小白都能看明白的数据分析入门重点——SQL理论+实操
最近市面上很火的一个行业——数据分析师,作为数据分析师,感觉像是一个很高大上的工作岗位,之前的时候有同学毅然决然的投身其中,这不,这几天闲聊,我就问他你们都干嘛啊,他说:没想到换了工作,SQL还是常用的工具,我就问他为什么?他说常规的数据分析,有什么比数据库好用,大数据量的数据分析,像hive、sparkSQL又都支持sql操作,所以sql还是占用了很大一部分空间
快挂电话的时候这老小子跟我说:我知道你小子SQL好,快点给我整理一下SQL 的相关知识,我正好最近接了一个“私教”的活,也需要一套系统的“授课”体系,也就顺手一起整理一下吧
适应人群
1、刚开始学习的小白:这是5天的“私教”课程,我教自家的小外甥的,他也是计算机系的学生
2、工作有一段时间想要巩固一下基础的,建议也能回忆一下,我当时整理的时候发现很多都开始遗忘了,除了常用的
注:篇幅太长,我分两篇文章进行整理,需要更完整的文档的,敬请期待
1 sql基础讲解
着重介绍数据库的定义语言,操纵语言,数据控制语言和事物控制语言。
数据库定义语言(DDL,Data Definition Language)是负责数据的模式定义与数据的物理存取构建,说白了CREATE建表语句,ALTER 更新表结构语句,DROP 删除语句
CREATE建表语句
//创建表的基本语句:create table 表名(字段名 类型,字段名 类型,字段名 类型....)#创建学生表:学号,姓名,性别,年龄,qq号,邮箱。create table student(snum number(10),//指定学号的数字长度为10sname varchar2(100),//指定姓名的存储上限为100个字节sex char(4),age number,qq number,sal number(6,2),//指定工资的整数位为6和小数位为2mail varchar2(50))Drop删除表
#删除表:DROP TABLE 表名;
drop table deptALTER更新表结构
#添加新字段 alter table 表名 add 字段名 类型alter table student add phone number(11)#修改字段类型 alter table 表名 modify 字段名 类型alter table student modify sname varchar2(200)#删除字段 alter table 表名 drop column 字段名alter table student drop column phone数据操纵语言
数据操纵语言(DML,Data Manipulation Language):负责数据的操纵,包括查询及增、删、改等操作,SELECT(选择),DELETE(删除),UPDATE(更新),INSERT(插入)四类语法。
SELECT(选择)
SELECT说起来大家都不陌生,它是SQL中最常见的语法,主要用法是从数据表中选择你想要的那几列数据,因为select相对应的知识点真的太多了,后面单独那一章来给大家进行整理
#删除表:DROP TABLE 表名;
drop table dept
#删除数据:delete 表名 where 条件
delete dept where deptno='70'
delete from dept //删除所有数据DELETE(删除)
DELETE删除行,甚至删除所有的行,但是并不删除表本身。如果要快速删除所有行,可以使用TRUNCATE TABLE语句,因为不记录数据变动。下面举几个例子。
#删除数据:delete 表名 where 条件
