hadoop的分布集群和高可用
什么是hadoop?
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问
Hadoop部署
| 主机 | ip |
|---|---|
| server1 | 172.25.26.11 |
| server2 | 172.25.26.12 |
| server3 | 172.25.26.13 |
1.创建hadoop
[root@server1 ~]# useradd -u 800 hadoop
[root@server1 ~]# passwd hadoop
2.切换到hadoop用户,安装jdk
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ ls
hadoop-3.0.3.tar.gz jdk-8u181-linux-x64.tar.gz zookeeper-3.4.9.tar.gz
[hadoop@server1 ~]$ tar zxf jdk-8u181-linux-x64.tar.gz
[hadoop@server1 ~]$ ls
hadoop-3.0.3.tar.gz jdk1.8.0_181 jdk-8u181-linux-x64.tar.gz zookeeper-3.4.9.tar.gz
[hadoop@server1 ~]$ ln -s jdk1.8.0_181 java
[hadoop@server1 ~]$ ls
hadoop-3.0.3.tar.gz jdk1.8.0_181 zookeeper-3.4.9.tar.gz
java jdk-8u181-linux-x64.tar.gz
[hadoop@server1 ~]$ cd java
[hadoop@server1 java]$ ls
bin jre README.html THIRDPARTYLICENSEREADME.txt
COPYRIGHT lib release
include LICENSE src.zip
javafx-src.zip man THIRDPARTYLICENSEREADME-JAVAFX.txt
解压jdk,做软连接。
[hadoop@server1 ~]$ vim .bash_profile
10 PATH=$PATH:$HOME/bin:/home/hadoop/java/bin
[hadoop@server1 ~]$ jps
1054 Jps
修改环境变量。
3.安装配置hadoop
[hadoop@server1 ~]$ tar zxf hadoop-3.0.3.tar.gz
[hadoop@server1 ~]$ cd hadoop-3.0.3/etc/hadoop/
[hadoop@server1 hadoop]$ vim hadoop-env.sh 54 export JAVA_HOME=/home/hadoop/java
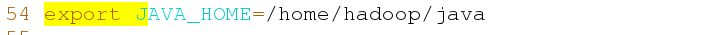
[hadoop@server1 ~]$ cd hadoop-3.0.3
[hadoop@server1 hadoop-3.0.3]$ mkdir input
[hadoop@server1 hadoop-3.0.3]$ cp etc/hadoop/*.xml input/
[hadoop@server1 hadoop-3.0.3]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce \-examples-3.0.3.jar grep input output 'dfs[a-z.]+'

[hadoop@server1 hadoop-3.0.3]$ cd output/
[hadoop@server1 output]$ ls
part-r-00000 _SUCCESS
[hadoop@server1 output]$ cat *
1 dfsadmin
搭建伪分布集群
1.修改配置,配置Hadoop的核心属性
[hadoop@server1 hadoop-3.0.3]$ cd etc/hadoop/
[hadoop@server1 hadoop]$ vim core-site.xml 19 20 21 fs.defaultFS 22 hdfs://172.25.26.11:9000 23 24

[hadoop@server1 hadoop]$ vim hdfs-site.xml19 20 21 dfs.replication 22 1 23 24

2.设置免密登陆
[hadoop@server1 hadoop]$ ssh-keygen
[hadoop@server1 hadoop]$ ssh-copy-id 172.25.26.11

发送密钥。
4.启动hdf,格式化名称节点
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop-3.0.3/etc/hadoop
[hadoop@server1 hadoop]$ vim slaves

[hadoop@server1 hadoop-3.0.3]$ pwd
/home/hadoop/hadoop-3.0.3
[hadoop@server1 hadoop-3.0.3]$ bin/hdfs namenode -format

[hadoop@server1 hadoop-3.0.3]$ sbin/start-dfs.sh
[hadoop@server1 hadoop-3.0.3]$ jps

在浏览器查看:

[hadoop@server1 hadoop-3.0.3]$ bin/hdfs dfs -mkdir /user
[hadoop@server1 hadoop-3.0.3]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@server1 hadoop-3.0.3]$ bin/hdfs dfs -ls /user
[hadoop@server1 hadoop-3.0.3]$ bin/hdfs dfs -put input/
创建目录,将input目录内容上传。

