前Vit时代CV模型大串烧
AlexNet
首次应用cpu
relu替代sigmoid和tanhi
LRN局部响应归一化
dropout
VGG
堆叠多个3*3的卷积代替大尺度卷积核
提出感受野


GoogLeNet
引入inception结构(融合不同尺度的特征信息)
1*1的卷积核进行降维以及映射
两个辅助分类器帮助训练
丢弃全连接层,使用平均池化
ResNet
增加深度
residual模块
使用BN加速训练(使用BN卷积就不用bias)
ResNext
组卷积
MobileNet
V1:
DW,PW cnov
增加超参数alpha(控制卷积层卷积核个数的超参),beta(输入图像大小的超参)
深度可分离卷积:DW+PW。DW会失去通道之间的关联,通过PW将通道打通
但是DW conv部分卷积核大部分参数等于0,没有起到作用
V2:
倒残差结构(先升维,再降维)
relu6激活函数
Linear Bottlenecks:倒残差结构最后一个1*1的卷积层使用了线性激活函数。解释:relu激活函数在高维损失小,但对低维特征信息会造成大量损失,而这里采用了两头细中间粗的倒残差结构,所以替换为了线性激活函数。
模型特点:只有stride=1并且输入输出特征矩阵shape相同时才会有残差结构
V3
