是不是第一句sentence的下一句。NSP学习的是句子与句子之间的关系。
具体做法:
10. 训练数据中的50%,第二句是真实的下句;
11. 另外50%,第二句是语料库中的随机句子;
12. 前50%的标签是isNext,后50%的标签是notNext;
九、什么是RoBERTa
RoBERTa是a Robustly Optimized BERT Pretraining Approach的缩写。RoBERTa是BERT的改进版,通过改进训练任务和数据生成方式、训练更久、使用更大批次、使用更多数据等获得了State of The Art的效果;可以用Bert直接加载。
哈工大讯飞联合实验室结合中文Whole Word Masking技术以及RoBERTa模型发布中文RoBERTa-wwm-ext预训练模型。
中文RoBERTa-wwm-ext结合了中文Whole Word Masking技术以及RoBERTa模型的优势,得以获得更好的实验效果。该模型包含如下特点:
1. 预训练阶段采用wwm策略进行mask(但没有使用dynamic masking)
2. 取消了Next Sentence Prediction(NSP)
3. 不再采用先使用max_len=128的数据预训练然后再用max_len=512的数据预训练的模式,取而代之的是直接使用max_len=512的数据进行预训练
4. 训练步数适当延长,共计训练了1M步
目前哈工大讯飞联合实验室已发布的中文预训练BERT系列模型。所有发布的BERT模型均是BERT-base派生模型,即由12层Transformers组成,Attention Head为12个,隐层维度是768。
十、BERT在下游任务中的应用方式
BERT在下游任务中的应用主要有两种方式即Feature-based和Finetune-based。其中Feature -based方法将BERT作为文本编码器获取文本表示向量,从而完成文本相似度计算、向量召回等任务。而Finetune-based方法是在预训练模型的基础上,使用具体任务的部分训练数据进行训练,从而针对性地修正预训练阶段获得的网络参数。该方法更为主流,在大多数任务上效果也更好。
十一、BERT需要分词吗
bert是基于字符的,不需要中文分词,没有借助任何分词工具。
比如形容词,名词等等都是被完全拆开为单个字符作为输入的,这样的好处是大大减少了未登录词出现的概率,缺点是需要巨大的数据量才能训练出较好的效果,幸运的是,谷歌公开了预训练模型,自己训练的时候再fine-tuning下就好。
十二、Albert是啥
谷歌19年10月新出的albert模型 基于bert模型进行了三个方面的改进,小而快速,稳定性也很好,预测精度相比于bert并没有降低多少。
十三、什么是知识蒸馏
知识蒸馏,让大模型产生训练数据来训练一个小模型,通常小模型只有几十兆的模型参数。
十四、Transformer的优缺点

十五、transformer为啥要做scale
一句话概括就是:如果不对softmax的输入做缩放,那么万一输入的数量级很大,softmax将几乎全部的概率分布都分配给了最大值对应的标签,而softmax的梯度会趋向于0,导致梯度消失。
所以scale因子起到调节作用,使得内积不至于太大(太大的话softmax后就非0即1了,不够“soft”了)。
十六、transformer的encoder和decoder的mask有什么区别
Encoder中 self-attention的mask是padding mask,用于解决不定长问题,而 Decode的mask是sequence mask,是为了防止标签泄露,即在 t 时刻不能看到 t 时刻之后的信息。
1.padding mask
在encoder和decoder两个模块里都有padding mask,位置是在softmax之前,为什么要使用padding mask,是因为由于encoder和decoder两个模块都会有各自相应的输入,但是输入的句子长度是不一样的,计算attention score会出现偏差,为了保证句子的长度一样所以需要进行填充,但是用0填充的位置的信息是完全没有意义的(多余的),经过softmax操作也会有对应的输出,会影响全局概率值,因此我们希望这个位置不参与后期的反向传播过程。以此避免最后影响模型自身的效果,既在训练时将补全的位置给Mask掉,也就是在这些位置上补一些无穷小(负无穷)的值,经过softmax操作,这些值就成了0,就不在影响全局概率的预测。
2.Sequence MASK
sequence MASK是只存在decoder的第一个mutil_head_self_attention里,为什么这样做?是因为在测试验证阶段,模型并不知道当前时刻的输入和未来时刻的单词信息。也就是对于一个序列中的第i个token解码的时候只能够依靠i时刻之前(包括i)的的输出,而不能依赖于i时刻之后的输出。因此我们要采取一个遮盖的方法(Mask)使得其在计算self-attention的时候只用i个时刻之前的token进行计算。
举例:“我爱中国共产党”,假如要预测“中”这个词,那么当前时刻的输入就是“我”以及“爱”的输入的叠加,一部分来自"我“的信息输出,一部分来自”爱”的信息输出,如果没有mask将后面的单词信息遮住,那么后面的单词对要预测的这个字“中”也会有相应的信息贡献,在训练的时候整个句子的前后字词的位置是已知的,所以不遮挡模型也是可以运行的,因为本身模型输入时就已经知道了句子的整个信息(也就是ground truth embeding)。 但是在进行模型预测(测试新的输入句子)时,输入的句子是未知的,随机的,模型不知道句子的信息,只能通过上一层的输出和原始的输入知道要预测字的前一个信息,进而依次预测后面的字的信息。这就造成了在训练时模型多训练了“中”后面的词,增加了训练时间,消耗了本没必要的空间及时间。在一开始训练时就mask掉,节省时间的同时也降低了过拟合的风险,提高了模型泛化能力。
十七、GPT和BERT有啥区别
GPT 中训练的是单向语言模型,其实就是直接应用 Transformer Decoder;
Bert 中训练的是双向语言模型,应用了 Transformer Encoder 部分,不过在 Encoder 基础上还做了 Masked 操作;
BERT Transformer 使用双向 self-attention,而 GPT Transformer 使用受限制的 self-attention,其中每个 token 只能处理其左侧的上下文。
十八、Transformer相比lstm在长距离依赖上的优势
Transformer解决了RNN的长距离依赖问题,RNN只能捕获较短距离的依赖,LSTM利用门限机制,将连乘转变了为连加,提升了模型长程捕获能力,但梯度弥散问题没有从根本上得到解决,故其最大程度只能在400左右,Transformer利用self-attention机制进行建模,使得任何两个位置单词的距离都为1。如果没有内存和算力的限制,Transformer理论上可以编码无限长的文本。
十九、Transformer和RNN的输入有什么不同
Transformer是:非顺序处理,也就是句子是整体处理,而不是逐字处理
RNN是:顺序处理,也就是句子必须逐字或者逐词处理
二十、Transformer、CNN、RNN速度对比如何