delete dept where deptno='70'
delete from dept //删除所有数据UPDATE(更新)
UPDATE(更新)由三部分组成,分别是要更新的表,列名和他们的新值,确定要更新那些行的过滤条件。
#更新一列
UPDATE Customers SET cust_email = 'kim@thetoystore.com' WHERE cust_id = '1000000005';
#更新多列
UPDATE Customers SET cust_contact = 'Sam Roberts', cust_email = 'sam@toyland.com' WHERE cust_id = '1000000006';
#删除某列,删除某列可以将该列设为null
UPDATE Customers SET cust_email = NULL WHERE cust_id = '1000000005';
#更新表中所有的行
UPDATE Customers SET cust_email = 'kim@thetoystore.com' INSERT(插入)
INSERT插入可以在数据表中插入完整的行,插入行的一部分,插入某些查询结果,下面我们将会给出几个例子进行说明。
/*1、语法规范 insert into 表名(字段1,字段2,字段3,....)values('值1','值2','值3'.....)2、主键:用来唯一标识一条数据的字段通常设置主键,主键是唯一不可以重复的3、如果插入的数据是全字段数据,字段可以省略不写。部分字段,必须加上字段说明和字段值,但是主键不能为空
*/#在北京新建了一个名为LOL学院的新部门,请插入insert into dept(deptno,dname,loc)values('50','lol学院','北京');insert into dept values('80','教学部','北京');#插入某些查询结果INSERT INTO Customers(cust_id, cust_contact, cust_email)SELECT cust_id, cust_contact, cust_email
FROM CustNew;数据控制语言
数据控制语言(DCL,Data Control Language):负责数据完整性、安全性的定义与检查以及并发控制、故障恢复等功能,主要语法有GRANT授权,REVOKE取消授权等。大部分情况下,这部分语法主要是提供给数据库工程师以及数仓开发使用的,分析师不太能用到这些语法,所以也不细讲了。
#给创建的用户赋予角色。 GRANT ON TO [IDENTIFIED BY ""]GRANT USAGE ON *.* TO 'discuz'@'localhost' IDENTIFIED BY PASSWORD# 删除用户权限 revoke [权限1],[权限2]on [对象类型] [对象名]from [用户]revoke update on Student from User3 事务控制语
事务控制语言(TCL,Transaction Control Language)包括SAVEPOINT 设置保存点,它是事务处理中设置临时的占位符,可以对它发布回退;ROLLBACK 回滚,撤销指定的SQL语句;COMMIT提交,将未储存的SQL写入数据库表。
ROLLBACK 回滚
select * from ordertotals;
start transaction;
delete from ordertotals;
select * from ordertotals;