点击utilities,在点击browse file system,查看内容。
[hadoop@server1 hadoop-3.0.3]$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce- \
examples-3.0.3.jar grep input output 'dfs[a-z.]+'
[hadoop@server1 hadoop-3.0.3]$ bin/hdfs dfs -ls
[hadoop@server1 hadoop-3.0.3]$ bin/hdfs dfs -cat output/*
[hadoop@server1 hadoop-3.0.3]$ bin/hdfs dfs -get output
hadoop完全分布式集群部署
server1关闭服务,切换到超级用户

在server1,server2和servre3端安装nfs-utils:
[root@server1 ~]# yum install -y nfs-utils
[root@server1 ~]# vim /etc/exports 1 /home/hadoop *(rw,anonuid=800,anongid=800)

[root@server1 ~]# /etc/init.d/rpcbind start
[root@server1 ~]# /etc/init.d/nfs start

启动服务。
[root@server1 ~]# showmount -e 172.25.26.11

刷新挂载。
在server2和server3:
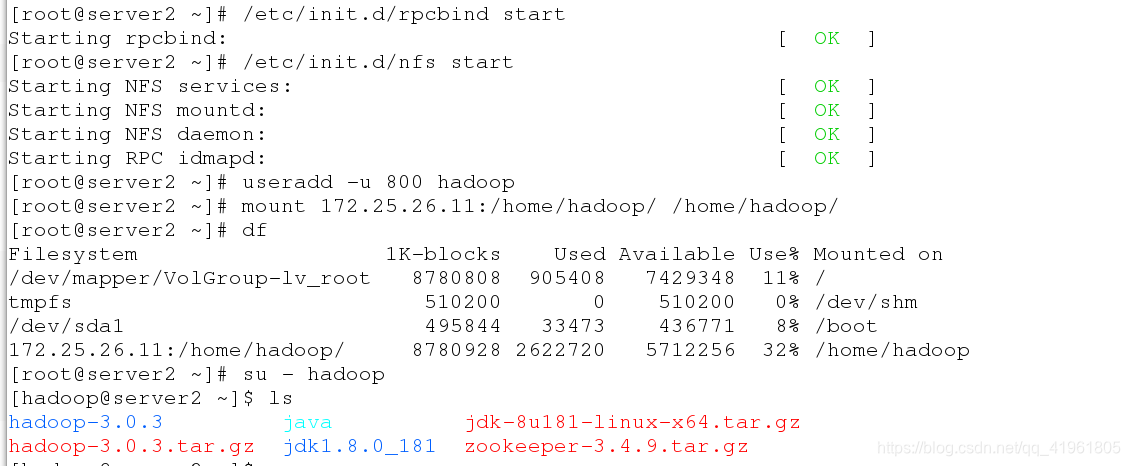
[root@server2 ~]# yum install -y nfs-utils
[root@server2 ~]# /etc/init.d/rpcbind start
[root@server2 ~]# /etc/init.d/nfs start
[root@server2 ~]# useradd -u 800 hadoop
[root@server2 ~]# mount 172.25.26.11:/home/hadoop/ /home/hadoop/
[root@server2 ~]# df
[root@server2 ~]# su - hadoop
[hadoop@server2 ~]$ ls
安装nfs,启动服务,建立hadoop用户,挂载之后发现,server1hadoop用户家目录文件已经同步过来了。
测试:
[hadoop@server1 ~]$ ssh 172.25.26.12

在server1使用hadoop用户进行连接不需要密码。
[hadoop@server1 ~]$ ln -s hadoop-3.03 hadoop
做软链接。
[hadoop@server1 ~]$ cd hadoop/etc/hadoop/
[hadoop@server1 hadoop]$ vim hdfs-site.xml

