二叉树(序列化篇)
JSON 的运用非常广泛,比如我们经常将变成语言中的结构体序列化成 JSON 字符串,存入缓存或者通过网络发送给远端服务,消费者接受 JSON 字符串然后进行反序列化,就可以得到原始数据了。这就是「序列化」和「反序列化」的目的,以某种固定格式组织字符串,使得数据可以独立于编程语言。
本文会用前序、中序、后序遍历的方式来序列化和反序列化二叉树,进一步,还会用迭代式的层级遍历来解决这个问题。
文章目录
- 一、题目描述
- 二、前序遍历解法
- 三、后序遍历解法
- 四、中序遍历解法
- 五、层级遍历解法
一、题目描述
力扣第 297 题「 二叉树的序列化与反序列化」
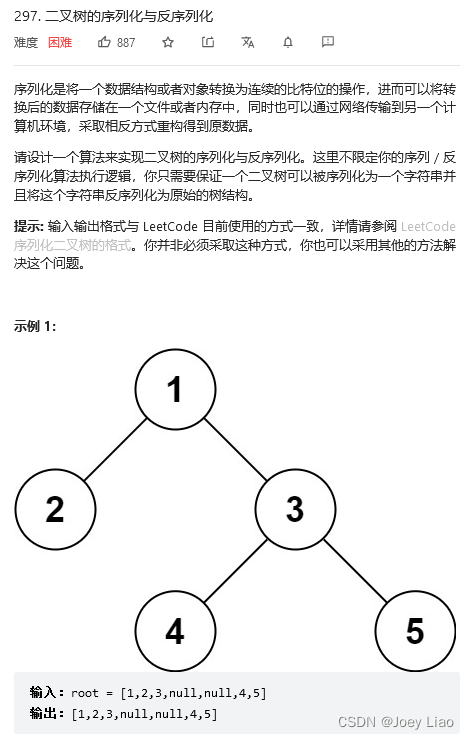
就是给你输入一棵二叉树的根节点 root,要求你实现如下一个类:
public class Codec {// 把一棵二叉树序列化成字符串public String serialize(TreeNode root) {}// 把字符串反序列化成二叉树public TreeNode deserialize(String data) {}
}
二、前序遍历解法
想象一下,二叉树结该是一个二维平面内的结构,而序列化出来的字符串是一个线性的一维结构。所谓的序列化不过就是把结构化的数据「打平」,其实就是在考察二叉树的遍历方式。
StringBuilder 可以用于高效拼接字符串,所以也可以认为是一个列表,用 , 作为分隔符,用 # 表示空指针 null
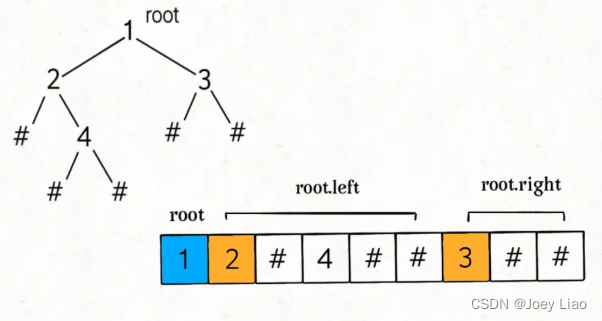
至此,我们已经可以写出序列化函数 serialize 的代码了:
String SEP = ",";
String NULL = "#";/* 主函数,将二叉树序列化为字符串 */
String serialize(TreeNode root) {StringBuilder sb = new StringBuilder();serialize(root, sb);return sb.toString();
}/* 辅助函数,将二叉树存入 StringBuilder */
void serialize(TreeNode root, StringBuilder sb) {if (root == null) {sb.append(NULL).append(SEP);return;}/****** 前序遍历位置 ******/sb.append(root.val).append(SEP);/***********************/serialize(root.left, sb);serialize(root.right, sb);
}
思考一下如何写 deserialize 函数,将字符串反过来构造二叉树。
一般语境下,单单前序遍历结果是不能还原二叉树结构的,因为缺少空指针的信息,至少要得到前、中、后序遍历中的两种才能还原二叉树。但是这里的 node 列表包含空指针的信息,所以只使用 node 列表就可以还原二叉树。
那么,反序列化过程也是一样,先确定根节点 root,然后遵循前序遍历的规则,递归生成左右子树即可:
/* 主函数,将字符串反序列化为二叉树结构 */
TreeNode deserialize(String data) {// 将字符串转化成列表LinkedList<String> nodes = new LinkedList<>();for (String s : data.split(SEP)) {nodes.addLast(s);}return deserialize(nodes);
}/* 辅助函数,通过 nodes 列表构造二叉树 */
TreeNode deserialize(LinkedList<String> nodes) {if (nodes.isEmpty()) return null;/****** 前序遍历位置 ******/// 列表最左侧就是根节点String first = nodes.removeFirst();if (first.equals(NULL)) return null;TreeNode root = new TreeNode(Integer.parseInt(first));/***********************/root.left = deserialize(nodes);root.right = deserialize(nodes);return root;
}
三、后序遍历解法
明白了前序遍历的解法,后序遍历就比较容易理解了,我们首先实现 serialize 序列化方法,只需要稍微修改辅助方法即可:
/* 辅助函数,将二叉树存入 StringBuilder */
void serialize(TreeNode root, StringBuilder sb) {if (root == null) {sb.append(NULL).append(SEP);return;}serialize(root.left, sb);serialize(root.right, sb);/****** 后序遍历位置 ******/sb.append(root.val).append(SEP);/***********************/
}
deserialize 方法首先寻找 root 节点的值,然后递归计算左右子节点
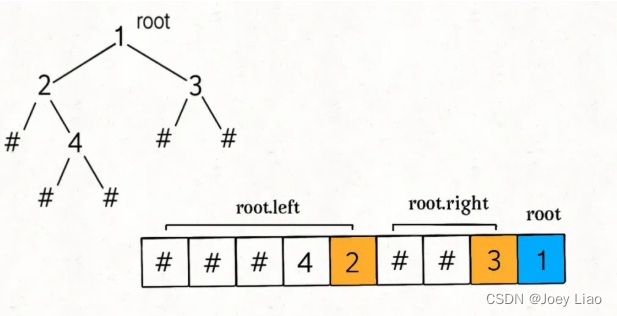
可见,root 的值是列表的最后一个元素。我们应该从后往前取出列表元素,先用最后一个元素构造 root,然后递归调用生成 root 的左右子树。注意,根据上图,从后往前在 nodes 列表中取元素,一定要先构造 root.right 子树,后构造 root.left 子树。
/* 主函数,将字符串反序列化为二叉树结构 */
TreeNode deserialize(String data) {LinkedList<String> nodes = new LinkedList<>();for (String s : data.split(SEP)) {nodes.addLast(s);}return deserialize(nodes);