rollback;
select * from ordertotals;COMMIT提交
start transaction;
delete from orderitems where order_num = 20010;
delete from orders where order_num = 20010;
commit;2 sql处理函数
这里会整理一些常用的sql函数进行介绍,包括去重,聚合函数,常用的数值处理函数,条件筛选以及排序进行讲解。
在日常的工作过程中,这些函数会帮你解决很多的数据操作问题,提升工作效率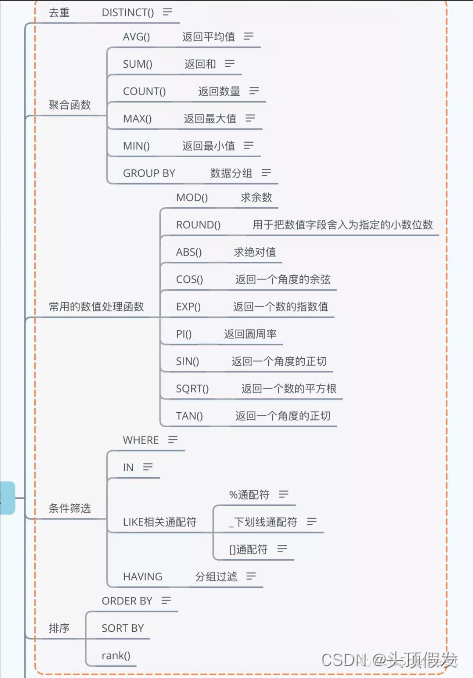
Distinct数据去重
从Products中筛选出无重复的vend_id 。
SELECT AVG(prod_price) AS avg_price
FROM Products;聚合函数
#AVG( )返回平均值
SELECT AVG(prod_price) AS avg_price
FROM Products;#SUM( ) 汇总求和
SELECT SUM(quantity) AS items_ordered
FROM OrderItems
WHERE order_num = 20005; #COUNT( )返回数量
//count(*)返回所有值,包括null
SELECT COUNT(*) AS num_cust
FROM Customers;//count(字段名)只返回该字段不为null的值
SELECT COUNT(cust_email) AS num_cust
FROM Customers;#MAX()/MIN()求最大最小值
SELECT MAX(prod_price) AS max_price
FROM Products;SELECT dt,COUNT(*) AS num_items,MIN(prod_price) AS price_min,MAX(prod_price) AS price_max,AVG(prod_price) AS price_avg
FROM Products
GROUP BY dt;数值处理函数
主要是将数值型的数据转换为其余数,绝对值,余弦值,正切值等,具体用如下:
SELECT dt,COUNT(*) AS num_items,MOD(prod_price) AS price_mod,ROUND(prod_price) AS price_round,ABS(prod_price) AS price_abs,SQRT(prod_price) AS price_sqrt
FROM Products
GROUP BY dt;条件筛选
#WHERE的用法
SELECT prod_name, prod_price FROM ProductsWHERE prod_price = 3.49;
//AND
SELECT prod_id, prod_price, prod_name
FROM Products
WHERE vend_id = 'DLL01' AND prod_price <= 4; //OR
SELECT prod_name, prod_priceFROM ProductsWHERE vend_id = 'DLL01' OR vend_id = ‘BRS01’;#IN的用法
SELECT prod_name, prod_price
FROM Products
WHERE vend_id IN ( 'DLL01', 'BRS01' )
ORDER BY prod_name;#LIKE相关通配符
// 1.%通配符 查找有bean bag的字段
