1、picodet模型全流程-VOC格式数据准备模型训练验证导出推理
文章目录
- 1 环境准备
- 2 数据准备
- 2.1 清理检查数据集
- 2.2 划分训练和验证集
- 2.3 获取标注类别
- 2.4 整合所有文件的训练、验证及训练名称
- 3 开始模型训练
- 3.1 准备数据配置文件
- 3.2 对运行时文件进行修改
- 3.3 模型网络参数picodet_v2.yml
- 3.4 训练优化参数optimizer_300e.yml
- 3.5 数据读取器配置picodet_640_reader.yml
- 3.6 主配置文件修改
- 3.7 GPU训练
- 4 模型评估
- 5 模型推理
- 6 模型导出
- 7 导出后模型推理
- 8 小目标检测推理
- 9 后记
本文只读官方文档和aistation上的一个 参考,整个过程以picodet L为例,对VOC格式数据进行模型训练、验证、推理、导出全流程。 本博客对于使用PaddleDetection构建目标检测模型具有参考意义,其它模型流程基本是一样的,只要修改配置文件即可,对于anchor based的模型,会多一点步骤,加数据集anchors生成,后续博客中会加入。
1 环境准备
PaddleDetection从github拉取后,放到需要位置即可;相关的依赖在requirements.txt中,所有依赖都安装即可。以下所有代码执行位置都在/path/PaddleDetection下。本文档的编写使用版本为PaddleDetection 2.4。
2 数据准备
我们以VOC格式为例,当然COCO也是可以的,而且在tools/x2coco.py可以将其它格式数据集转换成coco格式。两都都是可以的,官方使用的COCO居多,可能是因为对更多任务通用,其它数数集也方便转换。但我们还是使用VOC格式,因为数据方便使用labelimg标注工具来查看数据集标注情况。
对于多个数据集或单个数据集,但每个数据集必须由图片和标注文件夹组成,可以是imgs,xml,或者 VOC的JPEGImages,Annotations;如下有多个文件夹。关于数据的较验和清洗,可以查看我的其它有关目标检测数据集的处理的博客。
VOCdevkit/
├── d1
│ ├── Annotations
│ └── JPEGImages
├── l0
│ ├── Annotations
│ └── JPEGImages
├── l1
│ ├── Annotations
│ └── JPEGImages
├── l2
│ ├── Annotations
│ └── JPEGImages
├── l3
│ ├── Annotations
│ └── JPEGImages
└── l4├── Annotations└── JPEGImages18 directories, 0 files
最后一定是图片和标注文件一一0相对应的。
接下来可以把各个文件夹的数据混合在一起进行处理,或者是分别处理,最后再合并,我们采用第二种方式,因为,在实际工作中,可能不同文件夹来自不同的数据源,或都我们是后期采集的要单独加进来。
2.1 清理检查数据集
处理代码如下:
import os
from PIL import Image
from tqdm import tqdm
import re
import copy
def convert(datapath,background=False):imgpaths = os.path.join('VOCdevkit',datapath,'JPEGImages')annpaths = os.path.join('VOCdevkit',datapath,'Annotations')if not os.path.exists(imgpaths):print("该数据集不存")returnimgfiles = sorted(os.listdir(imgpaths))if not len(imgfiles):print("该数据集中无图片")else:#避免使用加号、减号或者"."作为普通文件的第一个字符,文件名避免使用下列特殊字符,包括制表符和退格符#['/', '\t', '\b', '@', '#', '$', '%', '^', '&', '*', '(', ')', '[', ']'],最长不超过255p = "^[^+-./\s\t\b@#$%*()\[\]][^/\s\t\b@#$%*()\[\]]{1,254}$"for imgfile in tqdm(imgfiles):#进行文件名检查newimgfile = copy.deepcopy(imgfile)if not re.match(p,imgfile):#文件名不符合要求进行处理if not re.match("[^+-./\s\t\b@#$%*()\[\]]",imgfile[0]):newimgfile=newimgfile[1:]p1 = "[/\s\t\b@#$%*()\[\]]"b = set(re.findall(p1,newimgfile))for i in b:newimgfile=newimgfile.replace(i,'_')file_name,file_extend = os.path.splitext(imgfile)new_file_name,new_file_extend = os.path.splitext(newimgfile)imgpath = os.path.join(imgpaths,imgfile)annpath = os.path.join(annpaths,file_name+'.xml')destimgpath = os.path.join(imgpaths,new_file_name+file_extend)destannpath = os.path.join(annpaths,new_file_name+'.xml')#对图片进行重命名os.rename(imgpath,destimgpath)#对标注文件进行重命名if not background:os.rename(annpath,destannpath)else:destimgpath=os.path.join(imgpaths,imgfile)try: img = Image.open(destimgpath)except:print("image format wrong remove it")os.remove(destimgpath)continueif img.mode !='RGB':img = img.convert('RGB')#删除原图,保存转换后的图os.remove(destimgpath)img.save(destimgpath,quality=95)file_name,file_extend = os.path.splitext(destimgpath)if not file_extend=='.jpg':file_extend = '.jpg'os.rename(destimgpath,file_name+file_extend)执行是要 os.chdir('/path/') 其中 /path下就是VOCdevkit
接着对数据集质量进行判断:
import os
import shutil
import numpy as np
import pandas as pd
from tqdm import tqdm
import matplotlib.pyplot as pltfrom collections import defaultdict
import xml.etree.ElementTree as ET
def check(year='VOC2007',show=False):"""输入数据文件名,返回有图没标注文件和有标注文件没图的数据路径"""################################################################################################################################本节代码检查只有图或只有标注文件的情况#################################################################################################################################################data_path=os.path.join("VOCdevkit",year)imgs_path = os.path.join(data_path,'JPEGImages')anns_path = os.path.join(data_path,'Annotations')#获取图片文件img_names = set([os.path.splitext(i)[0] for i in os.listdir(imgs_path)])ann_names = set([os.path.splitext(i)[0] for i in os.listdir(anns_path)])print("########################################################################################数据集{}检验结果如下:######################################################################################################".format(year))if not len(img_names):print(' 该数据集没有图片')returnimg_ann = img_names-ann_names #有图没标注文件ann_img = ann_names-img_names #有标注文件没有图if len(img_ann):print(" 有图片没标注文件的图片是:{} 等(只列前50个) 注意检查这些图片是否是背景图片".format({v for k,v in enumerate(img_ann) if k<50}))else:print(" 所有图片都有对应标注文件")if len(ann_img):print(" 有标注文件没有图片的标注文件是:{}(只列前50个)".format({v for k,v in enumerate(ann_img) if k<50}))else:print(" 所有标注文件都有对应图片")############################################################################################################本节代码对于上节检查结果有问题的图片和标注文件统一移动到结果文件夹中进行下一步查看 #######################################################################################################################result_path = os.path.join(data_path,year+'_result')if os.path.exists(result_path):print(' 结果文件{}已经存在,请检查'.format(result_path))if len(ann_img)+len(img_ann):# 把只有图或只有标注文件的数据集全部移出来if (not os.path.exists(result_path)):os.makedirs(result_path)else:print(' 存在有图无标注或有标注无图的文件,另结果文件{}已经存在,请检查'.format(result_path))# return img_anns = [os.path.join(imgs_path,i+'.jpg') for i in img_ann]ann_imgs = [os.path.join(anns_path,i+'.xml') for i in ann_img]if len(img_anns):for img in img_anns:shutil.move(img,result_path)print(' 移动只有图无标注文件完成')if len(ann_img):for ann in ann_imgs:shutil.move(ann,result_path)print(' 移动只有标注文件无图完成')#############################################################################################################本节内容提取分类文件夹标注文件夹中所有的分类类别,这个部分由于数据可能是#################################多个人标的,所在对于使用数据的人还是要看一下分类的,很有必要 #######################ann_names_new = [os.path.join(anns_path,i) for i in os.listdir(anns_path)]#得新获取经过检查处理的标注文件total_images_num = len(ann_names_new)classes=list() #用来存放所有的标注框的分类名称img_boxes = list() #用来存放单张图片的框的个数hw_percents = list() #用来存放图像的高宽比,因为图像是要进行resize的,所以可能会有resize和scaled resize区分num_imgs = defaultdict(int) # 存放每个分类有多少张图片出现num_boxes = dict() # 存放每个分类有多少个框出现h_imgs = list() # 存放每张图的高w_imgs = list() # 存放每张图的宽area_imgs = list() #存放每张图的面积h_boxes = defaultdict(list) #存放每个分类框的高w_boxes = defaultdict(list) #存放每个分类框的宽area_boxes = defaultdict(list) #存放每个分类框的面积area_percents = defaultdict(list) #存放每个分类框与图像面积的百分比for ann in tqdm(ann_names_new):try:in_file=open(ann)tree=ET.parse(in_file)except:print("打开标注文件失败:",ann)root =tree.getroot()size = root.find('size')# print image_idw = int(size.find('width').text)h = int(size.find('height').text)img_area = w * hif img_area< 100:print(f"有标注文件{ann}无图片尺寸,将被处理")shutil.move(ann,result_path)im_path=os.path.join(ann.split(os.sep)[0],ann.split(os.sep)[1],'JPEGImages',os.path.splitext(ann)[0].split(os.sep)[-1]+'.jpg')shutil.move(im_path,result_path)continueimg_boxes.append(len(root.findall('object')))if not len(root.findall('object')):print(f"有标注文件{ann}但没有标注框,将被处理")shutil.move(ann,result_path)i_path=os.path.join(ann.split(os.sep)[0],ann.split(os.sep)[1],'JPEGImages',os.path.splitext(ann)[0].split(os.sep)[-1]+'.jpg')shutil.move(i_path,result_path)continueimg_classes=[]ok_flag=Truefor obj in root.iter('object'):difficult = obj.find('difficult').textcls_name = obj.find('name').text if isinstance(cls_name,type(None)) :print(f"标注框类名有问题,标注文件将被处理,类名:{cls_name},标注文件:{ann}")shutil.move(ann,result_path) ok_flag=Falsecontinueelif isinstance(cls_name,str) and len(cls_name)<2: ok_flag=False print(f"标注框类名有问题,标注文件将被处理,类名:{cls_name},标注文件:{ann}") shutil.move(ann,result_path) continue else:pass# if int(difficult) == 1:# continuexmlbox = obj.find('bndbox')b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text)) #左,右,上,下if int(b[1]-b[0])==0 or int(b[3]-b[2])==0:ok_flag=Falseprint(f"有零存在,框为点或直线,将被处理,边框:{b},标注文件:{ann},类名称:{cls_name}")shutil.move(ann,result_path)box_area = (b[1]-b[0])*(b[3]-b[2])area_percent = round(np.sqrt(box_area/float(img_area)),3)*100hw_percents.append(float(h/w))if not (cls_name in classes):classes.append(cls_name)img_classes.append(cls_name)num_boxes[cls_name]= num_boxes.get(cls_name,0)+1h_boxes[cls_name].append(int(b[3]-b[2]))w_boxes[cls_name].append(int(b[1]-b[0]))area_boxes[cls_name].append(int(box_area))area_percents[cls_name].append(area_percent)if ok_flag:h_imgs.append(h)w_imgs.append(w)area_imgs.append(img_area)for img_cls_name in set(img_classes):num_imgs[img_cls_name] = num_imgs.get(img_cls_name,0)+1classes=sorted(classes)print(f"数据集{year}一共有{total_images_num}张合格的标注图片,{sum(img_boxes)}个标注框,平均每张图有{round(sum(img_boxes)/total_images_num,2)}个标注框;一共有{len(classes)}个分类,分别是{classes};图片中标注框个数最少是{min(img_boxes)}, \最多是{max(img_boxes)}.