bneck:1、加入SE(通道注意力):对每个channel进行全局平均池化处理,得到一个维度为channel的一维向量。再经过两个全连接层得到输出。对网络认为重要的channel赋予更大的权重。
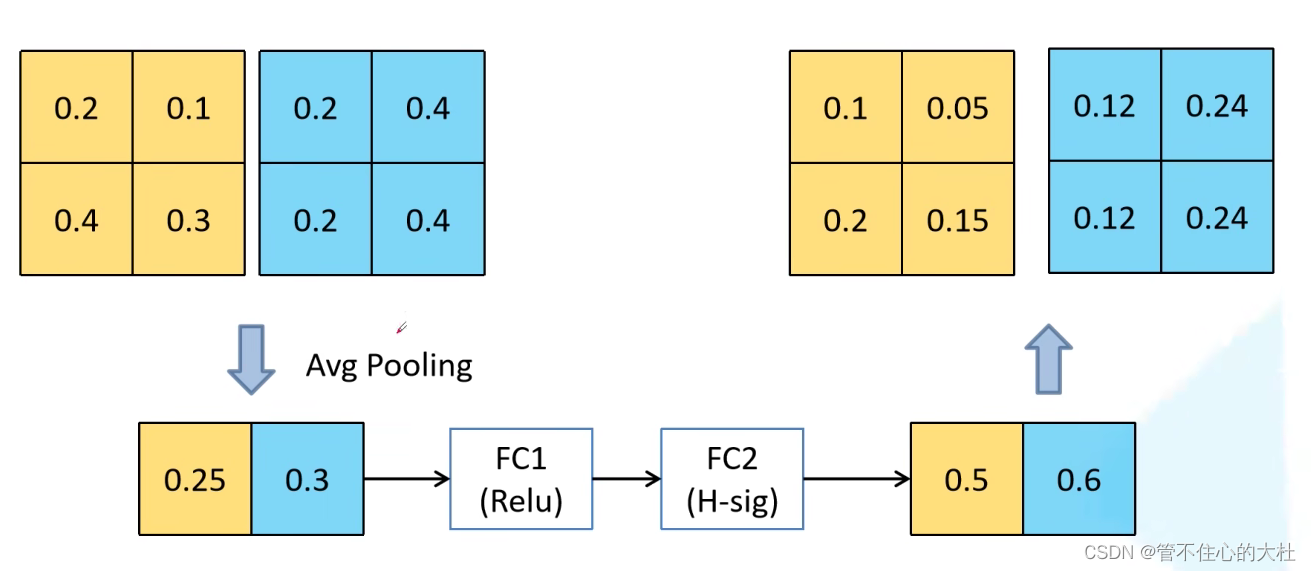
2、更新了激活函数: swishx = x * sigmoid(x)计算,求导复杂,对量化不友好。于是提出h-swichx =x * relu6(x+3)/6
使用NAS搜索参数(Neural Architecture Search),详见
神经网络结构搜索 (1/3): 基本概念和随机搜索 Neural Architecture Search: Basics & Random Search_哔哩哔哩_bilibili
重新设计耗时层结构:1、减少第一个卷积层卷积核的个数。2、精简Last Stage。
ShuffleNet
v1
提出channel shuffle:虽然组卷积可以减少复杂度,但不同组之间没有交流。
于是
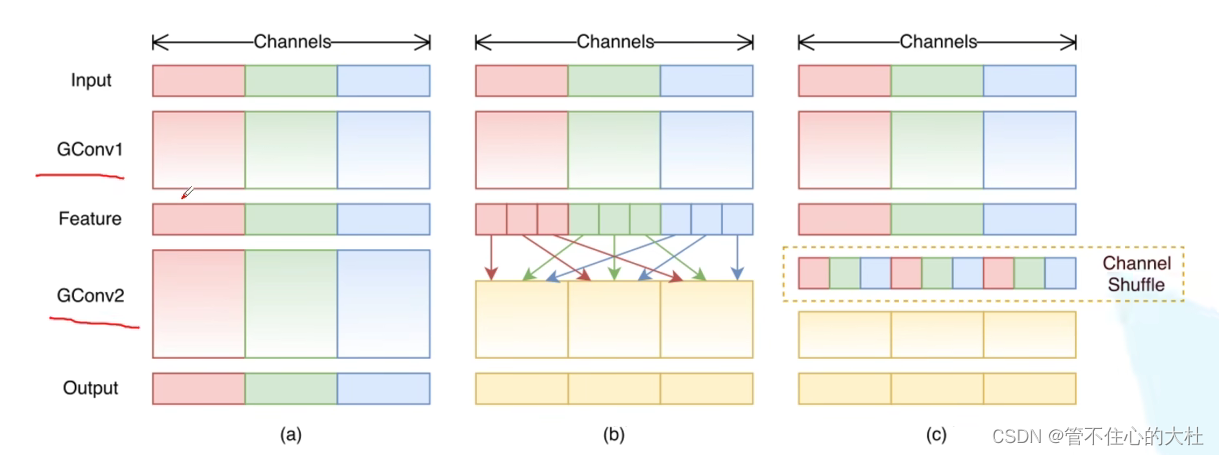
使用PW Gconv积,用3*3全局平均池化代替1*1卷积的映射:原因:1*1卷积占计算量百分之九十。
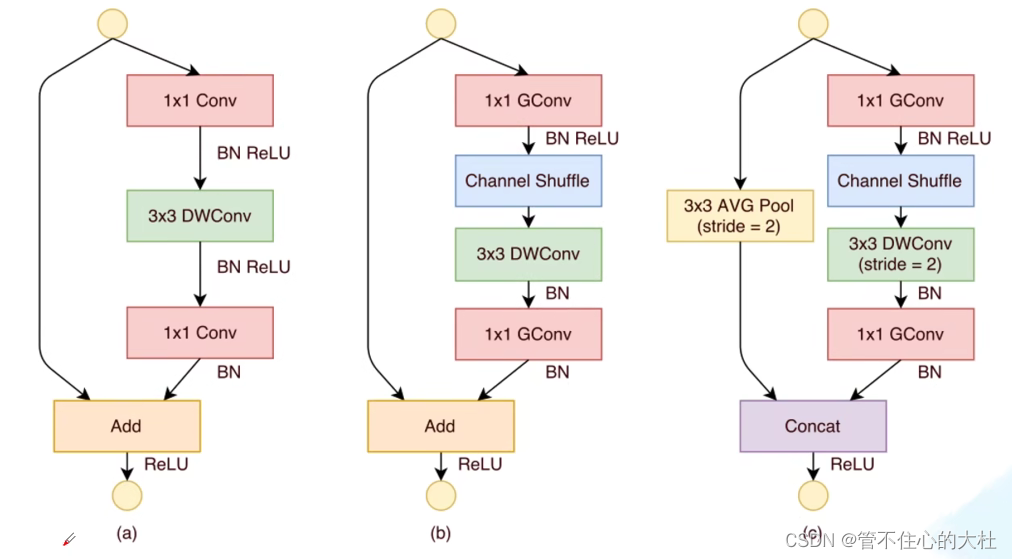
V2
计算量不能看FLOPs,比如内存访问时间(MAC),并行等级
提出四条设计高效网络准则:
1、卷积层输入输出通道数相同时MAC最小(保持FLOPs不变时)
2、Gconv的groups增大时(保持FLOPs不变),MAC也会增大
3、网络设计碎片化程度越高,速度越慢(分支程度)
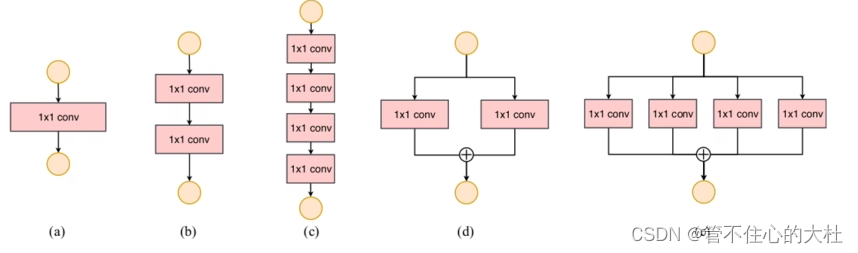
4、Element-wise操作带来的影响不可忽视。包括激活,相加,偏置bias,它们的FLOPs很小但MAC很大 。
channel split:按channel划分为两半,一半处理一半不处理最后拼接而不是加和。
EfficientNet
V1
同时探讨输入分辨率,网络深度和宽度对准确率的影响。
增加深度能够得到更加丰富,复杂的特征并能很好的应用在其他任务中,但深度过深会面临梯度消失,训练困难问题。
增加宽度能获得更高细粒度的特征并且也更容易训练,但宽度很大深度较浅的网络往往很难学到更深层次特征。
增加输入网络的图像分辨率能够潜在的获得更高细粒度的特征模版,但对于非常高的输入分辨率,准确率的增益也会减小,并且大分辨率图形会增加计算量。
具体d,w,resolution与准确度之间的关系见EfficientNet网络详解_太阳花的小绿豆的博客-CSDN博客
存在问题:图形尺寸很大时训练速度很慢,网络浅层使用DW conv速度很慢(无法利用一些现有的加速器),同等的放大每个stage是次优的。
V2
引入Fused-MBConv模块