[hadoop@server1 hadoop]$ vim slaves

设定从设备。
[hadoop@server1 ~]$ cd hadoop
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
初始化,并开启服务。
添加节点
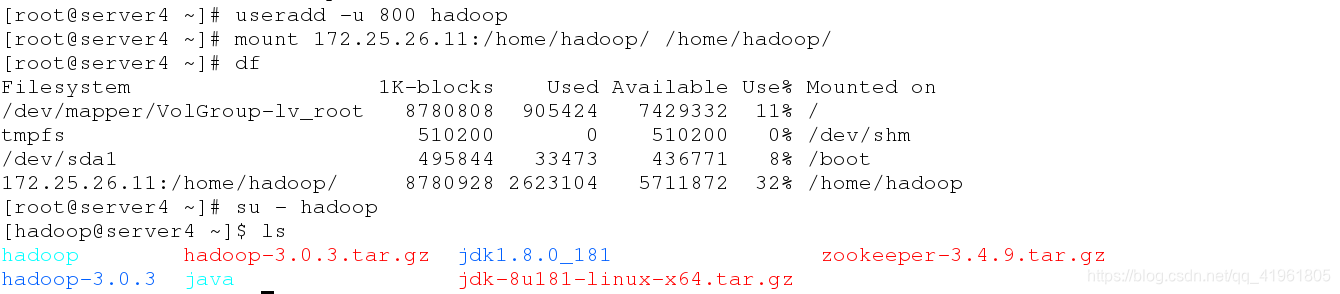
在server4:
[root@server4 ~]# yum install nfs-utils -y
[hadoop@server4 ~]$ cd hadoop/etc/hadoop/[hadoop@server4 hadoop]$ vim slaves