图片高度最小值是{min(h_imgs)},最大值是{max(h_imgs)};图片宽度最小值是{min(w_imgs)},最大值是{max(w_imgs)}; \图片面积最小值是{min(area_imgs)},最大值是{max(area_imgs)} ;图片高宽比最小值是{round(min(hw_percents),2)},图片高宽比最大值是{round(max(hw_percents),2)}")num_imgs_class = [num_imgs[class_name] for class_name in classes] num_boxes_class = [num_boxes[class_name] for class_name in classes] #各分类的标注框个数min_h_boxes = [min(h_boxes[class_name]) for class_name in classes] #各分类标注框高度最小值max_h_boxes = [max(h_boxes[class_name]) for class_name in classes] #各分类标注框高度最大值min_w_boxes = [min(w_boxes[class_name]) for class_name in classes] #各分类标注框宽度最小值max_w_boxes = [max(w_boxes[class_name]) for class_name in classes] #各分类标注框宽度最大值min_area_boxes = [min(area_boxes[class_name]) for class_name in classes] #各分类标注框面积最小值max_area_boxes = [max(area_boxes[class_name]) for class_name in classes] #各分类标注框面积最大值min_area_percents = [min(area_percents[class_name]) for class_name in classes] #各分类标注框面积与图像面积比最小值max_area_percents = [max(area_percents[class_name]) for class_name in classes] #各分类标注框面积与图像面积比最大值result = {'cls_names':classes,'images':num_imgs_class,'objects':num_boxes_class,'min_h_bbox':min_h_boxes,'max_h_bbox':max_h_boxes,'min_w_bbox':min_w_boxes, 'max_w_bbox':max_w_boxes,'min_area_bbox':min_area_boxes,'max_area_bbox':max_area_boxes,'min_area_box/img':min_area_percents,'max_area_box/img':max_area_percents}#显示所有列(参数设置为None代表显示所有行,也可以自行设置数字)pd.set_option('display.max_columns',None)#显示所有行pd.set_option('display.max_rows',None)#设置数据的显示长度,默认为50pd.set_option('max_colwidth',50)#禁止自动换行(设置为Flase不自动换行,True反之)pd.set_option('expand_frame_repr', False)result_df = pd.DataFrame(result)print(result_df)# plt.figure(figsize=(10.8,6.4))# result_df.iloc[:,1:3].plot(kind='bar',)if show:##############################################画各个类别图片数与框数的直方图############################################################plt.figure(figsize=(15,6.4))x1 = [i+4*i for i in range(len(classes))]x2 = [i+2 for i in x1]y1= [int(num_boxes[cl]) for cl in classes]y2 = [int(num_imgs[cl]) for cl in classes]lb1=["" for i in x1]lb2=classesplt.bar(x1,y1,alpha=0.7,width=2,color='b',label='objects',tick_label=lb1)plt.bar(x2,y2,alpha=0.7,width=2,color='r',label='images',tick_label=lb2)plt.xticks(rotation=45)# plt.axis('off')plt.legend()#plt.savefig##############################################画单张图标注框数量的直方图#################################################################接着用直方图把这些结果画出来plt.figure(figsize=(15,6.4))# 定义组数,默认60# 定义一个间隔大小a = 1# 得出组数group_num= int((max(img_boxes) - min(img_boxes)) / a)n,bins,patches=plt.hist(x=img_boxes,bins=group_num,color='c',edgecolor='red',density=False,rwidth=0.8)for k in range(len(n)):plt.text(bins[k], n[k]*1.02, int(n[k]), fontsize=12, horizontalalignment="center") #打标签,在合适的位置标注每个直方图上面样本数# 组距distance=int((max(img_boxes)-min(img_boxes)) /group_num)if distance<1:distance=1plt.xticks(range(min(img_boxes),max(img_boxes)+2,distance),fontsize=8)# 辅助显示设置plt.xlabel('number of bbox in each image')plt.ylabel('image numbers')plt.xticks(rotation=45)plt.title(f"The number of bbox min:{round(np.min(img_boxes),2)},max:{round(np.max(img_boxes),2)} \n mean:{round(np.mean(img_boxes),2)} std:{round(np.std(img_boxes),2)}")plt.grid(True)plt.tight_layout()##############################################画单张图高宽比的直方图################################################################plt.figure(figsize=(15,6.4))# 定义组数,默认60a = 0.1# 得出组数group_num= int((max(hw_percents) - min(hw_percents)) / a)n,bins,patches=plt.hist(x=hw_percents,bins=group_num,color='c',edgecolor='red',density=False,rwidth=0.8)for k in range(len(n)):plt.text(bins[k], n[k]*1.02, int(n[k]), fontsize=12, horizontalalignment="center") #打标签,在合适的位置标注每个直方图上面样本数# 组距distance=int((max(hw_percents)-min(hw_percents)) /group_num)if distance<1:distance=1plt.xticks(range(int(min(hw_percents)),int(max(hw_percents))+2,distance),fontsize=8)# 辅助显示设置plt.xlabel('image height/width in each image')plt.ylabel('image numbers')plt.xticks(rotation=45)plt.title(f"image height/width min:{round(np.min(hw_percents))},max:{round(np.max(hw_percents),2)} \n mean:{round(np.mean(hw_percents),2)} std:{round(np.std(hw_percents),2)}")plt.grid(True)plt.tight_layout()##############################################画各个分类框图面积比直方图################################################################plt.figure(figsize=(8*3,8*round(len(classes)/3)))for