SELECT prod_id, prod_name
FROM Products
WHERE prod_name LIKE '%bean bag%';
//2._下划线通配符
SELECT prod_id, prod_name
FROM Products
WHERE prod_name LIKE '__ inch teddy bear';
//3.[]通配符
//寻找J或M开头的姓名
SELECT cust_contact
FROM Customers
WHERE cust_contact LIKE '[JM]%'
ORDER BY cust_contact;//此通配符之前加一个括号可以表示否定,即寻找不是J或M开头的人
SELECT cust_contact
FROM Customers
WHERE cust_contact LIKE '[^JM]%' ORDER BY cust_contact; #HAVING分组过滤
SELECT vend_id, COUNT(*) AS num_prods
FROM ProductsWHERE prod_price >= 4GROUP BY vend_id
HAVING COUNT(*) >= 2;数据排序
# ORDER BY 数据排序
SELECT prod_id, prod_price, prod_name
FROM Products
ORDER BY prod_price DESC, prod_name;#分组查询过滤排序
SELECT order_num, COUNT(*) AS items FROM OrderItems
GROUP BY order_num
HAVING COUNT(*) >= 3
ORDER BY items, order_num;3 表关联
讲解SQL中的数据表关联,包括UNION,JOIN的操作。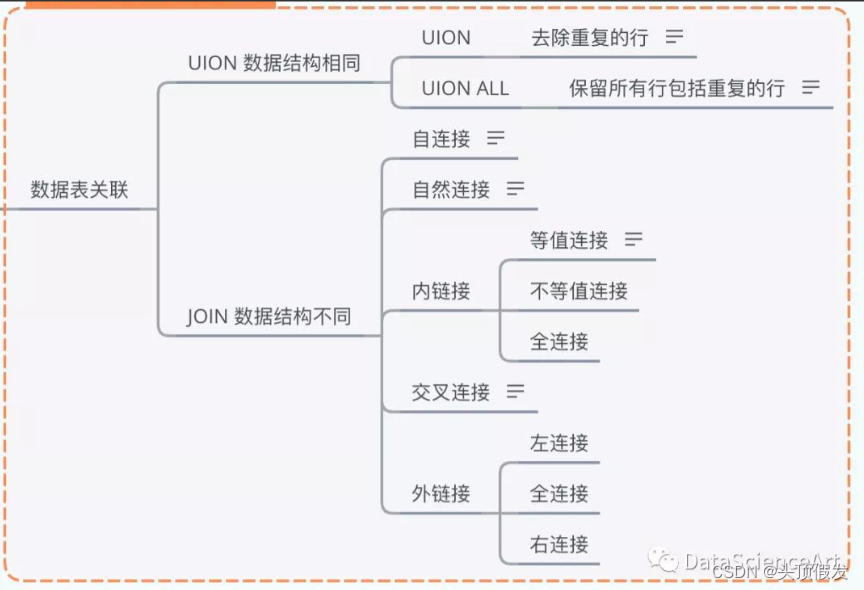
UION关联数据结构相同的表
UION包括UION 和UION ALL,二者都是用来关联数据结构相同的数据表,二者的区别在于UION关联之后会去除重复的行,而 UION ALL会保留所有的行。
/*SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;*/
# UNION 示例
SELECT cust_name, cust_contact, cust_emailFROM CustomersWHERE cust_state IN ('IL','IN','MI')UNION SELECT cust_name, cust_contact, cust_emailFROM Customers/*SELECT column_name(s) FROM table1
UNION ALL
SELECT column_name(s) FROM table2;*/
# UION ALL示例
SELECT cust_name, cust_contact, cust_email
FROM Customers
WHERE cust_state IN ('IL','IN','MI')
UNION ALL SELECT cust_name, cust_contact, cust_email
FROM CustomersJION关联数据结构不同的表
JION类型比较多,包括自连接,自然连接,内链接,交叉连接和外链接,其主要类型汇总如下图。
自连接
两张相同的表,自己和自己连接
SELECT c1.cust_id, c1.cust_name, c1.cust_contact