[hadoop@server4 ~]$ cd hadoop[hadoop@server4 hadoop]$ sbin/hadoop-daemon.sh start datanode
开启数据节点
[hadoop@server4 hadoop]$ bin/hdfs dfsadmin -report
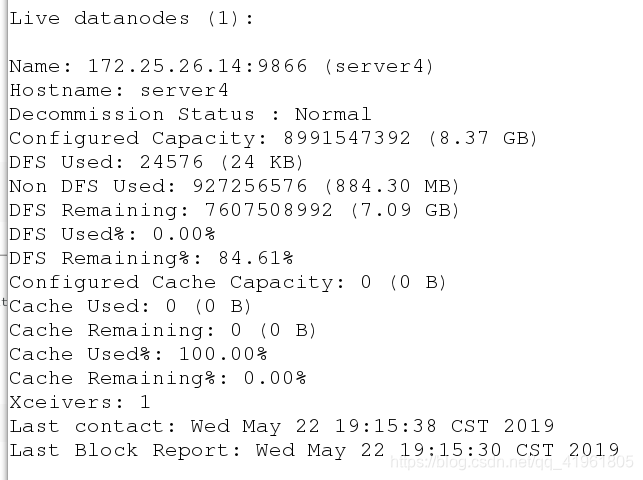
查看添加的节点server4.
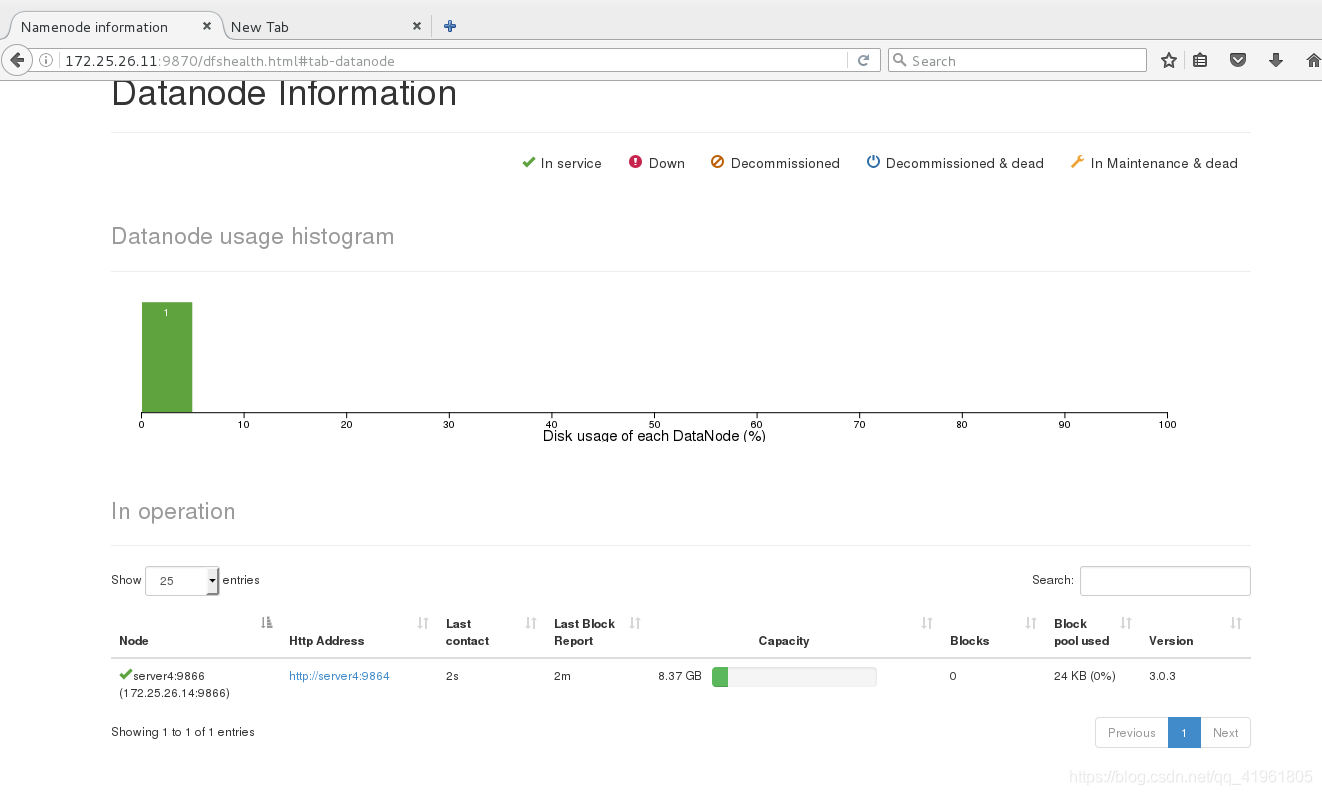
用同样的方法,将server2和server3加入节点。
hadoop+zookeeper高可用集群
hdfs实现高可用:
| 主机 | ip |
|---|---|
| server1 | 172.25.26.11 |
| server2 | 172.25.26.12 |
| server3 | 172.25.26.13 |
| server4 | 172.25.26.14 |
| server5 | 172.25.26.15 |
需要用到5个虚拟机。
[root@server5 ~]# yum install nfs-utils -y
[root@server5 ~]# /etc/init.d/rpcbind start
[root@server5 ~]# /etc/init.d/nfs start
[root@server5 ~]# useradd -u 800 hadoop
[hadoop@server5 ~]$ mount 172.25.26.11:/home/hadoop/ /home/hadoop/
添加用户,开启服务。