i,name in enumerate(classes):plt.subplot(int(np.ceil(len(classes)/3)),3,i+1)# 定义组数,默认60a = 5# 得出组数group_num= int((max(area_percents[name]) - min(area_percents[name])) / a)n,bins,patches=plt.hist(x=area_percents[name],bins=group_num,color='c',edgecolor='red',density=False,rwidth=0.8)for k in range(len(n)):plt.text(bins[k], n[k]*1.02, int(n[k]), fontsize=12, horizontalalignment="center") #打标签,在合适的位置标注每个直方图上面样本数# 组距distance=int((max(area_percents[name])-min(area_percents[name])) /group_num)if distance<1:distance=1plt.xticks(range(int(min(area_percents[name])),int(max(area_percents[name]))+2,distance),fontsize=8)# 辅助显示设置plt.xlabel('area percent bbox/img')plt.ylabel('boxes numbers')plt.xticks(rotation=45)plt.title(f"id {i+1} class {name} area percent min:{round(np.min(area_percents[name]),2)},max:{round(np.max(area_percents[name]),2)} \n mean:{round(np.mean(area_percents[name]),2)} std:{round(np.std(area_percents[name]),2)}")plt.grid(True)plt.tight_layout()同样,执行是要 os.chdir('/path/') 其中 /path下就是VOCdevkit
2.2 划分训练和验证集
接下来,对各个文件夹划分训练和验证集参见博客。
import os
def create_train_val(dataset="输入数据集名称",percent=0.9):# wd = os.getcwd()nameset = os.path.split(dataset)[-1]img_path = os.path.join(dataset,"JPEGImages")img_files = os.listdir(img_path)split = int(len(img_files) * percent)train_img_files,val_img_files = img_files[:split],img_files[split:]with open(os.path.join(dataset,'train.txt'),'w') as f1:for img_file in train_img_files:name = img_file.split('.')[0]text = f"{nameset}/JPEGImages/{name}.jpg {nameset}/Annotations/{name}.xml\n"f1.write(text)print('train.txt done')with open(os.path.join(dataset,'valid.txt'),'w') as f2:for img_file in val_img_files:name = img_file.split('.')[0]text = f"{nameset}/JPEGImages/{name}.jpg {nameset}/Annotations/{name}.xml\n"f2.write(text)print('valid.txt done')
执行是可以这样:
create_train_val('/path/VOCdevkit/d1')
结果是:
d1
├── Annotations
├── JPEGImages
├── train.txt
└── valid.txt2 directories, 2 filestrain.txt:./d1/JPEGImages/a5.jpg ./d1/Annotations/a5.xml,也就是说再加上/path/VOCdevkit就是图片和标注文件的绝对路径。valid.txt同理。
2.3 获取标注类别
这个类别我们理论上是知道的,因我们是自己标注的,有自己的任务,但这里的标注类别统计是从标注文件中获取。获取后,按照类别首字母从小到大排列。也可以通过查看标注结果的类别名称来判断是否是我们相要的分类。
def get_names(dataset='vechcle'):"""输入数据文件名,返回有图没标注文件和有标注文件没图的数据路径"""################################################################################################################################本节代码检查只有图或只有标注文件的情况#################################################################################################################################################anns_path = os.path.join(dataset,'Annotations')ann_names = [os.path.join(anns_path,i) for i in os.listdir(anns_path)]#得新获取经过检查处理的标注文件classes=list() #用来存放所有的标注框的分类名称for ann in tqdm(ann_names):in_file=open(ann)tree=ET.parse(in_file) root =tree.getroot() for obj in root.iter('object'):cls_name = obj.find('name').text if not (cls_name in classes):classes.append(cls_name)classes = sorted(classes)classes = [cla+'\n' for cla in classes[:-1]] + [classes[-1]]with open(os.path.join(dataset,'label_list.txt'),'w') as f:f.writelines(classes)
执行方式与划分训练集和验证集相似。
get_names('/path/VOCdevdit/d1')
结果是:
d1
├── Annotations
├── JPEGImages
├── label_list.txt
├── train.txt
└── valid.txt2 directories, 3 files
其中就是label_list.txt
2.4 整合所有文件的训练、验证及训练名称
把各个文件的train.txt valid.txt label_list.txt合成一个就行
import os
def merge_data(dirs,save_dir):"""_summary_Args:dirs (_type_): [d1,l0,l1...]save_dir (_type_): /path/VOCdevkit"""all_train_file=[]all_valid_file=[]all_label_file=[]for d in dirs:all_train_file.append(os.path.join(save_dir,d,'train.txt'))all_valid_file.append(os.path.join(save_dir,d,'valid.txt'))all_label_file.append(os.path.join(save_dir,d,'label_list.txt'))with open(os.path.join(save_dir,'train.txt'),'w') as f:for train_file in all_train_file:with open(train_file,'r') as f1:lines = f1.readlines()f.writelines(lines)with open(os.path.join(save_dir,'valid.txt'),'w') as f:for valid_file in all_valid_file:with open(valid_file,'r') as f1:lines = f1.readlines()f.writelines(lines)with open(os.path.join(save_dir,'label_list.txt'),'w') as f:all_lines = []for label_file in all_label_file:with open(label_file,'r') as f1:lines = f1.readlines()all_lines.extend(lines)all_lines=set(all_lines)f.writelines(all_lines)print('done!')