FROM Customers AS c1, Customers AS c2
WHERE c1.cust_name = c2.cust_name
AND c2.cust_contact = 'Jim Jones'; 自然连接
SELECT C.*, O.order_num, O.order_date, OI.prod_id, OI.quantity, OI.item_price
FROM Customers AS C, Orders AS O, OrderItems AS OI
WHERE C.cust_id = O.cust_id AND OI.order_num = O.order_num AND prod_id = 'RGAN01';内链接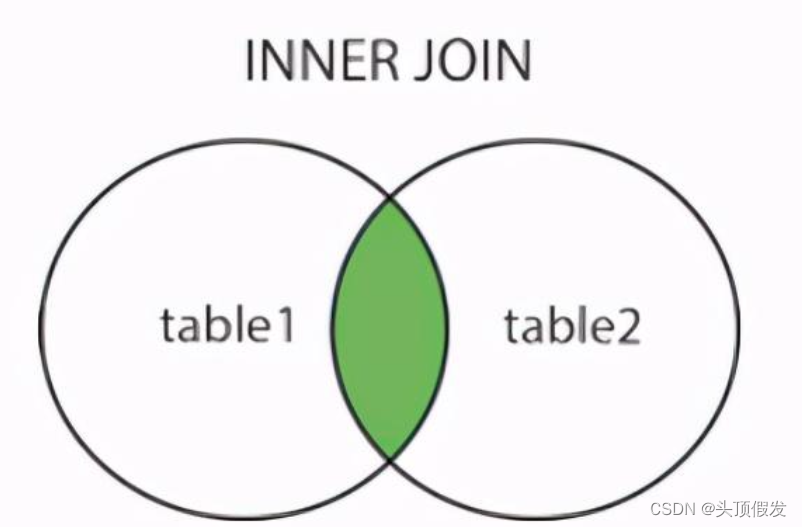
/*SELECT column_name(s)
FROM table1
JOIN table2
ON table1.column_name=table2.column_name;*/
#实例:
SELECT vend_name, prod_name, prod_price FROM Vendors
INNER JOIN Products ON Vendors.vend_id = Products.vend_id;交叉连接
没有联结条件的联结是交叉连接,也称为笛卡尔积
SELECT vend_name, prod_name, prod_price FROM Vendors, Products;外连接
1.左外连接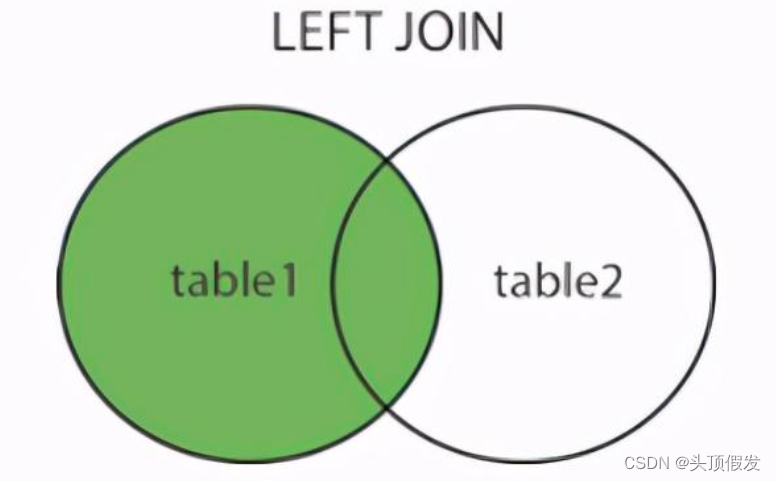
/*SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;*/
#实例
SELECT Websites.name, access_log.count, access_log.date
FROM Websites
LEFT JOIN access_log
ON Websites.id=access_log.site_id
ORDER BY access_log.count DESC;2.全连接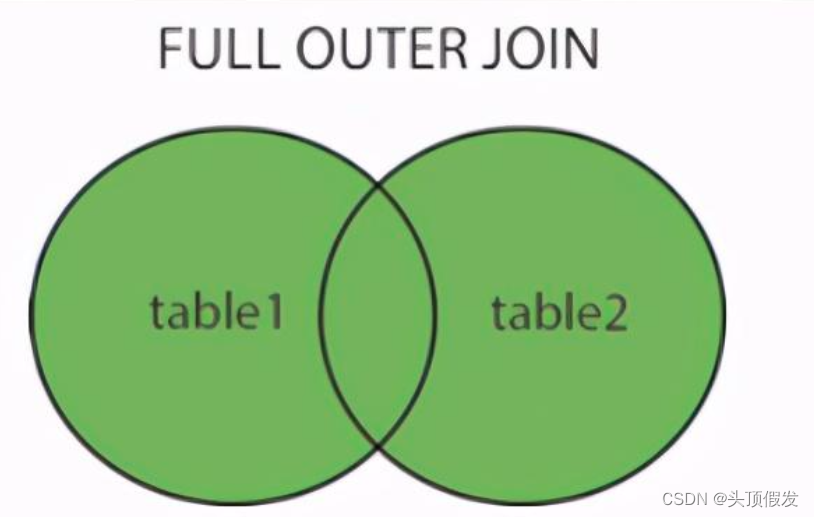
/*SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;*/
#实例
SELECT Websites.name, access_log.count, access_log.date
FROM Websites
FULL OUTER JOIN access_log
ON Websites.id=access_log.site_id
ORDER BY access_log.count DESC;3.右连接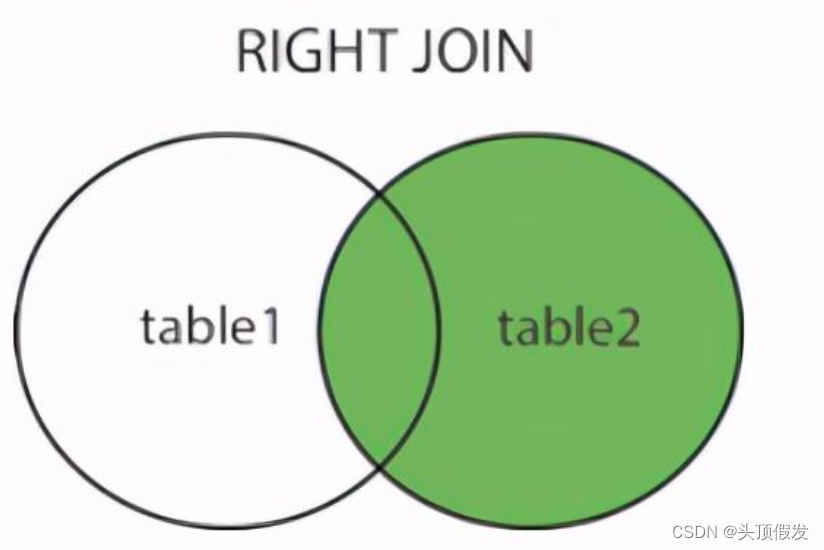
/*SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name=table2.column_name;*/
#实例
SELECT websites.name, access_log.count, access_log.date
FROM websites
RIGHT JOIN access_log
ON access_log.site_id=websites.id
ORDER BY access_log.count DESC;本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!