和前面一样配置server5,可以正常连接server1的家目录。
在server1进行配置:
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$ tar zxf zookeeper-3.4.9.tar.gz
[hadoop@server1 ~]$ cd zookeeper-3.4.9/conf
[hadoop@server1 conf]$ cp zoo_sample.cfg zoo.cfg
1 tickTime=20002 initLimit=103 syncLimit=54 dataDir=/tmp/zookeeper5 clientPort=21816 server.2=172.25.26.12:2888:38887 server.3=172.25.26.13:2888:38888 server.4=172.25.26.14:2888:3888
修改配置文件,将server2,server3,server4写入集群。因为5台主机都使用nfs文件系统,所以几台主机的配置是一样的。
删除server2上tmp目录的文件,建立zookeeper目录,并创建myid文件,写入一个数字,范围0~255。同样的在server3和server4也进行一样的操作。
在server2,server3,server4节点启动服务:
[hadoop@server4 ~]$ cd zookeeper-3.4.9
[hadoop@server4 zookeeper-3.4.9]$ bin/zkServer.sh start
 在3台主机进行一样的操作,其中会有两台主机的Mode是follower,一台是Leader。
在3台主机进行一样的操作,其中会有两台主机的Mode是follower,一台是Leader。
在server1端进行配置:
[hadoop@server1 ~]$ cd hadoop/etc/hadoop/
[hadoop@server1 hadoop]$ vim core-site.xml
19
20
21 fs.defaultFS
22 hdfs://masters
23
24
25 ha.zookeeper.quorum
26 172.25.26.12:2181,172.25.26.13:2181,172.25.26.14:2181
27
28
[hadoop@server1 hadoop]$ vim hdfs-site.xml
19 20 21 dfs.replication 22 3 23 24 25 dfs.nameservices 26 masters 27 28 29 dfs.ha.namenodes.masters 30 h1,h2 31 32 33 dfs.namenode.rpc-address.masters.h1 34 172.25.26.11:9000 35 36 37 dfs.namenode.http-address.masters.h1 38 172.25.26.11:9870 39 40 41 dfs.namenode.rpc-address.masters.h2 42 172.25.26.15:9000 43 44 45 dfs.namenode.http-address.masters.h2 46 172.25.26.15:9870 47 48 49 dfs.namenode.shared.edits.dir 50 qjournal://172.25.26.12:8485;172.25.26.13:8485;172.25.26.14:8485/masters 51 52 53 dfs.journalnode.edits.dir 54 /tmp/journaldata 55 56 dfs.ha.automatic-failover.enabled 57 true 58 59 60 dfs.client.failover.proxy.provider.masters 61 org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider 62 63 64 dfs.ha.fencing.methods 65 66 sshfence67 shell(/bin/true)68 69 70 71 dfs.ha.fencing.ssh.private-key-files 72 /home/hadoop/.ssh/id_rsa 73 74 75 dfs.ha.fencing.ssh.connect-timeout 76 30000 77 78
[hadoop@server1 hadoop]$ vim slaves

启动hdfs集群:
在三个 DN 上依次启动 zookeeper 集群(即server2,3,4)
[hadoop@server2 zookeeper-3.4.9]$ bin/zkServer.sh start
在三个 DN 上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
[hadoop@server2 ~]$ cd hadoop
[hadoop@server2 hadoop]$ sbin/hadoop-daemon.sh start journalnode
[hadoop@server2 hadoop]$ jps