可以这样执行:
merge_data(['d1','l0','l1','l2','l3','l4'],'/path/VOCdevkit')
结果为:
.
├── d1
├── l0
├── l1
├── l2
├── l3
├── l4
├── label_list.txt
├── train.txt
└── valid.txt6 directories, 3 files
3 开始模型训练
数据准备是最花费时间的。数据准备好之后就可以进行训练了。
PaddleDetection/configs/picodet/README.md下有相关picodet的说明。参照
PicoDet-L640*64042.659.25.8016.8162.5ms108.1msmodel | logconfigw/ 后处理 | w/o 后处理
下载预训练模型,放到pretrained_model/picodet_l_640_lcnet.pdparams中,配置文件是 configs/picodet/picodet_l_640_coco_lcnet.yml
3.1 准备数据配置文件
复制 configs/picodet/picodet_l_640_coco_lcnet.yml configs/picodet/picodet_l_640_voc_lcnet_my.yml,这个是主配置文件,复制configs/datasets/voc.yml 到configs/datasets/voc_my.yml,这个是数据相关配置文件。
voc_my.yam 修改3,7,8,9,14,15,16,21行,主要修改num_classes,dataset_dir,anno_path,label_list
修改前后对比:
voc.yml:
metric: VOC
map_type: 11point
num_classes: 20TrainDataset:!VOCDataSetdataset_dir: dataset/vocanno_path: trainval.txtlabel_list: label_list.txtdata_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']EvalDataset:!VOCDataSetdataset_dir: dataset/vocanno_path: test.txtlabel_list: label_list.txtdata_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']TestDataset:!ImageFolderanno_path: dataset/voc/label_list.txtvoc_my.yml:
metric: VOC
map_type: 11point
num_classes: 5 #改成自己的分类数TrainDataset:!VOCDataSetdataset_dir: /path/VOCdevkit # 改anno_path: train.txt # /path/VOCdevkit/train.txtlabel_list: label_list.txt #改,/path/VOCdevkit/label_list.txtdata_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']EvalDataset:!VOCDataSetdataset_dir: /path/VOCdevkit #改anno_path: valid.txt #改 /path/VOCdevkit/valid.txtlabel_list: label_list.txt #改,/path/VOCdevkit/label_list.txtdata_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']TestDataset:!ImageFolderanno_path: /path/VOCdevkit/label_list.txt #改,/path/VOCdevkit/label_list.txt 标签文件的绝对路径
3.2 对运行时文件进行修改
改之前configs/runtime.yml:
use_gpu: true #是否使用GPU训练
use_xpu: false #是否使用XPU训练
log_iter: 20 #显示训练信息的迭代间隔
save_dir: output #模型保存位置
snapshot_epoch: 1 #模型保存间隔
print_flops: false# Exporting the model #这个是与导出模型有关
export:post_process: True # Whether post-processing is included in the network when export model.nms: True # Whether NMS is included in the network when export model.benchmark: False # It is used to testing model performance, if set `True`, post-process and NMS will not be exported.这里基本上不用做修改
3.3 模型网络参数picodet_v2.yml
这部分也是不用改的,需要改的部分己经在 configs/picodet/picodet_l_640_voc_lcnet_my.yml 主配置文件中做了覆盖。
3.4 训练优化参数optimizer_300e.yml
修改前configs/picodet/base/optimizer_300e.yml:
epoch: 300LearningRate:base_lr: 0.32schedulers:- !CosineDecaymax_epochs: 300- !LinearWarmupstart_factor: 0.1steps: 300OptimizerBuilder:optimizer:momentum: 0.9type: Momentumregularizer:factor: 0.00004type: L2主要是关于学习率和优化器的配置,其中学习率已经在主配置文件做了修改。学习率这个可以尝试的设。
3.5 数据读取器配置picodet_640_reader.yml
改前内容configs/picodet/base/picodet_640_reader.yml:
worker_num: 6
eval_height: &eval_height 640
eval_width: &eval_width 640
eval_size: &eval_size [*eval_height, *eval_width]TrainReader:sample_transforms:- Decode: {}- RandomCrop: {}- RandomFlip: {prob: 0.5}- RandomDistort: {}batch_transforms:- BatchRandomResize: {target_size: [576, 608, 640, 672, 704], random_size: True, random_interp: True, keep_ratio: False}- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}- Permute: {}- PadGT: {}batch_size: 32shuffle: truedrop_last: trueEvalReader:sample_transforms:- Decode: {}- Resize: {interp: 2, target_size: *eval_size, keep_ratio: False}- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}- Permute: {}batch_transforms:- PadBatch: {pad_to_stride: 32}batch_size: 8shuffle: falseTestReader:inputs_def:image_shape: [1, 3, *eval_height, *eval_width]sample_transforms:- Decode: {}- Resize: {interp: 2, target_size: *eval_size, keep_ratio: False}- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}- Permute: {}batch_size: 1主要配置训练、验证、测试时数据集的配置,对于训练,重要的是:
sample_transforms/batch_transforsms:是数据增强算子,分别用于单样本和批量的数据
batch_size: 数据读取的大小
worker_num:并发加载子进程数对于数据增强的方法,可以去源码中找,如增加图片裁剪和颜色扰动
sample_transforms:- Decode: {}- RandomCrop: {}- RandomFlip: {prob: 0.5}- RandomDistort: {}- CropImage: {}- ColorDistort: {}
其它增强方式可参考 PaddleDetection/docs/advanced_tutorials.md
3.6 主配置文件修改
主配置文件中设置的参数会覆盖掉子配置文件相关参数,所以子配置文件可以保留不变,想要修改直接在主配置文件中修改,这样避免要修改的地方太分散。
改前config/picodet/picodet_l_640_coco_lcnet.yml:
_BASE_: ['../datasets/coco_detection.yml','../runtime.yml','_base_/picodet_v2.yml','_base_/optimizer_300e.yml','_base_/picodet_640_reader.yml',
]pretrain_weights: https://paddle-imagenet-models-name.bj.bcebos.com/dygraph/legendary_models/PPLCNet_x2_0_pretrained.pdparams
weights: output/picodet_l_320_coco/best_model
find_unused_parameters: True
use_ema: true
epoch: 200
snapshot_epoch: 10LCNet:scale: 2.0feature_maps: [3, 4, 5]LCPAN:out_channels: 160PicoHeadV2:conv_feat:name: PicoFeatfeat_in: 160feat_out: 160num_convs: 4num_fpn_stride: 4norm_type: bnshare_cls_reg: Trueuse_se: Truefeat_in_chan: 160LearningRate:base_lr: 0.06schedulers:- !CosineDecaymax_epochs: 300- !LinearWarmupstart_factor: 0.1steps: 300TrainReader:batch_size: 12改后:configs/picodet/picodet_l_640_voc_lcnet_my.yml
_BASE_: ['../datasets/voc_my.yml', # 改成VOC读取方式'../runtime.yml','_base_/picodet_v2.yml','_base_/optimizer_300e.yml','_base_/picodet_640_reader.yml',
]pretrain_weights: pretrained_model/picodet_l_640_coco_lcnet.pdparams #改成我们下载的预训练模型
weights: output/picodet_l_640_voc_my/model_best # 模型评估和推理时使用的模型
find_unused_parameters: True
use_ema: true
epoch: 300 #改总共要训300个epoch
snapshot_epoch: 10 #可改可不改,10个epoch保存一个模型LCNet:scale: 2.0feature_maps: [3, 4, 5]LCPAN:out_channels: 160PicoHeadV2:conv_feat:name: PicoFeatfeat_in: 160feat_out: 160num_convs: 4num_fpn_stride: 4norm_type: bnshare_cls_reg: Trueuse_se: Truefeat_in_chan: 160LearningRate:base_lr: 0.015 #改,官方用四个显卡,我们用1个,学习率改为1/4schedulers:- !CosineDecaymax_epochs: 300- !LinearWarmupstart_factor: 0.1steps: 300TrainReader:batch_size: 12 #可改可不改,根据gpu显存大小来设置即可,表示一次推理所用的图片数,如果是多卡,会分散到各个卡上,所以batch_size要能被GPU整除3.7 GPU训练
单GPU训练
export CUDA_VISIBLE_DEVICES=0
python tools/train.py -c configs/picodet/picodet_l_640_voc_lcnet_my.yml --eval
多GPU训练
export CUDA_VISIBLE_DEVICES=0,1,2,3
python -m paddle.distributed.launch --gpus 0,1,2,3 tools/train.py -c configs/picodet/picodet_l_640_voc_lcnet_my.yml --eval
如果相要可视化训练过程可以加入以下命令
--use_vdl=True --vdl_log_dir=./output
4 模型评估
更多的关于目标检测的评价指标可以看本文开头推荐的链接,及更多指标请查看知乎文档
export CUDA_VISIBLE_DEVICES=0
python tools/eval.py -c configs/picodet/picodet_l_640_voc_lcnet_my.yml -o weights=output/picodet_l_640_voc_lcnet_my/best_model.pdparams
输出的结果类似是这样:
[07/06 10:08:52] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 71.69%
[07/06 10:08:52] ppdet.engine INFO: Total sample number: 5237, averge FPS: 51.81244804206111
要获复每个类别的结果:
python tools/eval.py -c configs/picodet/picodet_l_640_voc_lcnet_my.yml -o weights=output/picodet_l_640_voc_lcnet_my/best_model.pdparams --classwise
会列出每个分类的AP值,样子大概是这样:
[07/06 10:22:12] ppdet.metrics.map_utils INFO: Per-category of VOC AP:
+----------+-------+
| category | AP |
+----------+-------+
| screen | 0.717 |
+----------+-------+
[07/06 10:22:12] ppdet.metrics.map_utils INFO: per-category PR curve has output to voc_pr_curve folder.