引入渐进式学习策略:根据训练图像尺寸动态调节正则方法(提升训练速度,准确率)
对V1问题的解决:
限制图像尺寸;
引入Fused-MBConv模块(3*3的卷积代替1*1卷积+3*3DW Conv,又转回去了。。。),但不是无脑的换成fused,而只在浅层中替换。
引入渐进式学习策略:根据训练图像尺寸动态调节正则方法(提升训练速度,准确率)。在早期时采用较小的训练尺寸以及较弱的正则方法,这样网络可以快速地学到一些简单的表达能力。接着逐渐提升图像尺寸,同时增强正则方法(dropout,randaugment,mixup)。
RepVGG
结构重参数化:训练时多分支,推理时单路。
1、结果:更快,更省内存,更加灵活。
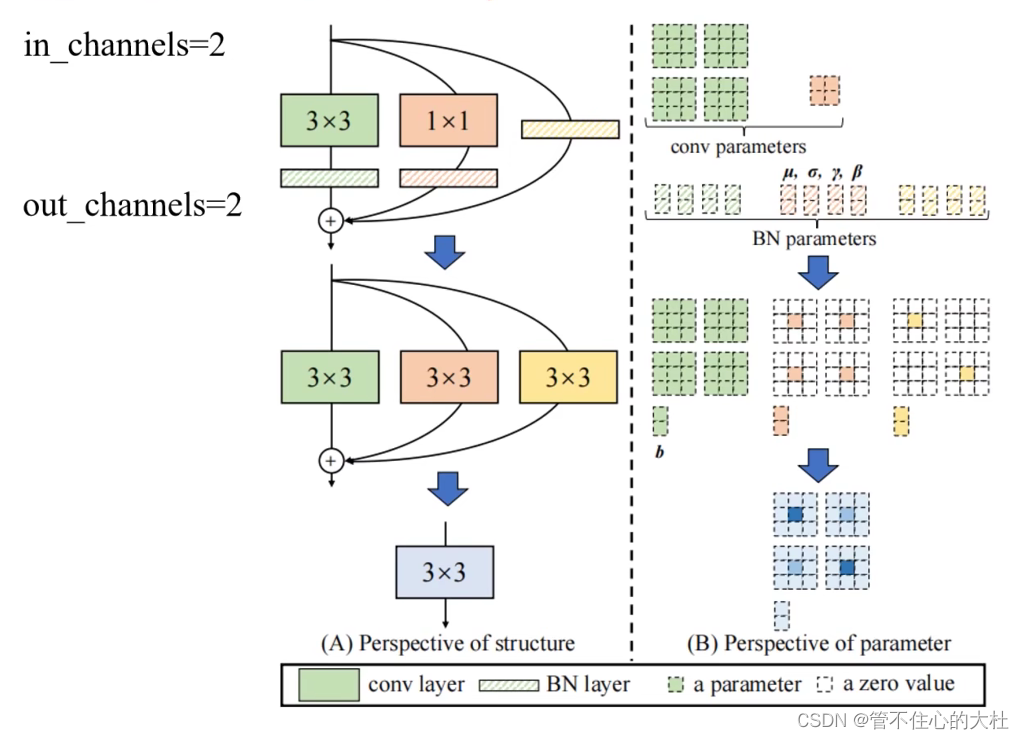
2、3*3与BN融合,1*1先转化成3*3再与BN融合,identity进行恒等映射得到3*3卷积层再与BN融合。
原理:
1、卷积与BN融合:相当于在原来卷积核乘一个常数,再加上一个bias

2、1*1变3*3:只用padding上一圈0

3、identity变3*3:通过如下所示直接进行恒等映射。
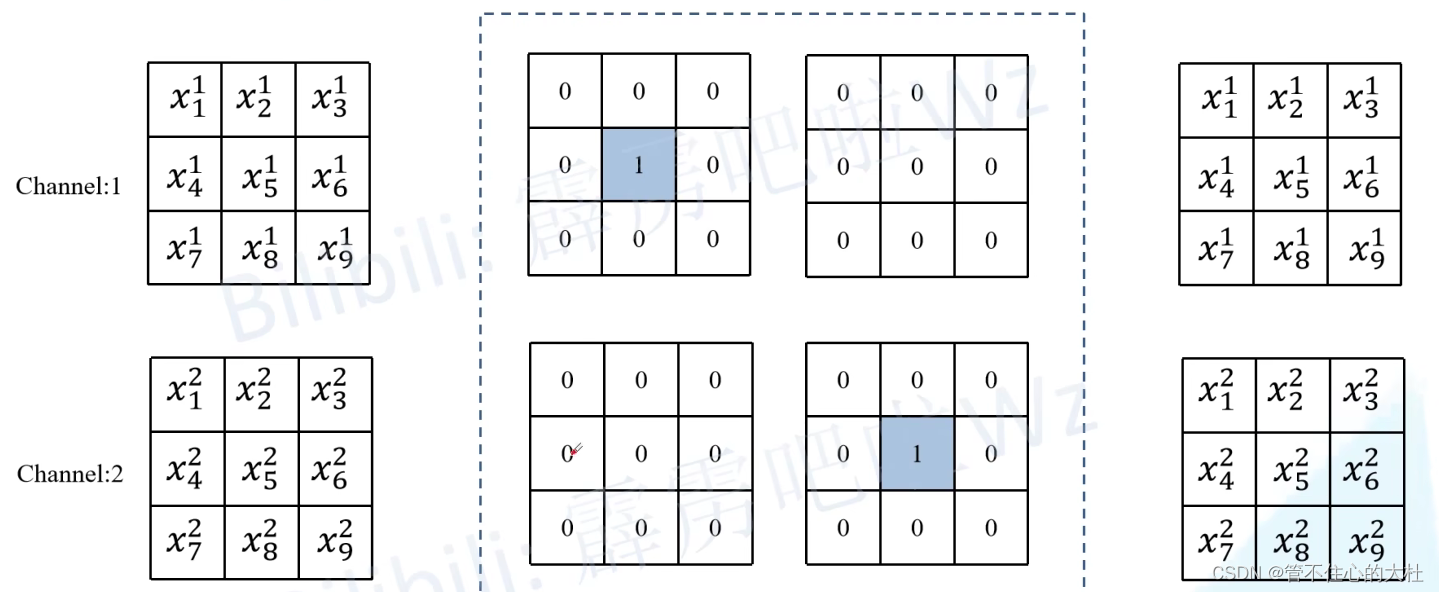
4、融合:利用结合律。

本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!