在server格式话hdfs集群:
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 hadoop]$ scp -r /tmp/hadoop-hadoop 172.25.26.15:/tmp
将文件复制到server5的tmp目录。
格式化 zookeeper (只需在 h1 上执行即可)
[hadoop@server1 hadoop]$ bin/hdfs zkfc -formatZK
[hadoop@server1 hadoop]$ sbin/start-dfs.sh
格式化后启动服务。
查看各个节点状态:
server1:
[hadoop@server1 hadoop]$ jps
12372 Jps
7050 DFSZKFailoverController
12332 NameNode
server2:
[hadoop@server2 hadoop]$ jps
1664 JournalNode
2325 Jps
1535 QuorumPeerMain
2212 DataNode
server3:
[hadoop@server3 hadoop]$ jps
1918 Jps
1651 JournalNode
1755 DataNode
1543 QuorumPeerMain
server4:
[hadoop@server4 hadoop]$ jps
2050 DataNode
1475 QuorumPeerMain
1600 JournalNode
2152 Jps
server5:
[hadoop@server5 dfs]$ jps
1306 DFSZKFailoverController
1511 Jps
1376 NameNode
测试:
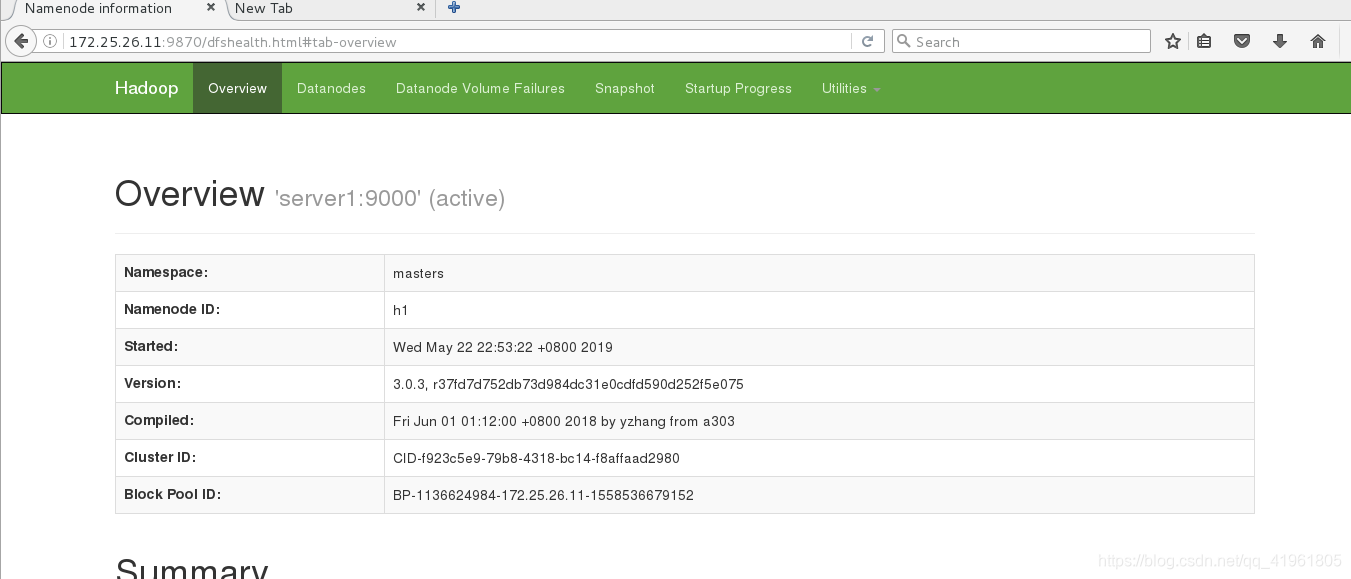
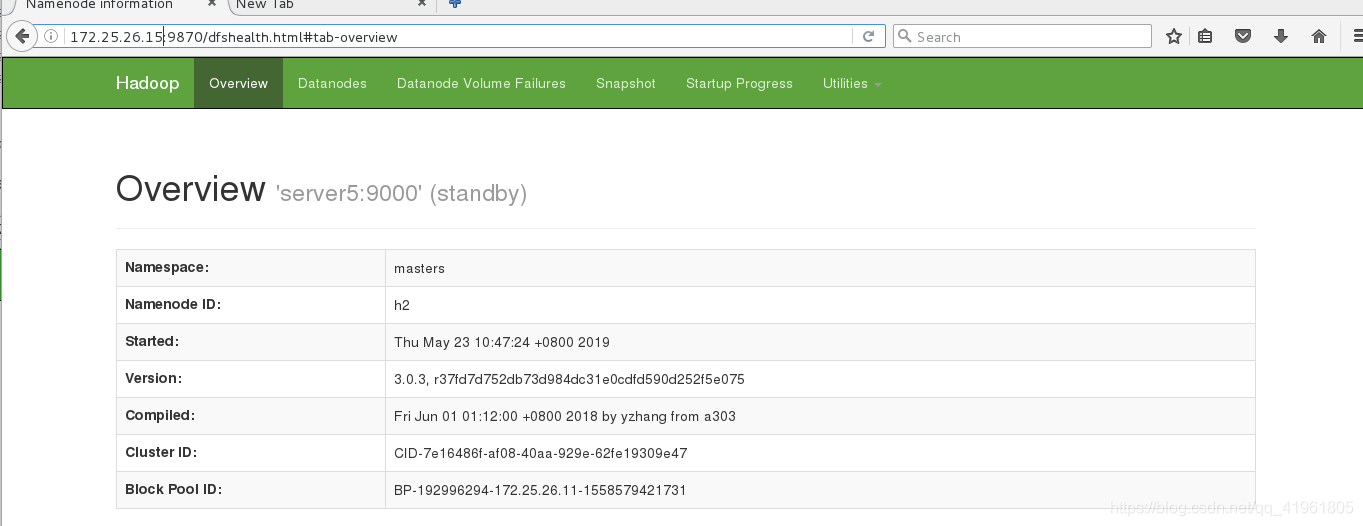
server1为作为h1,server5为h2,此时server1为active,server5为stabdby,server5做为备用节点。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!