[07/06 10:22:12] ppdet.metrics.metrics INFO: mAP(0.50, 11point) = 71.69%
[07/06 10:22:12] ppdet.engine INFO: Total sample number: 5237, averge FPS: 52.107162396101515
输出以上结果,同时会在voc_pr_curve下生成每个分类的PR曲线。由于数据格式是VOC所以无法输出COCO的格式。
5 模型推理
# 推理单张图片
CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/picodet/picodet_l_640_voc_lcnet_my.yml -o weights=output/picodet_l_640_voc_lcnet_my/best_model.pdparams --infer_img=a.jpg # 推理文件中的所有图片
CUDA_VISIBLE_DEVICES=0 python tools/infer.py -c configs/picodet/picodet_l_640_voc_lcnet_my.yml -o weights=output/picodet_l_640_voc_lcnet_my/best_model.pdparams --infer_dir=/path/demo
有几个可以加的参数:
--draw_threshold=0.5 # 结果画框只画大于该阈值的框
--output_dir='output' # 指定画框后结果保存位置
遇到一个报错:–save_results=True报错,可能是bug,本意是想把预测的结果保存到文件。
6 模型导出
训练保存的模型包含前向和后向推理相关的优化器、模型结构等配置,但在实际落地只需要做前向推理,更多的参看REAMEM,关于导出tensorrt的。
python tools/export_model.py -c configs/picodet/picodet_l_640_voc_lcnet_my.yml -o weights=output/picodet_l_640_voc_lcnet_my/best_model.pdparams --output_dir=inference_model
–output_dir指定模型保存位置,内容如下:
inference_model/
└── picodet_l_640_voc_lcnet_my├── infer_cfg.yml├── model.pdiparams├── model.pdiparams.info└── model.pdmodel1 directory, 4 files这时的模型中是包括后处理的,模型相关配置在infer_cfg.yml中:
mode: paddle
draw_threshold: 0.5
metric: VOC
use_dynamic_shape: false
arch: GFL
min_subgraph_size: 3
Preprocess:
- interp: 2keep_ratio: falsetarget_size:- 640- 640type: Resize
- is_scale: truemean:- 0.485- 0.456- 0.406std:- 0.229- 0.224- 0.225type: NormalizeImage
- type: Permute
label_list:
- screen
NMS:keep_top_k: 100name: MultiClassNMSnms_threshold: 0.5nms_top_k: 1000score_threshold: 0.3
fpn_stride:
- 8
- 16
- 32
- 64对于是否包括后处理到模型中 可以修改runtime.yml 或-o export.postprocess=False export.nms=False,两个中选择。
7 导出后模型推理
python deploy/python/infer.py --model_dir=inference_model/picodet_l_640_voc_lcnet_my --image_file=/path/a.jpg --device=GPU
输出是:
----------- Running Arguments -----------
action_file: None
batch_size: 1
camera_id: -1
cpu_threads: 1
device: GPU
enable_mkldnn: False
enable_mkldnn_bfloat16: False
image_dir: None
image_file: 1512005712438366208.jpeg
model_dir: inference_model/picodet_l_640_voc_lcnet_my
output_dir: infer_result
random_pad: False
reid_batch_size: 50
reid_model_dir: None
run_benchmark: False
run_mode: paddle
save_images: False
save_mot_txt_per_img: False
save_mot_txts: False
save_results: False
scaled: False
threshold: 0.5
tracker_config: None
trt_calib_mode: False
trt_max_shape: 1280
trt_min_shape: 1
trt_opt_shape: 640
use_dark: True
use_gpu: False
video_file: None
window_size: 50
------------------------------------------
----------- Model Configuration -----------
Model Arch: GFL
Transform Order:
--transform op: Resize
--transform op: NormalizeImage
--transform op: Permute
--------------------------------------------
class_id:0, confidence:0.9052, left_top:[218.28,133.36],right_bottom:[255.10,199.04]
class_id:0, confidence:0.8979, left_top:[196.59,132.87],right_bottom:[236.89,197.48]
class_id:0, confidence:0.8768, left_top:[88.77,126.61],right_bottom:[126.54,198.21]
class_id:0, confidence:0.8680, left_top:[67.65,125.99],right_bottom:[108.40,196.04]