从上图可以看出,如果是 self attention/CNN/RNN 单层比较计算量的话,三者都包含一个平方项,区别主要是:self attention 的平方项是句子长度,因为每一个单词都需要和任意一个单词发生关系来计算 attention,所以包含一个 n 的平方项。而 RNN 和 CNN 的平方项则是 embedding size。
如果句子平均长度 n 大于 embedding size,那么意味着 Self attention 的计算量要大于 RNN 和 CNN;反之,那么RNN 和 CNN 的计算量要大于self attention 操作。一般正常的句子长度,平均起来也就几十个单词吧。而当前常用的 embedding size 从 128 到 512 都常见,所以在大多数任务里面其实 self attention 计算效率是要高于 RNN 和 CNN 的。
目前的主流经验结论基本如上所述:Transformer Base 最快,CNN 次之,再次 Transformer Big,最慢的是 RNN。RNN 比前两者慢了 3 倍到几十倍之间
二十一、Transformer在长距离特征抽取上的关键因素是什么
对于 Transformer 来说,Multi-head attention 的 head 数量严重影响 NLP 任务中 Long-range 特征捕获能力:结论是 head 越多越有利于捕获 long-range 特征。
二十二、如果输入的句子长度超过512怎么办

上面使用510的原因是,得用512 减去这两个token:[CLS] 和 [SEP]
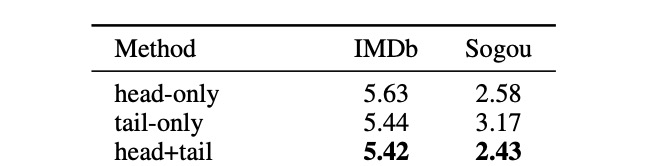
从上面的文本分类测试错误率来看,head+tail的方式是最好的
参考文献:
- https://www.ylkz.life/deeplearning/p10553832/
- https://www.ylkz.life/deeplearning/p10631450/
- https://www.ylkz.life/deeplearning/p10602241/
- https://blog.csdn.net/qq_25850819/article/details/115351471
- http://cogskl.iflytek.com/archives/924
- https://blog.csdn.net/qq_27590277/article/details/107625545
- https://www.zhihu.com/question/311141947/answer/598153866
- https://www.jianshu.com/p/21c18e3a27dd
- https://www.zhihu.com/question/317540171
- https://www.jianshu.com/p/38bc767ef412
- https://www.zhihu.com/question/339723385
- https://blog.csdn.net/weixin_37947156/article/details/100082543
- https://zhuanlan.zhihu.com/p/139595546 (NLP中的Mask介绍得很好)
- https://zhuanlan.zhihu.com/p/459972761
- https://www.zhihu.com/question/369075515 (解释了Transformer里decoder为啥需要seq mask)
- Multi-headed Self-attention(多头自注意力)机制介绍. (全网把self-attention讲解得最透彻的文章)
- https://www.cnblogs.com/yijiewufu/p/14464711.html (将RNN、CNN、Transformer进行了综合对比,讲得很好)
- https://www.zhihu.com/question/302392659
- https://www.leiphone.com/category/ai/fRHKKOZuS3wldH0o.html (对比RNN、CNN、Transformer速度)
- https://www.yanxishe.com/columnDetail/17424
- https://arxiv.org/pdf/1905.05583.pdf (讲述了如何对bertfinetune调参)
- https://zhuanlan.zhihu.com/p/101570806(把Transformer的Layer Normalization层讲述得比较好)
- https://blog.csdn.net/qq_41568188/article/details/107202905
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!