}/* 辅助函数,通过 nodes 列表构造二叉树 */
TreeNode deserialize(LinkedList<String> nodes) {if (nodes.isEmpty()) return null;// 从后往前取出元素String last = nodes.removeLast();if (last.equals(NULL)) return null;TreeNode root = new TreeNode(Integer.parseInt(last));// 限构造右子树,后构造左子树root.right = deserialize(nodes);root.left = deserialize(nodes);return root;
}
四、中序遍历解法
先说结论,中序遍历的方式行不通,因为无法实现反序列化方法 deserialize。中序遍历的代码,root 的值被夹在两棵子树的中间,也就是在 nodes 列表的中间,我们不知道确切的索引位置,所以无法找到 root 节点,也就无法进行反序列化。
五、层级遍历解法
首先,先写出层级遍历二叉树的代码框架:
void traverse(TreeNode root) {if (root == null) return;// 初始化队列,将 root 加入队列Queue<TreeNode> q = new LinkedList<>();q.offer(root);while (!q.isEmpty()) {TreeNode cur = q.poll();/* 层级遍历代码位置 */System.out.println(root.val);/*****************/if (cur.left != null) {q.offer(cur.left);}if (cur.right != null) {q.offer(cur.right);}}
}
上述代码是标准的二叉树层级遍历框架,从上到下,从左到右打印每一层二叉树节点的值,可以看到,队列 q 中不会存在 null 指针。
不过我们在反序列化的过程中是需要记录空指针 null 的,所以可以把标准的层级遍历框架略作修改
String SEP = ",";
String NULL = "#";/* 将二叉树序列化为字符串 */
String serialize(TreeNode root) {if (root == null) return "";StringBuilder sb = new StringBuilder();// 初始化队列,将 root 加入队列Queue<TreeNode> q = new LinkedList<>();q.offer(root);while (!q.isEmpty()) {TreeNode cur = q.poll();/* 层级遍历代码位置 */if (cur == null) {sb.append(NULL).append(SEP);continue;}sb.append(cur.val).append(SEP);/*****************/q.offer(cur.left);q.offer(cur.right);}return sb.toString();
}
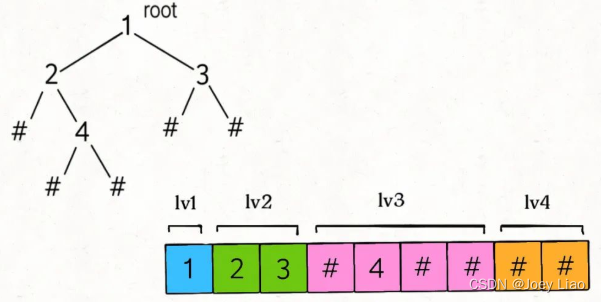
可以看到,每一个非空节点都会对应两个子节点,那么反序列化的思路也是用队列进行层级遍历,同时用索引 i 记录对应子节点的位置:
/* 将字符串反序列化为二叉树结构 */
TreeNode deserialize(String data) {if (data.isEmpty()) return null;String[] nodes = data.split(SEP);// 第一个元素就是 root 的值TreeNode root = new TreeNode(Integer.parseInt(nodes[0]));// 队列 q 记录父节点,将 root 加入队列Queue<TreeNode> q = new LinkedList<>();q.offer(root);for (int i = 1; i < nodes.length; ) {// 队列中存的都是父节点TreeNode parent = q.poll();// 父节点对应的左侧子节点的值String left = nodes[i++];if (!left.equals(NULL)) {parent.left = new TreeNode(Integer.parseInt(left));q.offer(parent.left);} else {parent.left = null;}// 父节点对应的右侧子节点的值String right = nodes[i++];if (!right.equals(NULL)) {parent.right = new TreeNode(Integer.parseInt(right));q.offer(parent.right);} else {parent.right = null;}}return root;
}
这段代码可以考验一下你的框架思维。仔细看一看 for 循环部分的代码,发现这不就是标准层级遍历的代码衍生出来的嘛:
while (!q.isEmpty()) {TreeNode cur = q.poll();if (cur.left != null) {q.offer(cur.left);}if (cur.right != null) {q.offer(cur.right);}
}
只不过,标准的层级遍历在操作二叉树节点 TreeNode,而我们的函数在操作 nodes[i],这也恰恰是反序列化的目的嘛。
本文来自互联网用户投稿,文章观点仅代表作者本人,不代表本站立场,不承担相关法律责任。如若转载,请注明出处。 如若内容造成侵权/违法违规/事实不符,请点击【内容举报】进行投诉反馈!