save result to: infer_result/1512005712438366208.jpeg
Test iter 0
------------------ Inference Time Info ----------------------
total_time(ms): 1727.4, img_num: 1
average latency time(ms): 1727.40, QPS: 0.578905
preprocess_time(ms): 1139.00, inference_time(ms): 588.40, postprocess_time(ms): 0.00
有些参数可以设定 --output_dir=/savepath 可以指定推理结果的保存位置,更多参数配置请看deploy/python/README.md。要保存结果,可以–save_results=True。
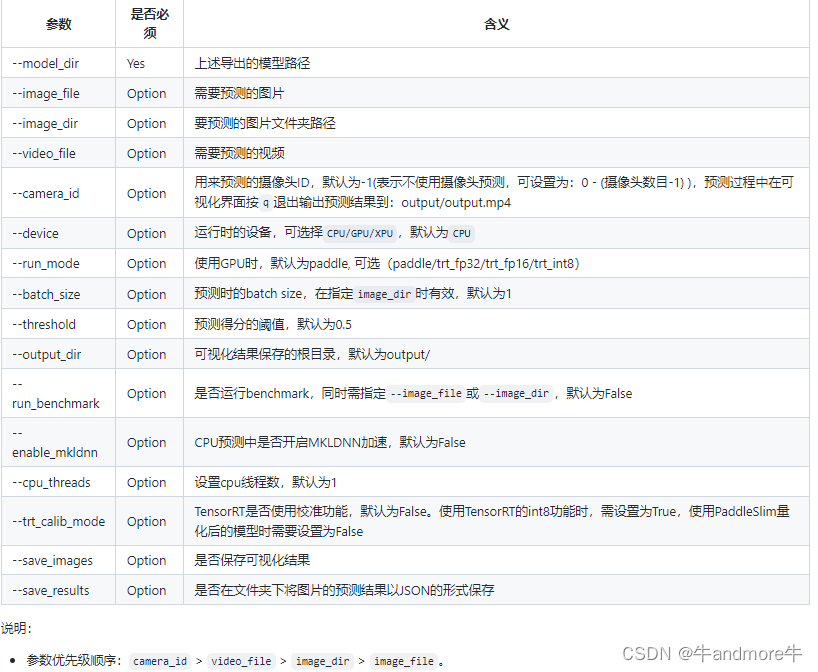
模测结果在与结果图在同一位置,results.json,内容是:
[{"image_file": "1512005712438366208.jpeg", "bbox": [218.27879333496094, 133.3578338623047, 36.81669616699219, 65.68455505371094], "score": 0.9051915407180786, "category_id": 0}, {"image_file": "1512005712438366208.jpeg", "bbox": [196.58615112304688, 132.8676300048828, 40.30314636230469, 64.61126708984375], "score": 0.8978725671768188, "category_id": 0}]
无阈值限制,所有结果都会保存;坐标是(xmin,ymin,width,height),也会有–threshold这个参数来做限制,但只会在画框时用到,保存的整个json文件是所有框都有保存的。
对于我们常规的工作,硬件的选gpu和cpu,gpu没什么说的,用cpu时,可以选用enable_mkdnn和cpu_threads,我都试过,速度很快。
有一点要说,就是我们往往用训练的新的模型来反过来标新的数据,https://blog.csdn.net/u011119817/article/details/125665410 这个博文中把检测结果json转voc xml时,设置了阈值,这就决定要把那些结果用做标注,所以设置阈值可以放到这个环节
这一部分很有用,我们训练模型往往就是需要最终的检测结果。
paddledetection2.6最近json文件保存结果变了,是一个列表内容为:
[{"image_id":0,"category_id": 0,"file_name": "1512005712438366208.jpeg", "bbox": [218.27879333496094, 133.3578338623047, 36.81669616699219, 65.68455505371094], "score": 0.9051915407180786, }, {{"image_id":0,"category_id": 0,"file_name": "1512005712438366208.jpeg", "bbox": [196.58615112304688, 132.8676300048828, 40.30314636230469, 64.61126708984375], "score": 0.8978725671768188}]
相比之前的,多了一个image_id,image_file变成了file_name,由原来图片的绝对路径变成一个文件名。
8 小目标检测推理
本小节是2023年4月新加,使用paddledetection2.6版本,该版本加入了小目标检测和旋转框检测功能。在模型训练环节是一样的,我用picodet xs训练一个乒乓球检测的模型。下面加上使用小目标和不使用小目标推理的命令,当然,结果类型是一样的。
python tools/infer.py -c configs/picodet/picodet_xs_320_voc_256_20230405.yml -o weights=output/picodet_xs_320_voc_256_20230405/best_model.pdparams --infer_dir=test_images --draw_threshold=0.4 --save_results=True --output_dir=test_images_not_slice
python tools/infer.py -c configs/picodet/picodet_xs_320_voc_256_20230405.yml -o weights=output/picodet_xs_320_voc_256_20230405/best_model.pdparams --infer_dir=test_images --draw_threshold=0.4 --save_results=True --output_dir=test_images_slice --slice_infer --slice_size 256 256 --overlap_ratio 0.25 0.25 --combine_method nms --match_threshold 0.4 --match_metric ios这个是可以保存结果的,但有个问题保存结果bbox.json是一个字典,keys:bboxs,scores,labels三个都是列表,无其它信息,这没法对应到图片,这是不方便的,比如我要用推理结果,做辅助标注,要能做到infer推理那样。
可以用静态图模型来做这部分推理:
python deploy/python/infer.py --model_dir=inference_model/picodet_xs_256_all_20230405/picodet_xs_320_voc_256_20230405 --image_dir=images_build --device gpu --threshold=0.3 --save_results --save_images=True --output_dir=images_build_slice1 --slice_infer --slice_size 256 256 --overlap_ratio 0.2 0.2 --combine_method nms --match_threshold 0.4 --match_metric ios
其中要说明的是,overlap_ration 越大,滑窗也就越密集,推理越耗时,当为0时,可以对于大图做一遍最少的滑窗来解决。结果的json同7中的一样,可以转成其它格式。
9 后记
更多关于模型转换paddlelite,tensorrt,onnx及部署还有量化,稀疏等工作,可以参考configs/picodet/README.md 。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!